使用LabVIEW实现 DeepLabv3+ 语义分割含源码
前言
图像分割可以分为两类:语义分割(Semantic Segmentation)和实例分割(Instance Segmentation),前面已经给大家介绍过两者的区别,并就如何在labview上实现相关模型的部署也给大家做了讲解,今天和大家分享如何使用labview 实现deeplabv3+的语义分割,并就 Pascal VOC2012 (DeepLabv3Plus-MobileNet) 上的分割结果和城市景观的分割结果(DeepLabv3Plus-MobileNet)给大家做一个分享。
一、什么是deeplabv3+
Deeplabv3+是一个语义分割网络,使用DeepLabv3作为Encoder模块,并添加一个简单且有效的Decoder模块来获得更清晰的分割。即网络主要分为两个部分:Encoder和Decoder;论文中采用的是Xception作为主干网络(在代码中也可以根据需求替换成MobileNet,本文示例中即使用的MobileNet),然后使用了ASPP结构,解决多尺度问题;为了将底层特征与高层特征融合,提高分割边界准确度,引入Decoder部分。
Encoder-Decoder网络已经成功应用于许多计算机视觉任务,通常,Encoder-Decoder网络包含:
- 逐步减少特征图并提取更高语义信息的Encoder模块
- 逐步恢复空间信息的Decoder模块

二、LabVIEW调用DeepLabv3+实现图像语义分割
1、模型获取及转换
- 下载预训练好的.pth模型文件,下载链接:https://share.weiyun.com/qqx78Pv5 ,我们选择主干网络为Mobilenet的模型

- git上下载开源的整个项目文件,链接为:https://github.com/VainF/DeepLabV3Plus-Pytorch
- 根据requirements.txt 安装所需要的库
pip install -r requirements.txt
- 原项目中使用的模型为.pth,我们将其转onnx模型,
- 将best_deeplabv3plus_mobilenet_voc_os16.pth转化为deeplabv3plus_mobilenet.onnx,具体转化模型代码如下:
import network
import numpy as np
import torch
from torch.autograd import Variable
from torchvision import models
import os
import re
dirname, filename = os.path.split(os.path.abspath(__file__))
print(dirname)
def get_pytorch_onnx_model(original_model):
# define the directory for further converted model save
onnx_model_path = dirname
# define the name of further converted model
onnx_model_name = "deeplabv3plus_mobilenet.onnx"
# create directory for further converted model
os.makedirs(onnx_model_path, exist_ok=True)
# get full path to the converted model
full_model_path = os.path.join(onnx_model_path, onnx_model_name)
