Python 分析热卖年货,今年春节大家都在送啥?

今年不知道有多少小伙伴留在原地过年,虽然今年过年不能回老家,但这个年也得过,也得买年货,给家人长辈送礼。于是我出于好奇心的想法利用爬虫获取某宝数据,并结合 Python 数据分析和第三方可视化平台来分析一下大家过年都买了哪些东西,分析结果如下:
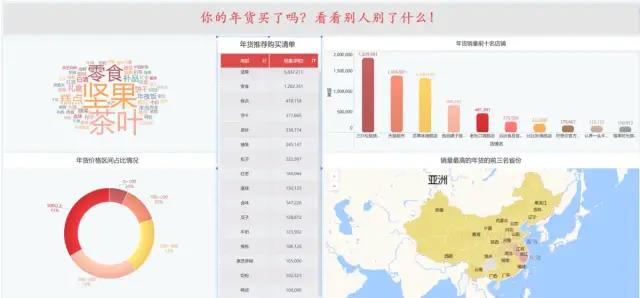
上面使用清洗好的数据后用 finebi 第三方可视化工具完成的。接下来是用 Python 的实现过程,对于本文的叙述,主要分为以下五步:
- 分析思路
- 爬虫部分
- 数据清洗
- 数据可视化及分析
- 结论与建议
一、分析思路
其实就今天的数据来讲,我们主要做的是探索性分析;首先梳理已有的字段,有标题(提取出品类)、价格、销量、店铺名、发货地。下面来做一下详细的维度拆分以及可视化图形选择:
品类:
- 品类销量的 TOP 10 有哪些?(表格或者横向条形图)
- 热门(出现次数最多)品类展示;(词云)
价格:年货的价格区间分布情况;(圆环图,观察占比)
销量、店铺名: - 店铺销量最高的 TOP 10 有哪些?(条形图)
- 结合品类做联动,比如点坚果,对应展示销量排名的店铺;(联动,利用三方工具)
发货地:销量最高的城市有哪些?(地图)
二、爬取数据
爬取主要利用 selenium 模拟点击浏览器,前提是已经安装 selenium 和浏览器驱动,这里我是用的 Google 浏览器,找到对应的版本号后并下载对应的版本驱动,一定要对应浏览器的版本号。
pip install selenium
安装成功后,运行如下代码,输入关键字"年货",进行扫码就可以了,等着程序慢慢采集。
# coding=utf8
import re
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
import time
import csv
# 搜索商品,获取商品页码
def search_product(key_word):
# 定位输入框
browser.find_element_by_id("q").send_keys(key_word)
# 定义点击按钮,并点击
browser.find_element_by_class_name('btn-search').click()
# 最大化窗口:为了方便我们扫码
browser.maximize_window()
# 等待15秒,给足时间我们扫码
time.sleep(15)
# 定位这个“页码”,获取“共100页这个文本”
page_info = browser.find_element_by_xpath('//div[@class="total"]').text
# 需要注意的是:findall()返回的是一个列表,虽然此时只有一个元素它也是一个列表。
page = re.findall("(\d+)", page_info)[0]
return page
# 获取数据
def get_data():
# 通过页面分析发现:所有的信息都在items节点下
items = browser.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for item in items:
# 参数信息
pro_desc = item.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
# 价格
pro_price = item.find_element_by_xpath('.//strong').text
# 付款人数
buy_num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 旗舰店
shop = item.find_element_by_xpath('.//div[@class="shop"]/a').text
# 发货地
address = item.find_element_by_xpath('.//div[@class="location"]').text
# print(pro_desc, pro_price, buy_num, shop, address)
with open('{}.csv'.format(key_word), mode='a', newline='', encoding='utf-8-sig') as f:
csv_writer = csv.writer(f, delimiter=',')
csv_writer.writerow([pro_desc, pro_price, buy_num, shop, address])
def main():
browser.get('https://www.taobao.com/')
page = search_product(key_word)
print(page)
get_data()
page_num = 1
while int(page) != page_num:
print("*" * 100)
print("正在爬取第{}页".format(page_num + 1))
browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_num * 44))
browser.implicitly_wait(25)
get_data()
page_num += 1
print("数据爬取完毕!")
