37 手游基于 Flink CDC + Hudi 湖仓一体方案实践
简介: 介绍了 37 手游为何选择 Flink 作为计算引擎,并如何基于 Flink CDC + Hudi 构建新的湖仓一体方案。
本文作者是 37 手游大数据开发徐润柏,介绍了 37 手游为何选择 Flink 作为计算引擎,并如何基于 Flink CDC + Hudi 构建新的湖仓一体方案,主要内容包括:
- Flink CDC 基本知识介绍
- Hudi 基本知识介绍
- 37 手游的业务痛点和技术方案选型
- 37 手游湖仓一体介绍
- Flink CDC + Hudi 实践
- 总结
一、Flink-CDC 2.0
Flink CDC Connectors 是 Apache Flink 的一个 source 端的连接器,目前 2.0 版本支持从 MySQL 以及 Postgres 两种数据源中获取数据,2.1 版本社区确定会支持 Oracle,MongoDB 数据源。
Fink CDC 2.0 的核心 feature,主要表现为实现了以下三个非常重要的功能:
- 全程无锁,不会对数据库产生需要加锁所带来的风险;
- 多并行度,全量数据的读取阶段支持水平扩展,使亿级别的大表可以通过加大并行度来加快读取速度;
- 断点续传,全量阶段支持 checkpoint,即使任务因某种原因退出了,也可通过保存的 checkpoint 对任务进行恢复实现数据的断点续传。
二、Hudi
Apache Hudi 目前被业内描述为围绕数据库内核构建的流式数据湖平台 (Streaming Data Lake Platform)。
由于 Hudi 拥有良好的 Upsert 能力,并且 0.10 Master 对 Flink 版本支持至 1.13.x,因此我们选择通过 Flink + Hudi 的方式为 37 手游的业务场景提供分钟级 Upsert 数据的分析查询能力。
三、37 手游的业务痛点和技术方案选型
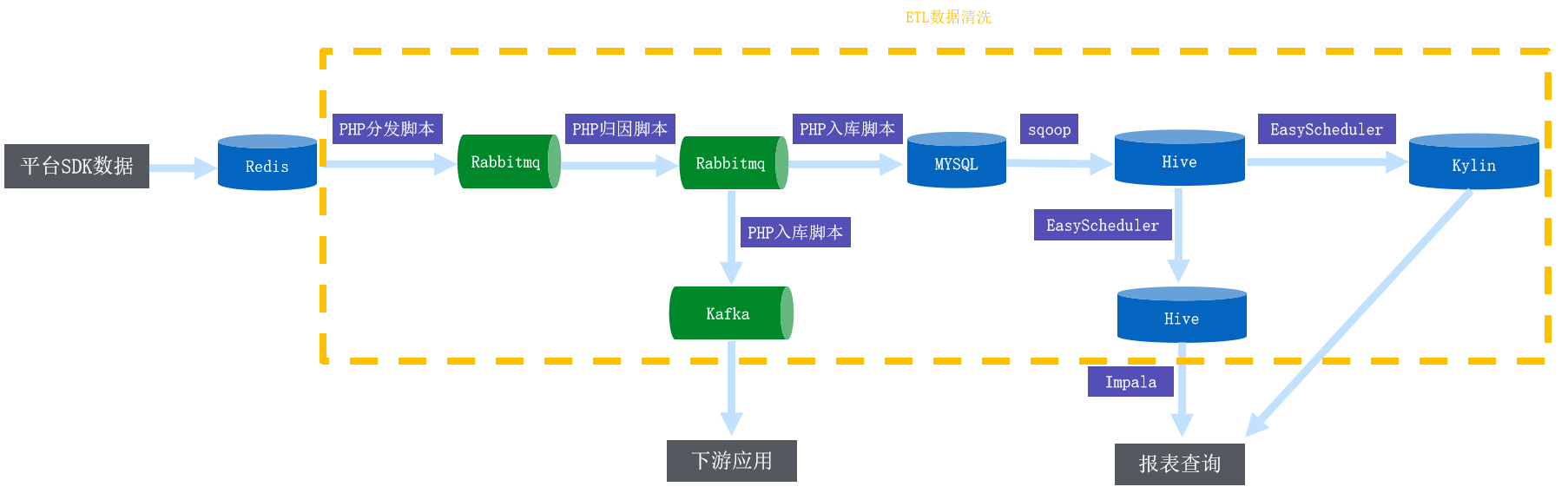
1. 旧架构与业务痛点
1.1 数据实时性不够
- 日志类数据通过 sqoop 每 30min 同步前 60min 数据到 Hive;
- 数据库类数据通过 sqoop 每 60min 同步当天全量数据到 Hive;
- 数据库类数据通过 sqoop 每天同步前 60 天数据到 Hive。
1.2 业务代码逻辑复杂且难维护
- 目前 37 手游还有很多的业务开发沿用 MySQL + PHP 的开发模式,代码逻辑复杂且很难维护;
- 相同的代码逻辑,往往流处理需要开发一份代码,批处理则需要另开发一份代码,不能复用。
1.3 频繁重刷历史数据
- 频繁地重刷历史数据来保证数据一致。
1.4 Schema 变更频繁
- 由于业务需求,经常需要添加表字段。
1.5 Hive 版本低
- 目前 Hive 使用版本为 1.x 版本,并且升级版本比较困难;
- 不支持 Upsert;
- 不支持行级别的 delete。
由于 37 手游的业务场景,数据 upsert、delete 是个很常见的需求。所以基于 Hive 数仓的架构对业务需求的满足度不够。
2. 技术选型
