Deformable DETR:商汤提出可变型 DETR,提点又加速 | ICLR 2021 Oral
DETR能够消除物体检测中许多手工设计组件的需求,同时展示良好的性能。但由于注意力模块在处理图像特征图方面的限制,DETR存在收敛速度慢和特征分辨率有限的问题。为了缓解这些问题,论文提出了Deformable DETR,其注意力模块仅关注参考点周围的一小组关键采样点,通过更少的训练次数实现比DETR更好的性能来源:晓飞的算法工程笔记 公众号
论文: Deformable DETR: Deformable Transformers for End-to-End Object Detection

Introduction
现代物体检测器采用许多手工制作的组件,例如锚点生成、基于规则的训练目标分配、非极大值抑制 (NMS) 后处理,导致其并不是完全端到端的。DETR的提出消除了对此类手工制作组件的需求,并构建了第一个完全端到端的物体检测器。DETR采用简单的架构,结合卷积神经网络 (CNN) 和Transformer编码器-解码器,利用Transformer的多功能且强大的关系建模功能,达到了很不错的性能。
尽管DETR具有有趣的设计和良好的性能,但它也有自己的问题:(1)需要更长的训练周期才能收敛。(2)DETR在检测小物体方面的性能相对较低,没有利用多尺度特征。
上述问题主要归因于Transformer组件在处理图像特征图方面的缺陷。在初始化时,注意力模块将几乎统一的注意力权重投射到特征图中的所有像素。长时间的训练对于注意力权重学习如何关注稀疏的有意义的位置是必要的。另一方面,Transformer编码器中的注意力权重计算与像素成二次计算度。因此,处理高分辨率特征图的计算和存储复杂度非常高。
在图像领域,可变形卷积是处理稀疏空间位置的强大而有效的机制,自然就避免了上述问题。但它缺乏元素关系建模机制,而这正是DETR成功的关键。
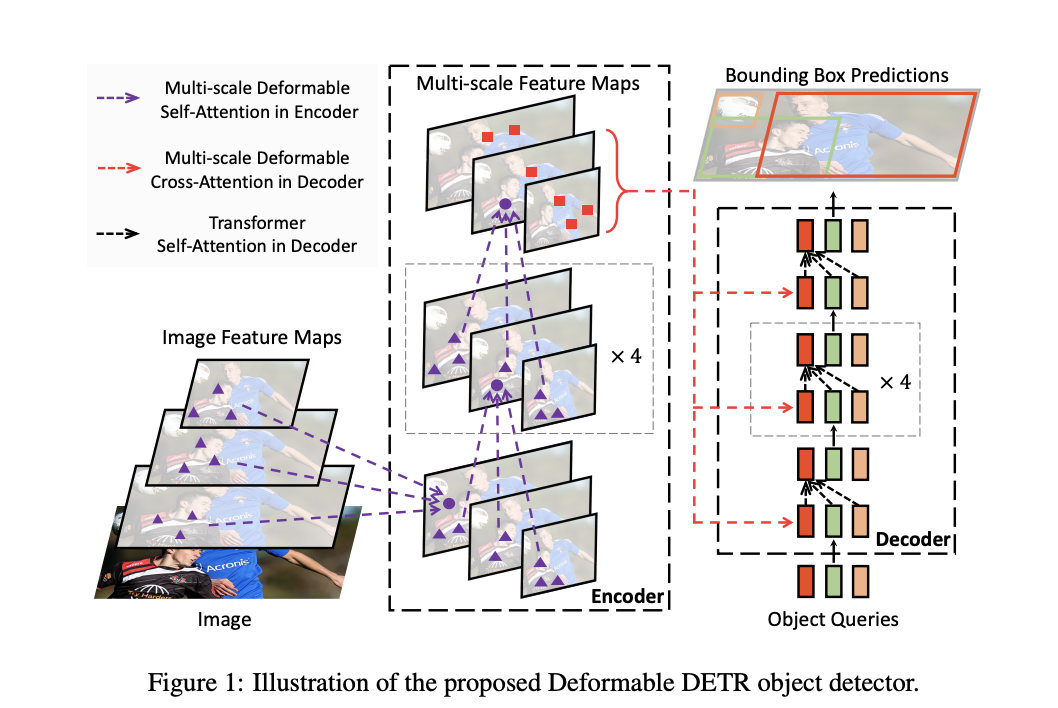
在本文中,论文提出了Deformable DETR,结合可变形卷积的稀疏空间采样和Transformers的关系建模能力,缓解了DETR收敛速度慢和计算复杂度高的问题。可变形注意模块仅关注一小组采样位置,相当于所有特征图像素中突出关键元素的预过滤器。该模块可以自然地扩展到多尺度特征架构,而无需FPN的帮助。在Deformable DETR中,论文利用(多尺度)可变形注意力模块来代替处理特征图的Transformer注意力模块,如图 1 所示。
Revisiting Transformers and DETR
Multi-Head Attention in Transformers.
