从此Redis是路人
从此Redis是路人
序言:Redis(Remote DIctionary Server)作为一个开源/C实现/高性能/基于内存的key-value存储系统,相信做Java的小伙伴都不会陌生。Redis常用于缓存、分布式锁、队列(或有序集合)等场景,追求技术的小伙伴们肯定不只满足于Redis的使用上,肯定也想了解Redis背后的设计思想及对应的开发实践,话不多少,上车吧~
ps:文章较长,小伙伴可以搬个小板凳慢慢阅读,也可以结合自身情况进行选择阅读 : )
由于文章内容较多,下面就按照Redis对象、事件处理机制、持久化机制、事务机制、主备模型、集群机制等内容进行分析讨论,中间可能穿插着相关内容的扩展和思考。Let's go....
Redis对象
Redis主要有5种不同类型的对象,分别是字符串、列表、哈希表、集合、有序集合。这些对象都是基于Redis基础数据结构来构建的,并且每种对象都用到了至少一种基础数据结构。Redis对象还实现了引用计数的内存回收技术,当不再使用某个对象时,可以及时释放其内存;通过引用计数实现了对象共享机制,节约内存(Redis只对包含整数值的字符串对象进行共享);Redis的对象带有访问时间戳,可用于计算该对象空转时间,启用maxmemroy功能时,空转时间较长的键优先被删除。
Redis用到的底层数据结构有:简单动态字符串、双端链表、字典、压缩列表、整数集合、跳跃表等,Redis并没有直接使用这些数据结构来实现键值对数据库,而是基于这些基础数据结构创建了一个对象系统,这写对象包括字符串对象、列表对象、哈希对象、集合对象和有序集合对象等。
Redis中使用对象表示键和值,当新建一个键值对时,Redis至少创建2个对象,一个是键对象,另一个是值对象。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
type表示对象类型(有REDIS_STRING/REDIS_LIST/REDIS_HASH/REDIS_SET/REDIS_ZSET几种),对于Redis键值对来说,键永远都是字符串,值可以是字符串、列表、哈希表、集合、有序集合中的一种。encoding表示对象编码,也就是该对象使用什么底层数据结构实现。ptr指向对象的底层数据结构。
Redis对象:
字符串:字符串对象底层可以是int和raw编码方式,如set num 1后执行append num hello,则会导致编码方式由int到raw转换。
127.0.0.1:6379> set num 1
OK
127.0.0.1:6379> object encoding num
"int"
127.0.0.1:6379> append num hello
(integer) 6
127.0.0.1:6379> object encoding num
"raw"列表:列表对象的编码可以是ziplist、linkedlist和quicklist(新版本Redis使用quicklist作为列表底层数据结构了)。ziplist使用功能压缩列表作为底层实现,每个压缩列表节点保存一个列表元素。
127.0.0.1:6379> rpush nums 1 "tow" 3
127.0.0.1:6379> object encoding nums
"quicklist"集合:set容器,集合对象的编码可以是intset和hashtable。intset编码的集合对象使用整数集合作为底层实现,所有元素都保存在整数集合中。另一方面,使用hashtable的集合对象使用字典作为底层实现,字典中每个键都是一个字符串对象,即一个集合元素,而字典的值都是NULL。
127.0.0.1:6379> sadd mans 1
127.0.0.1:6379> sadd mans 2
127.0.0.1:6379> object encoding mans
"intset"
127.0.0.1:6379> sadd mans luoxn28
127.0.0.1:6379> object encoding mans
"hashtable"有序集合:有序集合对象的编码可以是ziplist和skiplist。ziplist编码的压缩列表对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨着的压缩列表节点保存,第一个保存集合元素,第二个保存集合元素对应的分值。压缩列表内集合元素按照分值大小进行排序,分值较小的在前,分值大的在后;skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表,通过字典提高获取单个元素效率,通过skiplist提高获取范围查询能力,二者各取所长。
哈希表:哈希对象的编码可以是ziplist和hashtable。hashtable编码的哈希对象使用字典作为底层实现,则哈希对象中的每个键值对都是字典键值对来保存,hashtable为数组+链表的分离连接法实现。
事件处理机制
Redis的事件类型分为时间事件和文件事件,文件事件也就是IO事件。时间事件的处理是在epoll_wait返回处理文件事件后处理的,每次epoll_wait的超时时间都是Redis最近的一个定时器时间。Redis对epoll进行了简单封装,不像memcached直接使用libevent作为网络通信组件。
Redis在进行事件处理前,首先会进行初始化,初始化的主要逻辑在main/initServer函数中。初始化流程主要做的工作如下:
设置回调函数;
创建事件循环机制,即调用epoll_create;
创建服务监听端口,创建定时事件,并将这些事件添加到事件机制中。
void initServer(void) {
// 设置信号对应的处理函数
signal(SIGHUP, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
setupSignalHandlers();
...
createSharedObjects();
adjustOpenFilesLimit();
// 创建事件循环机制,及调用epoll_create创建epollfd用于事件监听
server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR);
server.db = zmalloc(sizeof(redisDb)*server.dbnum);
/* Open the TCP listening socket for the user commands. */
// 创建监听服务端口,socket/bind/listen
if (server.port != 0 &&
listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR)
exit(1);
...