if __name__ == '__main__':
key_word = input("请输入你要搜索的商品:")
option = Options()
browser = webdriver.Chrome(chrome_options=option,
executable_path=r"C:\Users\cherich\AppData\Local\Google\Chrome\Application\chromedriver.exe")
main()
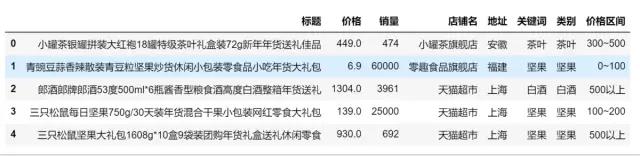
采集结果如下:

数据准备完成,中间从标题里提取类别过程比较耗时,建议大家直接用整理好的数据。
大概思路是对标题进行分词,命名实体识别,标记出名词,找出类别名称,比如坚果、茶叶等。
三、数据清洗
这里的文件清洗几乎用 Excel 搞定,数据集小,用 Excel 效率很高,比如这里做了一个价格区间。到现在数据清洗已经完成(可以用三方工具做可视化了),如果大家爱折腾,可以接着往下看用 Python 如何进行分析。
四、数据可视化及分析
1、读取文件
import pandas as pd
import matplotlib as mpl
mpl.rcParams['font.family'] = 'SimHei'
from wordcloud import WordCloud
from ast import literal_eval
import matplotlib.pyplot as plt
datas = pd.read_csv('./年货.csv',encoding='gbk')
datas
2、可视化:词云图
li = []
for each in datas['关键词'].values:
new_list = str(each).split(',')
li.extend(new_list)
def func_pd(words):
count_result = pd.Series(words).value_counts()
return count_result.to_dict()
frequencies = func_pd(li)
frequencies.pop('其他')
plt.figure(figsize = (10,4),dpi=80)
wordcloud = WordCloud(font_path="STSONG.TTF",background_color='white', width=700,height=350).fit_words(frequencies)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()

图表说明:我们可以看到词云图,热门(出现次数最多)品类字体最大,依次是:坚果、茶叶、糕点等。
3、可视化:绘制圆环图
# plt.pie(x,lables,autopct,shadow,startangle,colors,explode)
food_type = datas.groupby('价格区间').size()
plt.figure(figsize=(8,4),dpi=80)
explodes= [0,0,0,0,0.2,0.1]
size = 0.3
plt.pie(food_type, radius=1,labels=food_type.index, autopct='%.2f%%', colors=['#F4A460','#D2691E','#CDCD00','#FFD700','#EEE5DE'],
wedgeprops=dict(width=size, edgecolor='w'))
plt.title('年货价格区间占比情况',fontsize=18)
plt.legend(food_type.index,bbox_to_anchor=(1.5, 1.0))
plt.show()
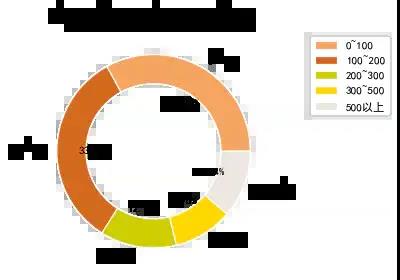
图表说明:圆环图和饼图类似,代表部分相对于整体的占比情况,可以看到0 ~ 200元的年货大概33%左右,100 ~ 200元也是33%。说明大部分的年货的价格趋于200以内。
4、可视化:绘制条形图
