SSD学习笔记
目标检测算法——SSD:Single Shot MultiBox Detector,是一篇非常经典的目标检测算法,十分值得阅读和进行代码复现,其论文地址是:https://arxiv.org/abs/1512.02325
一、前言
1.1 什么是SSD
从论文的题目《SSD:Single Shot MultiBox Detector》可以看出,single shot表明是one_stage检测算法,即不需要类似faster R-CNN中的RPN等区域推荐算法,一步就能得到预测坐标和类别,实现真正的end-to-end训练;multibox表示是多框预测,即SSD算法借鉴了faster R-CNN中的锚点框思想,对每个先验锚点框进行预测,判断其类别和目标的预测框。
1.2 为什么提出SSD
在SSD算法提出之前,R-CNN系列的目标检测算法,其准确率很高,但是这些算法需要消耗大量计算资源,特别是对于嵌入式设备或者终端设备,其算力无法满足此类算法,造成了无法进行实时目标检测。
目标检测的检测速度通常使用FPS进行衡量,即1秒能处理多少帧。Faster R-CNN的检测速度只有7FPS,虽然已经比以前的算法快很多了,但远远还达不到实时检测的效果。虽然后续对faster R-CNN做了很多改进来提高FPS,但这些增益都是以牺牲大量精度为前提。
因此,急需一种速度快且精度不低的目标检测算法。
1.3 如何平衡速度与精度
如下图所示,下图是R-CNN系列,YOLO和SSD的性能对比图(Ref.《目标检测算法之SSD》),可以看出SSD在速度和mAP上都有较大的提升。

那么,SSD能实现速度与精度的平衡,是通过以下方式来实现的:
a) 改变网络结构,并使用多尺度融合;
b) 精心设计先验锚点框,和锚点框匹配策略;
c) 使用多个tricks来提高精度,如用于平衡正负样本数量的难例挖掘(hard negative mining)和数据增强。
二、网络结构
如图1所示,是SSD的网络结构。在论文中,图片的输入尺寸为300*300*3,使用VGG16作为主干网络,同时,做出了以下修改:
- 将原本VGG16的FC6和FC7换成卷积层Conv6和Conv7,并依次加入新的层:Conv8_2,Conv9_2,Conv10_2,Conv11_2。具体而言,在Conv7层的特征图为19*19*1024,经过1*1*256和3*3*512-s2的卷积操作后,得到Conv8_2的特征图,其尺寸为10*10*512,依次类推。
