SpringBoot2 整合JTA组件,多数据源事务管理
本文源码:GitHub·点这里 || GitEE·点这里
一、JTA组件简介
1、JTA基本概念
JTA即Java-Transaction-API,JTA允许应用程序执行分布式事务处理,即在两个或多个网络计算机资源上访问并且更新数据。JDBC驱动程序对JTA的支持极大地增强了数据访问能力。
XA协议是数据库层面的一套分布式事务管理的规范,JTA是XA协议在Java中的实现,多个数据库或是消息厂商实现JTA接口,开发人员只需要调用SpringJTA接口即可实现JTA事务管理功能。
JTA事务比JDBC事务更强大。一个JTA事务可以有多个参与者,而一个JDBC事务则被限定在一个单一的数据库连接。下列任一个Java平台的组件都可以参与到一个JTA事务中
2、分布式事务
分布式事务(DistributedTransaction)包括事务管理器(TransactionManager)和一个或多个支持 XA 协议的资源管理器 ( Resource Manager )。
资源管理器是任意类型的持久化数据存储容器,例如在开发中常用的关系型数据库:MySQL,Oracle等,消息中间件RocketMQ、RabbitMQ等。
事务管理器提供事务声明,事务资源管理,同步,事务上下文传播等功能,并且负责着所有事务参与单元者的相互通讯的责任。JTA规范定义了事务管理器与其他事务参与者交互的接口,其他的事务参与者与事务管理器进行交互。
二、SpringBoot整合JTA
项目整体结构图
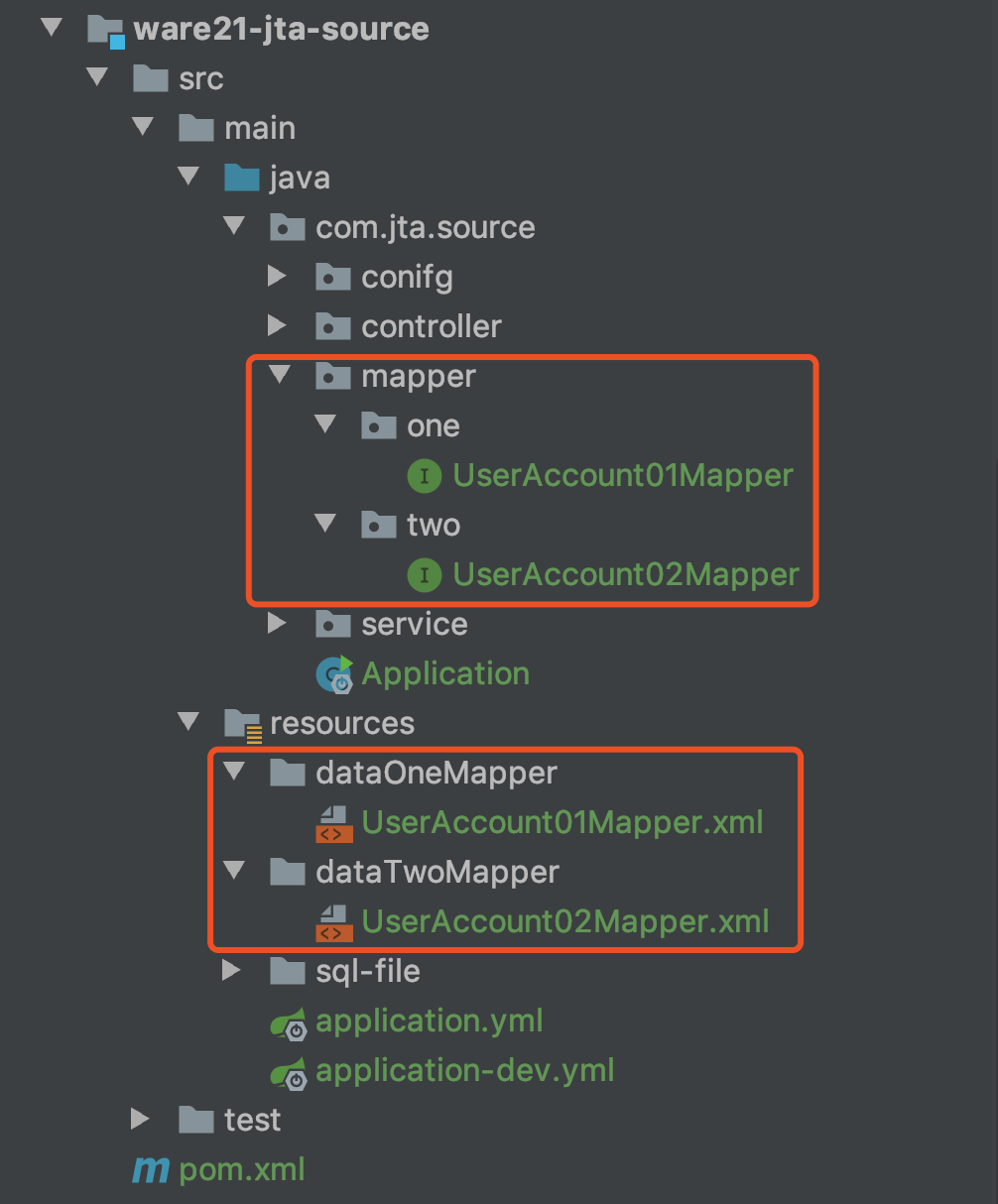
1、核心依赖
<!--SpringBoot核心依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--JTA组件核心依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
2、环境配置
这里jtaManager的配置,在日志输出中非常关键。
spring:
jta:
transaction-manager-id: jtaManager
# 数据源配置
datasource:
type: com.alibaba.druid.pool.DruidDataSource
data01:
driverClassName: com.mysql.jdbc.Driver
dbUrl: jdbc:mysql://localhost:3306/data-one
username: root
password: 000000
data02:
driverClassName: com.mysql.jdbc.Driver
dbUrl: jdbc:mysql://localhost:3306/data-two
username: root
password: 000000
3、核心容器
这里两个数据库连接的配置手法都是一样的,可以在源码中自行下载阅读。基本思路都是把数据源交给JTA组件来统一管理,方便事务的通信。
数据源参数
@Component
@ConfigurationProperties(prefix = "spring.datasource.data01")
public class DruidOneParam {
private String dbUrl;
private String username;
private String password;
private String driverClassName;
}
JTA组件配置
package com.jta.source.conifg;
@Configuration
@MapperScan(basePackages = {"com.jta.source.mapper.one"},sqlSessionTemplateRef = "data01SqlSessionTemplate")
public class DruidOneConfig {
private static final Logger LOGGER = LoggerFactory.getLogger(DruidOneConfig.class) ;
@Resource
private DruidOneParam druidOneParam ;
@Primary
@Bean("dataSourceOne")
public DataSource dataSourceOne () {
// 设置数据库连接
MysqlXADataSource mysqlXADataSource = new MysqlXADataSource();
mysqlXADataSource.setUrl(druidOneParam.getDbUrl());
mysqlXADataSource.setUser(druidOneParam.getUsername());
mysqlXADataSource.setPassword(druidOneParam.getPassword());