# generate model input
generated_input = Variable(
torch.randn(1, 3, 513, 513)
)
# model export into ONNX format
torch.onnx.export(
original_model,
generated_input,
full_model_path,
verbose=True,
input_names=["input"],
output_names=["output"],
opset_version=11
)
return full_model_path
model = network.modeling.__dict__["deeplabv3plus_mobilenet"](num_classes=21, output_stride=8)
checkpoint = torch.load("best_deeplabv3plus_mobilenet_voc_os16.pth", map_location=torch.device('cpu'))
model.load_state_dict(checkpoint["model_state"])
full_model_path = get_pytorch_onnx_model(model)
- 将best_deeplabv3plus_mobilenet_cityscapes_os16.pth转化为deeplabv3plus_mobilenet_cityscapes.onnx,具体转化模型代码如下:
import network
import numpy as np
import torch
from torch.autograd import Variable
from torchvision import models
import os
import re
dirname, filename = os.path.split(os.path.abspath(__file__))
print(dirname)
def get_pytorch_onnx_model(original_model):
# define the directory for further converted model save
onnx_model_path = dirname
# define the name of further converted model
onnx_model_name = "deeplabv3plus_mobilenet_cityscapes.onnx"
# create directory for further converted model
os.makedirs(onnx_model_path, exist_ok=True)
# get full path to the converted model
full_model_path = os.path.join(onnx_model_path, onnx_model_name)
# generate model input
generated_input = Variable(
torch.randn(1, 3, 513, 513)
)
# model export into ONNX format
torch.onnx.export(
original_model,
generated_input,
full_model_path,
verbose=True,
input_names=["input"],
output_names=["output"],
opset_version=11
)
return full_model_path