- 为了实现多尺度融合,需要将不同层的特征图提取出来进行判断。在论文中,作者使用Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2的特征图来进行多尺度融合。如图2所示,每层特征图会分别经过3*3的卷积,得到2个tensor,分别用于进行坐标预测和类别置信度预测。其中,用于坐标预测的通道数是(num_anchor*4),num_anchor表示该特征图每个位置对应的锚点框数量,4表示(x_min,y_min,x_max,y_max);用于类别置信度预测的通道数是(num_anchor*num_classes),num_classes表示类别的数量(包含背景),对于VOC来说,num_classes=21,20个类别加上1个背景。另外,论文中会对Conv4_3层的特征图使用L2归一化后,再进行3*3的卷积,这样做的目的是,防止此层特征图的值过大,利于收敛。
对于需要融合的特征图,假设此特征图的尺寸是w*h,那么,对于每个位置(x,y),会预先生成N个锚点框(具体锚点框的细节,下面会叙述),因此,每张特征图会生成w*h*N个锚点框。SSD通过对每个锚点框进行位置回归和类别预测,并通过NMS非极大值抑制得到最终的检测结果。
SSD算法会生成一系列预测框(bounding boxes)和每个预测框的得分,然后通过NMS非极大值抑制得到最终的检测结果。如下图所示,是SSD的网络结构。

图1 SSD的网络结构
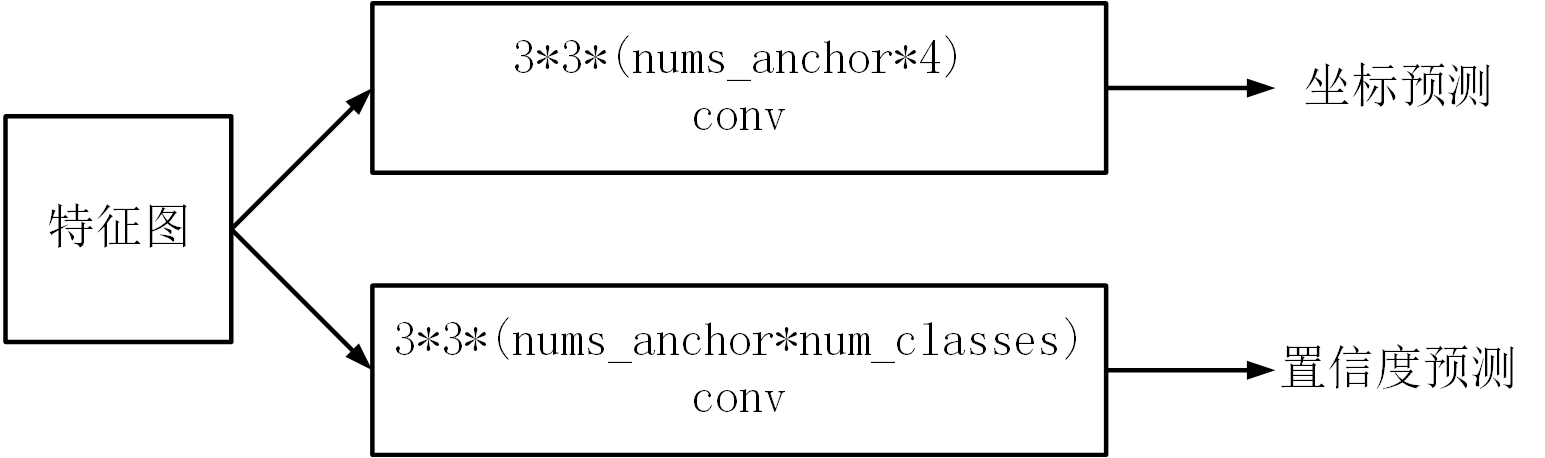
图2 特征图的处理
三、锚点框
SSD的锚点框借鉴了faster R-CNN的锚点框思想,但不同的是,在SSD中,每个特征图对应的锚点框均不相同,即锚点框会根据特征图的尺寸发生变化。例如,Conv4_3的锚点框和Conv7的锚点框的尺寸是不一样的。假定使用m张特征图进行预测判断,每张特征图的锚点框大小,可以通过下式进行计算:
$$s_k=s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1),k\in [1,m]$$