/* Create the Redis databases, and initialize other internal state. */
for (j = 0; j < server.dbnum; j++) {
server.db[j].dict = dictCreate(&dbDictType,NULL);
server.db[j].expires = dictCreate(&keyptrDictType,NULL);
server.db[j].blocking_keys = dictCreate(&keylistDictType,NULL);
server.db[j].ready_keys = dictCreate(&setDictType,NULL);
server.db[j].watched_keys = dictCreate(&keylistDictType,NULL);
server.db[j].eviction_pool = evictionPoolAlloc();
server.db[j].id = j;
server.db[j].avg_ttl = 0;
}
...
/* Create the serverCron() time event, that's our main way to process
* background operations. 创建定时事件 */
if(aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create the serverCron time event.");
exit(1);
}
/* Create an event handler for accepting new connections in TCP and Unix
* domain sockets. */
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic("Unrecoverable error creating server.ipfd file event.");
}
}
// 将事件加入到事件机制中,调用链为 aeCreateFileEvent/aeApiAddEvent/epoll_ctl
if (server.sofd > 0 && aeCreateFileEvent(server.el,server.sofd,AE_READABLE,
acceptUnixHandler,NULL) == AE_ERR)
/* Open the AOF file if needed. */
if (server.aof_state == AOF_ON) {
server.aof_fd = open(server.aof_filename,
O_WRONLY|O_APPEND|O_CREAT,0644);
if (server.aof_fd == -1) {
exit(1);
}
}
...
}
IO事件的处理:
Redis监听端口的事件回调函数链是:acceptTcpHandler / acceptCommonHandler / createClient / aeCreateFileEvent / aeApiAddEvent / epoll_ctl。在Reids监听事件处理流程中,会将客户端的连接fd添加到事件机制中,并设置其回调函数为readQueryFromClient,该函数负责处理客户端的命令请求。
命令处理流程:
命令处理流程链是:readQueryFromClient / processInputBuffer / processCommand / call / 对应命令的回调函数(c->cmd->proc),比如get key命令的处理回调函数为getCommand。getCommand的执行流程是先到client对应的数据库字典中根据key来查找数据,然后根据响应消息格式将查询结果填充到响应消息中。
定时事件的处理:
Redis的定时时间是通过堆来管理的,按照延时时间作为优先级排序,当进行epoll_wait时,选择堆中最小延时时间作为epoll_wait的timeout:
typedef struct aeTimeEvent {
long long id; /* time event identifier. */
long when_sec; /* seconds */
long when_ms; /* milliseconds */
aeTimeProc *timeProc;
aeEventFinalizerProc *finalizerProc;
void *clientData;
struct aeTimeEvent *next;
} aeTimeEvent;
注意:定时事件是在IO事件处理完成之后才进行的,这样保证了优先响应client端的请求操作。
持久化机制
Redis作为内存数据库,它将自己的数据库状态保存在内存中,试想一下,如果此时服务器突然崩溃,那么数据库的状态就无法恢复了。所以,Reids提供了持久化机制,将Redis数据库状态持久化到磁盘,Redis的持久化机制分为2种:RDB和AOF。
RDB