在同步工具的选型上考虑过 Canal 和 Maxwell。但 Canal 只适合增量数据的同步并且需要部署,维护起来相对较重。而 Maxwell 虽然比较轻量,但与 Canal 一样需要配合 Kafka 等消息队列使用。对比之下,Flink CDC 可以通过配置 Flink connector 的方式基于 Flink-SQL 进行使用,十分轻巧,并且完美契合基于 Flink-SQL 的流批一体架构。
在存储引擎的选型上,目前最热门的数据湖产品当属:Apache Hudi,Apache Iceberg 和 DeltaLake,这些在我们的场景下各有优劣。最终,基于 Hudi 对上下游生态的开放、对全局索引的支持、对 Flink 1.13 版本的支持,以及对 Hive 版本的兼容性 (Iceberg 不支持 Hive1.x 的版本) 等原因,选择了 Hudi 作为湖仓一体和流批一体的存储引擎。
针对上述存在的业务痛点以及选型对比,我们的最终方案为:以 Flink1.13.2 作为计算引擎,依靠 Flink 提供的流批统一的 API,基于 Flink-SQL 实现流批一体,Flink-CDC 2.0 作为 ODS 层的数据同步工具以及 Hudi-0.10 Master 作为存储引擎的湖仓一体,解决维护两套代码的业务痛点。
四、新架构与湖仓一体
37 手游的湖仓一体方案,是 37 手游流批一体架构的一部分。通过湖仓一体、流批一体,准实时场景下做到了:数据同源、同计算引擎、同存储、同计算口径。数据的时效性可以到分钟级,能很好的满足业务准实时数仓的需求。下面是架构图:

MySQL 数据通过 Flink CDC 进入到 Kafka。之所以数据先入 Kafka 而不是直接入 Hudi,是为了实现多个实时任务复用 MySQL 过来的数据,避免多个任务通过 Flink CDC 接 MySQL 表以及 Binlog,对 MySQL 库的性能造成影响。
通过 CDC 进入到 Kafka 的数据除了落一份到离线数据仓库的 ODS 层之外,会同时按照实时数据仓库的链路,从 ODS->DWD->DWS->OLAP 数据库,最后供报表等数据服务使用。实时数仓的每一层结果数据会准实时的落一份到离线数仓,通过这种方式做到程序一次开发、指标口径统一,数据统一。
从架构图上,可以看到有一步数据修正 (重跑历史数据) 的动作,之所以有这一步是考虑到:有可能存在由于口径调整或者前一天的实时任务计算结果错误,导致重跑历史数据的情况。
而存储在 Kafka 的数据有失效时间,不会存太久的历史数据,重跑很久的历史数据无法从 Kafka 中获取历史源数据。再者,如果把大量的历史数据再一次推到 Kafka,走实时计算的链路来修正历史数据,可能会影响当天的实时作业。所以针对重跑历史数据,会通过数据修正这一步来处理。
总体上说,37 手游的数据仓库属于 Lambda 和 Kappa 混搭的架构。流批一体数据仓库的各个数据链路有数据质量校验的流程。第二天对前一天的数据进行对账,如果前一天实时计算的数据无异常,则不需要修正数据,Kappa 架构已经足够。
五、Flink CDC 2.0 + Kafka + Hudi 0.10 实践
1. 环境准备
- Flink 1.13.2
- .../lib/hudi-flink-bundle_2.11-0.10.0-SNAPSHOT.jar (修改 Master 分支的 Hudi Flink 版本为 1.13.2 然后构建)
- .../lib/hadoop-mapreduce-client-core-2.7.3.jar (解决 Hudi ClassNotFoundException)