其中,$s_{min}=0.2$和$s_{max}=0.9$,表示Conv4_3特征图的锚点框的尺寸为0.2,Conv11_2特征图的锚点框尺寸为0.9。既然有了锚点框的大小,可以理解为面积,接下来就需要为锚点框设置不同的宽高比。作者设置了5种宽高比,分别是$a_r={1,2,3,1/2,1/3}$,因此,可以计算得到宽度$w_k^a=s_k\sqrt{a_r}$,高度为$h_k^a=s_k/\sqrt{a_r}$。对于宽高比为1的情况,额外增加一个锚点框,其尺寸为${s_k}'=\sqrt{s_ks_{k+1}}$。所以,一般而言,第i层特征图的(x,y)位置,具有6个锚点框。而第一层特征图和最后两层层特征图,每个位置只设置4个锚点框。因此,图1中的8732个锚点框是这样计算得到的,$38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732$。
通过对不同特征图设置不同的锚点框,有利于检测不同尺寸的物体,大特征图可检测小物体,小特征图可以检测大物体。如图3所示,(a)表示带GT框的图像;(b)表示在8*8的特征图中,每个位置使用6个不同尺寸的锚点框,当某个锚点框与GT框的IOU大于阈值时,将其设置成正样本,该位置下其他锚点框为负样本;(c)表示4*4特征图下,红色虚线框用于预测狗的情况,会输出loc和conf两个tensor,loc表示相对于锚点框的偏移量,conf表示每个类别的置信度。
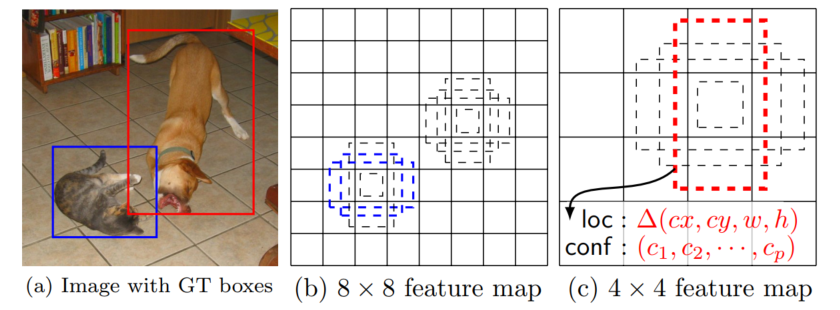
图3 锚点框匹配
当设定了锚点框后,就需要制定其匹配规则,即制定哪些锚点框用于回归GT框和预测类别。首先,为每个GT框匹配一个与其IOU最高的先验锚点框,保证了每个GT框都有对应的锚点框,来预测GT框;其次,当GT框与先验锚点框的IOU大于阈值(0.5)时,也指定该锚点框用来预测该GT框。当然,若锚点框A与多个GT框的IOU都大于阈值,则该锚点框A选择与其IOU最大的GT框。
图4是锚点框与GT框的匹配示意图,为了方便理解,将锚点框映射回原图尺寸,与GT框进行匹配。
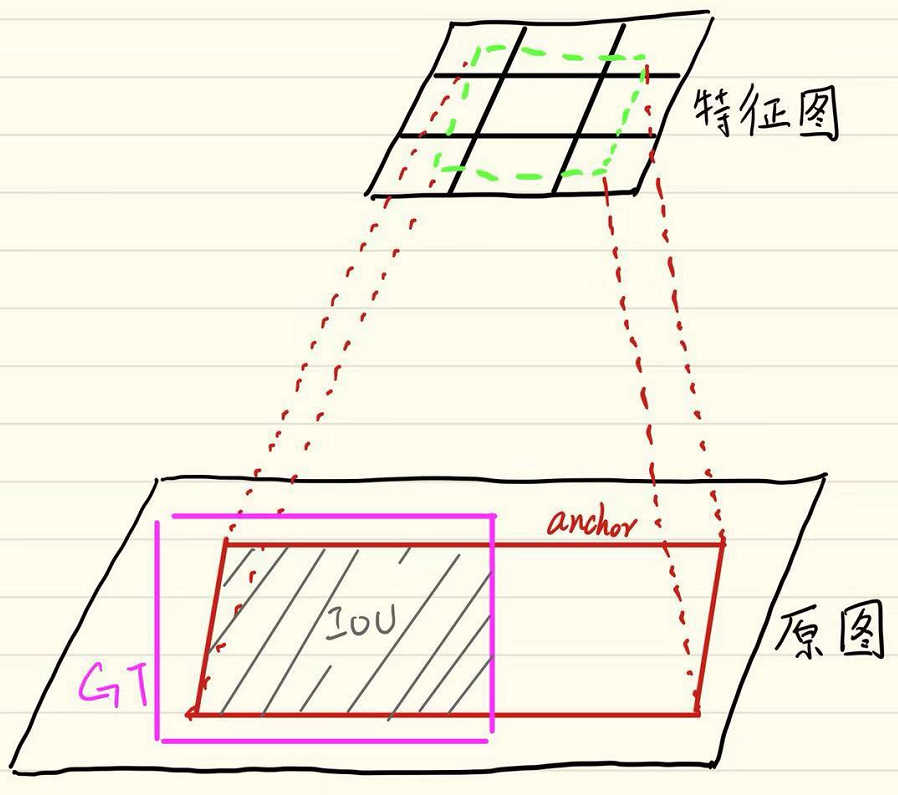
图4 锚点框与GT框的匹配
四、其余策略
- SSD的损失函数继承了R-CNN系列的损失函数,如下所示,由位置损失和置信度损失组成,位置损失使用了smooth1,置信度损失使用多类别交叉熵:
$$L(x,c,l,g)=\frac{1}{N}(L_{conf}(x,c)+\alpha L_{loc}(x,l,g))L(x,c,l,g)=\frac{1}{N}(L_{conf}(x,c)+\alpha L_{loc}(x,l,g))$$
