Linux core dump使用
什么是 core dump?
core dump是一个当进程意外终止时包含进程内存内容的文件。当程序崩溃的时候,core dump由kernel触发。core dump可以作为程序崩溃时的事后快照(post-mortem snapshot),尤其是在难以可靠的重现故障的情况下。
大多数Linux系统默认开始core dump。但是通常这么做是有代价的。一方面我们想要去收集信息从而提高稳定性并且帮助我们排除故障;另一方面,我们希望限制debug的数据并且避免泄漏一些敏感数据。第一个选择适合于研究不稳定的程序的机器。第二个选择适用于存储和处理敏感数据。
开启 core dump
为了开启core dump,我们需要打开一下系统的软限制(soft limits)。
ulimit -S -c unlimited
- -S:soft limit
- -c:core dump的大小
如果想要永久的打开core dump,我们可以在 /etc/security/limits.conf 文件中添加下面这一句,
* soft core unlimited
除了指定为unlimited,即没有大小限制外,我们还可以直接指定大小,例如
ulimit -c 1024 限制大小为1024
ulimit -c 0 限制大小为0,即不输出core文件
当我们指定数字为0的时候,就意味着不输出core文件了。
当我们只使用-c参数的时候,就是查看core文件的大小限制,也就是关闭了core dump。
ulimit -c
关闭 core dump
core dump 通常需要占用我们的磁盘空间并且可能会包含一些敏感数据,所以我们有的时候需要关闭它。
我们可以通过更新soft limit来关闭core dump
ulimit -S -c 0
如果想要永久的关闭core dump,我们可以在 /etc/security/limits.conf 文件中添加下面这一句,
* soft core 0
* hard core 0
core dump在哪?
Linux通过一个配置的地址来保存core dump
默认路径是
/usr/libexec/abrt-hook-ccpp %s %c %p %u %g %t e %P %I
(%s %c %p %u %g %t e %P %I为core dump文件的命令规则,会在下一小节中解释)
我们可以通过sysctl命令来改变这个位置
sudo sysctl -w kernel.core_pattern=/coredumps/core-%e-%s-%u-%g-%p-%t
这个命令将会更新core_pattern文件/proc/sys/kernel/core_pattern到一个新的位置。
也可以通过在/etc/sysctl.conf中添加下面的代码来永久的改变core dump文件的路径,
kernel.core_pattern="/coredumps/core-%e-%s-%u-%g-%p-%t"
core dump文件的命名规则
默认情况下,一个core dump文件被命名为core,但是在/proc/sys/kernel/core_pattern文件中我们可以定义core dump文件的命名规则(参考上一节中的例子)。这个规则使用%标识符来代替一些当core dump文件被创建的时候可能的传来的值。
- %%:一个%字符
- %p:dumped进程的PID
- %u:dumped进程的真实UID
- %g:dumped进程的真实GID
- %s:导致dump的信号个数
- %t:dump的时间,精确到秒
- %h:hostname
- %e:可执行文件名
- %c:core file大小的限制
例子
根据上面提到的命令,我们现在可以进行一些core dump的操作,查看core dump文件的大小限制、开启core dump、更新core file pattern去存储core dump到磁盘上。下面的操作可以看到在程序崩溃后产生了一个core dump文件。
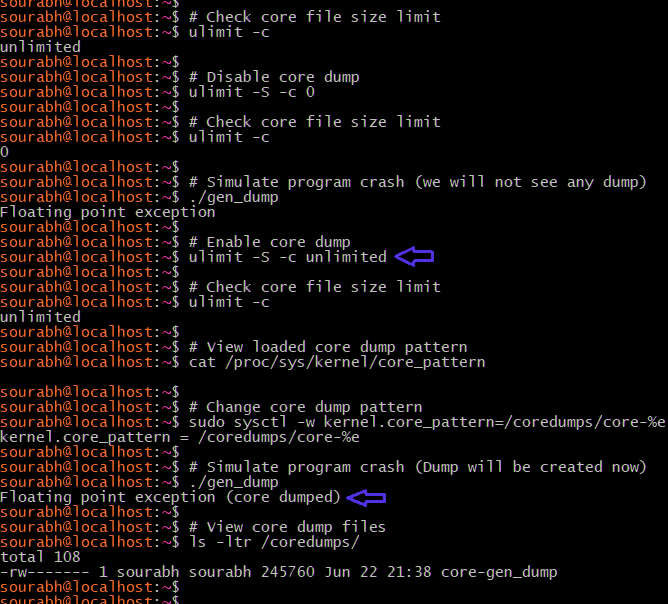
Docker中使用core dump
在docker容器中,使用core dump需要在docker启动的时候就做好设定。我们可以利用--ulimit参数进行设定。
docker run -it -d --name=core-test --ulimit core=-1 image-test bash
这样在容器中,如果发生了程序崩溃,我们就可以在pwd,即当前目录下看到core文件。
注意
- 如果管道符号(‘|’)被用在core file pattern中,core dump文件的大小限制就不起作用了。
参考文献
本文部分内容翻译自
- https://medium.com/@sourabhedake/core-dumps-how-to-enable-them-73856a437711
- http://manpages.ubuntu.com/manpages/precise/man5/core.5.html
有兴趣的同学可以直接看英文原版。如有翻译问题请在评论区指出。
Linux core dump使用的更多相关文章
- 【转】 Linux Core Dump 介绍
=============================================================== Linux core dump的祥细介绍和使用 =========== ...
