Intel 的 MKL是可以用来训练的——官方的实验也提到了训练
TensorFlow如何充分使用所有CPU核数,提高TensorFlow的CPU使用率,以及Intel的MKL加速
TensorFlow如何充分使用所有CPU核数,提高TensorFlow的CPU使用率,以及Intel的MKL加速
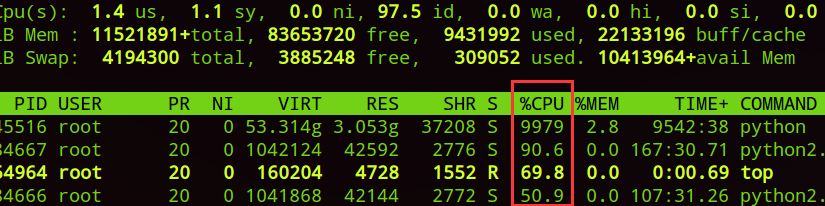
许多朋友使用服务器时,碰巧服务器没有安装GPU或者GPU都被占满了。可是,服务器有很多CPU都是空闲的,其实,把这些CPU都充分利用起来,也可以有不错的训练效果。
但是,如果你是用CPU版的TF,有时TensorFlow并不能把所有CPU核数使用到,这时有个小技巧David 9要告诉大家:
- with tf.Session(config=tf.ConfigProto(
- device_count={"CPU":12},
- inter_op_parallelism_threads=1,
- intra_op_parallelism_threads=1,
- gpu_options=gpu_options,
- )) as sess:
在Session定义时,ConfigProto中可以尝试指定下面三个参数:
- device_count, 告诉tf Session使用CPU数量上限,如果你的CPU数量较多,可以适当加大这个值
- inter_op_parallelism_threads和intra_op_parallelism_threads告诉session操作的线程并行程度,如果值越小,线程的复用就越少,越可能使用较多的CPU核数。如果值为0,TF会自动选择一个合适的值。
David 9亲自试验,训练似乎有1倍速度的提高。
另外,有的朋友的服务器上正好都是Intel的CPU,很可能需要把Intel的MKL包编译进TensorFlow中,以增加训练效率。这里David 9把MKL编译进TF的关键点也指出一下。
- Run “./configure” from the TensorFlow source directory, and it will download latest Intel MKL for machine learning automatically in tensorflow/third_party/mkl/mklml if you select the options to use Intel MKL
- Execute the following commands to create a pip package that can be used to install the optimized TensorFlow build.
- PATH can be changed to point to a specific version of GCC compiler:
export PATH=/PATH/gcc/bin:$PATH - LD_LIBRARY_PATH can also be changed to point to new GLIBC :
- export LD_LIBRARY_PATH=/PATH/gcc/lib64:$LD_LIBRARY_PATH.
- Build for best performance on Intel Xeon and Intel Xeon Phi processors:
- bazel build --config=mkl --copt="-DEIGEN_USE_VML"
-c opt //tensorflow/tools/pip_package: - build_pip_package
- bazel build --config=mkl --copt="-DEIGEN_USE_VML"
- PATH can be changed to point to a specific version of GCC compiler:
3. Install the optimized TensorFlow wheel
- bazel-bin/tensorflow/tools/pip_package/build_pip_package
~/path_to_save_wheel - pip install --upgrade --user ~/path_to_save_wheel /wheel_name.whl
与官网编译TF的大致流程类似,就是先./configure,再用bazel编译TensorFlow。
最后用编译好的bazel工具生成whl的包,用来安装pip TensorFlow。