- 此外,SSD可以理解成对图片进行密集采样,得到8732个patch,然后对这些patch进行预测和回归。因此,会发现,大部分锚点框都会匹配上背景,也就是被设置成负样本。因此,会造成正负样本之间的不平衡。对于此情况,SSD使用了hard negative mining策略来缓解这一锚段。在SSD中,并没有使用所有的负样本,而是将这些匹配上背景的样本根据置信度损失进行降序排列,取出置信度损失进行排序,将损失较大的样本认为是难例(hard negative),需要模型重点学习。选取损失最大的前N个样本作为负样本,正样本与负样本的比例控制在1:3左右,对于那些没有选上的样本,label设置成-1,不参与训练当中。
- 为了扩大感受野,加快推理速度,还使用了空洞卷积。
- SSD中还采用了数据增强的策略,如对原图进行色域变换、扩增、采样的操作,具体可以参考这篇文章。
五、实验结果
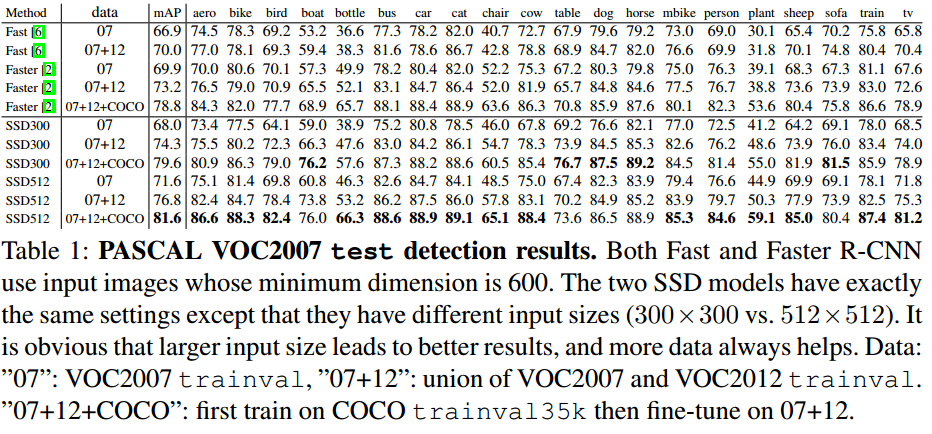
(1)VOC测试结果
下表是SSD在VOC的实验结果图。与Fast R-CNN和Faster R-CNN进行对比,分别使用了300*300和 512*512的图片作为输入。在07+12+COCO数据集上来看,SSD300比Faster R-CNN的mAP提高了0.8%,SSD512提高了2.8%。此外,SSD的定位误差更小,因为SSD是直接回归目标的形状和进行分类,将定位和分类合成了一步。但是,对于相似目标,SSD容易产生混淆,可能是因为对不同种类的目标共享了位置。SSD还容易预测框尺寸的干扰,即在小目标上其性能比大目标要差。作者认为这可能是由于在浅层的时候,小目标物体包含的信息不多。当增加了分辨率的时候,这种情况得到了较好的改善。
(2)模型分析
为了了解SSD中各组成对结果的影响程度,作者使用SSD300进行了控制变量实验,结果如下图所示。

- 数据增强:在R-CNN系列中,采用的是原图或者对原图进行翻转等变换。而SSD中,使用了更多的策略,包括扩增、采样等。可以看出,使用数据增强的SSD,mAP提高了8.8%。但作者认为,同样的数据增强策略,对R-CNN系列可能会失效,因为在进入分类头的时候,使用了特征池化。
- 锚点框的多样性:在SSD中,对特征图的每个位置使用了6个不同形状的锚点框,每层特征图的锚点框也均不一致。当移除锚点框后,mAP都出现了不同比例的下降。使用不同尺寸的锚点框,使网络能更加简单对锚点框进行回归。但是不是锚点框越多越好呢?锚点框越多,推理速度也就越慢。这中间应该会有折中。
