chatglm2-6b在P40上做LORA微调
背景:
目前,大模型的技术应用已经遍地开花。最快的应用方式无非是利用自有垂直领域的数据进行模型微调。chatglm2-6b在国内开源的大模型上,效果比较突出。本文章分享的内容是用chatglm2-6b模型在集团EA的P40机器上进行垂直领域的LORA微调。
一、chatglm2-6b介绍
github: https://github.com/THUDM/ChatGLM2-6B
chatglm2-6b相比于chatglm有几方面的提升:
1. 性能提升: 相比初代模型,升级了 ChatGLM2-6B 的基座模型,同时在各项数据集评测上取得了不错的成绩;
2. 更长的上下文: 我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练;
3. 更高效的推理: 基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%;
4. 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
二、微调环境介绍
2.1 性能要求
推理这块,chatglm2-6b在精度是fp16上只需要14G的显存,所以P40是可以cover的。
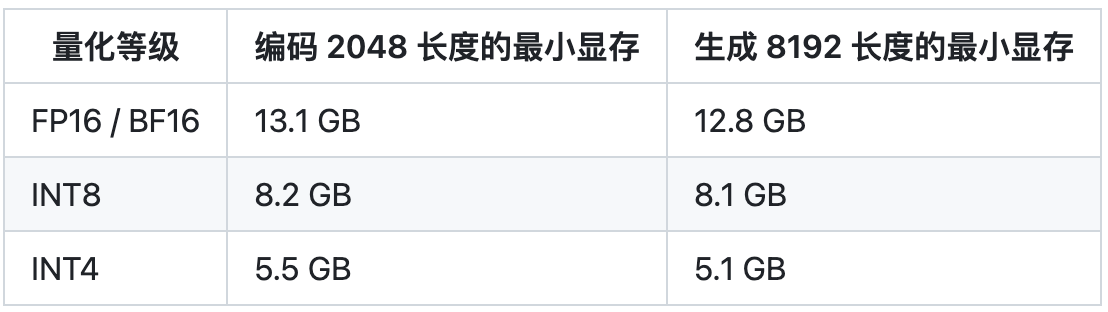
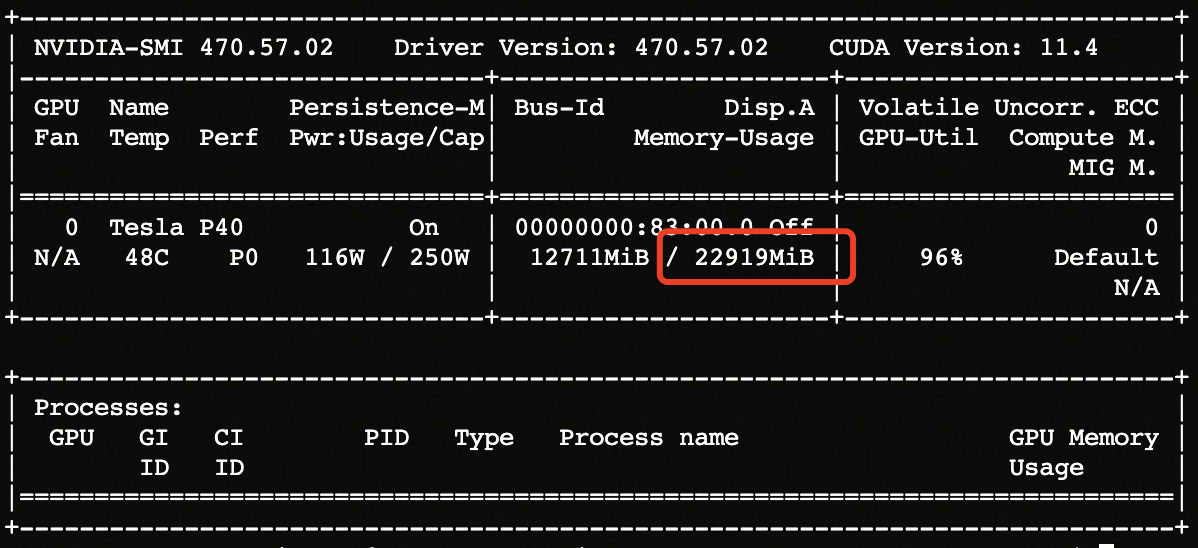
EA上P40显卡的配置如下:
2.2 镜像环境
做微调之前,需要编译环境进行配置,我这块用的是docker镜像的方式来加载镜像环境,具体配置如下:
FROM base-clone-mamba-py37-cuda11.0-gpu
# mpich
RUN yum install mpich
# create my own environment
RUN conda create -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ --override --yes --name py39 python=3.9
# display my own environment in Launcher
RUN source activate py39 \
&& conda install --yes --quiet ipykernel \
&& python -m ipykernel install --name py39 --display-name "py39"
# install your own requirement package
RUN source activate py39 \
&& conda install -y -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ \
pytorch torchvision torchaudio faiss-gpu \
&& pip install --no-cache-dir --ignore-installed -i https://pypi.tuna.tsinghua.edu.cn/simple \
protobuf \
streamlit \
transformers==4.29.1 \
cpm_kernels \
mdtex2html \
gradio==3.28.3 \
sentencepiece \
accelerate \
langchain \
pymupdf \
unstructured[local-inference] \
layoutparser[layoutmodels,tesseract] \
nltk~=3.8.1 \
sentence-transformers \
beautifulsoup4 \
icetk \
fastapi~=0.95.0 \
uvicorn~=0.21.1 \
pypinyin~=0.48.0 \
click~=8.1.3 \
tabulate \
feedparser \
azure-core \
openai \
pydantic~=1.10.7 \
starlette~=0.26.1 \
numpy~=1.23.5 \
tqdm~=4.65.0 \
requests~=2.28.2 \
rouge_chinese \
jieba \
datasets \
deepspeed \
pdf2image \
urllib3==1.26.15 \
tenacity~=8.2.2 \
autopep8 \
paddleocr \
mpi4py \
tiktoken
如果需要使用deepspeed方式来训练, EA上缺少mpich信息传递工具包,需要自己手动安装。
2.3 模型下载
huggingface地址: https://huggingface.co/THUDM/chatglm2-6b/tree/main
三、LORA微调
3.1 LORA介绍
paper: https://arxiv.org/pdf/2106.09685.pdf
LORA(Low-Rank Adaptation of Large Language Models)微调方法: 冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。
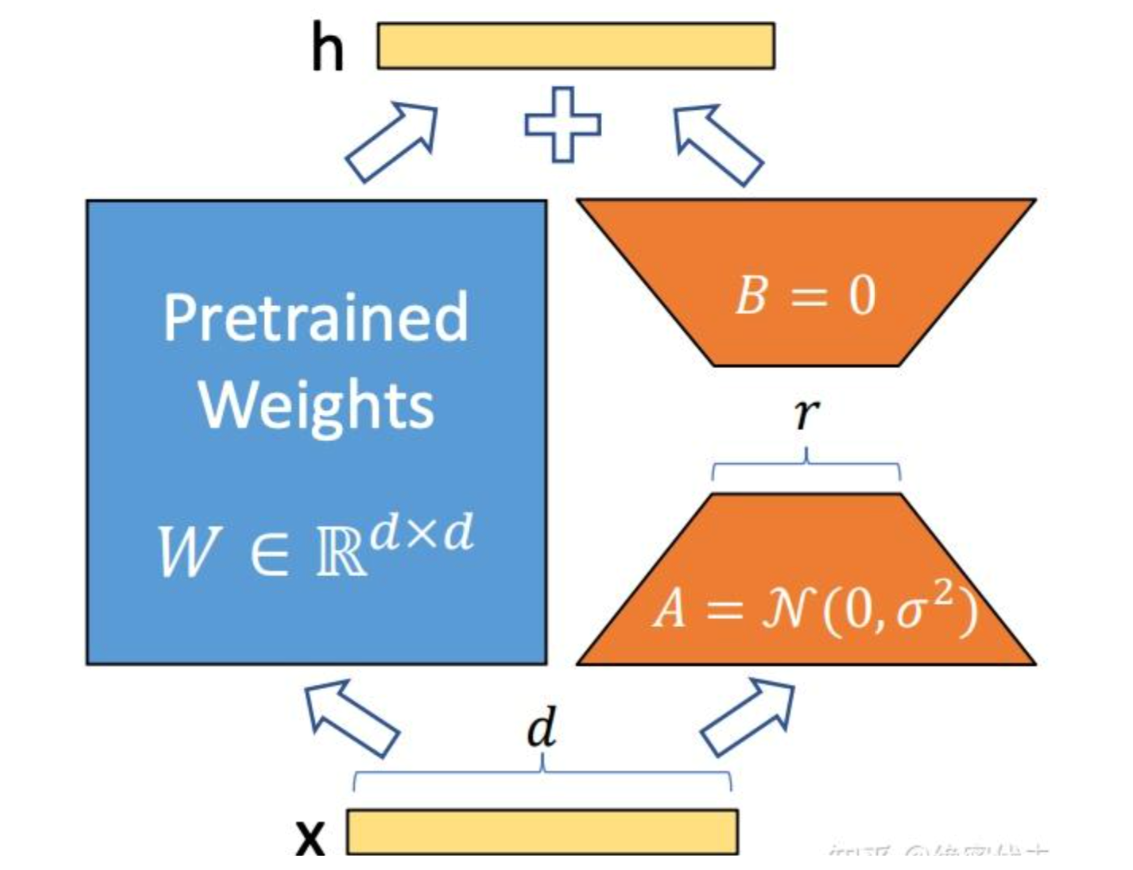
LoRA 的思想:
- 在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作。
- 训练的时候固定 PLM 的参数,只训练降维矩阵A与升维矩B。而模型的输入输出维度不变,输出时将BA与 PLM 的参数叠加。
- 用随机高斯分布初始化A,用 0 矩阵初始化B,保证训练的开始此旁路矩阵依然是 0 矩阵。
