3. Dictionaries and Sets
1. Generic Mapping Types
- The collections.abc module provides the Mapping and MutableMapping ABCs to formalize the interfaces of dict and similar types (in Python 2.6 to 3.2, these classes are imported from the collections module, and not from collections.abc).
- All mapping types in the standard library use the basic dict in their implementation, so they share the limitation that the keys must be hashable.

a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
print(a == b == c == d == e) # True from collections import abc
print(isinstance(a, abc.Mapping)) # True
# 1. The main value of the ABCs is documenting and formalizing the
# minimal interfaces for mappings, and serving as criteria for isinstance
# tests in code that needs to support mappings in a broad sense. print(hash((1, 2, (3, 4)))) # -2725224101759650258
# 1. An object is hashable if it has a hash value which never changes
# during its lifetime (it needs a __hash__() method), and can be compared
# to other objects (it needs an __eq__() method).
# 2. Hashable objects which compare equal must have the same hash value.
# 3. (atomic immutable types / frozen set / tuple when all its items are hashable)
# 4. User-defined types are hashable by default because their hash value is their
# id() and they all compare not equal. If an object implements a custom __eq__
# that takes into account its internal state, it may be hashable only if all its
# attributes are immutable.
2. Dict Comprehensions
DIAL_CODES = [
(86, 'China'),
(91, 'India'),
(1, 'United States')
]
print {country.upper(): code for code, country in DIAL_CODES if code > 66}
# {'INDIA': 91, 'CHINA': 86}
3. Overview of Common Mapping Methods

4. Mappings with Flexible Key Lookup
my_dict.get(key, default)
# my_dict[key] # KeyError my_dict.setdefault(key, []).append(new_value)
# if key not in my_dict:
# my_dict[key] = []
# my_dict[key].append(new_value) # 1. setdefault returns the value, so it can
# be updated without requiring a second search. import collections
my_dict = collections.defaultdict(list)
my_dict[key].append(new_value)
print my_dict.default_factory # <type 'list'> # 1. When instantiating a defaultdict, you provide a callable
# that is used to produce a default value whenever __getitem__
# is passed a nonexistent key argument.
# 2. If no default_factory is provided, the usual KeyError
# is raised for missing keys.
# 3. The default_factory of a defaultdict is only invoked to
# provide default values for __getitem__ calls, and not for
# the other methods. (__missing__) class MyDict(dict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys() d = MyDict([('1', 'one'), ('4', 'four')])
print d[1] # one
print d[2] # KeyError
print d.get(3) # None
print 4 in d # True # 1. If you subclass dict and provide a __missing__ method, the
# standard dict.__getitem__ will call it whenever a key is not found,
# instead of raising KeyError. The __missing__ method is just called
# by __getitem__. (i.e., for the d[k] operator).
# 2. A better way to create a user-defined mapping type is to
# sub‐class collections.UserDict instead of dict
# 3. A search like k in my_dict.keys() is efficient in Python 3 even
# for very large mappings because dict.keys() returns a view, which is
# similar to a set, and containment checks in sets are as fast as in
# dictionaries. In Python 2, dict.keys() returns a list, k in my_list
# must scan the list.
5. Variations of dict
- collections.OrderedDict
- Maintains keys in insertion order. The popitem method of an OrderedDict pops the first item by default, but if called as my_odict.popitem(last=True), it pops the last item added.
- collections.ChainMap
- Holds a list of mappings that can be searched as one. The lookup is performed on each mapping in order, and succeeds if the key is found in any of them. This is useful to interpreters for languages with nested scopes, where each mapping represents a scope context. The “ChainMap objects” section of the collections docs has several examples of ChainMap usage.
import builtins
pylookup = ChainMap(locals(), globals(), vars(builtins))
collections.Counter
- A mapping that holds an integer count for each key. Updating an existing key adds to its count. This can be used to count instances of hashable objects (the keys) or as a multiset—a set that can hold several occurrences of each element.
import collections
ct = collections.Counter('abracadabra')
print ct # Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
ct.update('aaaaazzz')
print ct # Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
print ct.most_common(2) # [('a', 10), ('z', 3)]
- collections.UserDict
- A pure Python implementation of a mapping that works like a standard dict.
import collections
class MyDict2(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = item # stores all keys as str d = MyDict2([('1', 'one'), ('4', 'four')])
print(d[1]) # one
print(d[2]) # KeyError
print(d.get(3)) # None
print(4 in d) # True
d.update([('1', '111')])
print(d.get(1)) # 111 # 1. The main reason why it’s preferable to subclass from UserDict
# rather than from dict is that the built-in has some implementation
# shortcuts that end up forcing us to override methods that we can
# just inherit from UserDict with no problems.
# 2. UserDict does not inherit from dict, but has an internal dict
# instance, called data, which holds the actual items.
6. Immutable Mappings
from types import MappingProxyType
d = {1: 'A'}
d_proxy = MappingProxyType(d)
print(d_proxy) # mappingproxy({1: 'A'})
print(d_proxy[1]) # 'A'
# d_proxy[2] = 'B' # TypeError
d[2] = 'B'
print(d_proxy) # {1: 'A', 2: 'B'}
print(d) # {1: 'A', 2: 'B'} # 1. updates to the original mapping can be seen in the
# mappingproxy, but changes cannot be made through it.
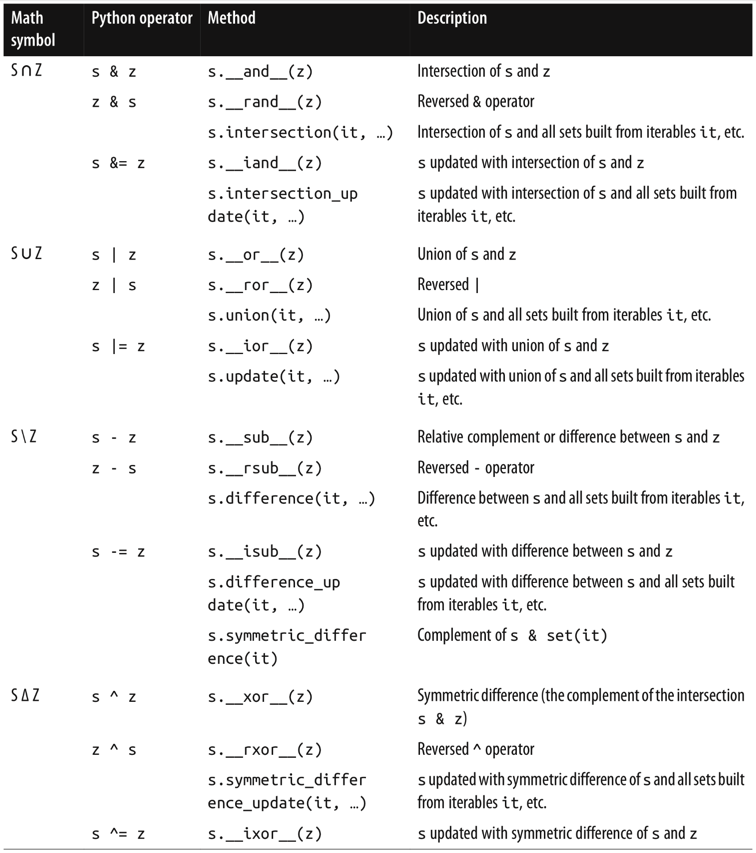
7. Set Theory