唯一的不同要注意用–config=mkl的选项编译TensorFlow:
bazel build –config=mkl –copt=”-DEIGEN_USE_VML” -c opt //tensorflow/tools/pip_package: build_pip_package
这样,用pip安装完成TF后,mkl就集成在TF中了。
参考文献:
- https://software.intel.com/es-es/articles/tensorflow-optimizations-on-modern-intel-architecture
- https://richardstechnotes.wordpress.com/2016/08/09/encouraging-tensorflow-to-use-more-cores/
- https://www.tensorflow.org/install/install_sources
现代英特尔® 架构上的 TensorFlow* 优化
英特尔:Elmoustapha Ould-Ahmed-Vall,Mahmoud Abuzaina,Md Faijul Amin,Jayaram Bobba,Roman S Dubtsov,Evarist M Fomenko,Mukesh Gangadhar,Niranjan Hasabnis,Jing Huang,Deepthi Karkada,Young Jin Kim,Srihari Makineni,Dmitri Mishura,Karthik Raman,AG Ramesh,Vivek V Rane,Michael Riera,Dmitry Sergeev,Vamsi Sripathi,Bhavani Subramanian,Lakshay Tokas,Antonio C Valles
谷歌:Andy Davis,Toby Boyd,Megan Kacholia,Rasmus Larsen,Rajat Monga,Thiru Palanisamy,Vijay Vasudevan,Yao Zhang
作为一款领先的深度学习和机器学习框架,TensorFlow* 对英特尔和谷歌发挥英特尔硬件产品的最佳性能至关重要。本文 向人工智能 (AI) 社区介绍了在基于英特尔® 至强和英特尔® 至强融核™ 处理器的平台上实施的 TensorFlow* 优化。在去年举办的首届英特尔人工智能日上,英特尔公司的柏安娜和谷歌的 Diane Green 共同宣布了双方的合作,这些优化是英特尔和谷歌工程师密切合作取得的成果。
我们介绍了在优化实践中遇到的各种性能挑战以及采用的解决方法,还报告了对通用神经网络模型示例的性能改进。这些优化带来了多个数量级的性能提升。例如,根据我们的测量,英特尔® 至强融核™ 处理器 7250 (KNL) 上的训练性能提升了高达 70 倍,推断性能提升了高达 85 倍。基于英特尔® 至强® 处理器 E5 v4 (BDW) 和英特尔至强融核处理器 7250 的平台为下一代英特尔产品奠定了基础。用户尤其希望今年晚些时候推出的英特尔至强(代号为 Skylake)和英特尔至强融合(代号为 Knights Mill)处理器将提供显著的性能提升。
在现代 CPU 上优化深度学习模型的性能面临众多挑战,和优化高性能计算 (HPC) 中其他性能敏感型应用所面临的挑战差别不大:
- 需要重构代码,以利用现代矢量指令。这意味着将所有关键基元(如卷积、矩阵乘法和批归一化)被向量化为最新 SIMD 指令(英特尔至强处理器为 AVX2,英特尔至强融核处理器为d AVX512)。
- 要想实现最佳性能,需要特别注意高效利用所有内核。这意味着在特定层或操作实施并行化以及跨层的并行化。
- 根据执行单元的需要,提供尽可能多的数据。这意味着需要平衡使用预取、缓存限制技术和改进空间和时间局部性的数据格式。
为了满足这些要求,英特尔开发了众多优化型深度学习基元,计划应用于不同的深度学习框架,以确保通用构建模块的高效实施。除了矩阵乘法和卷积以外,创建模块还包括:
- 直接批量卷积
- 内积
- 池化:最大、最小、平均
- 标准化:跨通道局部响应归一化 (LRN),批归一化
- 激活:修正线性单元 (ReLU)
- 数据操作:多维转置(转换)、拆分、合并、求和和缩放。
请参阅 本文,获取关于面向深度神经网络的英特尔® 数学核心函数(英特尔® MKL-DNN)的优化基元的更多详情。