RDB持久化既可以手动执行,也可以定期执行,该功能就是将某个时间点的数据库状态保存到一个RDB文件。有2个命令用于生成RDB文件,save和bgsave命令。二者不同的是,前者会阻塞Redis服务器进程,直到RDB文件创建完成为止;后者会fork一个子进程,然后由子进程来负责创建RDB文件,而父进程可以继续处理请求命令。
和使用save和bgsave命令创建RDB文件不同,RDB文件的启动是在Redis服务器启动时自动执行的,所以Redis未提供用于加载RDB文件的命令。注意:因为AOF文件的更新频率通常比RDB文件要高,所以如果Redis开启了AOF功能,则会优先使用AOF文件来还原数据;只有在AOF未开启情况下,Redis才会使用RDB文件完成数据库还原操作。
自动RDB策略:
save 900 1
save 300 10
save 60 10000
以上配置表示当900s内有一次更新操作,或者300s内有10次更新操作,或者60s内有10000次更新操作,就会触发RDB持久化。RDB文件是按照RDB格式存储的,经过压缩的二进制文件,故数据恢复速度较快。当RDB机制被触发时,会fork子进程,扫描所有数据库的所有键值对,然后将其按照固定格式写入到RDB文件中,扫描完毕后写入磁盘,这时可能会进行重写文件名操作。
AOF
与RDB通过保存数据库中键值对来记录数据状态不同,AOF持久化是通过保存Redis服务器所执行的写命令来记录数据状态的。AOF持久化的实现:在AOF使能后,Redis在执行完一个写命令后,会以协议格式将写命令追加到服务器状态的aof_buf缓冲区末尾。
Redis进程就是一个事件循环,事件分为IO事件和时间事件,IO事件就是处理与客户端的通信,时间事件就是负责执行像serverCron函数这样需要定时执行的函数。文件事件可能会涉及到写命令,所以Redis在每次结束一个事件循环前,都会调用flushAppendOnlyFile函数,考虑是否将aof_buf缓冲区的内容写入到AOF文件。flushAppendOnlyFile的行为有appendfsync配置项来决定:
always:每次写命令都会同步到aof文件
everysec:每秒同步一次(默认)
no:不主动进行同步,何时同步由操作系统决定
AOF重写
因为AOF文件保存写命令来记录数据库状态,所以随着服务器的运行,AOF文件记录内容会越来越多,不加控制的话AOF会占用过多磁盘空间。因此,AOF增加了重写功能,也就是Redis将生成AOF文件替换旧AOF文件,虽然名字是AOF重写,但是AOF重写并不是对现有的AOF文件进行任何读取修改操作,而是读取数据库当前状态来实现的,生成能够还原当前数据库记录的最小写命令集合。
Redis使用子进程来完成AOF重写操作,这样Redis服务器可以继续处理客户端请求,子进程使用父进程的数据副本,使用子进程而不是线程,避免使用锁的同时也保证数据安全性。不过还有一个问题需要解决,如果在子进程进行AOF重写时,父进程又处理一部分写命令,从而使得服务器当前数据库状态和重写后的AOF文件所保存的数据库状态不一致。Redis又是如何处理该问题的呢?
AOF缓冲区内容会定期被写入和同步到AOF文件,对现有AOF文件的处理工作照常执行。从创建子进程开始,服务器所执行的写命令都会被记录到AOF重写缓冲区中。在子进程执行完AOF重写后,会向父进程发送一个信号,然后父进程会进行以下操作:
将AOF重写缓冲区内容写入到新的AOF文件中,这是新的AOF文件所保存的数据库状态和服务器当前状态一致。
对新的AOF文件更改名字,原子覆盖现有的AOF文件,完成新旧两个文件的替换。
既然有AOF和RDB两种方式,那么哪一种更好呢?总的来说,二者都有优缺点,最好是根据业务场景来做(只作为缓存的场景理论上也可以不要持久化策略),同样的数据集AOF文件要比RDB文件大很多,但是AOF策略数据持久化更实时可靠一些。因为二者各有所长,所以Redis4.0中引入了混合持久化机制。
混合持久化
在Redis 4.0 中引入了混合持久化,将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。

于是在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。
事务机制
Redis通过MULTI、EXEC、WATCH命令来实现事务,Reids在事务执行期间,服务器不会中断事务去执行其他命令,而是在事务的所有命令执行完毕后再执行其他命令,因为Redis是单线程处理模型。以下是一个事务执行流程:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name luo
QUEUED
127.0.0.1:6379> set age 26
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
一个事务从开始到结束通常会经历以下3个阶段:
事务开始:multi命令标志着事务的开始;
命令入列:当事务开始后,所有命令都不会立即执行,而是将命令放入一个事务队列中;
事务执行:exec命令将开始执行事务,服务器会遍历这个事务队列,执行队列中所有的命令,最后将执行后的结果都返回给该客户端。注意,该事务队列是FIFO的。
WATCH命令的实现
WATCH是一个乐观锁,它可以在MULTI命令执行前,监视任意多个key,并在EXEC执行前,如果有一个或多个被监视key被更新,则拒绝执行事务,并向客户端返回执行失败的空回复。以下是一个事务执行失败的例子(在EXEC前另一个客户端更改了name的值):
