Android 12(S) MultiMedia Learning(十)ACodec & OMX
这一节的学习分为三块内容,omx hidl service用法、OMX架构、ACodec中的buffer分配。
1、omx hidl service
system可以借助vndbinder来访问vendor分区的内容,这里以omx hidl service为例子学习下hidl代码要如何阅读使用。
相关代码路径:
hardware/interfaces/media/omx/1.0/IOmx.hal
frameworks/av/media/libstagefright/omx/1.0/Omx.cpp
frameworks/av/services/mediacodec/main_codecservice.cpp
frameworks/av/media/libstagefright/OMXClient.cpp
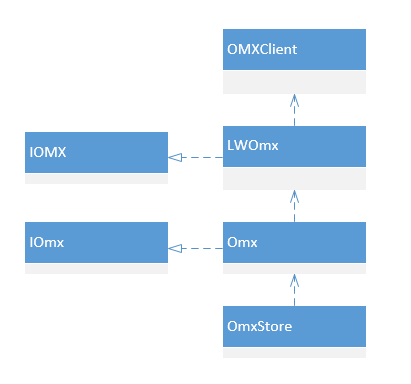
IOmx.hal中定义相关的接口,编译之后会在out/soong/.intermediates下生成相关的.h以及.cpp文件
Omx.cpp中会有接口的实现
main_codecservice.cpp用于启动服务,registerAsService声明在hidl生成文件中
OMXClient 获取IOmx服务,IOmx::getService声明在hidl生成文件中
2、OMX架构
2.1、获取IOmx服务
// ACodec.cpp
OMXClient client;
if (client.connect(owner.c_str()) != OK) {
mCodec->signalError(OMX_ErrorUndefined, NO_INIT);
return false;
}
omx = client.interface(); // OMXClient.cpp
status_t OMXClient::connect(const char* name) {
using namespace ::android::hardware::media::omx::V1_0;
if (name == nullptr) {
name = "default";
}
sp<IOmx> tOmx = IOmx::getService(name);
if (tOmx.get() == nullptr) {
ALOGE("Cannot obtain IOmx service.");
return NO_INIT;
}
if (!tOmx->isRemote()) {
ALOGE("IOmx service running in passthrough mode.");
return NO_INIT;
}
mOMX = new utils::LWOmx(tOmx);
ALOGI("IOmx service obtained");
return OK;
}
这里的代码还算简单,利用OMXClient的connect方法来获取IOmx服务,然后封装到LWOmx当中。
LWOmx定义在 frameworks/av/media/libmedia/include/media/omx/1.0/WOmx.h,继承于IOMX,注意这里并不是一个binder对象!为什么要把IOmx封装到LWOmx中呢?看LWOmx的实现就知道了,LWOmx帮我们隐藏了hidl调用的细节(比如hidl callback),让调用更简单。
2.2、服务的使用
这里以allocateNode方法为例子来看看OMX的架构。
// ACodec.cpp
sp<CodecObserver> observer = new CodecObserver(notify);
sp<IOMXNode> omxNode;
err = omx->allocateNode(componentName.c_str(), observer, &omxNode);
参数传递了一个CodecObserver对象和一个IOMXNode对象。CodecObserver继承于BnOMXObserver,BnOMXObserver声明在IOMX.h当中;IOMXMode同样声明在IOMX.h当中。
// WOmx.cpp
status_t LWOmx::allocateNode(
char const* name,
sp<IOMXObserver> const& observer,
sp<IOMXNode>* omxNode) {
status_t fnStatus;
status_t transStatus = toStatusT(mBase->allocateNode(
name, new TWOmxObserver(observer),
[&fnStatus, omxNode](Status status, sp<IOmxNode> const& node) {
fnStatus = toStatusT(status);
*omxNode = new LWOmxNode(node);
}));
return transStatus == NO_ERROR ? fnStatus : transStatus;
}
LWOmx中的调用做了两个转换,IOMXObserver转TWOmxObserver,IOmxNode转LWOmxNode,乍一看很复杂!