在 TensorFlow 中,我们实施了英特尔优化版运算,以确保这些运算能在任何情况下利用英特尔 MKL-DNN 基元。同时,这也是支持英特尔® 架构可扩展性能的必要步骤,我们还需要实施大量其他优化。特别是,因为性能原因,英特尔 MKL 使用了不同于 TensorFlow 默认布局的另一种布局。我们需要最大限度地降低两种格式的转换开销。我们还想确保数据科学家和其他 TensorFlow 用户不需要改变现有的神经网络模型,便可使用这些优化。

图形优化
我们推出了大量图形优化通道,以:
- 在 CPU 上运行时,将默认的 TensorFlow 操作替换为英特尔优化版本。确保用户能运行现有的 Python 程序,在不改变神经网络模型的情况下提升性能。
- 消除不必要且昂贵的数据布局转换。
- 将多个运算融合在一起,确保在 CPU 上高效地重复使用高速缓存。
- 处理支持快速向后传播的中间状态。
这些图形优化进一步提升了性能,没有为 TensorFlow 编程人员带来任何额外负担。数据布局优化是一项关键的性能优化。对于 CPU 上的某些张量运算而言,本地 TensorFlow 数据格式通常不是最高效的数据布局。在这种情况下,将来自 TensorFlow 本地格式的数据布局转换运算插入内部格式,在 CPU 上执行运算,并将运算输出转换回 TensorFlow 格式。但是,这些转换造成了性能开销,应尽力降低这些开销。我们的数据布局优化发现了能利用英特尔 MKL 优化运算完全执行的子图,并消除了子图运算中的转换。自动插入的转换节点在子图边界执行数据布局转换。融合通道是另一个关键优化,它将多个运算自动融合为高效运行的单个英特尔 MKL 运算。
其他优化
我们还调整众多 TensorFlow 框架组件,以确保在各种深度学习模型上实现最高的 CPU 性能。我们使用 TensorFlow 中现成的池分配器开发了一款自定义池分配器。我们的自定义池分配器确保了 TensorFlow 和英特尔 MKL 共享相同的内存池(使用英特尔 MKL imalloc 功能),不必过早地将内存返回至操作系统,因此避免了昂贵的页面缺失和页面清除。此外,我们还认真优化了多个线程库(TensorFlow 使用的 pthread 和英特尔 MKL 使用的 OpenMP),使它们能共存,而不是互相争夺 CPU 资源。
性能实验
我们的优化(如上述优化)在英特尔至强和英特尔至强融核平台上实现了显著的性能提升。为了更好地展示性能改进,我们提供了以下最佳方法(或 BKM)和 3 个通用 ConvNet 性能指标评测的基准和优化性能值。
- 以下参数对英特尔至强(代号为 Broadwell)和英特尔至强融核(代号为 Knights Landing)的性能非常重要,建议您针对特定的神经网络模型和平台优化这些参数。我们认真优化了这些参数,力求在英特尔至强和英特尔至强融核处理器上获得 convnet 性能指标评测的最佳性能。
- 数据格式:建议用户针对特定的神经网络模型指定 NCHW 格式,以实现最佳性能。TensorFlow 默认的 NHWC 格式不是 CPU 上最高效的数据布局,将带来额外的转换开销。
- Inter-op / intra-op:建议数据科学家和用户在 TensorFlow 中试验 intra-op 和 inter-op 参数,为每个模型和 CPU 平台搭配最佳设置。这些设置将影响某层或跨层的并行性。
- 批处理大小 (Batch size):批处理大小是影响可用并行性(以使用全部内核)、工作集大小和总体内存性能的另一个重要参数。
- OMP_NUM_THREADS:最佳性能需要高效使用所有可用内核。由于该设置控制超线程等级(1 到 4),因此,对英特尔至强融核处理器的性能尤为重要。
- 矩阵乘法中的转置 (Transpose in Matrix multiplication):对于某些矩阵大小,转置第二个输入矩阵 b 有助于改进 Matmul 层的性能(改进高速缓存的重复使用)。以下 3 个模型所用的所有 Matmul 运算亦是如此。用户应在其他尺寸的矩阵中试验该设置。
- KMP_BLOCKTIME:用户应试验各种设置,以确定每个线程完成并行区域执行后等待的时间,单位为毫秒。
英特尔® 至强® 处理器(代号为 Broadwell - 双插槽 - 22 个内核)上的示例设置

英特尔® 至强融核™ 处理器(代号为 Knights Landing - 68 个内核)上的示例设置

- 英特尔® 至强® 处理器(代号为 Broadwell – 双插槽 – 22 个内核)的性能结果

- 英特尔® 至强融核™ 处理器(代号为 Knights Landing – 68 个内核)的性能结果

- 英特尔® 至强® 处理器(代号为 Broadwell)和英特尔® 至强融核™ 处理器(代号为 Knights Landing)上不同批处理尺寸的性能结果 - 训练