定义 \(q\in\Omega_{q}\) 为查询元素下标,索引特征 \({z}_{q}\in {\mathbb{R}}^C\) ,\(k\in\Omega_{k}\) 为键元素下标,索引特征 \(x\_k \in \mathbb{R}^C\),\({C}\) 是特征维度,\(\Omega_{q}\) 和 \(\Omega\_{k}\) 分别为查询元素和键元素的集合。
多头注意力特征的计算可表示为:
\mathrm{MultiHeadAttn}(z_{q},x)=\sum_{m=1}^{M}W_{m}[\sum_{k\in\Omega_{k}}A_{m q k}\cdot W_{m}^{\prime}x_{k}],
\quad\quad (1)
\]
其中 \(m\) 为注意力头下标,\(W_{m}^{\prime}\in\mathbb{R}^{C_{v}\times C}\) 和 \(W_{m}\in{\mathbb{R}^{{C}\times C_{v}}}\) 为可学习的权重(默认 \({C}_{v}=C/M\))。注意力权重 \(A_{m q k}\propto{exp}\lbrace\frac{z_{q}^{T}\,U_{m}^{T}\,\,V_{m}\,x_{k}}{\sqrt{C_{v}}}\rbrace\) 归一化为 \(\sum_{k\in\Omega_k}A_{mqk}=1\),其中 \(U_{m},V_{m}\in\mathbb{R}^{C_{v}\times C}\) 也是可学习的权重。为了区别不同的空间位置,特征 \({z}_{q}\) 和 \({z}\_{k}\) 通常是元素内容和位置嵌入的串联或求和。
Transformer有两个已知问题:1)收敛需要很长的训练周期。2)多头注意力的计算和内存复杂度可能非常高。
DETR
DETR建立在Transformer编码器-解码器架构之上,与基于集合的匈牙利损失相结合,通过二分匹配强制对每个GT的边界框进行预测。对DETR不熟悉的,可以看看之前的文章,【DETR:Facebook提出基于Transformer的目标检测新范式 | ECCV 2020 Oral】。