- ../lib/flink-sql-connector-mysql-cdc-2.0.0.jar
- ../lib/flink-format-changelog-json-2.0.0.jar
- ../lib/flink-sql-connector-kafka_2.11-1.13.2.jar
source 端 MySQL-CDC 表定义:
create table sy_payment_cdc (
ID BIGINT,
...
PRIMARY KEY(ID) NOT ENFORCED
) with(
'connector' = 'mysql-cdc',
'hostname' = '',
'port' = '',
'username' = '',
'password' = '',
'database-name' = '',
'table-name' = '',
'connect.timeout' = '60s',
'scan.incremental.snapshot.chunk.size' = '100000',
'server-id'='5401-5416'
);
值得注意的是:scan.incremental.snapshot.chunk.size 参数需要根据实际情况来配置,如果表数据量不大,使用默认值即可。
Sink 端 Kafka+Hudi COW 表定义:
create table sy_payment_cdc2kafka (
ID BIGINT,
...
PRIMARY KEY(ID) NOT ENFORCED
) with (
'connector' = 'kafka',
'topic' = '',
'scan.startup.mode' = 'latest-offset',
'properties.bootstrap.servers' = '',
'properties.group.id' = '',
'key.format' = '',
'key.fields' = '',
'format' = 'changelog-json'
);
create table sy_payment2Hudi (
ID BIGINT,
...
PRIMARY KEY(ID) NOT ENFORCED
)
PARTITIONED BY (YMD)
WITH (
'connector' = 'Hudi',
'path' = 'hdfs:///data/Hudi/m37_mpay_tj/sy_payment',
'table.type' = 'COPY_ON_WRITE',
'partition.default_name' = 'YMD',
'write.insert.drop.duplicates' = 'true',
'write.bulk_insert.shuffle_by_partition' = 'false',
'write.bulk_insert.sort_by_partition' = 'false',
'write.precombine.field' = 'MTIME',
'write.tasks' = '16',
'write.bucket_assign.tasks' = '16',
'write.task.max.size' = '',
'write.merge.max_memory' = ''