利用 CPU 优化安装 TensorFlow
按照“现已推出英特尔优化型 TensorFlow 系统”中的指令安装包含 pip 或 conda 的预构建二进制软件包,或按照以下指令从源构建:
- 运行 TensorFlow 源目录中的 "./configure",如果您选择了使用英特尔 MKL 的选项,将自动下载 tensorflow/third_party/mkl/mklml 中的面向机器学习的最新版英特尔 MKL。
- 执行以下命令创建 pip 程序包,以安装经过优化的 TensorFlow 创建。
- 可更改 PATH,使其指向特定 GCC 编译器版本:
export PATH=/PATH/gcc/bin:$PATH - 也可以更改 LD_LIBRARY_PATH,使其指向新 GLIBC:
export LD_LIBRARY_PATH=/PATH/gcc/lib64:$LD_LIBRARY_PATH. - 专为在英特尔至强和英特尔至强融核处理器上实现最佳性能而创建:
bazel build --config=mkl --copt=”-DEIGEN_USE_VML” -c opt //tensorflow/tools/pip_package:
build_pip_package
- 可更改 PATH,使其指向特定 GCC 编译器版本:
- 安装优化版 TensorFlow 系统
- bazel-bin/tensorflow/tools/pip_package/build_pip_package ~/path_to_save_wheel
pip install --upgrade --user ~/path_to_save_wheel /wheel_name.whl
- bazel-bin/tensorflow/tools/pip_package/build_pip_package ~/path_to_save_wheel
系统配置

对人工智能意味着什么
优化
TensorFlow
意味着高度可用、广泛应用的框架创建的深度学习应用现在能更快速地运行于英特尔处理器,以扩大灵活性、可访问性和规模。例如,英特尔至强融核处理器能以近乎线性的方式跨内核和节点横向扩展,可显著减少训练机器学习模型的时间。我们不断增强英特尔处理器的性能,以处理更大、更困难的人工智能工作负载,TensorFlow
也能随着性能的进步而升级。
英特尔和谷歌共同优化 TensorFlow
的合作体现了双方面向开发人员和数据科学家普及人工智能的不懈努力,力求在从边缘到云的所有设备上随时运行人工智能应用。英特尔相信这是创建下一代人工智能算法和模型的关键,有助于解决最紧迫的业务、科学、工程、医学和社会问题。
本次合作已经在基于英特尔至强和英特尔至强融核处理器的领先平台上实现了显著的性能提升。这些优化现已在谷歌的 TensorFlow GitHub 存储库中推出。我们建议人工智能社区尝试这些优化,并期待获得基于优化的反馈与贡献。
Intel 的 MKL是可以用来训练的——官方的实验也提到了训练的更多相关文章
- 谷歌BERT预训练源码解析(三):训练过程
目录前言源码解析主函数自定义模型遮蔽词预测下一句预测规范化数据集前言本部分介绍BERT训练过程,BERT模型训练过程是在自己的TPU上进行的,这部分我没做过研究所以不做深入探讨.BERT针对两个任务同 ...
- 谷歌BERT预训练源码解析(一):训练数据生成
目录预训练源码结构简介输入输出源码解析参数主函数创建训练实例下一句预测&实例生成随机遮蔽输出结果一览预训练源码结构简介关于BERT,简单来说,它是一个基于Transformer架构,结合遮蔽词 ...
- 知识增广的预训练语言模型K-BERT:将知识图谱作为训练语料
原创作者 | 杨健 论文标题: K-BERT: Enabling Language Representation with Knowledge Graph 收录会议: AAAI 论文链接: https ...
- 如何借助 JuiceFS 为 AI 模型训练提速 7 倍
背景 海量且优质的数据集是一个好的 AI 模型的基石之一,如何存储.管理这些数据集,以及在模型训练时提升 I/O 效率一直都是 AI 平台工程师和算法科学家特别关注的事情.不论是单机训练还是分布式训练 ...
- [论文理解] An Analysis of Scale Invariance in Object Detection – SNIP
An Analysis of Scale Invariance in Object Detection – SNIP 简介 小目标问题一直是目标检测领域一个比较难解决的问题,因为小目标提供的信息比较少 ...