给定CNN主干网提取的输入特征图 \(x\in\mathbb{R}^{C\times H\times W}\),DETR利用标准Transformer编码器-解码器架构将输入特征图转换为一组对象查询的特征。在对象查询特征(由解码器产生)之上添加一个 3 层前馈神经网络(FFN)和一个线性投影作为检测头。FFN充当回归分支来预测边界框坐标 \(b\in 0, 1^4\),其中 \(b = {b_{x},b_{y},b_{w},b_{h}}\) 编码归一化的框中心坐标、框高度和框宽度(相对于图像大小),线性投影则作为分类分支来产生分类结果。
对于DETR中的Transformer编码器,查询元素和键元素都是主干网络特征图中的像素(带有编码的位置嵌入)。
对于DETR中的Transformer解码器,输入包括来自编码器的特征图和由可学习位置嵌入表示的N个对象查询。解码器中有两种类型的注意力模块,即交叉注意力模块和自注意力模块。
- 在交叉注意力模块中,查询元素为学习到的对象查询,而键元素是编码器的输出特征图。
- 在自注意力模块中,查询元素和键元素都是对象查询,从而捕获它们的关系。
DETR是一种极具吸引力的物体检测设计,无需许多手工设计的组件,但也有自己的问题:1)由于计算复杂度限制其可使用分辨率的大小,导致Transformer在检测小物体方面的性能相对较低。2)因为处理图像特征的注意力模块很难训练,DETR需要更多的训练周期才能收敛。
METHOD
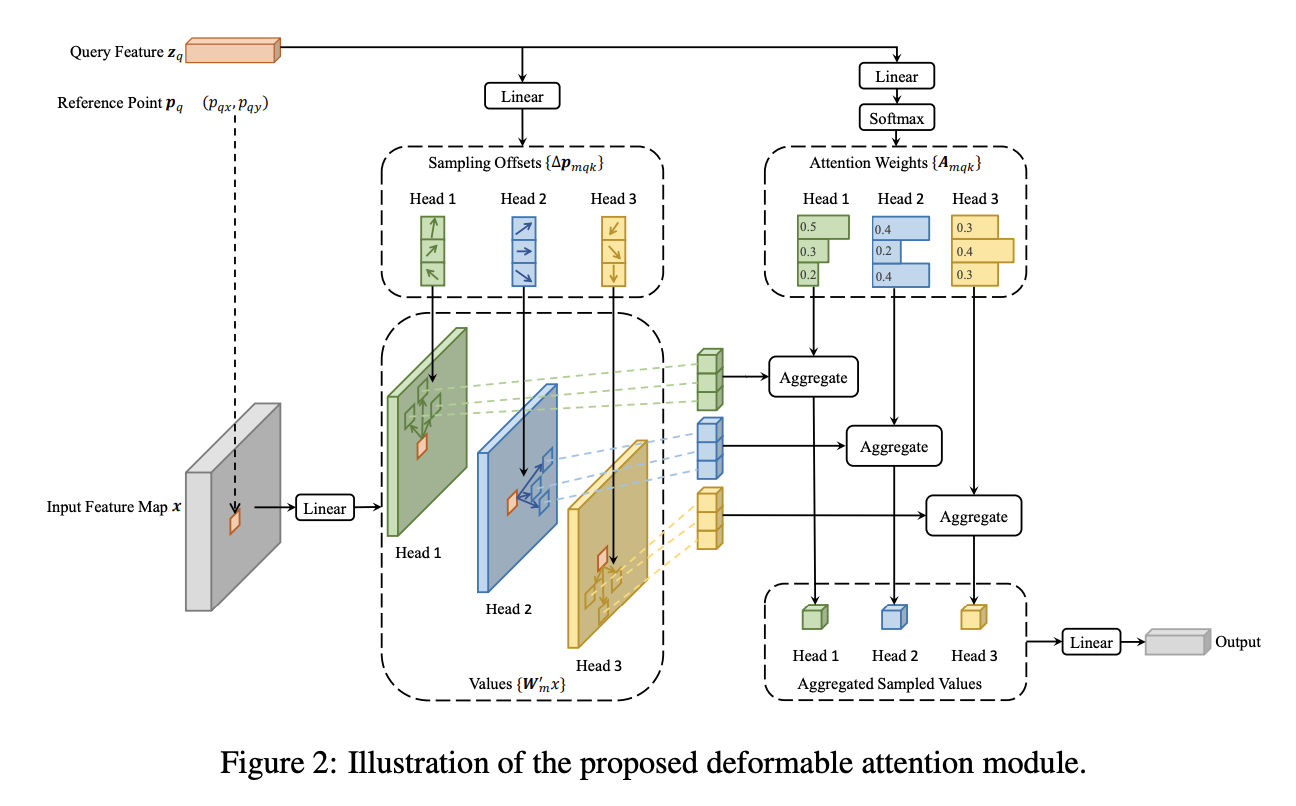
Deformable Transformers for End-to-End Object Detection
- Deformable Attention Module
在图像特征图上应用注意力计算的核心问题是,它会遍历所有的空间位置。为了解决这个问题,论文提出了一个可变形的注意力模块。受可变形卷积的启发,可变形注意力模块仅关注参考点周围的一小组关键采样点,而不管特征图的空间大小。如图 2 所示,通过为每个查询元素仅分配少量的键元素,可以缓解收敛慢和特征空间分辨率大的问题。
给定输入特征图 \(x\in\mathbb{R}^{C\times H\times W}\) ,\(q\) 为查询元素的下标,对应内容特征 \({z}_{q}\) 和二维参考点 \({p}_{q}\),可变形注意力特征的计算如下
\mathrm{DeformAttn}(z_{q},p_{q},x)=\sum_{m=1}^{M}W_{m}\sum_{k=1}^{K}A_{m q k}\cdot W_{m}^{\prime}x(p_{q}+\Delta p\_{m q k}),
\quad\quad (2)
\]