mysqlXADataSource.setPinGlobalTxToPhysicalConnection(true);
// 事务管理器
AtomikosDataSourceBean atomikosDataSourceBean = new AtomikosDataSourceBean();
atomikosDataSourceBean.setXaDataSource(mysqlXADataSource);
atomikosDataSourceBean.setUniqueResourceName("dataSourceOne");
return atomikosDataSourceBean;
}
@Primary
@Bean(name = "sqlSessionFactoryOne")
public SqlSessionFactory sqlSessionFactoryOne(
@Qualifier("dataSourceOne") DataSource dataSourceOne) throws Exception{
// 配置Session工厂
SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(dataSourceOne);
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
sessionFactory.setMapperLocations(resolver.getResources("classpath*:/dataOneMapper/*.xml"));
return sessionFactory.getObject();
}
@Primary
@Bean(name = "data01SqlSessionTemplate")
public SqlSessionTemplate sqlSessionTemplate(
@Qualifier("sqlSessionFactoryOne") SqlSessionFactory sqlSessionFactory) {
// 配置Session模板
return new SqlSessionTemplate(sqlSessionFactory);
}
}
4、测试对比
这里通过两个方法测试结果做对比,在两个数据源之间进行数据操作时,只需要在接口方法加上@Transactional注解即可,这样保证数据在两个数据源间也可以保证一致性。
@Service
public class TransferServiceImpl implements TransferService {
@Resource
private UserAccount01Mapper userAccount01Mapper ;
@Resource
private UserAccount02Mapper userAccount02Mapper ;
@Override
public void transfer01() {
userAccount01Mapper.transfer("jack",100);
System.out.println("i="+1/0);
userAccount02Mapper.transfer("tom",100);
}
@Transactional
@Override
public void transfer02() {
userAccount01Mapper.transfer("jack",200);
System.out.println("i="+1/0);
userAccount02Mapper.transfer("tom",200);
}
}
三、JTA组件小结
在上面JTA实现多数据源的事务管理,使用方式还是相对简单,通过两阶段的提交,可以同时管理多个数据源的事务。但是暴露出的问题也非常明显,就是比较严重的性能问题,由于同时操作多个数据源,如果其中一个数据源获取数据的时间过长,会导致整个请求都非常的长,事务时间太长,锁数据的时间就会太长,自然就会导致低性能和低吞吐量。
因此在实际开发过程中,对性能要求比较高的系统很少使用JTA组件做事务管理。作为一个轻量级的分布式事务解决方案,在小的系统中还是值得推荐尝试的。
最后作为Java下的API,原理和用法还是值得学习一下,开阔眼界和思路。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/middle-ware-parent
GitEE·地址
https://gitee.com/cicadasmile/middle-ware-parent

推荐阅读:SpringBoot进阶系列
SpringBoot2 整合JTA组件,多数据源事务管理的更多相关文章
- SpringBoot2 整合Ehcache组件,轻量级缓存管理
本文源码:GitHub·点这里 || GitEE·点这里 一.Ehcache缓存简介 1.基础简介 EhCache是一个纯Java的进程内缓存框架,具有快速.上手简单等特点,是Hibernate中默认 ...