- 空洞卷积:在本实验中,使用的是带空洞卷积版本的VGG16。如果使用完全版本的VGG16,即保留pool5和对fc6/fc7不使用下采样,增加conv5_3进行特征融合。这样的话,能得到相同精度的结果,但速度却慢了20%。
- 多尺度融合:SSD的主要贡献在于在不同分辨率的特征层中使用了不同尺寸的锚点框,进行多尺度融合。为了比较这一做法的影响,作者去除某些用于特征融合的层,实验的结果如下表所示。为了保证一致性,锚点框的数量保持接近8732。可以看出,当特征层越来越少的时候,mAP也会随之下降,从74.3下降到62.4。

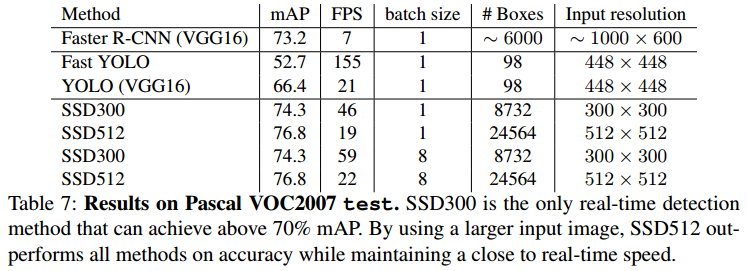
(3)推理时间
下表是SSD的推理时间对比图。可以看出,SSD中精度和速度上做到了比较好的平衡。
SSD是一种很优秀的one-stage框架,对后面很多目标检测算法有着深远的影响。读完论文,发现还是对SSD的了解不够深入,接下来,会对其源码进行分析。
SSD学习笔记的更多相关文章
- 深度学习笔记(十三)YOLO V3 (Tensorflow)
[代码剖析] 推荐阅读! SSD 学习笔记 之前看了一遍 YOLO V3 的论文,写的挺有意思的,尴尬的是,我这鱼的记忆,看完就忘了 于是只能借助于代码,再看一遍细节了. 源码目录总览 tens ...
- 深度学习笔记(七)SSD 论文阅读笔记简化
一. 算法概述 本文提出的SSD算法是一种直接预测目标类别和bounding box的多目标检测算法.与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度.针 ...
- 深度学习笔记(七)SSD 论文阅读笔记
一. 算法概述 本文提出的SSD算法是一种直接预测目标类别和bounding box的多目标检测算法.与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度.针 ...
- [学习笔记] SSD代码笔记 + EifficientNet backbone 练习
SSD代码笔记 + EifficientNet backbone 练习 ssd代码完全ok了,然后用最近性能和速度都非常牛的Eifficient Net做backbone设计了自己的TinySSD网络 ...