我们先仔细看一下Omx.h中allocateNode的声明:
Return<void> allocateNode(
const hidl_string& name,
const sp<IOmxObserver>& observer,
allocateNode_cb _hidl_cb) override;
传入参数为IOmxObserver,注意它和我们看到的ACodec和IOMX.h中的IOMXObserver是完全不同的,看他们的名字中的"omx"的大小写,IOmx这是在hal中声明的,而IOMX是其他地方声明的binder对象。
IOmxObserver的接口实现为TWOmxObserver,为了传递IOMXObserver对象,TWOmxObserver中封装了一个IOMXObserver对象
// frameworks/av/media/libmedia/include/media/omx/1.0/WOmxObserver.h
struct TWOmxObserver : public IOmxObserver {
sp<IOMXObserver> mBase;
TWOmxObserver(sp<IOMXObserver> const& base);
Return<void> onMessages(const hidl_vec<Message>& tMessages) override;
};
这里注意在stagefright目录下也有一个WOmxObserver.h,这两个看起来内容很像但也是完全不同的,从命名空间来看stagefright目录下的都是hidl接口的实现,media目录下的作为工具类使用。
同样的IOmxNode 和 IOMXNode的关系也一样,callback拿回来的是一个hidl对象,通过LWOmxNode封装为一个binder对象给上层使用。
接下来看看Omx.cpp中的allocateNode实现具体是怎么做的:
Return<void> Omx::allocateNode(
const hidl_string& name,
const sp<IOmxObserver>& observer,
allocateNode_cb _hidl_cb) { using ::android::IOMXNode;
using ::android::IOMXObserver; sp<OMXNodeInstance> instance;
{
// 1、检查实例数量
Mutex::Autolock autoLock(mLock);
if (mLiveNodes.size() == kMaxNodeInstances) {
_hidl_cb(toStatus(NO_MEMORY), nullptr);
return Void();
}
// 2、创建OMXNodeInstance
instance = new OMXNodeInstance(
this, new LWOmxObserver(observer), name.c_str()); OMX_COMPONENTTYPE *handle;
// 3、创建Component
OMX_ERRORTYPE err = mStore->makeComponentInstance(
name.c_str(), &OMXNodeInstance::kCallbacks,
instance.get(), &handle);
// ......
// 4、把component交给OMXNodeInstance管理
instance->setHandle(handle); // 5、从xml查找quirks
// Find quirks from mParser
const auto& codec = mParser.getCodecMap().find(name.c_str());
if (codec == mParser.getCodecMap().cend()) {
// ......
} else {
uint32_t quirks = 0;
for (const auto& quirk : codec->second.quirkSet) {
if (quirk == "quirk::requires-allocate-on-input-ports") {
quirks |= OMXNodeInstance::
kRequiresAllocateBufferOnInputPorts;
}
if (quirk == "quirk::requires-allocate-on-output-ports") {
quirks |= OMXNodeInstance::
kRequiresAllocateBufferOnOutputPorts;
}
}
instance->setQuirks(quirks);
}
// 6、添加OMXNodeInstance到IOmx服务管理列表中
mLiveNodes.add(observer.get(), instance);
mNode2Observer.add(instance.get(), observer.get());
}
observer->linkToDeath(this, 0);
// callback将OMXNodeInstance返回给上层
_hidl_cb(toStatus(OK), new TWOmxNode(instance));
return Void();
}
第二步创建OMXNodeInstance时会把传进来的TWOmxObserver转为LWOmxObserver,这里用到LWOmxObserver声明在stagefright目录中。
OMXNodeInstance的创建和OMXStore的makeComponentInstance方法这里不做展开,比较简单。
IOMXNode调用某个方法的过程:
IOMXNode -> LWOmxNode -> TWOmxNode -> OMXNodeInstance
IOMXObserver的回调过程:
IOMXObserver -> LWOmxObserver -> TWOmxObserver -> CodecObserver
3、ACodec中的buffer分配
先看一下mPortMode,分为kPortIndexInput和kPortIndexOutput
mPortMode会在构造函数中被初始化为IOMX::kPortModePresetByteBuffer,configureCodec过程中可能会被修改为其他值,看看都有哪些情况:
encoder:
1、会判断Message中是否有"android._input-metadata-buffer-type" tag,如果有则置为kPortIndexInput对应值,如果没有就置kPortIndexInput为IOMX::kPortModePresetByteBuffer
2、如果是video,并且需要secure mode,设定kPortIndexOutput为IOMX::kPortModePresetSecureBuffer,否则保持为IOMX::kPortModePresetByteBuffer
decoder:
1、需要secure mode,设定kPortIndexInput为IOMX::kPortModePresetSecureBuffer,否则保持为IOMX::kPortModePresetByteBuffer
2、如果有surface
tunnel mode,kPortIndexOutput设定为IOMX::kPortModePresetANWBuffer,同时会调用configureTunneledVideoPlayback
非tunnel mode,kPortIndexOutput设定为IOMX::kPortModeDynamicANWBuffer
没有surface,kPortIndexOutput保持为IOMX::kPortModePresetByteBuffer
3、如果是视频
组件使用的是OMX.google开头的软解组件,kPortIndexOutput保持为IOMX::kPortModePresetByteBuffer
到allocateBuffersOnPort时(暂时只讨论decoder)
1、kPortIndexOutput
1.1、有surface
1.1.1、非tunnel mode
allocateOutputMetadataBuffers分配buffer
// ACodec.cpp
status_t ACodec::allocateOutputMetadataBuffers() {
OMX_U32 bufferCount, bufferSize, minUndequeuedBuffers;
status_t err = configureOutputBuffersFromNativeWindow(
&bufferCount, &bufferSize, &minUndequeuedBuffers,
mFlags & kFlagPreregisterMetadataBuffers /* preregister */);
if (err != OK)
return err;
mNumUndequeuedBuffers = minUndequeuedBuffers; for (OMX_U32 i = 0; i < bufferCount; i++) {
BufferInfo info;
info.mStatus = BufferInfo::OWNED_BY_NATIVE_WINDOW;
info.mFenceFd = -1;
info.mRenderInfo = NULL;
info.mGraphicBuffer = NULL;
info.mNewGraphicBuffer = false;
info.mDequeuedAt = mDequeueCounter; info.mData = new MediaCodecBuffer(mOutputFormat, new ABuffer(bufferSize)); ((VideoNativeMetadata *)info.mData->base())->nFenceFd = -1; info.mCodecData = info.mData;
// useBuffer
err = mOMXNode->useBuffer(kPortIndexOutput, OMXBuffer::sPreset, &info.mBufferID);
mBuffers[kPortIndexOutput].push(info); ALOGV("[%s] allocated meta buffer with ID %u",
mComponentName.c_str(), info.mBufferID);
} mMetadataBuffersToSubmit = bufferCount - minUndequeuedBuffers;
return err;
}
useBuffer传入参数为OMXBuffer::sPreset,查看OMXBuffer代码后看到其实是:
OMXBuffer OMXBuffer::sPreset(static_cast<sp<MediaCodecBuffer> >(NULL));
OMXBuffer::OMXBuffer(const sp<MediaCodecBuffer>& codecBuffer)
: mBufferType(kBufferTypePreset),
mRangeOffset(codecBuffer != NULL ? codecBuffer->offset() : 0),
mRangeLength(codecBuffer != NULL ? codecBuffer->size() : 0) {
}
到OMXNodeInstance
status_t OMXNodeInstance::useBuffer(
OMX_U32 portIndex, const OMXBuffer &omxBuffer, IOMX::buffer_id *buffer) {
switch (omxBuffer.mBufferType) {
case OMXBuffer::kBufferTypePreset: {
if (mPortMode[portIndex] != IOMX::kPortModeDynamicANWBuffer
&& mPortMode[portIndex] != IOMX::kPortModeDynamicNativeHandle) {
break;
}
return useBuffer_l(portIndex, NULL, NULL, buffer);
}
}
进入到useBuffer_l 发现有OMX_AllocateBuffer 和 OMX_UseBuffer两个选择。先看mMetaDataType,它是在setPortMode时被重新设定值,在这种情况下会被设定为kMetadataBufferTypeANWBuffer