data = datas.groupby(by='店铺名')['销量'].sum().sort_values(ascending=False).head(10)
plt.figure(figsize = (10,4),dpi=80)
plt.ylabel('销量')
plt.title('年货销量前十名店铺',fontsize=18)
colors = ['#F4A460','#D2691E','#CDCD00','#EEE5DE', '#EEB4B4', '#FFA07A', '#FFD700']
plt.bar(data.index,data.values, color=colors)
plt.xticks(rotation=45)
plt.show()
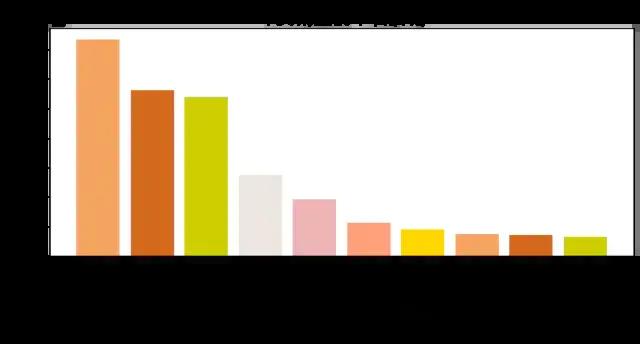
图表说明:以上是店铺按销量排名情况,可以看到第一名是三只松鼠旗舰店,看来过年大家都喜欢吃干货。
5、可视化:绘制横向条形图
foods = datas.groupby(by='类别')['销量'].sum().sort_values(ascending=False).head(10)
foods.sort_values(ascending=True,inplace=True)
plt.figure(figsize = (10,4),dpi=80)
plt.xlabel('销量')
plt.title('年货推荐购买排行榜',fontsize=18)
colors = ['#F4A460','#D2691E','#CDCD00','#CD96CD','#EEE5DE', '#EEB4B4', '#FFA07A', '#FFD700']
plt.barh(foods.index,foods.values, color=colors,height=1)
plt.show()

图表说明:根据类别销量排名,排名第一是坚果,验证了上面的假设,大家喜欢吃坚果。
结论与建议
淘宝热卖年货: 坚果,茶叶,糕点,饼干,糖果,白酒,核桃,羊肉,海参,枸杞;
年货推荐清单(按销量):坚果、零食、糕点、饼干、茶叶、糖果、松子、红枣、蛋糕、卤味、瓜子、牛奶、核桃;
年货价格参考:66%以上的年货价格在0~200元之间;
热门店铺:三只老鼠、天猫超市、百草味、良品铺子;
Python 分析热卖年货,今年春节大家都在送啥?的更多相关文章
- 用Python分析国庆旅游景点,告诉你哪些地方好玩、便宜、人又少
注:本人参考“裸睡的猪”公众号同名文章,学习使用. 一.目标 使用Python分析出国庆哪些旅游景点:好玩.便宜.人还少的地方,不然拍照都要抢着拍! 二.获取数据 爬取出行网站的旅游景点售票数据,反映 ...
- Python分析盘点2019全球流行音乐:是哪些歌曲榜单占领了我们?
写在前面:圣诞刚过,弥留者节日气息的大家是否还在继续学习呐~在匆忙之际也不忘给自己找几首好听的歌曲放松一下,缠绕着音乐一起来看看关于2019年流行音乐趋势是如何用Python分析的吧! 昨天下午没事儿 ...
- Python分析数据难吗?某科技大学教授说,很难但有方法就简单
用python分析数据难吗?某科技大学的教授这样说,很难,但要讲方法,主要是因为并不是掌握了基础,就能用python来做数据分析的. 所谓python的基础,也就是刚入门的python学习者,学习的基 ...
- 五月天的线上演唱会你看了吗?用Python分析网友对这场线上演唱会的看法
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:CDA数据分析师 豆瓣9.4分!这场线上演唱会到底多好看? 首先让我 ...
- Python分析离散心率信号(下)
Python分析离散心率信号(下) 如何使用动态阈值,信号过滤和离群值检测来改善峰值检测. 一些理论和背景 到目前为止,一直在研究如何分析心率信号并从中提取最广泛使用的时域和频域度量.但是,使用的信号 ...
- Python分析离散心率信号(中)
Python分析离散心率信号(中) 一些理论和背景 心率信号不仅包含有关心脏的信息,还包含有关呼吸,短期血压调节,体温调节和荷尔蒙血压调节(长期)的信息.也(尽管不总是始终如一)与精神努力相关联,这并 ...