127.0.0.1:6379> watch name
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name luoxn28
QUEUED
127.0.0.1:6379> exec
(nil)
每个Reids数据库都保存着一个watched_keys字典,这个字典的键是某个被WATCH命令监控的数据库键,而字典的值是一个链表,链表记录了所有监控对应数据库键的客户端:
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
通过watched_keys字典可以很容易的清楚哪些数据库键被监视,以及哪些客户端正在监视这些数据库键。那么监控机制什么时候被触发的呢?所有对数据库键进行修改的命令,比如set/lpush/sadd/zrem/del/flushdb等,在执行之后都会对watched_keys字典进行检查,检查是否有刚才修改的数据库键,如果有的话则会将监控被修改键对应链表上所有客户端的REDIS_DIRTY_CAS标志打开,表示该客户端事务安全性被破坏。
在收到EXEC命令时,Redis会根据客户端对应连接是否打开了REDIS_DIRTY_CAS标志来决定是否执行事务。如果被打开,则拒绝执行事务,因为此时事务提交已不再安全;否则将执行事务。
Redis事务与MySQL事务比较:
传统数据库系统中常用ACID属性来检验事务的安全性和可靠性,关于MySQL资料较多,这里不再赘述。
原子性:Reids事务不具有回滚机制,即使事务中有部分命令执行错误,事务也会继续执行之后的命令直到结束,并且之前执行的命令不受任何影响。Redis为什么不支持回滚机制呢,其作者解释道,不支持事务回滚是因为这种复杂的功能和Reids追求的简单高效设计主旨不符,并且他认为,Reids事务的执行中的错误通常是由程序错误导致的,这种错误在实际生产环境中较少出现,因此没必要为Reids开发事务回滚功能。
一致性:一致性指数据库在执行事务之前是一致的,那么在事务的执行之后,无论其成功与否,数据库都仍然是一致的。Redis通过以下几个机制来保证事务的一致性:
入队错误检查:命令入事务队列时,会检查该命令,如果该命令不存在或者格式不正确,那么Reids拒绝执行该事务。
事务在执行过程中发生了错误,比如对数据库键进行了错误类型操作,此时Redis不会中断事务的执行,而是继续执行后面的命令,并且已执行的命令不会受到错误命令的影响。
Reids运行在某一持久化机制下,事务执行过程中发生停机都不会影响数据库的一致性,因为可以通过持久化文件来恢复出数据库之前保存的状态。
隔离性:隔离性是指在事务并发执行时,各个事务之间不会互相影响。因为Reids是单线程模型,所以其不存在事务并发执行问题,都是以串行方式执行事务的,可以看成是“串行化隔离级别”。
持久性:事务的持久性是指当事务执行完毕后,其数据已经持久化到磁盘(永久介质)上了,即使服务器停机,事务执行的结果也不会丢失。Reids事务不过是简单的多条命令的集合,并没有为其提供额外的持久化机制,因为事务的持久化依赖于Redis所使用的持久化机制。如果Redis没有配置AOF或者RDB,则Redis事务可以说是没有持久性的。
主备模型
Redis复制
Redis复制功能可以通过执行slaveof命令或者设置slaveof选项来启用(命令格式:slaveof ip port),让一个服务器去复制另一个服务器,一个称为主服务器,另一个为从服务器。从服务器只能进行读取命令操作,而不能更新数据。
Redis 2.8之前的版本不能高效的处理断线后重新复制问题,但是Redis 2.8之后版本新增的部分重同步功能可以解决该问题。Redis 2.8之前版本复制功能分为同步和命令传播两个步骤,在断线重连时,会使用同步来处理数据的同步,也就是再次发送完整的数据库中键值对数据,来保证数据一致性。部分重同步通过复制偏移量、复制积压缓冲区、服务器运行ID3个部分来实现。
Redis 2.8之后版本使用PSYNC命令代替SYNC命令来执行复制时的同步操作,PSYNC具有完全同步和部分同步两种模式,前者用于处理初次复制情况,后者用于处理断线重连时情况,处理PSYNC功能的函数是syncCommand函数。
在复制操作刚开始的时候,从服务器成为主服务器的客户端,并通过向主服务器发送命令请求来执行复制步骤(异步复制),而在复制操作步骤后,主从服务器会互相成为对方的客户端。主服务器通过向服务器传播命令来更新服务器的状态,保持主从服务器一致,而从服务器则每秒通过向主服务器发送命令来进行心跳检测,以及命令丢失检测。
sentinel机制
Sentinel(哨兵)是Redis高可用性解决方案:有一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器,以及这些主服务器下的所有从服务器,并在被监视的主服务器进入下线状态时,自动地将其所属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
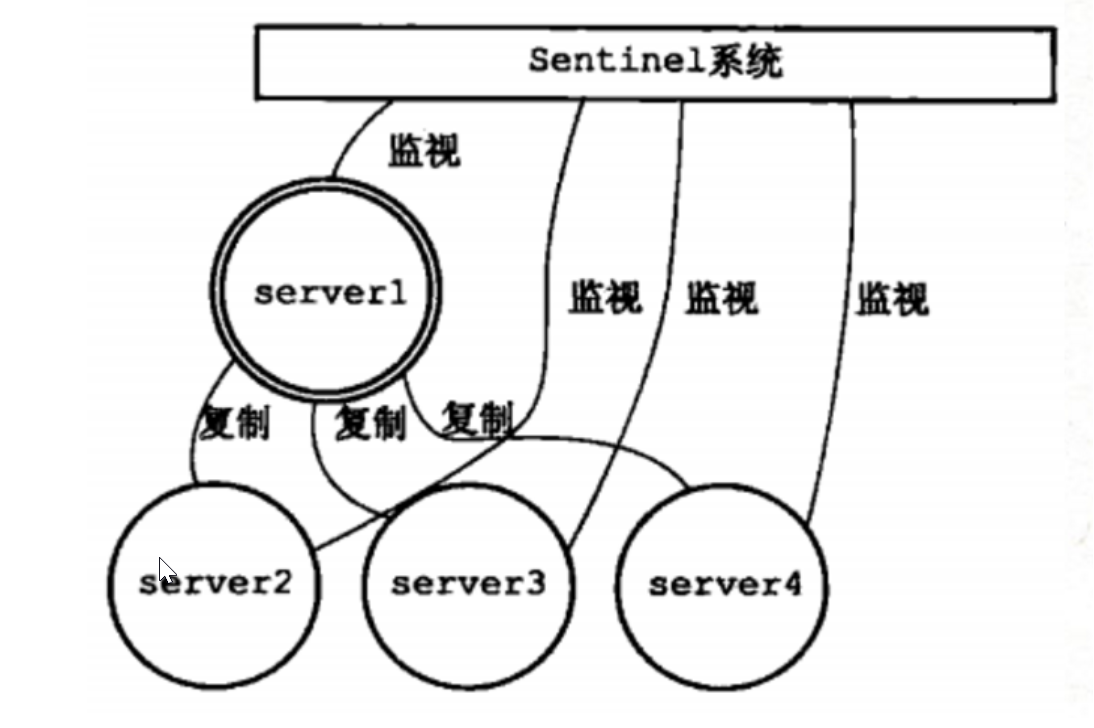