bool isOutputGraphicMetadata = (portIndex == kPortIndexOutput) &&
(mMetadataType[portIndex] == kMetadataBufferTypeGrallocSource ||
mMetadataType[portIndex] == kMetadataBufferTypeANWBuffer);
isOutputGraphicMetaData为true,所以第一个条件不满足,使用OMX_UseBuffer,isMetaData为true
if (isMetadata) {
data = new (std::nothrow) OMX_U8[allottedSize];
if (data == NULL) {
return NO_MEMORY;
}
memset(data, 0, allottedSize);
buffer_meta = new BufferMeta(
params, hParams, portIndex, false /* copy */, data);
}
err = OMX_UseBuffer(
mHandle, &header, portIndex, buffer_meta,
allottedSize, data);
到这儿发现,用于创建BufferMeta的IMemory和IHidlMemory都是null,真正用于BufferMeta的是重新分配的一块buffer,说明在ACodec中创建的buffer 并没有通过OMX_UseBuffer往下传递。回到ACodec中创建BufferInfo的地方看mStatus为OWNED_BY_NATIVE_WINDOW,意思就是真正的output buffer并不是由上层创建。所以在这种情况下播放时,上层通过getBuffer获取的output buffer中是没有数据的。
1.1.2、tunnel mode
allocateOutputBuffersFromNativeWindow分配buffer
status_t ACodec::allocateOutputBuffersFromNativeWindow() {
OMX_U32 bufferCount, bufferSize, minUndequeuedBuffers;
status_t err = configureOutputBuffersFromNativeWindow(
&bufferCount, &bufferSize, &minUndequeuedBuffers, true /* preregister */);
if (err != 0)
return err;
mNumUndequeuedBuffers = minUndequeuedBuffers;
static_cast<Surface*>(mNativeWindow.get())
->getIGraphicBufferProducer()->allowAllocation(true);
// Dequeue buffers and send them to OMX
for (OMX_U32 i = 0; i < bufferCount; i++) {
ANativeWindowBuffer *buf;
int fenceFd;
err = mNativeWindow->dequeueBuffer(mNativeWindow.get(), &buf, &fenceFd);
if (err != 0) {
ALOGE("dequeueBuffer failed: %s (%d)", strerror(-err), -err);
break;
}
sp<GraphicBuffer> graphicBuffer(GraphicBuffer::from(buf));
BufferInfo info;
info.mStatus = BufferInfo::OWNED_BY_US;
info.mFenceFd = fenceFd;
info.mIsReadFence = false;
info.mRenderInfo = NULL;
info.mGraphicBuffer = graphicBuffer;
info.mNewGraphicBuffer = false;
info.mDequeuedAt = mDequeueCounter;
info.mData = new MediaCodecBuffer(mOutputFormat, new ABuffer(bufferSize));
info.mCodecData = info.mData;
mBuffers[kPortIndexOutput].push(info);
IOMX::buffer_id bufferId;
err = mOMXNode->useBuffer(kPortIndexOutput, graphicBuffer, &bufferId);
if (err != 0) {
ALOGE("registering GraphicBuffer %u with OMX IL component failed: "
"%d", i, err);
break;
}
mBuffers[kPortIndexOutput].editItemAt(i).mBufferID = bufferId;
}
OMX_U32 cancelStart;
OMX_U32 cancelEnd;
if (err != OK) {
cancelStart = 0;
cancelEnd = mBuffers[kPortIndexOutput].size();
} else {
cancelStart = bufferCount - minUndequeuedBuffers;
cancelEnd = bufferCount;
}
for (OMX_U32 i = cancelStart; i < cancelEnd; i++) {
BufferInfo *info = &mBuffers[kPortIndexOutput].editItemAt(i);
if (info->mStatus == BufferInfo::OWNED_BY_US) {
status_t error = cancelBufferToNativeWindow(info);
if (err == 0) {
err = error;
}
}
}
static_cast<Surface*>(mNativeWindow.get())
->getIGraphicBufferProducer()->allowAllocation(false);