- Python分析离散心率信号(上)
Python分析离散心率信号(上) 一些理论和背景 心率包含许多有关信息.如果拥有心率传感器和一些数据,那么当然可以购买分析包或尝试一些可用的开源产品,但是并非所有产品都可以满足需求.也是这种情况.那 ...
- 关于mysql保存数据的时候报问题分析 普通的字符串或者表情都是占位3个字节,所以utf8足够用了,但是移动端的表情符号占位是4个字节,普通的utf8就不够用了,为了应对无线互联网的机遇和挑战、避免 emoji 表情符号带来的问题、涉及无线相关的 MySQL 数据库建议都提前采用 utstring value:'\xF0\x9F\x98\x82\xF0\x9F...' for ...
问题分析 普通的字符串或者表情都是占位3个字节,所以utf8足够用了,但是移动端的表情符号占位是4个字节,普通的utf8就不够用了,为了应对无线互联网的机遇和挑战.避免 emoji 表情符号带来的问题 ...
- python 分析慢查询日志生成报告
python分析Mysql慢查询.通过Python调用开源分析工具pt-query-digest生成json结果,Python脚本解析json生成html报告. #!/usr/bin/env pyth ...
随机推荐
- 在项目中应该使用Boolean还是使用boolean?
起因 在公司看代码时,看到了使用Boolean对象来完成业务逻辑判断的操作.和我的习惯不一致,于是引起了一些反思. boolean和Boolean的差别咱就不说了,我们仅探讨使用boolean与Boo ...
- 删除开发账号的ACCESS KEY
大家都知道,当申请一个开发账号来开发程序的时候需要一个ACCESS key,这个key我们可以通过系统管理员在OSS上注册, 也可以通过一些软件来计算,比如zapgui.EXE,但是当用软件注册完,不 ...
- 深度学习DeepLearning技术实战(12月18日---21日)
12月线上课程报名中 深度学习DeepLearning(Python)实战培训班 时间地点: 2020 年 12 月 18 日-2020 年 12 月 21日 (第一天报到 授课三天:提前环境部署 电 ...
- Ubuntu安装记录
好吧,这成功地让我想起了那些边肯红薯边黑苹果的早晨······ 本人纯属Windows用腻,后期请大佬多多指教 前面因为没U盘而碰壁的内容在此不说,接下来因为太兴奋,关于安装U盘制作没记录什么.最终, ...
- b站视频_下载_去水印_视频转mp4-批量下载神器
b站下载_视频_去水印_转mp4_批量下载的解决办法 以下问题均可解决 b站下载的视频如何保存到本地 b站下载的视频在那个文件夹里 b站下载视频转mp4 b站下载app b站下载在哪 b站下载视频电脑 ...
- apk开发环境!多亏这份《秋招+金九银十-腾讯面试题合集》跳槽薪资翻倍!再不刷题就晚了!
开头 最近很多网友反馈:自己从各处弄来的资料,过于杂乱.零散.碎片化,看得时候觉得挺有用的,但过个半天,啥都记不起来了.其实,这就是缺少系统化学习的后果. 为了提高大家的学习效率,帮大家能快速掌握An ...
- TCP/IP建立连接的时候ISN序号分配问题
初始建立TCP连接的时候的系列号(ISN)是随机选择的,那么这个系列号为什么不采用一个固定的值呢?主要有两方面的原因 防止同一个连接的不同实例(different instantiations/inc ...
- Spring听课笔记(专题二下)
第4章 Spring Bean基于注解的装配 4.1 Bean的定义及作用域的注解实现 1. Bean定义的注解 -- @Component是一个通用注解,可用于任何bean -- @Reposito ...
- sql注入-原理&防御
SQL注入是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数 ...
- Spark:常用transformation及action,spark算子详解
常用transformation及action介绍,spark算子详解 一.常用transformation介绍 1.1 transformation操作实例 二.常用action介绍 2.1 act ...