);针对历史数据入 Hudi,可以选择离线 bulk_insert 的方式入湖,再通过 Load Index Bootstrap 加载数据后接回增量数据。bulk_insert 方式入湖数据的唯一性依靠源端的数据本身,在接回增量数据时也需要做到保证数据不丢失。
这里我们选择更为简单的调整任务资源的方式将历史数据入湖。依靠 Flink 的 checkpoint 机制,不管是 CDC 2.0 入 Kafka 期间还是 Kafka 入 Hudi 期间,都可以通过指定 checkpoint 的方式对任务进行重启并且数据不会丢失。
我们可以在配置 CDC 2.0 入 Kafka,Kafka 入 Hudi 任务时调大内存并配置多个并行度,加快历史数据入湖,等到所有历史数据入湖后,再相应的调小入湖任务的内存配置并且将 CDC 入 Kafka 的并行度设置为 1,因为增量阶段 CDC 是单并行度,然后指定 checkpoint 重启任务。
按照上面表定义的参数配置,配置 16 个并行度,Flink TaskManager 内存大小为 50G 的情况下,单表 15 亿历史数据入至 Hudi COW 表实际用时 10 小时,单表 9 亿数据入至 Hudi COW 表实际用时 6 小时。当然这个耗时很大一部分是 COW 写放大的特性,在大数据量的 upsert 模式下耗时较多。
目前我们的集群由 200 多台机器组成,在线的流计算任务总数有 200 多,总数据量接近 2PB。
如果集群资源很有限的情况下,可以根据实际情况调整 Hudi 表以及 Flink 任务的内存配置,还可以通过配置 Hudi 的限流参数 write.rate.limit 让历史数据缓慢入湖。
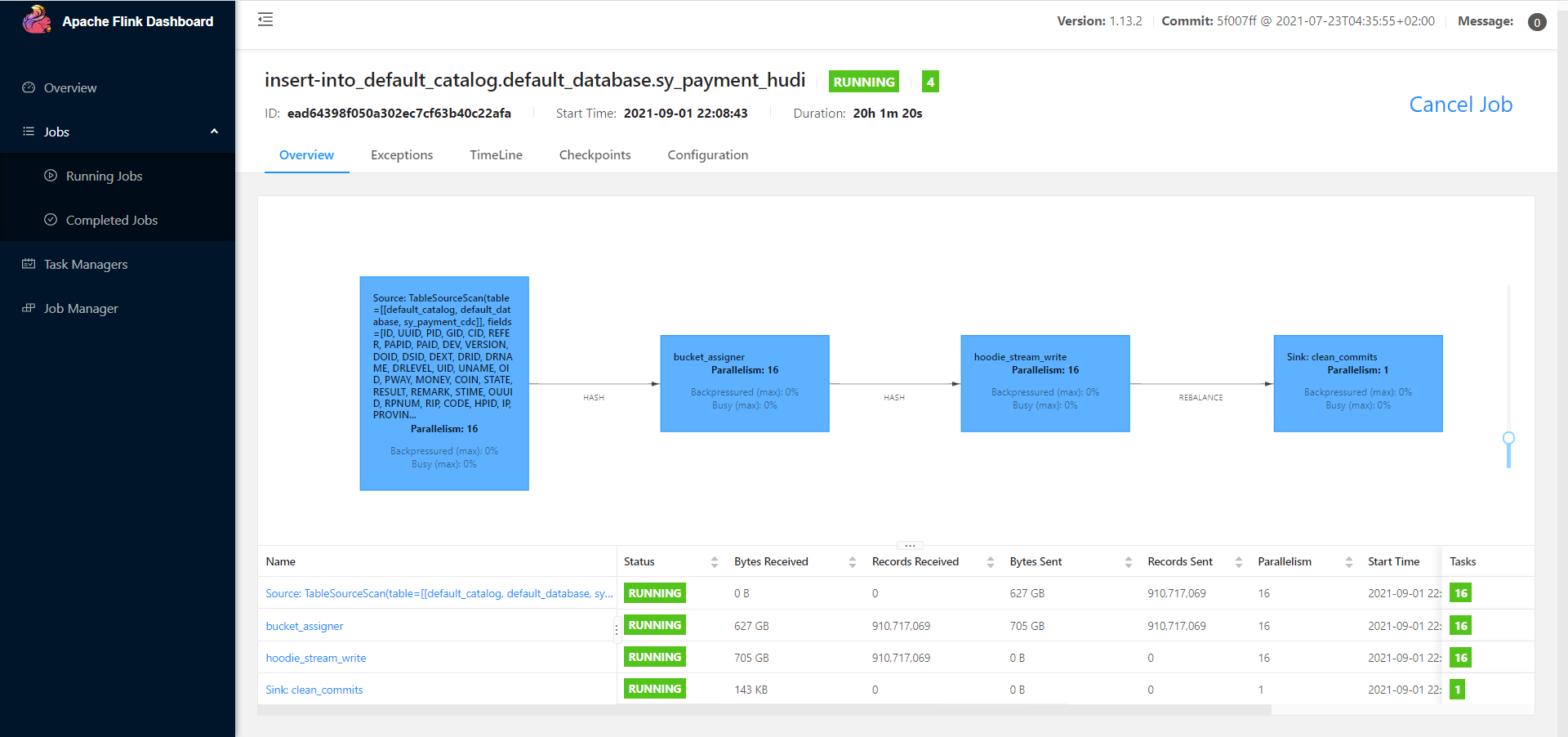
之前 Flink CDC 1.x 版本由于全量 snapshot 阶段单并行度读取的原因,当时亿级以上的表在全量 snapshot 读取阶段就需要耗费很长时间,并且 checkpoint 会失败无法保证数据的断点续传。
所以当时入 Hudi 是采用先启动一个 CDC 1.x 的程序将此刻开始的增量数据写入 Kafka,之后再启动另外一个 sqoop 程序拉取当前的所有数据至 Hive 后,通过 Flink 读取 Hive 的数据写 Hudi,最后再把 Kafka 的增量数据从头消费接回 Hudi。由于 Kafka 与 Hive 的数据存在交集,因此数据不会丢失,加上 Hudi 的 upsert 能力保证了数据唯一。
但是,这种方式的链路太长操作困难,如今通过 CDC 2.0 在全量 snapshot 阶段支持多并行度以及 checkpoint 的能力,确实大大降低了架构的复杂度。
2. 数据比对
- 由于生产环境用的是 Hive1.x,Hudi 对于 1.x 还不支持数据同步,所以通过创建 Hive 外部表的方式进行查询,如果是 Hive2.x 以上版本,可参考 Hive 同步章节;
- 创建 Hive 外部表 + 预创建分区;
- auxlib 文件夹添加 Hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar。
CREATE EXTERNAL TABLE m37_mpay_tj.`ods_sy_payment_f_d_b_ext`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`ID` bigint,