return err;
}
这里面UseBuffer的参数为GraphicBuffer,参考OMXBuffer代码:
OMXBuffer::OMXBuffer(const sp<GraphicBuffer> &gbuf)
: mBufferType(kBufferTypeANWBuffer),
mGraphicBuffer(gbuf) {
}
tunnel mode下portmode[out]是IOMX::kPortModePresetANWBuffer,这个portMode的设置比较隐蔽:
else if (!storingMetadataInDecodedBuffers()) {
err = setPortMode(kPortIndexOutput, IOMX::kPortModePresetANWBuffer);
if (err != OK) {
return err;
}
}
进入到UseBuffer中,根据BufferType判断会走到useGraphicBuffer_l
case OMXBuffer::kBufferTypeANWBuffer: {
if (mPortMode[portIndex] != IOMX::kPortModePresetANWBuffer
&& mPortMode[portIndex] != IOMX::kPortModeDynamicANWBuffer) {
break;
}
return useGraphicBuffer_l(portIndex, omxBuffer.mGraphicBuffer, buffer);
}
mMetadataType在setPortMode时被置为了kMetadataBufferTypeANWBuffer,进入到useGraphicBuffer_l看到
if (mMetadataType[portIndex] != kMetadataBufferTypeInvalid) {
return useGraphicBufferWithMetadata_l(
portIndex, graphicBuffer, buffer);
}
所以进到useGraphicBufferWithMetadata_l,
status_t OMXNodeInstance::useGraphicBufferWithMetadata_l(
OMX_U32 portIndex, const sp<GraphicBuffer> &graphicBuffer,
IOMX::buffer_id *buffer) {
if (portIndex != kPortIndexOutput) {
return BAD_VALUE;
} if (mMetadataType[portIndex] != kMetadataBufferTypeGrallocSource &&
mMetadataType[portIndex] != kMetadataBufferTypeANWBuffer) {
return BAD_VALUE;
} status_t err = useBuffer_l(portIndex, NULL, NULL, buffer);
if (err != OK) {
return err;
} OMX_BUFFERHEADERTYPE *header = findBufferHeader(*buffer, portIndex); return updateGraphicBufferInMeta_l(portIndex, graphicBuffer, *buffer, header); }
看来还是进入到了useBuffer_l当中,isOutputGraphicMetadata为true,isMetadata为true,所以使用的是OMX_UseBuffer
if (isMetadata) {
data = new (std::nothrow) OMX_U8[allottedSize];
if (data == NULL) {
return NO_MEMORY;
}
memset(data, 0, allottedSize);
buffer_meta = new BufferMeta(
params, hParams, portIndex, false /* copy */, data);
}
err = OMX_UseBuffer(
mHandle, &header, portIndex, buffer_meta,
allottedSize, data);
好家伙,看到这里发现和之前非tunnel mode是一样的,但是出了useBuffer_l,再回到useGraphicBufferWithMetadata_l,看到还有一个函数updateGraphicBufferInMeta_l:
BufferMeta *bufferMeta = (BufferMeta *)(header->pAppPrivate);
sp<ABuffer> data = bufferMeta->getBuffer(header, false /* limit */);
bufferMeta->setGraphicBuffer(graphicBuffer); else if (metaType == kMetadataBufferTypeANWBuffer
&& data->capacity() >= sizeof(VideoNativeMetadata)) {
VideoNativeMetadata &metadata = *(VideoNativeMetadata *)(data->data());
metadata.eType = kMetadataBufferTypeANWBuffer;
metadata.pBuffer = graphicBuffer == NULL ? NULL : graphicBuffer->getNativeBuffer();
metadata.nFenceFd = -1;
}
这里看到把OMX_BUFFERHEADERTYPE中的BufferMeta和上层传来的graphicBuffer做了关联,OMX和graphic公用一块buffer,由于graphicBuffer是在ACodec创建,所以mStatus值为OWNED_BY_US
1.2、无surface
无surface的情况与Input的普通模式相同
2、kPortIndexInput
2.1、no secure
使用的是hidl_memory