其中 \(m\) 为注意力头下标,\(k\) 为采样点下标,\(K\) 为采样点总数( \(K\ll H W\) )。\({\Delta}p_{mqk}\) 和 \(A_{m q k}\) 表示第k个采样点的采样偏移及其使用的在第m个头中的注意力权重。注意力权重 \(A_{m q k}\) 在 \(0,1\) 范围内,由 \(\sum_{k=1}^{K}A_{m q k} = 1\) 归一化。 \({\Delta}p_{mqk}\in \mathbb{R}^{2}\)是无约束范围的二维实数,由于 \(p_{q} + \Delta p_{mqk}\) 是小数,需要应用双线性插值。\(\Delta p_{m q k}\) 和 \(A_{mqk}\) 均通过对查询特征 \({z}_{q}\) 的线性投影获得的。在实现中,查询特征 \(z_{q}\) 被输入到 \(3MK\) 通道的线性投影运算符,其中前 \(2MK\) 通道对 \({\Delta}P_{m q k}\) 采样偏移进行编码,剩余的 \(MK\) 通道输入到 \(Softmax\) 运算符以获得 \(A_{m q k}\) 注意力权重。

定义 \(N_{q}\) 为查询元素的数量,当 \(M K\) 相对较小时,可变形注意力模块的复杂度为\(O(2N_{q}C^{2}+\operatorname\*{min}(H W C^{2},N_{q}K C^{2}))\)。当应用于__DETR__编码器时,其中 \(N_{q}=H W\) ,复杂度变为 \(O(H W C^{2})\),与空间大小成线性复杂度。当应用于DETR解码器中的交叉注意模块时,其中 \(N\_{q}=N\) (\(N\) 是对象查询的数量),复杂度变为 \(O(NKC^2)\),这与空间大小\(HW\)无关。
- Multi-scale Deformable Attention Module
大多数现代目标检测框架都受益于多尺度特征图,论文提出的可变形注意模块也可以自然地扩展到多尺度特征图。
定义 \(\left{x^{l}\right}^{L}_{l=1}\) 为输入的多尺度特征图,其中 \(x^{l}\in \mathbb{R}^{C\times H_{l}\times W_{l}}\)。定义 \({\hat{p}}_{q}\in0,1^{2}\) 为每个查询元素 \(q\) 对应的参考点的归一化坐标,多尺度可变形注意模块的计算为:
\mathrm{MSDeformAttn}(z_{q},\hat{p}_{q},{x^{l}}_{l=1}^{L})=\sum_{m=1}^{M}W_{m}\bigl[\sum_{l=1}^{L}\sum_{k=1}^{K}A_{m l q k}\cdot W_{m}^{\prime}x^{l}(\phi_{l}(\hat{p}_{q})+\Delta p_{m l q k}\bigr)\bigr],
\quad\quad (3)
\]
其中 \(m\) 为注意力头下标,\(l\) 为输入特征级别下标,\(k\) 为采样点下标。\(\Delta p_{mlqk}\) 和 \(A_{mlqk}\) 表示第 \({{k}}^{th}\) 个采样点在第 \({{l}}^{th}\) 个特征级别和第 \({{m}}^{th}\) 个注意头中的采样偏移和注意力权重,其中标量注意力权重 \(A_{mlqk}\) 由 \(\sum^L_{l=1}\sum^K_{k=1}A_{mlqk}=1\) 归一化。为了缩放方便,使用归一化的坐标 \({\hat{p}}_{q}\in0,1^{2}\),其中 \((0,0)\) 和 \((1,1)\) 分别表示图像的左上角和右下角。公式 3 中的函数 \(\phi_{l}{({\hat{p}}_{q})}^{\cdot}\) 将归一化坐标 \({\hat{p}}_{q}\) 重新缩放到第 \({l}^{th}\) 级别的输入特征图的坐标。多尺度可变形注意力与之前的单尺度版本非常相似,只是它从多尺度特征图中采样 \(LK\) 个点,而不是仅从单尺度特征图中采样 \(K\) 个点。
当 \(L=1\),\(K=1\) 以及将 \(W^{'}_{m}\in \mathbb{R}^{{C}_{v}\times C}\) 固定为单位矩阵时,论文所提出的注意力模块即退化为可变形卷积。
可变形卷积是针对单尺度输入而设计的,每个注意力头仅关注一个采样点,而论文的多尺度可变形注意力会关注来自多尺度输入的多个采样点。(多尺度)可变形注意模块也可以被视为Transformer注意力的有效变体,可变形采样位置相当于引入预过滤机制。当采样点为所有位置时,可变形注意力模块相当于Transformer注意力。
- Deformable Transformer Encoder
将DETR中处理特征图的注意力模块替换为多尺度可变形注意力模块,编码器的输入和输出都是具有相同分辨率的多尺度特征图。