...
)
PARTITIONED BY (
`dt` string)
ROW FORMAT SERDE
'org.apache.hadoop.Hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.Hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.Hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs:///data/Hudi/m37_mpay_tj/sy_payment'最终查询 Hudi 数据 (Hive 外部表的形式) 与原来 sqoop 同步的 Hive 数据做比对得到:
- 总数一致;
- 按天分组统计数量一致;
- 按天分组统计金额一致。
六、总结
湖仓一体以及流批一体架构对比传统数仓架构主要有以下几点好处:
- Hudi 提供了 Upsert 能力,解决频繁 Upsert/Delete 的痛点;
- 提供分钟级的数据,比传统数仓有更高的时效性;
- 基于 Flink-SQL 实现了流批一体,代码维护成本低;
- 数据同源、同计算引擎、同存储、同计算口径;
- 选用 Flink CDC 作为数据同步工具,省掉 sqoop 的维护成本。
最后针对频繁增加表字段的痛点需求,并且希望后续同步下游系统的时候能够自动加入这个字段,目前还没有完美的解决方案,希望 Flink CDC 社区能在后续的版本提供 Schema Evolution 的支持。
Reference
[1] MySQL CDC 文档: MySQL CDC Connector — Flink CDC 2.0.0 documentation
[2] Hudi Flink 答疑解惑:HUDI FLINK 答疑解惑 · 语雀
[3] Hudi 的一些设计:Hudi 的一些设计 · 语雀
原文链接
本文为阿里云原创内容,未经允许不得转载。
37 手游基于 Flink CDC + Hudi 湖仓一体方案实践的更多相关文章
- 李呈祥:bilibili在湖仓一体查询加速上的实践与探索
导读: 本文主要介绍哔哩哔哩在数据湖与数据仓库一体架构下,探索查询加速以及索引增强的一些实践.主要内容包括: 什么是湖仓一体架构 哔哩哔哩目前的湖仓一体架构 湖仓一体架构下,数据的排序组织优化 湖仓一 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- 华为云FusionInsight湖仓一体解决方案的前世今生
摘要:华为云发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念,那我们就来看看湖仓一体的来世今生. 伴随5G.大数据.AI.IoT的飞速发展,数据呈现大规模.多样性的极速增长 ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- Unity3D手游开发日记(1) - 移动平台实时阴影方案
阴影这个东西,说来就话长了,很多年前人们就开始研究出各种阴影技术,但都存在各种瑕疵和问题,直到近几年出现了PSSM,也就是CE3的CSM,阴影技术才算有个比较完美的解决方案.Unity自带的实时阴影, ...