- Java学习笔记(04)
Java学习笔记(04) 如有不对或不足的地方,请给出建议,谢谢! 一.对象 面向对象的核心:找合适的对象做合适的事情 面向对象的编程思想:尽可能的用计算机语言来描述现实生活中的事物 面向对象:侧重于 ...
- 学习笔记:The Log(我所读过的最好的一篇分布式技术文章)
前言 这是一篇学习笔记. 学习的材料来自Jay Kreps的一篇讲Log的博文. 原文很长,但是我坚持看完了,收获颇多,也深深为Jay哥的技术能力.架构能力和对于分布式系统的理解之深刻所折服.同时也因 ...
- Oracle User Management FAQ翻译及学习笔记
转载 最近了解到AME 的东西,很迫切,先转载一篇 [@more@] Oracle User Management FAQ翻译及学习笔记 写在前面 本文主要是翻译的英文版的Oracle User Ma ...
- 学习笔记:The Log(我所读过的最好的一篇分布式技术文章)
前言 这是一篇学习笔记. 学习的材料来自Jay Kreps的一篇讲Log的博文. 原文非常长.可是我坚持看完了,收获颇多,也深深为Jay哥的技术能力.架构能力和对于分布式系统的理解之深刻所折服.同一时 ...
- OpenCV 学习笔记 07 目标检测与识别
目标检测与识别是计算机视觉中最常见的挑战之一.属于高级主题. 本章节将扩展目标检测的概念,首先探讨人脸识别技术,然后将该技术应用到显示生活中的各种目标检测. 1 目标检测与识别技术 为了与OpenCV ...
随机推荐
- easy dragging script
下面的ahk脚本提供了windows下alt dragging的能力: ; Easy Window Dragging -- KDE style (requires XP/2k/NT) -- by Jo ...
- 阶段3 3.SpringMVC·_04.SpringMVC返回值类型及响应数据类型_4 响应之返回值是ModelAndView类型
ModelAndView是SpringMvc提供的一个对象 ModelAndView底层源码用也是ModelMap.ModelMap实现过Model的接口 ModelAndView可以直接new出来. ...
- C++数据结构之哈希表
哈希表的定义:哈希表是一种根据关键码去寻找值的数据映射结构,该结构通过把关键码映射的位置去寻找存放值的地方.键可以对应多个值(即哈希冲突),值根据相应的hash公式存入对应的键中. 哈希函数的构造要求 ...
- redis的日常操作(1)
一.简介 [概述] redis是一种nosql数据库,他的数据是保存在内存中,同时redis可以定时把内存数据同步到磁盘,即可以将数据持久化,并且他比memcached支持更多的数据结构(string ...
- Linux Openssh源码升级
telnet服务 yum install -y telnet-server xinetd systemctl start xinetd systemctl start telnet.socket #监 ...
- IntelliJ IDEA 2019 注册码 (激活码) 有效期至2100年
IntelliJ IDEA 2019 注册码 (激活码) 有效期至2100年 本人使用的IDEA是最新版:IntelliJ IDEA 2018.3.3 x64 (IntelliJ IDEA官网下载地址 ...
- HBase 数据恢复
参考链接: https://community.hortonworks.com/content/supportkb/48748/hbase-master-wont-start-with-followi ...
- Aes加密/解密示例项目
#AesEncrypt:Aes加密/解密示例项目 <br> 附件中的“AesEncrypt.zip”是本项目的exe文件,可直接下载下来运行和查看. *高级加密标准(英语:Advanced ...
- ES 知识点
一.ES基于_version 进行乐观锁并发控制 post /index/type/id/_update?retry_on_conflict=5&version=6 1.内部版本号 第一次创建 ...
- SQL常见面试题(学生表_课程表_成绩表_教师表)
表架构 Student(S#,Sname,Sage,Ssex) 学生表 Course(C#,Cname,T#) 课程表 SC(S#,C#,score) 成绩表 Teacher(T#,Tname) 教师 ...