Sentinel只是一个运行在特殊模式下的Redis服务器,Sentinel通过向主服务器发送INFO命令来获取主服务器下所有从服务器的地址信息,然后为所有的从服务器创建相应的实例结构,以及向这些从服务器创建命令连接和订阅连接。一般情况下,Sentinel每10秒向主服务器和所有的从服务器发送INFO命令,当主服务器处于下线状态时,或者Sentinel在进行故障转移时,Sentinel向服务器发送INFO命令的频率改为每秒一次。
对于监视同一个主服务器和从服务器的多个Sentinel来说,它们会以固定频率向被监视的服务器的sentinel:hello频道发送信息来向其他Sentinel宣告自己的存在,Sentinel从该频道接收到其他Sentinel发送的信息,然后为其他Sentinel创建相应的实例结构,并建立命令连接。注意:Sentinel和服务器之间会建立命令连接和频道连接,而Sentinel之间只会建立命令连接。
Sentinel以每秒一次的频率向所有实例连接(包括主服务器、从服务器、Sentinel连接)发送PING命令,并根据实例对PING命令的回复来判断是否在线,如果在一定时间内没有收到回复,Sentinel会将该实例判断为下线。当Sentinel认为主服务器主观下线时,它会向所有监视该主服务器的其他Sentinel询问,是否同意该主服务器已经进入下线状态。当Sentinel收集到足够多的主观下线投票后,它就会将该服务器判断为下线,并发起一次针对该服务器的故障转移操作。
在准备进行故障转移操作时,如果有多个Sentinal同时监听已下线的主服务器,则首先会从这些Sentinel中选取出首领Sentinel,然后由首领Sentinel来主导故障转移流程。Sentinel选取首领Sentinel的算法是Raft算法,一种分布式一致性算法。关于什么是Raft算法可以参考:http://www.cnblogs.com/mindwind/p/5231986.html。
Sentinel主要配置如下:
# Sentinel服务端口
port 26379 # sentinel monitor <master-name> <ip> <port> quorum
# quorum为判断这个实例客观断线所需要的投票数
sentinel monitor mymaster 127.0.0.1 6380 1 # sentinel down-after-milliseconds <master-name> <milliseconds>
#经过多少ms判断实例主观下线
sentinel down-after-milliseconds mymaster 30000 # sentinel parallel-syncs <master-name> <numslaves>
# 执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量
sentinel parallel-syncs mymaster 2 sentinel failover-timeout <master-name> <milliseconds>
# 故障迁移状态的最大时限
sentinel failover-timeout mymaster 900000
sentinel failover步骤:
在下线主服务器的所有从服务器中,选出一个数据状态最接近主服务器的从服务器,选择的条件包括:从服务器未下线、主从之间的连接断开时间最短、复制偏移量(replication offset)最大的那个从服务器,等等。
Sentinel 向被选中的从服务器发送SLAVEOF NO ONE ,将它升级为主服务器。
向其他从服务器发送 SLAVEOF 命令,让它们复制新的主服务器。
cluster机制
Redis cluster是Redis提供的分布式解决方案,集群通过分片(sharding)进行数据共享,并提供复制和故障转移功能。Redis默认对key使用crc16算法计算hash,得到一个整数值,然后取余槽个数(默认16384)得到对应槽号。
Redis集群是由多个节点(Node)组成的,刚开始每个节点都是独立的,运行在只包含自己一个节点的集群中,将多个节点连接起来,就构成了一个包含多个节点可用的集群。连接各个独立节点的功能是由 cluster meet <ip> <port>完成的。
cluster meet(节点握手)执行流程图示:

slot指派
Redis集群通过分片来保存数据库中的键值对,集群的整个数据库被分为16384个槽(slot),数据库中每个键都属于16384个槽中的一个,每个节点处理0个或者最多16384个槽。只有当16384个槽都有节点来存储,整个集群才会处于在线状态。通过使用 culster addslots <slot> [slot ..]命令将一个或者多个槽指派给某个节点负责。
既然集群是通过不同槽的数据交给不同节点来负责,那么节点就需要存储槽指派信息,clusterNode结构的slots属性和numslot属性就记录了槽的指派信息。
typedef struct clusterNode {
//... CLUSTER_SLOTS=16384
unsigned char slots[CLUSTER_SLOTS/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
//...
