deep_learning_Function_bath_normalization()
关于归一化的讲解的博客——【深度学习】Batch Normalization(批归一化)
tensorflow实现代码在这个博客——【超分辨率】TensorFlow中批归一化的实现——tf.layers.batch_normalization()函数
tf.nn.batch_normalization()函数用于执行批归一化。
# 用于最中执行batch normalization的函数
tf.nn.batch_normalization(
x,
mean,
variance,
offset,
scale,
variance_epsilon,
name=None
)
1
2
3
4
5
6
7
8
9
10
参数:
x是input输入样本
mean是样本均值
variance是样本方差
offset是样本偏移(相加一个转化值)
scale是缩放(默认为1)
variance_epsilon是为了避免分母为0,添加的一个极小值
输出的计算公式为:
y=scale∗(x−mean)/var+offset y = scale * (x - mean) / var + offset
y=scale∗(x−mean)/var+offset
这里安利一个简单讲述batch normalization的文章,还有相应的代码,通俗易懂。
tensorflow-BatchNormalization(tf.nn.moments及tf.nn.batch_normalization)
————————————————
原文链接:https://blog.csdn.net/TeFuirnever/article/details/88911995
批标准化
批标准化(batch normalization,BN)一般用在激活函数之前,使结果x=Wx+bx=Wx+b 各个维度均值为0,方差为1。通过规范化让激活函数分布在线性区间,让每一层的输入有一个稳定的分布会有利于网络的训练。
优点:
加大探索步长,加快收敛速度。
更容易跳出局部极小。
破坏原来的数据分布,一定程度上防止过拟合。
解决收敛速度慢和梯度爆炸。
tensorflow相应API
mean, variance = tf.nn.moments(x, axes, name=None, keep_dims=False)
计算统计矩,mean 是一阶矩即均值,variance 则是二阶中心矩即方差,axes=[0]表示按列计算;
tf.nn.batch_normalization(x, mean, variance, offset, scale, variance_epsilon, name=None)
tf.nn.batch_norm_with_global_normalization(x, mean, variance, beta, gamma, variance_epsilon, scale_after_normalization, name=None);
tf.nn.moments 计算返回的 mean 和 variance 作为 tf.nn.batch_normalization 参数调用;
tensorflow及python实现
import tensorflow as tf
W = tf.constant([[-2.,12.,6.],[3.,2.,8.]], )
mean,var = tf.nn.moments(W, axes = [0])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
resultMean = sess.run(mean)
print(resultMean)
resultVar = sess.run(var)
print(resultVar)
[ 0.5 7. 7. ]
[ 6.25 25. 1. ]
计算每个列的均值及方差。
size = 3
scale = tf.Variable(tf.ones([size]))
shift = tf.Variable(tf.zeros([size]))
epsilon = 0.001
W = tf.nn.batch_normalization(W, mean, var, shift, scale, epsilon)
#参考下图BN的公式,相当于进行如下计算
#W = (W - mean) / tf.sqrt(var + 0.001)
#W = W * scale + shift

with tf.Session() as sess:
#必须要加这句不然执行多次sess会报错
sess.run(tf.global_variables_initializer())
resultW = sess.run(W)
print(resultW)
#观察初始W第二列 12>2 返回BN的W值第二列第二行是负的,其余两列相反
[[-0.99992001 0.99997997 -0.99950027]
[ 0.99991995 -0.99997997 0.99950027]]
Bug
Attempting to use uninitialized value Variable_8:
#运行sess.run之前必须要加这句不然执行多次sess会报错
sess.run(tf.global_variables_initializer())
参考
深度学习Deep Learning(05):Batch Normalization(BN)批标准化
谈谈Tensorflow的Batch Normalization
tensorflow 的 Batch Normalization 实现(tf.nn.moments、tf.nn.batch_normalization)
————————————————
原文链接:https://blog.csdn.net/eclipsesy/article/details/77597965
tensorflow 在实现 Batch Normalization(各个网络层输出的归一化)时,主要用到以下两个 api:
tf.nn.moments(x, axes, name=None, keep_dims=False) ⇒ mean, variance:
统计矩,mean 是一阶矩,variance 则是二阶中心矩
tf.nn.batch_normalization(x, mean, variance, offset, scale, variance_epsilon, name=None)
https://www.tensorflow.org/api_docs/python/tf/nn/batch_normalization
γ⋅x−μσ+β \gamma\cdot\frac{x-\mu}{\sigma}+\beta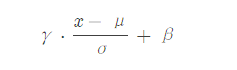
γ 表示 scale 缩放因子,β \betaβ 表示偏移量;
tf.nn.batch_norm_with_global_normalization(t, m, v, beta, gamma, variance_epsilon, scale_after_normalization, name=None)
由函数接口可知,tf.nn.moments 计算返回的 mean 和 variance 作为 tf.nn.batch_normalization 参数进一步调用;
1. tf.nn.moments,矩
tf.nn.moments 返回的 mean 表示一阶矩,variance 则是二阶中心矩;
如我们需计算的 tensor 的 shape 为一个四元组 [batch_size, height, width, kernels],一个示例程序如下:
import tensorflow as tf
shape = [128, 32, 32, 64]
a = tf.Variable(tf.random_normal(shape)) # a:activations
axis = list(range(len(shape)-1)) # len(x.get_shape())
a_mean, a_var = tf.nn.moments(a, axis)
这里我们仅给出 a_mean, a_var 的维度信息,
sess = tf.Session()
sess.run(tf.global_variables_initalizer()) sess.run(a_mean).shape # (64, )
sess.run(a_var).shape # (64, ) ⇒ 也即是以 kernels 为单位,batch 中的全部样本的均值与方差
2. demo
def batch_norm(x):
epsilon = 1e-3
batch_mean, batch_var = tf.nn.moments(x, [0])
return tf.nn.batch_normalization(x, batch_mean, batch_var,
offset=None, scale=None,
variance_epsilon=epsilon)
references
<a href=“http://www.jianshu.com/p/0312e04e4e83”, target="_blank">谈谈Tensorflow的Batch Normalization
————————————————
原文链接:https://blog.csdn.net/lanchunhui/article/details/70792458
deep_learning_Function_bath_normalization()的更多相关文章
随机推荐
- C基础知识(13):内存管理
如果事先不知道数组的具体长度,则需要动态分配内存.下面是例子. #include <stdio.h> #include <stdlib.h> #include <stri ...
- [转] 运维知识体系 -v3.1 作者:赵舜东(赵班长)转载请注明来自于-新运维社区:https://www.unixhot.com
[From]https://www.unixhot.com/page/ops [运维知识体系]-v3.1 作者:赵舜东(赵班长) (转载请注明来自于-新运维社区:https://www.unixhot ...
- Go package(2) strings 用法
go version go1.10.3 Go中的字符串用法,可以在 godoc.org 上查看语法和用法. 最简单的语法就是获取字符串中的子串 s := "hello world" ...
- pt-online-schema-change 修改表结构
- @lazy注解
默认情况下,Spring会在应用程序上下文的启动时创建所有单例bean 主要针对单实例 Bean ,容器启动时不创建对象,仅当第一次使用Bean的时候才创建 @Lazy @Bean public Pe ...
- webgoat8百度云下载链接
网络不好的很难下载,网上也没什么好用的下载链接,我就上传了百度网盘,有需要的兄弟自己下. 链接:https://pan.baidu.com/s/1plTxkZUhSZm9vA5GGzYmMQ 提取码: ...
- SolidWorks学习笔记5创建基准面,基准线,基准点
创建基准面 平面偏移方式 点击参考几何体,点击基准面 第一参考选中时,点击一个参考平面,粉色的 通过三个点 通过一个线和不在改线上的点 经过某一个点和某一个平面平行 一个平面绕一个轴(该轴平行或者在平 ...
- 获取JSON中所有的KEY
采用递归的方式,遍历JSON中所有的KEY. JSON格式如下: {"username":"tom","age":18,"addr ...
- linux shadow文件格式弱口令解密
shadow格式弱口令为linux弱口令,通过kali linux 终端 john --w=字典 加上shadow文件, 扫描完成之后通过john --show 加上shadow文件出结果
- Elasticsearch-字符串类型
ES-用于定义文档字段的核心类型 ES中一个字段可以是核心类型之一,如字符串.数值.日期.布尔型,也可以是一个从核心类型派生的复杂类型,如数组. 字符串类型 索引一类型为字符串的数据doc1: Fen ...