hidl_memory hidlMemToken; auto transStatus = mAllocator[portIndex]->allocate(
bufSize,
[&success, &hidlMemToken](
bool s,
hidl_memory const& m) {
success = s;
hidlMemToken = m;
}); err = mOMXNode->useBuffer(
portIndex, hidlMemToken, &info.mBufferID);
看看BufferType
OMXBuffer::OMXBuffer(const hidl_memory &hidlMemory)
: mBufferType(kBufferTypeHidlMemory),
mHidlMemory(hidlMemory) {
}
进入到UseBuffer中,此时portMode为kPortModePresetByteBuffer
case OMXBuffer::kBufferTypeHidlMemory: {
if (mPortMode[portIndex] != IOMX::kPortModePresetByteBuffer
&& mPortMode[portIndex] != IOMX::kPortModeDynamicANWBuffer
&& mPortMode[portIndex] != IOMX::kPortModeDynamicNativeHandle) {
break;
}
sp<IHidlMemory> hidlMemory = mapMemory(omxBuffer.mHidlMemory);
if (hidlMemory == nullptr) {
ALOGE("OMXNodeInstance useBuffer() failed to map memory");
return NO_MEMORY;
}
return useBuffer_l(portIndex, NULL, hidlMemory, buffer);
}
mMetadataType在setPortMode时被置为kMetadataBufferTypeInvalid,进入到useBuffer_l中:
isMetaData为false,isOutputGraphicMetadata为false,这时候看到if中有关于Quirks的判断
uint32_t requiresAllocateBufferBit =
(portIndex == kPortIndexInput)
? kRequiresAllocateBufferOnInputPorts
: kRequiresAllocateBufferOnOutputPorts; // we use useBuffer for output metadata regardless of quirks
if (!isOutputGraphicMetadata && (mQuirks & requiresAllocateBufferBit))
Quirks一般定义在media_codecs.xml中,译为怪癖模式,在其他地方找到可以翻译为兼容模式,示例如下:
42 <MediaCodec name="OMX.foo.bar" >
43 <Type name="something/interesting" />
44 <Type name="something/else" />
45 ...
46 <Quirk name="requires-allocate-on-input-ports" />
47 <Quirk name="requires-allocate-on-output-ports" />
48 <Quirk name="output-buffers-are-unreadable" />
49 </MediaCodec>
这种情况下,codec xml中如果定义有Quirk则进入到OMX_AllocateBuffer当中,没有定义Quirk则使用OMX_UseBuffer
a. OMX_AllocateBuffer
if (!isOutputGraphicMetadata && (mQuirks & requiresAllocateBufferBit)) {
buffer_meta = new BufferMeta(
params, hParams, portIndex, !isMetadata /* copy */, NULL /* data */);
err = OMX_AllocateBuffer(
mHandle, &header, portIndex, buffer_meta, allottedSize);
}
利用传下来的IHidlMemory创建BufferMeta,第四个参数copy为true,这里看看BufferMeta的构造函数:
explicit BufferMeta(
const sp<IMemory> &mem, const sp<IHidlMemory> &hidlMemory,
OMX_U32 portIndex, bool copy, OMX_U8 *backup)
: mMem(mem),
mHidlMemory(hidlMemory),
mCopyFromOmx(portIndex == kPortIndexOutput && copy),
mCopyToOmx(portIndex == kPortIndexInput && copy),
mPortIndex(portIndex),
mBackup(backup) {
}
copy为true会让mCopyToOMX或者mCopyFromOMX置为true,他们的作用就是使能copy,例如CopyToOMX,就是从上层的buffer中copy数据到OMX OMX_BUFFERHEADERTYPE
中,这个方法会在emptyBuffer_l中调用到
void CopyToOMX(const OMX_BUFFERHEADERTYPE *header) {
if (!mCopyToOmx) {
return;
}
memcpy(header->pBuffer + header->nOffset,
getPointer() + header->nOffset,
header->nFilledLen);
}
另外再看一下buffer的所有者是OWNED_BY_US
b. OMX_UseBuffer
看到创建BufferMeta时,copy都为false,不允许数据拷贝,decoder拿不到数据,上层也拿到解码后的数据,这明显是不对的。