} clusterNode;
其中numslots表示当前节点负责槽的总个数,slots是一个二进制位数组,根据槽位号i对应的二进制位来判断是否处理槽i,如果对应的二进制位为1表示处理该槽i,否则不处理。
clusterState的slots属性记录了节点的槽指派信息,能够表明一个槽该不该由自己节点来处理,但是不能表明不该自己处理的槽应该由哪个节点来处理。因此clusterState结构中的slots数组记录了集群中所有16384个槽的指派信息。
typedef struct clusterState {
//...
clusterNode *slots[CLUSTER_SLOTS];
//...
} clusterState;
clusterState的slots数组包含16384项,如果slots[i]指针指向的是NULL,表示该槽未指派给任何节点;如果指向了一个clusterNode节点,表示该槽指派给了该clusterNode节点。
注意,虽然clusterState的slots数组记录了集群中所有节点槽指派信息,但是用clusterNode.slots数组来记录单个节点的槽指派信息还是有必要的,因为当Redis需要将某个节点槽指派信息通过消息发送给其他节点时,只需要发送clusterNode.slots数组即可,也不用遍历clusterState.slots数组才能达到发送槽指派信息的目的。
cluster集群命令执行流程
在对数据库中16384个节点都进行指派后,集群就可以开始工作了,当客户端向集群中节点发送命令时,会首先计算数据库键对应的槽(涉及到crc16函数),并检查clusterState.slots数组,来判断该槽位号是否指派给了自己,如果指派给了自己则直接执行命令,否则会向客户单返回一个MOVE错误命令,引导客户端转向到正确的节点继续执行该命令。MOVE错误命令中包含了正确节点的IP和PORT信息,格式为moved <slot> <ip>:<port>。
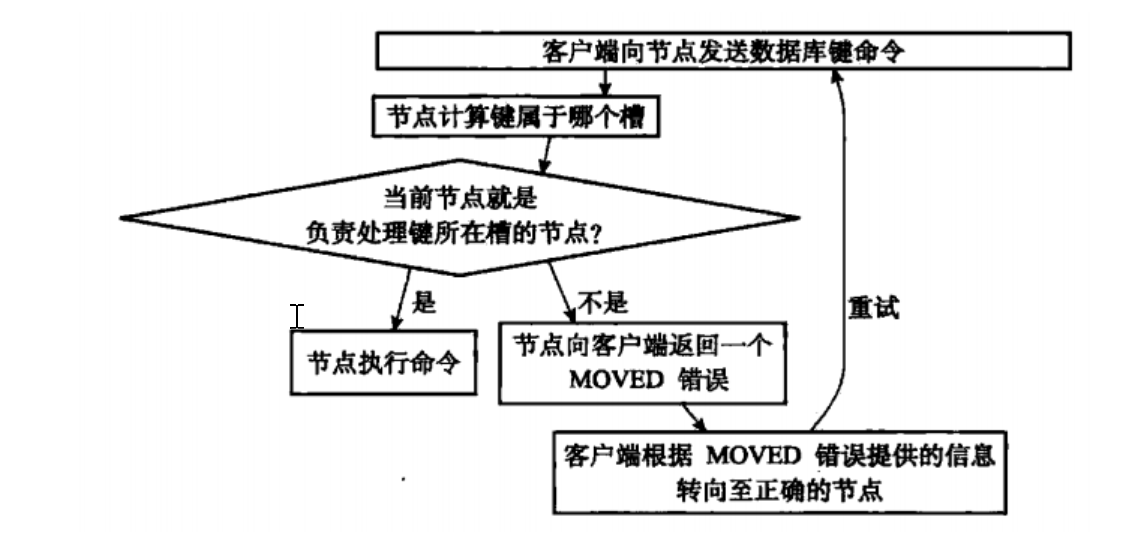
节点和单机数据库一个重要的区别就是节点只能使用0号数据库,而单机Redis服务器没有这个限制。节点除了将键值对保存在数据库里面之外,还会用clusterState结构中的slots_to_keys跳跃表来保存键和槽之间的关系。
重新分片
对Redis进行重新分片的工作是由redis-trab负责执行的,重新分片的关键是如何将原来属于一个节点的数据转移到另一个节点上。如果节点A正在转移槽i的数据到节点B,那么节点A没能在自己的服务器上找到指定的数据库键时,回向客户端返回一个ASK错误,指引客户端到节点B上去获取数据。MOVE表示当前节点不处理要查询键对应的槽位号,需到另一个节点去继续查询;而ASK错误只是在重新分片过程中使用的临时手段而已。
重新分片流程
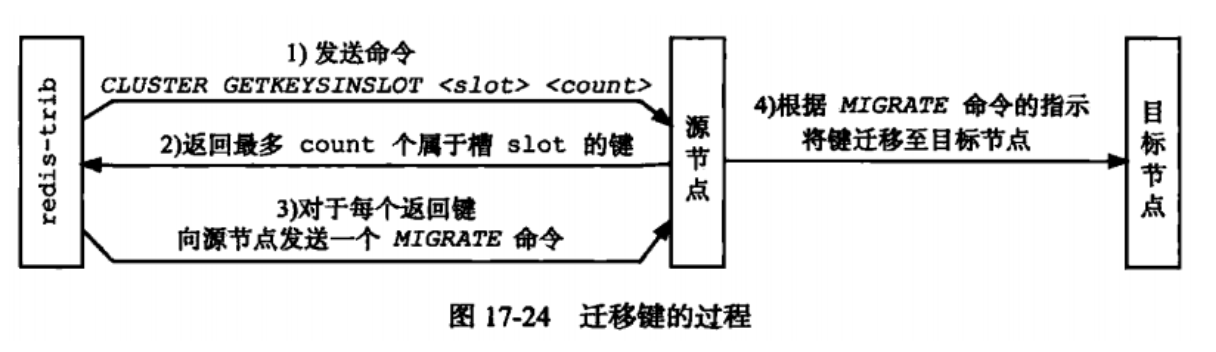
重新分片可以在线进行,不需要集群下线,并且源节点和目的节点可以继续处理命令。Redis提供了进行重新分片的所有命令,而redis-trab负责通过向源节点和目标节点发送命令来进行重新分片操作,步骤如下:
redis-trab对目标节点发送
cluster setslot <slot> importing <source_id>命令来让目标节点做好准备;redis-trab对源节点发送