3.2 微调
huggingface提供的peft工具可以方便微调PLM模型,这里也是采用的peft工具来创建LORA。
peft的github: https://gitcode.net/mirrors/huggingface/peft?utm_source=csdn_github_accelerator
加载模型和lora微调:
# load model
tokenizer = AutoTokenizer.from_pretrained(args.model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(args.model_dir, trust_remote_code=True)
print("tokenizer:", tokenizer)
# get LoRA model
config = LoraConfig(
r=args.lora_r,
lora_alpha=32,
lora_dropout=0.1,
bias="none",)
# 加载lora模型
model = get_peft_model(model, config)
# 半精度方式
model = model.half().to(device)
这里需要注意的是,用huggingface加载本地模型,需要创建work文件,EA上没有权限在没有在.cache创建,这里需要自己先制定work路径。
import os
os.environ['TRANSFORMERS_CACHE'] = os.path.dirname(os.path.abspath(__file__))+"/work/"
os.environ['HF_MODULES_CACHE'] = os.path.dirname(os.path.abspath(__file__))+"/work/"
如果需要用deepspeed方式训练,选择你需要的zero-stage方式:
conf = {"train_micro_batch_size_per_gpu": args.train_batch_size,
"gradient_accumulation_steps": args.gradient_accumulation_steps,
"optimizer": {
"type": "Adam",
"params": {
"lr": 1e-5,
"betas": [
0.9,
0.95
],
"eps": 1e-8,
"weight_decay": 5e-4
}
},
"fp16": {
"enabled": True
},
"zero_optimization": {
"stage": 1,
"offload_optimizer": {
"device": "cpu",
"pin_memory": True
},
"allgather_partitions": True,