2.2、secure mode
这时候portMode为kPortModePresetSecureBuffer,直接调用OMXNodeInstance的allocateSecureBuffer获取一个NativeHandle,BufferInfo中的data使用的睡觉哦SecureBuffer
if (mode == IOMX::kPortModePresetSecureBuffer) {
void *ptr = NULL;
sp<NativeHandle> native_handle;
err = mOMXNode->allocateSecureBuffer(
portIndex, bufSize, &info.mBufferID,
&ptr, &native_handle);
info.mData = (native_handle == NULL)
? new SecureBuffer(format, ptr, bufSize)
: new SecureBuffer(format, native_handle, bufSize);
info.mCodecData = info.mData;
}
进入到OMXNodeInstance看到allocateSecureBuffer并不复杂,创建一个BufferMeta,其中不带任何上层的buffer,之后直接调用OMX_AllocateBuffer创建一个OMX_BUFFERHEADERTYPE,返回给上层的是用BufferHeader创建的NativeHandle
BufferMeta *buffer_meta = new BufferMeta(portIndex);
OMX_BUFFERHEADERTYPE *header;
OMX_ERRORTYPE err = OMX_AllocateBuffer(
mHandle, &header, portIndex, buffer_meta, size);
if (mSecureBufferType[portIndex] == kSecureBufferTypeNativeHandle) {
*buffer_data = NULL;
*native_handle = NativeHandle::create(
(native_handle_t *)header->pBuffer, false /* ownsHandle */);
} else {
*buffer_data = header->pBuffer;
*native_handle = NULL;
}
上层ACodec用返回的NativeHandle创建一个SecureBuffer,这里面buffer是怎么连通的,可以阅读OMXNodeInstance::emptyBuffer的第三个case,最后其实还是调用的emptyBuffer_l。
到这里Buffer的分配大概就了解结束,做一个总结:
Input
non secure:上层分配一块hidl memory,omxnode中创建一个BufferMeta,调用OMX_AllocateBuffer在创建OMX_BUFFERHEADERTYPE(暂不了解BufferMeta在该方法中做什么用),允许BufferMeta与OMX_BUFFERHEADERTYPE中的buffer相互做数据拷贝。
secure:调用OMX_AllocateBuffer返回一个NativeHandle,用这个handle创建SecureBuffer
Output
无surface,与input non secure相同
有surface
non tunnel
上层创建的buffer并不与底层相关联,上层无法获取到ouput data,omxNode中会重新创建一块buffer,利用这块buffer创建BufferMeta,并调用OMX_UseBuffer。既然output data并没有送给上层,那么渲染肯定是另有途径
tunnel mode
上层从graphic获取buffer,omxNode同样也会创建一块buffer,并调用OMX_UseBuffer,但是之后会把graphic buffer与OMX_BUFFERHEADERTYPE相关联,output data直接送给graphic
Android 12(S) MultiMedia Learning(十)ACodec & OMX的更多相关文章
- Android 12(S) 图形显示系统 - 解读Gralloc架构及GraphicBuffer创建/传递/释放(十四)
必读: Android 12(S) 图形显示系统 - 开篇 一.前言 在前面的文章中,已经出现过 GraphicBuffer 的身影,GraphicBuffer 是Android图形显示系统中的一个重 ...
- Android 12(S) 图形显示系统 - BufferQueue的工作流程(十)
题外话 疫情隔离在家,周末还在努力学习的我 ..... 一.前言 上一篇文章中,有基本讲清楚Producer一端的处理逻辑,最后也留下了一个疑问: Consumer是什么时候来消费数据的?他是自己主 ...
- Android 12(S) 图形显示系统 - Surface 一点补充知识(十二)
必读: Android 12(S) 图形显示系统 - 开篇 一.前言 因为个人工作主要是Android多媒体播放的内容,在工作中查看源码或设计程序经常会遇到调用API: static inline i ...
- Android 12(S) 图像显示系统 - SurfaceFlinger之VSync-上篇(十六)
必读: Android 12(S) 图像显示系统 - 开篇 一.前言 为了提高Android系统的UI交互速度和操作的流畅度,在Android 4.1中,引入了Project Butter,即&quo ...
- Android系统--输入系统(十五)实战_使用GlobalKey一键启动程序
Android系统--输入系统(十五)实战_使用GlobalKey一键启动程序 1. 一键启动的过程 1.1 对于global key, 系统会根据global_keys.xml发送消息给某个组件 & ...
- (转载)Android项目实战(二十八):使用Zxing实现二维码及优化实例
Android项目实战(二十八):使用Zxing实现二维码及优化实例 作者:听着music睡 字体:[增加 减小] 类型:转载 时间:2016-11-21我要评论 这篇文章主要介绍了Android项目 ...