- 现代英特尔® 架构上的 TensorFlow* 优化——正如去年参加Intel AI会议一样,Intel自己提供了对接自己AI CPU优化版本的Tensorflow,下载链接见后,同时可以基于谷歌官方的tf版本直接编译生成安装包
现代英特尔® 架构上的 TensorFlow* 优化 转自:https://software.intel.com/zh-cn/articles/tensorflow-optimizations-on- ...
- tflearn kears GAN官方demo代码——本质上GAN是先训练判别模型让你能够识别噪声,然后生成模型基于噪声生成数据,目标是让判别模型出错。GAN的过程就是训练这个生成模型参数!!!
GAN:通过 将 样本 特征 化 以后, 告诉 模型 哪些 样本 是 黑 哪些 是 白, 模型 通过 训练 后, 理解 了 黑白 样本 的 区别, 再输入 测试 样本 时, 模型 就可以 根据 以往 ...
- x86 构架的 Arduino 开发板Intel Galileo
RobotPeak是上海的一家硬件创业团队,团队致力于民用机器人平台系统.机器人操作系统(ROS)以及相关设备的设计研发,并尝试将日新月异的机器人技术融入人们的日常生活与娱乐当中.同时,RobotPe ...
- 第三十二节,使用谷歌Object Detection API进行目标检测、训练新的模型(使用VOC 2012数据集)
前面已经介绍了几种经典的目标检测算法,光学习理论不实践的效果并不大,这里我们使用谷歌的开源框架来实现目标检测.至于为什么不去自己实现呢?主要是因为自己实现比较麻烦,而且调参比较麻烦,我们直接利用别人的 ...
随机推荐
- spring jdbc、事务(三)
spring整合jdbc spring中提供了一个可以操作数据库的对象(JDBCTemplate),对象封装了jdbc技术. 1.使用spring整合jdbc需要jdbc驱动.c3p0连接池.spri ...
- Oracle 数据导入导出(imp/exp)
环境:windows下,oracle11g 1.启动oracle服务 net start OracleDBConsoleorclnet start OracleOraDb11g_home1TNSLis ...
- Java多线程-synchronized关键字
进程:是一个正在执行中的程序.每一个进程执行都有一个执行顺序.该顺序是一个执行路径,或者叫一个控制单元. 线程:就是进程中的一个独立的控制单元.线程在控制着进程的执行. 一个进程中至少有一个线程 Ja ...
- [转载]MySql事物处理
事务处理在各种管理系统中都有着广泛的应用,比如人员管理系统,很多同步数据库操作大都需要用到事务处理.比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如 ...
- 图像局部显著性—点特征(FREAK)
参考文章:Freak特征提取算法 圆形区域分割 一.Brisk特征的计算过程(参考对比): 1.建立尺度空间:产生8层Octive层. 2.特征点检测:对这8张图进行FAST9-16角点检测,得到具 ...
- HDU_2149_基础博弈sg函数
Public Sale Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- PyCharm 恢复默认设置 | JetBrains IDE 配置文件安装目录
网上的答案为什么都乱七八糟并且全都全篇一律?某度知道是发源地? 先说 Mac 按需运行下面的 rm 删除命令 # Configuration rm -rf ~/Library/Preferences/ ...
- mysql安装包下载地址
1.打开mysql官网 :https://dev.mysql.com/ 2.选择 downlad-->windows-->MySQL Installer -->滑动至页面底部,选择第 ...
- Linux 重要文件目录
文件系统层次化标准(Filesystem Hierarchy Standard)[FHS] 树形结构 /boot 开机所需文件——内核开机菜单以及所需的配置文件等 /dev 以文件形式存放任何设备与接 ...
- uni-app强大的前端框架,h5,原生app(两大系统),微信小程序
最近发现一款强大的前端框架,它叫uni-app 这是一款通用的框架可以打包app,h5,微信小程序, 说说要弄这个工具需要会那些技能吧, 要熟悉vue,微信小程序.这样这个框架用的就是很快上手了 模块 ...