"allgather_bucket_size": 2e8,
"overlap_comm": True,
"reduce_scatter": True,
"reduce_bucket_size": 2e8,
"contiguous_gradients": True
},
"steps_per_print": args.log_steps
}
其他都是数据处理处理方面的工作,需要关注的就是怎么去构建prompt,个人认为在领域内做微调构建prompt非常重要,最终对模型的影响也比较大。
四、微调结果
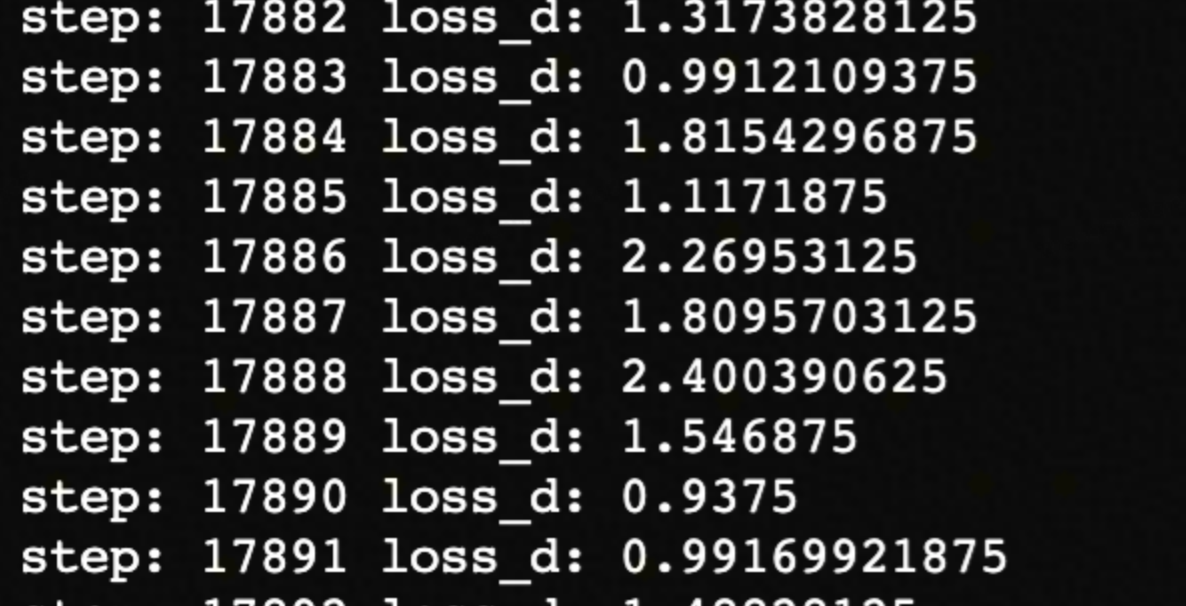
目前模型还在finetune中,batch=1,epoch=3,已经迭代一轮。
作者:京东零售 郑少强
来源:京东云开发者社区 转载请注明来源
chatglm2-6b在P40上做LORA微调的更多相关文章
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案. 请注意, ...
- Swift - 使用MapKit显示地图,并在地图上做标记
通过使用MapKit可以将地图嵌入到视图中,MapKit框架除了可以显示地图,还支持在地图上做标记. 1,通过mapType属性,可以设置地图的显示类型 MKMapType.Standard :标准地 ...
- 如何在WebGL全景图上做标记
WebGL可以用来做3D效果的全景图呈现,例如故宫的全景图.但有时候我们不仅仅只是呈现全景图,还需要增加互动.故宫里边可以又分了很多区域,例如外朝中路.外朝西路.外朝东路等等.我们需要在3D图上做一些 ...
- Android 如何将手机屏幕投影到 PC 屏幕上或者投影仪上做演示?
Android 如何将手机屏幕投影到 PC 屏幕上或者投影仪上做演示? 公司开发款APP,要给领导演示,总不能用手机面对面演示吧.所以找了好久,找到一款体验超好的: Total Control-帮助你 ...
- codewar 上做练习的一些感触
废话 在[codewar][1]上做练习,每次都是尽量快速地做完,然后赶着去看排名里面clever分最高的solution,看完每次都要感叹一下人家怎么可以写得这么简洁,甚至有一次我用了一段大约七八行 ...
- Centos6.2上做nginx和tomcat的集成及负载均衡(已实践)
Centos6.2上做nginx和tomcat的集成及负载均衡 ---------------------------------------------------------Jdk-------- ...
- 在 anyproxy 上做 mock 和 fuzz 测试
引言 写这个工具,主要有几个原因: 最近老大在尝试不同视角的测试----健壮性测试,任务下来,所以挽起袖子就开撸了 app很可能因为后端api做了变更,返回了一个异常的值而出现难以预知的问题,健壮性受 ...