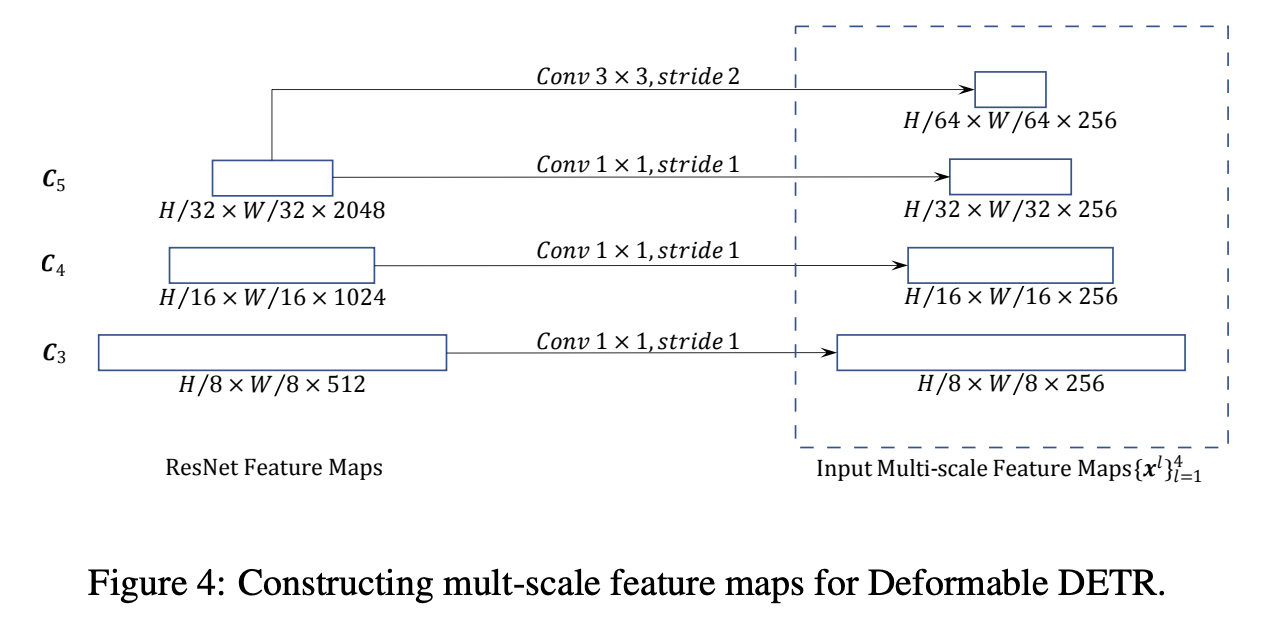
将ResNet的 \(C_3\) 到 \(C\_5\) 阶段的输出特征图,通过 \(1\times 1\) 卷积提取多尺度特征图 \(\left{x^{l}\right}_{l=1}^{L-1}\)(\(L=4\)),其中 \(C_{l}\) 的分辨率为输入图像的 \(2^{l}\) 倍降采样。最低分辨率特征图 \(x^{L}\) 是通过对 \(C\_5\) 阶段的输出进行步幅为 2 的 \(3\ \times\ 3\) 卷积获得,表示为 \(C_{6}\) 阶段。所有多尺度特征图都是 \(C=256\) 通道。这里没有使用类似FPN的自上而下结构,因为论文提出的多尺度可变形注意力本身就可以在多尺度特征图之间交换信息,添加FPN并不会提高性能。
在编码器中应用多尺度可变形注意力模块时,输出是与输入具有相同分辨率的多尺度特征图,键和查询元素都是来自多尺度特征图的像素。对于每个查询像素,参考点是其本身。为了确定每个查询像素位于哪个特征级别,除了位置嵌入之外,还在特征中添加了尺度级别嵌入 \(e\_{l}\)。与固定编码的位置嵌入不同,尺度级嵌入是随机初始化并与网络联合训练的。
- Deformable Transformer Decoder
解码器中有交叉注意力和自注意力模块,两种类型的注意力模块的查询元素都是对象查询。在交叉注意力模块中,键元素是编码器的输出特征图,对象查询通过与特征图交互提取特征。而在自注意力模块中,键元素也是对象查询,对象查询即相互交互提取特征。
由于可变形注意模块的设计初衷是将卷积特征图作为键元素,因此论文仅将交叉注意模块替换为多尺度可变形注意模块,保持自注意模块不变。对于每个对象查询,参考点 \({\hat{p}}\_{q}\) 的二维归一化坐标是通过带 \(\mathrm{sigmoid}\) 函数的可学习线性投影从对象查询嵌入中预测的。
由于多尺度可变形注意模块提取参考点周围的图像特征,论文将参考点作为边界框中心的初始猜测,然后检测头预测边的相对偏移量。这样,不仅能够降低优化难度,还能让解码器注意力将与预测的边界框具有很强的相关性,加速训练收敛。
Additional Improvements and Variants for Deformable DETR
由于其快速收敛以及高效率的计算,可变形DETR为各种端到端目标检测器的变体提供了可能性,比如:
- Iterative Bounding Box Refinement:通过级联的方式,每层解码器优化前一层的预测结果。
- Two-Stage Deformable DETR:通过两阶段检测的方式,选择第一阶段预测的高分区域提案作为第二阶段解码器的对象查询。
EXPERIMENT
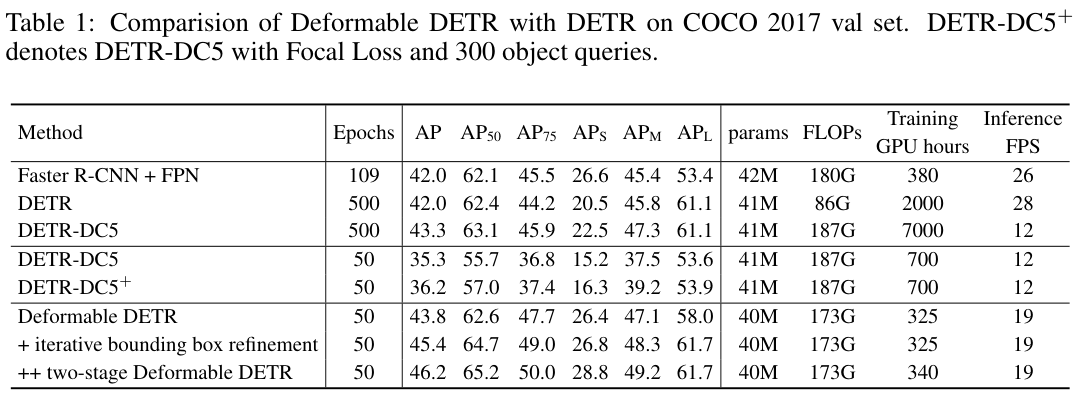
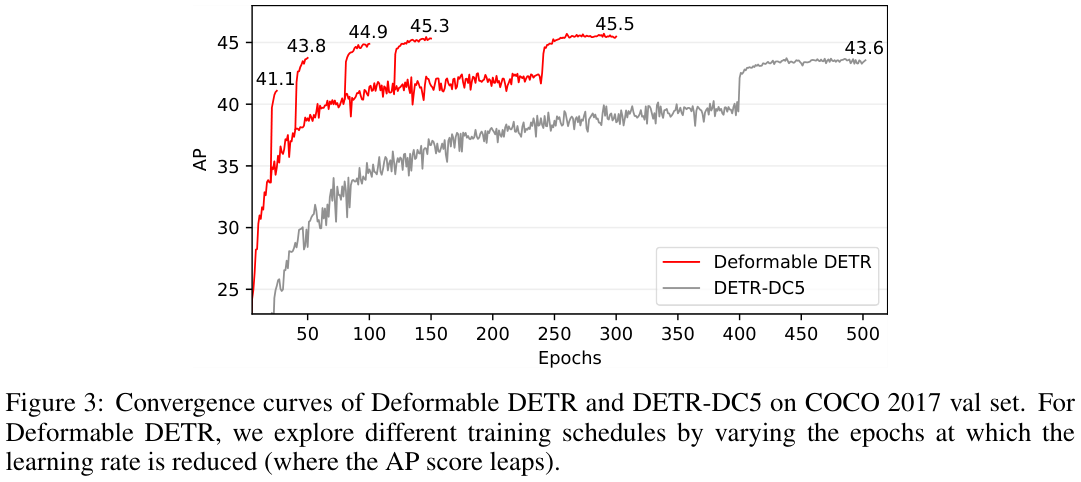
表 1 展示了与Faster R-CNN+FPN、DETR的性能对比。
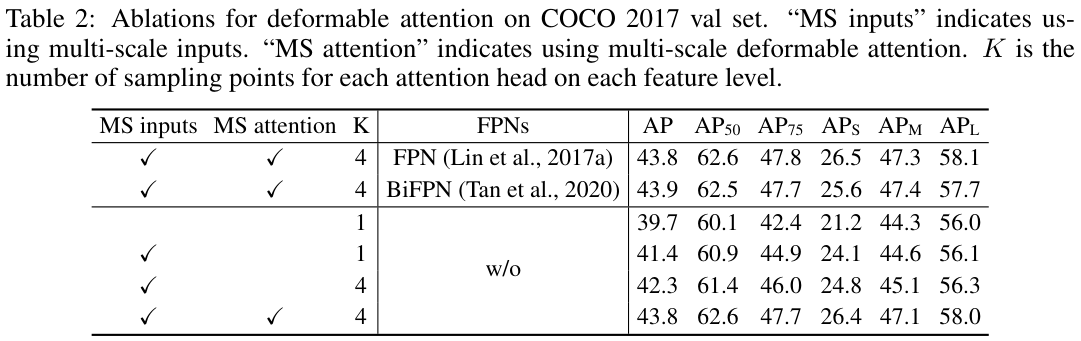
表 2 列出了所提出的可变形注意模块的各种设计选择的消融实验。
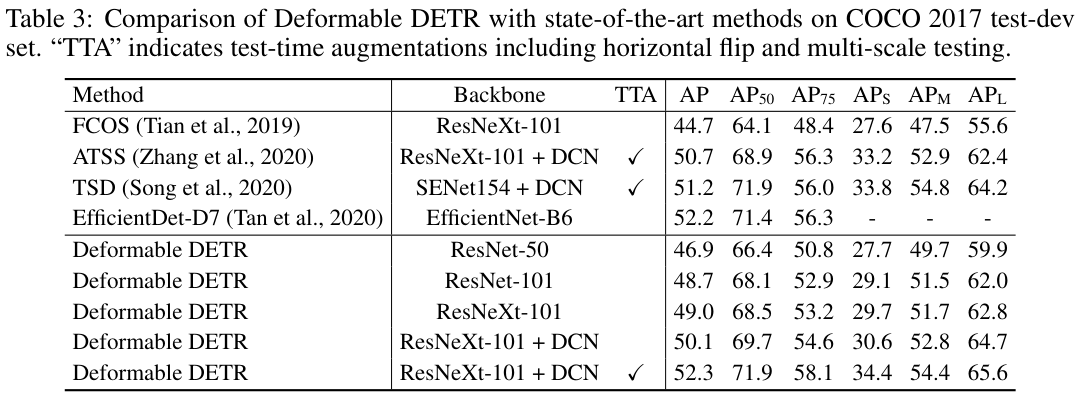
表 3 与其他最先进的方法进行了比较。
如果本文对你有帮助,麻烦点个赞或在看呗~undefined更多内容请关注 微信公众号【晓飞的算法工程笔记】
Deformable DETR:商汤提出可变型 DETR,提点又加速 | ICLR 2021 Oral的更多相关文章
- 商汤提出解偶检测中分类和定位分支的新方法TSD,COCO 51.2mAP | CVPR 2020
目前很多研究表明目标检测中的分类分支和定位分支存在较大的偏差,论文从sibling head改造入手,跳出常规的优化方向,提出TSD方法解决混合任务带来的内在冲突,从主干的proposal中学习不同的 ...
- 旷视向左、商汤向右,AI一哥之名将落谁家
编辑 | 于斌 出品 | 于见(mpyujian) AI风口历经多年洗礼之后,真正意义上的AI第一股终于要来了. 相比于聚焦在语音识别技术上的科大讯飞.立足互联网产业的百度.发力人形机器人领域的优必选 ...
- 商汤科技汤晓鸥:其实不存在AI行业,唯一存在的是“AI+“行业
https://mp.weixin.qq.com/s/bU-TFh8lBAF5L0JrWEGgUQ 9 月 17 日,2018 世界人工智能大会在上海召开,在上午主论坛大会上,商汤科技联合创始人汤晓鸥 ...
- 2019 计蒜之道 初赛 第一场 商汤AI园区的n个路口(中等) (树形dp)
北京市商汤科技开发有限公司建立了新的 AI 人工智能产业园,这个产业园区里有 nn 个路口,由 n - 1n−1 条道路连通.第 ii 条道路连接路口 u_iui 和 v_ivi. 每个路口都布有 ...