model = network.modeling.__dict__["deeplabv3plus_mobilenet"](num_classes=19, output_stride=8)
checkpoint = torch.load("best_deeplabv3plus_mobilenet_cityscapes_os16.pth", map_location=torch.device('cpu'))
model.load_state_dict(checkpoint["model_state"])
full_model_path = get_pytorch_onnx_model(model)
注意:我们需要将以上两个脚本保存并与network文件夹同路径
2、LabVIEW 调用基于 Pascal VOC2012训练的deeplabv3+实现图像语义分割 (deeplabv3+_onnx.vi)
经过实验发现,opencv dnn因缺少一些算子,所以无法加载deeplabv3+ onnx模型,所以我们选择使用LabVIEW开放神经网络交互工具包【ONNX】来加载并推理整个模型,实现语义分割,程序源码如下:
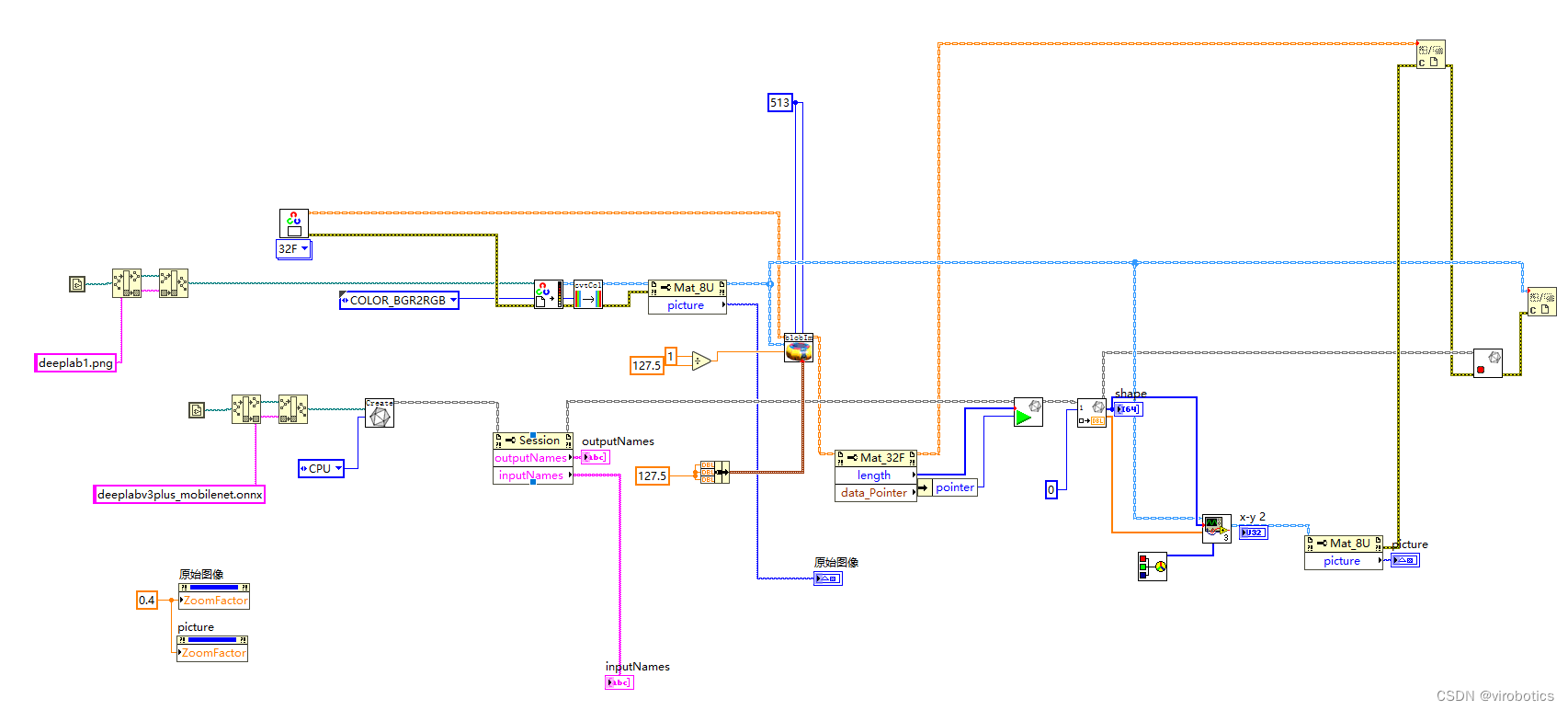
3、LabVIEW Pascal VOC2012上的分割结果(deeplabv3+_onnx.vi)

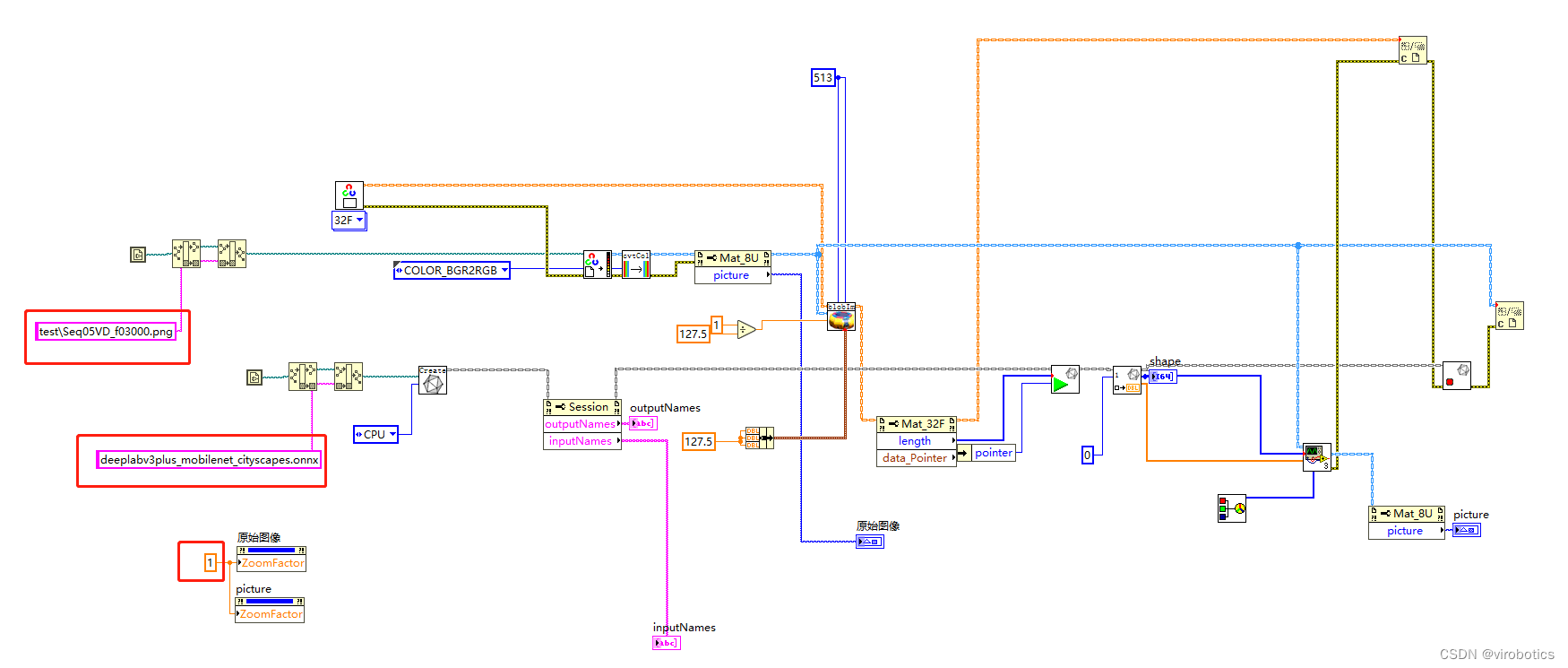
4、LabVIEW 调用基于 Cityscapes 训练的deeplabv3+实现图像语义分割 (deeplabv3+_onnx_cityscape.vi)
如下图所示即为程序源码,我们对比deeplabv3+_onnx.vi,发现其实只需要把模型和待检测的图片更换,图片尺寸比例也做一个修改即可
5、LabVIEW 城市景观的分割结果(deeplabv3+_onnx_cityscape.vi)

三、项目源码及模型下载
欢迎关注微信公众号: VIRobotics,回复关键字:deepLabv3+ 语义分割源码 获取本次分享内容的完整项目源码及模型。
附加说明
操作系统:Windows10
python:3.6及以上
LabVIEW:2018及以上 64位版本
视觉工具包:techforce_lib_opencv_cpu-1.0.0.73.vip
LabVIEW开放神经网络交互工具包【ONNX】:virobotics_lib_onnx_cpu-1.0.0.13.vip
总结
以上就是今天要给大家分享的内容。如果有问题可以在评论区里讨论,提问前请先点赞支持一下博主哦,如您想要探讨更多关于LabVIEW与人工智能技术,欢迎加入我们的技术交流群:705637299。
使用LabVIEW实现 DeepLabv3+ 语义分割含源码的更多相关文章
- DeepLabV3+语义分割实战
DeepLabV3+语义分割实战 语义分割是计算机视觉的一项重要任务,本文使用Jittor框架实现了DeepLabV3+语义分割模型. DeepLabV3+论文:https://arxiv.org/p ...
- jQuery使用():Deferred有状态的回调列表(含源码)
deferred的功能及其使用 deferred的实现原理及模拟源码 一.deferred的功能及其使用 deferred的底层是基于callbacks实现的,建议再熟悉callbacks的内部机制前 ...
- C++ JsonCpp 使用(含源码下载)
C++ JsonCpp 使用(含源码下载) 前言 JSON是一个轻量级的数据定义格式,比起XML易学易用,而扩展功能不比XML差多少,用之进行数据交换是一个很好的选择JSON的全称为:JavaScri ...