- 基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升. 1. 系统架构层面. DataPipeline引入DataPipeli ...
- 在Jenkins上做一个定时闹钟
[本文出自天外归云的博客园] 利用Jenkins定时任务来做一个闹钟,每天隔一段时间提醒自己一下“你该休息了!别老坐着!出去走一走!珍爱生命,远离久坐!” 首先在Jenkins上创建一个node. 创 ...
- (原)关于sdl在部分机器上做视频显示,改变显示窗口大小会崩溃
今天测试人员反应,之前做的视频绘图显示,会在她机器上,会出现崩溃现象,最后我在她机器上对代码进行跟踪,发现在某种情况,确实会崩溃. 最主要的原因是,视频显示窗口变成非活动窗口的时候,sdl内部会循环消 ...
随机推荐
- macOS下由yarn与npm差异引发的Electron镜像地址读取问题
记录macOS下由yarn与npm差异引发的Electron镜像地址读取问题 写在前面:该问题仅仅出现在Linux和macOS上,Windows上不存在该问题! 初始背景 最近笔者重新拾起了Elect ...
- 代码随想录算法训练营Day17二叉树|110.平衡二叉树 257. 二叉树的所有路径 404.左叶子之和
优先掌握递归 110.平衡二叉树 题目链接:110.平衡二叉树 给定一个二叉树,判断它是否是高度平衡的二叉树. 本题中,一棵高度平衡二叉树定义为: 一个二叉树_每个节点_ 的左右两个子树的高度差的绝对 ...
- Not a managed type: class com.example.commonspojo.entity,公共实体类剥离,然后引入报错的问题及解决办法
最近搞springcloud项目遇到在商品服务中调用基本服务时jvm扫描不到的问题 需要加@entityscan 学习博客: (9条消息) Not a managed type: class com. ...
- Clumpify:能使 Fastq 压缩文件再缩小 30% 并加速后续分析流程
由于微信不允许外部链接,你需要点击文章尾部左下角的 "阅读原文",才能访问文中链接. Clumpify 是 BBMap 工具包中的一个组件,它与其他工具略有不同的是 Clumpif ...
- C#设计模式19——装饰器模式的写法
装饰器模式(Decorator Pattern)是一种结构型设计模式,它允许你动态地给一个对象添加一些额外的职责,而不需要修改这个对象的代码. What(什么) 装饰器模式是一种结构型设计模式,它允许 ...
- OpenAI发布ChatGPT函数调用和API更新
2023年6月13日,OpenAI针对开发者调用的API做了重大更新,包括更易操控的 API模型.函数调用功能.更长的上下文和更低的价格. 在今年早些时候发布gpt-3.5-turbo,gpt-4在短 ...
- PicoRV32-on-PYNQ-Z2: An FPGA-based SoC System——RISC-V On PYNQ项目复现
本文参考: 1️⃣ 原始工程 2️⃣ 原始工程复现教程 3️⃣ RISCV工具链安装教程 本文工程: https://bhpan.buaa.edu.cn:443/link/4B08916BF2CDB4 ...
- 简约版八股文(day1)
Java基础 面向对象的三大基本特征 封装:将一些数据和对这些数据的操作封装在一起,形成一个独立的实体.隐藏内部的操作细节,并向外提供一些接口,来暴露对象的功能. 继承:继承是指子类继承父类,子类获得 ...
- 【Azure API Management】实现在API Management服务中使用MI(管理标识 Managed Identity)访问启用防火墙的Storage Account
问题描述 在Azure的同一数据中心,API Management访问启用了防火墙的Storage Account,并且把APIM的公网IP地址设置在白名单.但访问依旧是403 原因是: 存储帐户部署 ...
- 在DevExpress的GridView的列中,动态创建列的时候,绑定不同的编辑处理控件
在使用DevExpress的GridView的时候,我们为了方便,往往使用一些扩展函数,动态创建GridView列的编辑控件对象,然后我们可以灵活的对内容进行编辑或者使用一些弹出的对话框窗体进行处理内 ...