cluster setslot <slot> migrating <target_id>命令,让目标节点准备好将slot的键值对迁移到目标节点,然后再向源节点发送 cluster getkeysinslot<slot> <count>命令,获取最多count个键值对的键名(key name)。对于获取到的每个键名,redis-trab都会向源节点发送命令
migrate <target_ip> <target_port> <key_name> 0 <timeout>命令,将被选中的键原子的转移到目标节点;重复执行步骤2和3,直到所有的键值对完成迁移工作;
redis-trab向集群中任意一个节点发送
cluster setslot <slot> node <target_id>命令,表明slot指定给了目标节点,这一指派信息最终都会到达所有的节点。
复制和故障转移
集群中的节点通过发送和接收数据来完成通信,常见的消息包括MEET、PING、PONG、PUBLISH、FALL五种类型。集群中的从节点复制于主节点,当主节点下线时,从节点会代替主节点继续完成请求处理任务。设置从节点使用命令:cluster replicate <node_id>。一个从节点开始复制主节点,同时会把这一信息通告给集群中的其他节点,最终集群中所有节点都知道该从节点复制于哪个主节点。
集群中节点都会定期向其他节点发送PING消息,用来检测对方是否在线,如果在规定的时间内有没有收到返回的PONG消息,则把对方节点标记为疑似下线。如果一个集群内有半数以上负责处理槽的主节点都将某个主节点x标记为疑似下线,那么该主节点x就会被标记为已下线,将主节点标记为已下线的节点会将集群中其他节点发送一个关于x的FAIL消息,接收到该消息的主节点都会把主节点x标记为已下线。
当一个从节点发现自己复制的主节点进入已下线转态时,从节点将开始对已下线主节点进行故障转移操作。
从复制下线主节点的所有从节点中选取一个从节点,执行slaveof no one命令,然后该从节点成为新的主节点;
新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己;
新的主节点会向集群中广播一个PONG消息,让其他节点知道该从节点已经成为了主节点,并接管了之前已下线主节点处理的槽;
新的主节点开始执行命令,故障转移完成。
故障转移操作中集群中其他主节点如何从所有从节点中选取新的主节点呢?
这个选举新主节点的方法和选举领头sentinel的方法类似,因为二者都是基于Raft算法的领头选举方法来实现的。集群中其他主节点都可以对故障主节点的所有从节点投票,然后按照投票进行选择从节点替换故障主节点。
文章主要讨论了Redis对象、事件处理机制、持久化机制、事务机制、主备模型、集群机制等内容,限于篇幅因素,剩余内容包括pipeline机制、Redis经典面试题、常见Redis集群方案和一致性hash等在后续文章再进行分享 :)
笔者整理了一份【Redis不完全指南】,包含了很多详细的知识点和Redis经典面试题,可关注公众号,发送 Reids 来获取~

往期精选
从此Redis是路人的更多相关文章
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- Redis基础知识点面试手册
Redis基础知识点面试手册 基础 概述 数据类型 STRING LIST SET HASH ZSET(SORTEDSET) 数据结构 字典 跳跃表 使用场景 会话缓存 缓存 计数器 查找表 消息队列 ...