- 计蒜客 第四场 C 商汤科技的行人检测(中等)平面几何好题
商汤科技近日推出的 SenseVideo 能够对视频监控中的对象进行识别与分析,包括行人检测等.在行人检测问题中,最重要的就是对行人移动的检测.由于往往是在视频监控数据中检测行人,我们将图像上的行人抽 ...
- 商汤开源的mmdetection技术报告
目录 1. 简介 2. 支持的算法 3. 框架与架构 6. 相关链接 前言:让我惊艳的几个库: ultralytics的yolov3,在一众yolov3的pytorch版本实现算法中脱颖而出,收到开发 ...
- 面试 | 商汤科技面试经历之Promise红绿灯的实现
说在前面 说实话,刚开始在听到这个面试题的实话,我是诧异的,红绿灯?这不是单片机.FPGA.F28335.PLC的实验吗?! 而且还要用Promise去写,当时我确实没思路,只好硬着头皮去写,下来再r ...
- SenseTime Ace Coder Challenge 暨 商汤在线编程挑战赛 A. 地铁站
//其实比赛的时候就想到这方法了,但看到数据太吓人,就没写//看着标程,实际上就是这方法,太坑爹…… /* 假设值为k,对于图中任意两点,圆1半径k/t1,圆2半径k/t2 圆1与圆2的交集为可以设置 ...
- SenseTime Ace Coder Challenge 暨 商汤在线编程挑战赛 D. 白色相簿
从某一点开始,以层次遍历的方式建树若三点a.b.c互相连接,首先必先经过其中一点a,然后a可以拓展b.c两点,b.c两点的高度是相同的,若b(c)拓展时找到高度与之相同的点,则存在三点互相连接 //等 ...
- SenseTime Ace Coder Challenge 暨 商汤在线编程挑战赛 E. 疯狂计数
1.改高精度 :float/double的精度为x位,小数部分最多x+x位(乘法和加法),整数部分<1000000*1000000/2=5 * 10^11 2.分成整数部分和小数部分分别存储,貌 ...
随机推荐
- Java与React轻松导出Excel/PDF数据
前言 在B/S架构中,服务端导出是一种高效的方式.它将导出的逻辑放在服务端,前端仅需发起请求即可.通过在服务端完成导出后,前端再下载文件完成整个导出过程.服务端导出具有许多优点,如数据安全.适用于大规 ...
- python selenium使用无头模式执行用例
什么是无头模式? Headless Browser模式是浏览器的无界面状态,即在不打开浏览器界面的情况下使用浏览器. 该模式的好处如下: 1)可以加快web自动化测试的执行时间,对于web自动化测试, ...
- BST-splay板子 - 维护一个分裂和合并的序列
splay 均摊复杂度 \(O(\log n)\) 证明: https://www.cnblogs.com/Mr-Spade/p/9715203.html 我这个 splay 有两个哨兵节点,分别是1 ...
- openEuler 20.04 TLS3 上的 Python3.11.9 源码一键构建安装
#! /bin/bash # filename: python-instaler.sh SOURCE_PATH=/usr/local/source # 下载源码包 mkdir -p $SOURCE_P ...
- PetaLinux常用命令汇总
创建petalinux工程 Create a new project from a reference BSP file. 用于从官方下载的BSP中抽取数据产生工程. petalinux-create ...
- 使用flume将数据sink到kafka
flume采集过程: #说明:案例是flume监听目录/home/hadoop/flume_kafka采集到kafka: 启动集群 启动kafka, 启动agent,flume-ng agent -c ...
- FFmpeg开发笔记(三十五)Windows环境给FFmpeg集成libsrt
<FFmpeg开发实战:从零基础到短视频上线>一书的"10.2 FFmpeg推流和拉流"提到直播行业存在RTSP和RTMP两种常见的流媒体协议.除此以外,还有比较两 ...
- Spring学习篇
什么是Spring? Spring是一个轻量级的IoC和AOP容器框架.是为Java应用程序提供基础性服务的一套框架,目的是用于简化企业应用程序的开发,它使得开发者只需要关心业务需求. 常见的配置方式 ...
- RK3588开发笔记(四):基于定制的RK3588一体主板升级镜像
前言 方案商定制的主板,加入了360°环视算法功能,涉及到了一些库的添加,重新制作了依赖库的镜像,镜像更新的原来的板子上. 定制的板子 升级接口type-c 设计接口是type-c, ...
- 洛谷P3009
#include<iostream> #include<utility> using namespace std; typedef long long ll; #define ...