- Linux core dump file详解
Linux core dump file详解 http://www.cnblogs.com/langqi250/archive/2013/03/05/2944931.html
- Linux Core Dump
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”).我们可以认为 core dump 是“内存快 ...
- linux core dump 文件 gdb分析
core dump又叫核心转储, 当程序运行过程中发生异常, 程序异常退出时, 由操作系统把程序当前的内存状况存储在一个core文件中, 叫core dump. (linux中如果内存越界会收到SIG ...
- Segment fault及LINUX core dump详解 (zz)
C 程序在进行中发生segment fault(core dump)错误,通常与内存操作不当有关,主要有以下几种情况: (1)数组越界. (2)修改了只读内存. (3)scanf("%d&q ...
- Segment fault及LINUX core dump详解
源自:http://andyniu.iteye.com/blog/1965571 core dump的概念: A core dump is the recorded state of the work ...
- linux core dump学习
1. core dump是什么? core dump又叫核心转储,当操作系统收到特定的signal时, 会生成某个进程的core dump文件.这样程序员可以根据 已经生成的core dump文件来d ...
- Linux Core Dump【转】
转自:http://www.cnblogs.com/hazir/p/linxu_core_dump.html 当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中 ...
- linux core dump 生成和调试
core dump 某些信号的产生会导致产生core dump,包含了进程终止时的内存镜像.在某些时候这个core文件就非常的有用处,配合gdb或者lldb调试起来非常方便. 更详细的文档参考 Lin ...
- Linux core dump总结
文章链接:https://www.cnblogs.com/Anker/p/6079580.html 1.前言 一直在从事linux下后台开发,经常与core文件打交道.还记得刚开始从事linux下开发 ...
随机推荐
- 技术实践丨React Native 项目 Web 端同构
摘要:尽管 React Native 已经进入开源的第 6 个年头,距离发布 1.0 版本依旧是遥遥无期."Learn once, write anywhere",完全不影响 Re ...
- kubernets之服务资源
一 服务集群内部或者客户端与pod的通信桥梁 kubernets集群的内部pod访问为啥不能使用传统的IP:PORT的形式? pod是短暂的,它们会随时启动或者关闭,原因可能是pod所在的节点下 ...
- Android之Xposed
基础书籍推荐:1.疯狂JAVA讲义:2.疯狂安卓讲义: 逆向分析必须知道他的原理,不然只会用工具,那就直接GG. 谷歌的镜像网站:https://developers.google.com/andro ...
- ThreadLocal 原理分析
用法 ThreadLocal<String> threadLocal = new ThreadLocal<>(); // 无初始值 ThreadLocal<String& ...
- vue3.0改变概况
一.slot API在render实现原理上的变化 二.全局API使用规范变化 三.Teleport添加 四.composition API变化 五.v-model变化
- C指针的这些使用技巧,掌握后立刻提升一个Level
这是道哥的第016篇原创 关注+星标公众号,不错过最新文章 目录 一.前言 二.八个示例 1. 开胃菜:修改主调函数中的数据 2. 在被调用函数中,分配系统资源 2.1 错误用法 2.2 正确用法 3 ...
- Docker 中的网络功能介绍 外部访问容器 容器互联 配置 DNS
Docker 中的网络功能介绍 | Docker 从入门到实践 https://vuepress.mirror.docker-practice.com/network/ Docker 允许通过外部访问 ...
- 苹果 M1 芯片 OpenSSL 性能测试
Apple M1(MacBook Air 2020) type 16 bytes 64 bytes 256 bytes 1024 bytes 8192 bytes md2 0.00 0.00 0.00 ...
- Spring听课笔记(专题二)
第3章 Spring Bean的装配(上) 3-1:配置项及作用域 1.Bean的配置项: -- Id -- Class (这个必须,其他的都可以不配置) -- Scope (作用域) -- Cons ...
- 四:SpringBoot-定时任务和异步任务的使用方式
SpringBoot-定时任务和异步任务的使用方式 1.定时任务 2.同步和异步 3.定时器的使用 3.1 定时器执行规则注解 3.2 定义时间打印定时器 3.3 启动类开启定时器注解 4.异步任务 ...