- 课程笔记:——javascript中的预解释2
in:检测某一个属性是否属于这个对象(既可以检测私有的属性,也可以检测公有的属性) --> attr in obj 1.不管条件是否成立,在预解释的时候,判断体中的带var和function的都 ...
- 是时候放弃sublime了
今天下午在忍无可忍之下终于卸载了sublime,最为一个在gui下最顺手的编辑器,放弃是需要非常充足的理由的. 放弃sublime无非是因为以下几点原因: 收费.我用的是未注册版的sublime,保存 ...
- 【Linux探索之旅】第二部分第一课:终端Terminal,好戏上场
内容简介 1.第二部分第一课:终端Terminal,好戏上场 2.第二部分第二课预告:命令行,世界尽在掌握 终端Terminal,好戏上场 随着第一部分的结束,我们进入了第二部分(小编你这好像是废话. ...
- 如何成为一名优秀的UI设计师
zccst整理 因为我自己就是一个 0 美术基础.非计算机.非艺术类科班出身,但从事视觉设计工作的同学,所以很多和题主一样大学里学着不喜欢的专业,想要转设计但又不知从何开始的朋友都来问过我类似的问题, ...
- 学习Android路上的一些感慨和总结,慢慢来,比较快!
学习Android路上的一些感慨和总结,慢慢来,比较快! 一直想对自己的学习路程做一个总结,来告别某一个阶段的过去,迎接某一个阶段的来临,一直抽不出时间来,于是零零散散的写了点-,到现在,也已经积攒了 ...
- PJ考试可能会用到的数学思维题选讲-自学教程-自学笔记
PJ考试可能会用到的数学思维题选讲 by Pleiades_Antares 是学弟学妹的讲义--然后一部分题目是我弄的一部分来源于洛谷用户@ 普及组的一些数学思维题,所以可能有点菜咯别怪我 OI中的数 ...
- 2013-2015 Aaronyang的又一总结,牧童遥指纳尼村
我没有时间去唠叨自己的事,可是你们是我喜欢的人,ay很愿意写给你们分享:去年的万人阅读的总结链接:<没学历的IT人生没那么悲催,献给程序员们> 提前声明:本文不良反应:请自备垃圾桶,准备装 ...
随机推荐
- git记不住用户名和密码
以前我是用svn的 , 我也是最近才用的git 虽然git 有GUI界面 , 但是我觉得还是不如svn 最开始使用git的时候我们直接clone项目的时候可能会设置全局的账号和密码 , 但是我重装系 ...
- Node child_process Study.2
child_process 模块用于新建子进程.子进程的运行结果存储在系统缓存之中,等到子进程运行结束之后,主进程再用回调函数读取子进程的运行结果 1.exec() exec 方法用于执行base命令 ...
- Windows10的Ubuntu子系统开启桌面环境
原文:Windows10的Ubuntu子系统开启桌面环境 Ubuntu 优势之一就是桌面环境比较好,所以咱们的子系统当然也不能少了这一环节,本小结开始安装Ubuntu 桌面系统. 安装环境 使用下面指 ...
- NYOJ781 又见回文数
又见回文数 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描写叙述 冷淡的回文数被水了,各种被水,然后他非常生气,然后... 一个数从左边读和从右边读一样,就说这个数是回文数 ...
- python win32api 使用小技巧
前些日子,由于需要,用python写了个小插件,通过win32api 访问外部程序的窗口 并且做些小操作. 因为原来对win32api 不怎么熟悉 所以只好求救.群里有个QQ:32034767 唐骁勇 ...
- WPF 将图片进行灰度处理
原文:WPF 将图片进行灰度处理 处理前: 处理后: 这个功能使用使用了 FormatConvertedBitmap(为BitmapSource提供像素格式转换功能) 代码如下: ...
- WPF 路由事件 Event Routing
原文:WPF 路由事件 Event Routing 1.路由事件介绍 之前介绍了WPF的新的依赖属性系统,本篇将介绍更高级的路由事件,替换了之前的.net普通事件.相比.net的事件,路由事件具有更强 ...
- 自定义 DependencyProperty 与 RoutedEvent
原文:自定义 DependencyProperty 与 RoutedEvent //自定义依赖属性 class MyBook : DependencyObject//依赖属性必须派生自Dependen ...
- Bootstrap 反色导航条
@{ Layout = null;}<!DOCTYPE html><html><head> <meta name="viewport&q ...
- UNITY VR 视频/图片 开发心得(二)
上回说到了普通的全景图片,这回讲真正的VR. 由于这种图片分为两部分,所以我们需要两个Camera对象以及两个球体.首先新建一个Camera对象,并将其命名为RightEye(其它名字也无妨,只要你自 ...