caffe(3) 视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN)局部相应归一化, im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
type:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
2、Pooling层
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
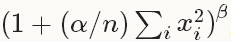 ,得到归一化后的输出
,得到归一化后的输出 layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
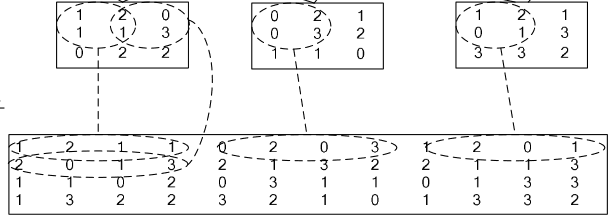
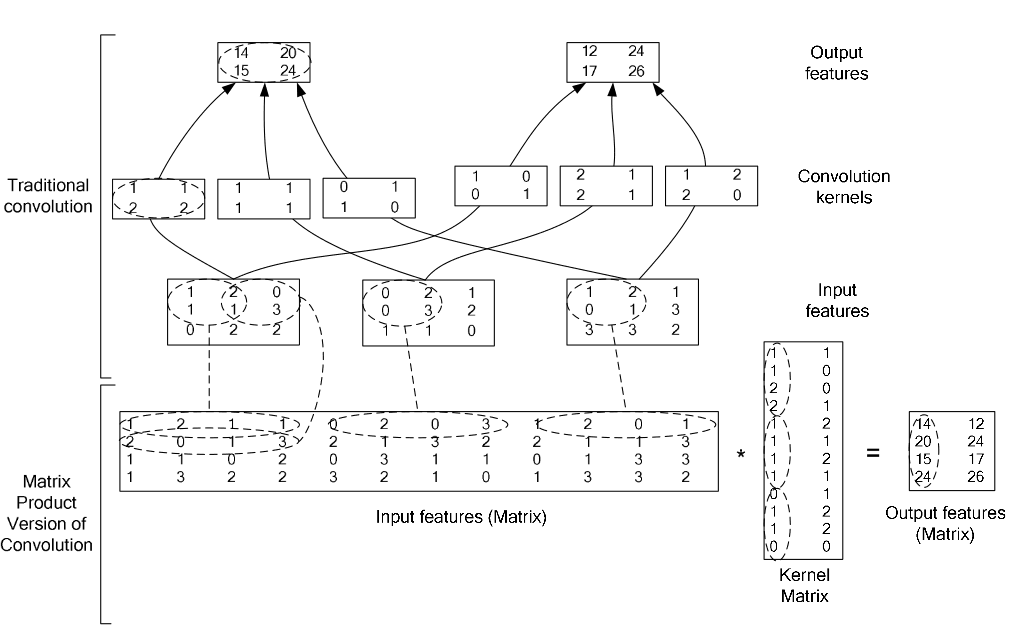
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
caffe(3) 视觉层及参数的更多相关文章
- 【转】Caffe初试(五)视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. ...
- 4、Caffe其它常用层及参数
借鉴自:http://www.cnblogs.com/denny402/p/5072746.html 本文讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accu ...
- caffe(2) 数据层及参数
要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个屋(layer)构成,每一屋又由许多参数组成.所有的参数都定义在caffe.proto这个文件 ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- [转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 1.Convolution层: 就是卷积层,是卷积神经 ...
- [caffe]网络各层参数设置
数据层 数据层是模型最底层,提供提供数据输入和数据从Blobs转换成别的格式进行保存输出,通常数据预处理(减去均值,放大缩小,裁剪和镜像等)也在这一层设置参数实现. 参数设置: name: 名称 ty ...
- caffe学习系列(4):视觉层介绍
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 这里介绍下conv层. layer { name: & ...
- Caffe学习系列(5):其它常用层及参数
本文讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accuracy层,reshape层和dropout层及其它们的参数配置. 1.softmax-loss so ...
随机推荐
- xBIM 基础16 IFC的空间层次结构
系列目录 [已更新最新开发文章,点击查看详细] 本篇介绍如何从文件中检索空间结构.IFC中的空间结构表示层次结构的嵌套结构,表示项目,站点,建筑物,楼层和空间.如果您查看IFC文档, 您会发现 ...
- BZOJ 2127 二元关系
题意: 思路: 先把所有的值加起来 最小割割哪儿 就代表那个地方不选 一减 剩下的就是 最大值了 //By SiriusRen #include <cstdio> #include < ...
- APACHE KYLIN™ 概览(分布式分析引擎)
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区.它能 ...
- Gulp 相关
获取执行在文件列表: http://www.thinksaas.cn/ask/question/21950/ 用through2这个插件. var through = require('through ...
- NEON基本知识
http://blog.csdn.net/EmSoftEn/article/details/51834171 http://blog.csdn.net/yxnyxnyxnyxnyxn/article/ ...
- array_key_exists()
array_key_exists()方法用于检查键名是否存在数组中. <?php $a=array("name"=>"XC90","tex ...
- http_build_query 字符串拼接
http_build_query 字符串拼接 产生一个urlencode之后的请求字符串. 1.将数组转化成url问号(?)后的字符串 <?php $date=array( 'name'=> ...
- java后台生成图片二维码
controller: /** * 获取登录的验证码 * @param request * @param response */ public void getLoginCode(HttpSessio ...
- MySQL中将数据库表名修改成大写的存储过程
原文:MySQL中将数据库表名修改成大写的存储过程 MySQL中将数据库表名修改成大写的存储过程 创建存储过程的代码: DROP PROCEDURE IF EXISTS uppercaseTablen ...
- [Java] 使用 Apache的 Commons-net库 实现FTP操作
因为最近工作中需要用到FTP操作,而手上又没有现成的FTP代码.就去网上找了一下,发现大家都使用Apache的 Commons-net库中的FTPClient. 但是,感觉用起来不太方便.又在网上找到 ...