- 划重点!AWS的湖仓一体使用哪种数据湖格式进行衔接?
此前Apache Hudi社区一直有小伙伴询问能否使用Amazon Redshift查询Hudi表,现在它终于来了. 现在您可以使用Amazon Redshift查询Amazon S3 数据湖中Apa ...
- 基于Github Actions + Docker + Git 的devops方案实践教程
目录 为什么需要Devops 如何实践Devops 版本控制工具(Git) 学习使用 配置环境 源代码仓库 一台配置好环境的云服务器 SSH远程登录 在服务器上安装docker docker技术准备工 ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
随机推荐
- slf4j 和 log4j2 架构设计
1.日志框架背景 2.为什么会有 slf4j 和 log4j2 搭配一说? 3.log4j2 3.1.背景及应用场景 3.2.功能模块 4.slf4j 4.1.背景及应用场景 4.2.功能模块 5.s ...
- Android 开发Day8
/* AUTO-GENERATED FILE. DO NOT MODIFY. * * This class was automatically generated by the * gradle pl ...
- 【个人笔记】2023年搭建基于webpack5与typescript的react项目
写在前面 由于我在另外的一些文章所讨论或分析的内容可能基于一个已经初始化好的项目,为了避免每一个文章都重复的描述如何搭建项目,我在本文会统一记录下来,今后相关的文章直接引用文本,方便读者阅读.此文主要 ...
- Liunx-LVM创建与扩容
LVM是 Logical Volume Manager(逻辑卷管理)的简写,它是Linux环境下对磁盘分区进行管理的一种机制,它由Heinz Mauelshagen在Linux 2.4内核上实现,最新 ...
- Gaussian YOLOv3 : 对bbox预测值进行高斯建模输出不确定性,效果拔群 | ICCV 2019
在自动驾驶中,检测模型的速度和准确率都很重要,出于这个原因,论文提出Gaussian YOLOv3.该算法在保持实时性的情况下,通过高斯建模.损失函数重建来学习bbox预测值的不确定性,从而提高准确率 ...
- 世界疫情div界面搭建初步
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...
- 简单的Git/GitHub
什么是Git/GitHub Git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目. 版本控制(Revision control)是一种在开发的过程中用于管理我们对文件.目录或工 ...
- CSP2020-S 游记
10.11 CSP-S1 自从国庆假期回到学校我申请停课, 从此开始了长达近一个的停课生活. 初赛也是有惊无险地过去了. 一出来发现自己仍旧是大考必败型选手, 对了答案发现我其实错了挺多的, 可能是因 ...
- nginx集成brotli压缩算法
本文于2017年2月中旬完成,发布在个人博客网站上. 考虑个人博客因某种原因无法修复,于是在博客园安家,之前发布的文章逐步搬迁过来. Google开源Brotli压缩算法 Brotli是一种全新的数据 ...
- OpenHarmony开源开发者成长计划 | 知识赋能第六期预告—从零上手OpenHarmony智能家居项目
OpenAtom OpenHarmony(以下简称"OpenHarmony")开源开发者成长计划项目自 2021 年 10 月 24 日上线以来,在开发者中引发高度关注. 成长计划 ...