- Android 12(S) 图形显示系统 - SurfaceFlinger的启动和消息队列处理机制(四)
1 前言 SurfaceFlinger作为Android图形显示系统处理逻辑的核心单元,我们有必要去了解其是如何启动,初始化及进行消息处理的.这篇文章我们就来简单分析SurfaceFlinger这个B ...
- Android 12(S) 图像显示系统 - SurfaceFlinger 之 VSync - 中篇(十七)
必读: Android 12(S) 图像显示系统 - 开篇 1 前言 这一篇文章,将继续讲解有关VSync的知识,前一篇文章 Android 12(S) 图像显示系统 - SurfaceFlinger ...
- Android系统--输入系统(十)Reader线程_核心类及配置文件深入分析
Android系统--输入系统(十)Reader线程_核心类及配置文件深入分析 0. 前言 个人认为该知识点阅读Android源代码会不仅容易走进死胡同,并且效果并不好,前脚看完后脚忘记,故进行总结, ...
- Android系统--输入系统(十二)Dispatch线程_总体框架
Android系统--输入系统(十二)Dispatch线程_总体框架 1. Dispatch线程框架 我们知道Dispatch线程是分发之意,那么便可以引入两个问题:1. 发什么;2. 发给谁.这两个 ...
随机推荐
- 知识图谱增强的KG-RAG框架
昨天我们聊到KG在RAG中如何发挥作用,今天我们来看一个具体的例子. 我们找到一篇论文: https://arxiv.org/abs/2311.17330 ,论文的研究人员开发了一种名为知识图谱增强的 ...
- HarmonyOS数据管理与应用数据持久化(二)
通过键值型数据库实现数据持久化 场景介绍 键值型数据库存储键值对形式的数据,当需要存储的数据没有复杂的关系模型,比如存储商品名称及对应价格.员工工号及今日是否已出勤等,由于数据复杂度低,更容易兼容不同 ...
- 当年老夫手写的cookie
前言 留来来只为了回忆,旧博客迁移. 正文 /** * Created by OC on 20xx/8/27. */ function setCookie(name,value,expires,pat ...
- Pytorch DistributedDataParallel(DDP)教程二:快速入门实践篇
一.简要回顾DDP 在上一篇文章中,简单介绍了Pytorch分布式训练的一些基础原理和基本概念.简要回顾如下: 1,DDP采用Ring-All-Reduce架构,其核心思想为:所有的GPU设备安排在一 ...
- 力扣852(java&python)-山脉数组的峰顶索引(中等)
题目: 符合下列属性的数组 arr 称为 山脉数组 : arr.length >= 3 存在 i(0 < i < arr.length - 1)使得: arr[0] < arr ...
- embedding models 是什么
embedding models 是一类机器学习模型,它们的核心功能是将高维.离散的输入数据(如词汇.类别标签.节点或实体)映射到低维.连续的向量空间中. 这些向量(即 embeddings)通常具有 ...
- C语言程序设计-笔记8-结构
C语言程序设计-笔记8-结构 例9-1 输出平均分最高的学生信息.根据学生的基本信息包括学号.姓名.三门课程成绩以及个人平均成绩.输入n个学生的成绩信息,计算并输出平均分最高的学生信息. #incl ...
- Fast Walsh Transform 学习笔记 | FWT
本文中使用 \(\cap\) 表示按位与,用 \(\cup\) 表示按位或 Part 1. 与/或 卷积 First. 问题引入 给定长度为 \(2^n\) 的数列 \(A,B\),求 \(C_i = ...
- THUWC2024&NOIWC2024游记
以 NOIWC 考试日为 Day 1 好了. Day -6 到重庆了.去报到,然后直接不去试机走了,这波主打一个自信. Day -5 THUWC Day1,四道传统题. 开 T1,一眼有一个 \(O( ...
- 简说Python之循环语句
目录 Python的运算逻辑 Python条件语句 Python循环语句 Python while循环 Python for 循环 条件语句和循环语句是程序常用的一种基础语法,从语言上来说,能说清楚的 ...