- 微信公众平台开发-OAuth2.0网页授权(含源码)
微信公众平台开发-OAuth2.0网页授权接口.网页授权接口详解(含源码)作者: 孟祥磊-<微信公众平台开发实例教程> 在微信开发的高级应用中,几乎都会使用到该接口,因为通过该接口,可以获 ...
- 微信公众平台开发-access_token获取及应用(含源码)
微信公众平台开发-access_token获取及应用(含源码)作者: 孟祥磊-<微信公众平台开发实例教程> 很多系统中都有access_token参数,对于微信公众平台的access_to ...
- 微信公众平台开发-微信服务器IP接口实例(含源码)
微信公众平台开发-access_token获取及应用(含源码)作者: 孟祥磊-<微信公众平台开发实例教程> 学习了access_token的获取及应用后,正式的使用access_token ...
- 百度智能手环方案开源(含源码,原理图,APP,通信协议等)
分享一个百度智能手环开源项目的设计方案资料. 项目简介 百度云智能手环的开源方案是基于Apache2.0开源协议,开源内容包括硬件设计文档,原理图.ROM.通讯协议在内的全套方案,同时开放APP和云服 ...
- Delphi:程序自己删除自己,适用于任何windows版本(含源码)
Delphi:程序自己删除自己,适用于任何windows版本(含源码) function Suicide: Boolean; var sei: TSHELLEXECUTEINFO; szMod ...
- 原创:用python把链接指向的网页直接生成图片的http服务及网站(含源码及思想)
原创:用python把链接指向的网页直接生成图片的http服务及网站(含源码及思想) 总体思想: 希望让调用方通过 http调用传入一个需要生成图片的网页链接生成一个网页的图片并返回图片链接 ...
- Python 基于python实现的http接口自动化测试框架(含源码)
基于python实现的http+json协议接口自动化测试框架(含源码) by:授客 QQ:1033553122 欢迎加入软件性能测试交流 QQ群:7156436 由于篇幅问题,采用百度网 ...
随机推荐
- Zabbix_sender基础命令浅析
zabbix_sender是Zabbix监控系统中用于向Zabbix服务器发送数据的命令行工具.以下是zabbix_sender基础命令教学: 语法: zabbix_sender -z <ser ...
- Redis 数据类型 Zset
Redis 数据类型 Zset(有序集合) Redis 常用命令,思维导图 >>> zset是Redis提供的一个非常特别的数据结构,常用作排行榜等功能,以用户id为value,关注 ...
- 利用机器人类Robot写出自动登录QQ的小代码
最近写了一个小代码控制鼠标键盘使他自己登录QQ,下面给大家分享下这一小代码. 这段小程序是用Java里的Robot类实现的,控制鼠标键盘的一个机器人类. 我们想要实现自动登录QQ首先得想要做到这一步需 ...
- 04-webpack初体验
/** * index.js: webpack入口起点文件 * * 1.运行指令: * 开发环境:webpack ./src/index.js -o ./build --mode=developmen ...
- [人脸活体检测] 论文:Face De-Spoofing: Anti-Spoofing via Noise Modeling
Face De-Spoofing: Anti-Spoofing via Noise Modeling 论文简介 将非活体人脸图看成是加了噪声后失真的x,用残差的思路检测该噪声从而完成分类. 文章引用量 ...
- 1分钟了解C语言正确使用字节对齐及#pragma pack的方法
C/C++编译器的缺省字节对齐方式为自然对界.即在缺省情况下,编译器为每一个变量或是数据单元按其自然对界条件分配空间. 在结构中,编译器为结构的每个成员按其自然对界(alignment)条件分配空 ...
- TCP/IP网络模型
在网络模型中有分为7层模型(OSI模型)和5层模型和TCP/IP模型 OSI模型将应用层和表示层作为独立的两层,而TCP/IP模型将它们合并为一个应用层. 两种对比来说,TCP/IP模型更符合实际开发 ...
- 分布式搜索引擎Elasticsearch基础入门学习
一.Elasticsearch介绍 Elasticsearch介绍 Elasticsearh 是 elastic.co 公司开发的分布式搜索引擎. Elasticsearch(简称ES)是一个开源的分 ...
- 推荐一个.Ner Core开发的配置中心开源项目
当你把单体应用改造为微服务架构,相应的配置文件,也会被分割,被分散到各个节点.这个时候就会产生一个问题,配置信息是分散的.冗余的,变成不好维护管理.这个时候我们就需要把配置信息独立出来,成立一个配置中 ...
- 2022-05-19:给定一个数组arr,给定一个正数M, 如果arr[i] + arr[j]可以被M整除,并且i < j,那么(i,j)叫做一个M整除对。 返回arr中M整除对的总数量。 来自微软。
2022-05-19:给定一个数组arr,给定一个正数M, 如果arr[i] + arr[j]可以被M整除,并且i < j,那么(i,j)叫做一个M整除对. 返回arr中M整除对的总数量. 来自 ...