- spring+springmvc+mybatis+oracle+atomikos+jta实现多数据源事务管理
---恢复内容开始--- 在做项目过程中,遇到了需要一个项目中访问两个数据库的情况,发现使用常规的spring管理事务,导致事务不能正常回滚,因此,采用了jta+atomikos的分布式数据源方式 ...
- spring boot 或 spring 集成 atomikos jta 完成多数据源事务管理
前言:对于事务,spring 不提供自己的实现,只是定义了一个接口来供其他厂商实现,具体些的请看我的这篇文章: https://www.cnblogs.com/qiaoyutao/p/11289996 ...
- springbootdruidmybatismysql多数据源事务管理
springboot+druid+mybatis+mysql+多数据源事务管理 分布式事务在java中的解决方案就是JTA(即Java Transaction API):springboot官方提供了 ...
- springboot-jta-atomikos多数据源事务管理
背景 我们平时在用springboot开发时,要使用事务,只需要在方法上添加@Transaction注解即可,但这种方式只适用单数据源,在多数据源下就不再适用: 比如在多数据源下,我们在一个方法里执行 ...
- 传统Spring配置JTA 实现多数据源事务的统一管理
分布式事务是指事务的参与者.支持事务的服务器.资源管理器以及事务管理器分别位于分布系统的不同节点之上,在两个或多个网络计算机资源上访问并且更新数据,将两个或多个网络计算机的数据进行的多次操作作为一个整 ...
- spring JTA多数据源事务管理详细教程
<context:annotation-config /> <!-- 使用注解的包路径 --> <context:component-scan base-package= ...
- Spring整合JMS(四)——事务管理
原文链接:http://haohaoxuexi.iteye.com/blog/1983532 Spring提供了一个JmsTransactionManager用于对JMS ConnectionFact ...
- Spring整合JMS(四)——事务管理(转)
*注:别人那复制来的 Spring提供了一个JmsTransactionManager用于对JMS ConnectionFactory做事务管理.这将允许JMS应用利用Spring的事务管理特性.Jm ...
随机推荐
- (十)自动化测试pom完整文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://mave ...
- usb串口的作用以及JLINK
usb串口的作用 (1)可以当串口使用 (2)如果usb串口连接到STM32的串口1(stm32ISP下载只能是串口1),可以用串口下载程序 (3)因为要连接到usb,可以用来供电 JLINK JLI ...
- MDK未添加相应芯片的安装包
问题: No Algorithm found for: 00000000H - 00000567HErase skipped!Error: Flash Download failed - " ...
- yii2.0数据库操作
User::find()->all(); 此方法返回所有数据: User::findOne($id); 此方法返回 主键 id=1 的一条数据(举个例子): User::find()->w ...
- router-view中绑定key='$route.fullPath'
原文链接https://www.jianshu.com/p/cf2fb443620f 来源:简书 作者:myzony 不设置 router-view 的 key 属性 由于 Vue 会复用相同组件, ...
- Elasticsearch系列---生产集群的索引管理
概要 索引是我们使用Elasticsearch里最频繁的部分日常的操作都与索引有关,本篇从运维人员的视角,来玩一玩Elasticsearch的索引操作. 基本操作 在运维童鞋的视角里,索引的日常操作除 ...
- 5种经典的Linux桌面系统
最近一直在准备Linux相关的PPT,对于一个老码农来说Linux系统自然是比较熟悉了,随口可以说出好几种Linux的版本,然而对于计算机初学者可能就知道windows操作系统.也许你告诉他你可以安装 ...
- 9、ssh的集成方式2
1.在第一种的集成方式中,通过struts2-spring-plugin-2.1.8.1.jar这个插件让spring自动产生对应需要的action类,不需要在对应的spring.xml文件中进行配置 ...
- 慕课网--java权限管理系统
http://coding.imooc.com/class/evaluation/149.html
- keras中loss与val_loss的关系
loss是训练集的损失值,val_loss是测试集的损失值 以下是loss与val_loss的变化反映出训练走向的规律总结: train loss 不断下降,test loss不断下降,说明网络仍在学 ...