l = ['spam', 'spam', 'eggs', 'spam']
s1 = set(l)
s2 = {'spam'}
print(hash(frozenset(range(4)))) # 7327027465595056883
print(s1) # {'eggs', 'spam'}
print(s1 & s2) # {'spam'}
print(s2.pop()) # spam
print(s2) # set()
s3 = {i for i in range(10) if i < 4} # Set Comprehensions
print(s3) # {0, 1, 2, 3} # 1. Create s1 is slower than s2 because, to evaluate it, Python
# has to look up the set name to fetch the constructor, then build
# a list, and finally pass it to the constructor.
# 2. Set elements must be hashable. The set type is not hashable,
# but frozenset is.
# 3. Given two sets a and b, a | b returns their union, a & b
# computes the intersection, and a - b the difference.
# 4. There’s no literal notation for the empty set, just use set().


8. dict and set Under the Hood
8.1 Hash Tables in Dictionaries
A hash table is a sparse array (i.e., an array that always has empty cells). In standard data structure texts, the cells in a hash table are often called “buckets.” In a dict hash table, there is a bucket for each item, and it contains two fields: a reference to the key and a reference to the value of the item. Because all buckets have the same size, access to an individual bucket is done by offset.
- Python tries to keep at least 1/3 of the buckets empty; if the hash table becomes too crowded, it is copied to a new location with room for more buckets.
- To put an item in a hash table, the first step is to calculate the hash value of the item key, which is done with the hash() built-in function.
- Hashes and equality:
- The hash() built-in function works directly with built-in types and falls back to calling __hash__ for user-defined types. If two objects compare equal, their hash values must also be equal. (hash(1) == hash(1.0))
- Ideally, objects that are similar but not equal should have hash values that differ widely.
- Starting with Python 3.3, a random salt value is added to the hashes of str, bytes, and datetime objects. The salt value is constant within a Python process but varies between interpreter runs. The random salt is a security measure to prevent a DOS attack.
- The hash table algorithm:
- To fetch the value at my_dict[search_key], Python calls hash(search_key) to obtain the hash value of search_key and uses the least significant bits of that number as an offset to look up a bucket in the hash table (the number of bits used depends on the current size of the table). If the found bucket is empty, KeyError is raised. Otherwise the found bucket has an item—a found_key:found_value pair—and then Python checks whether search_key == found_key. If they match, that was the item sought: found_value is returned.
- However, if search_key and found_key do not match, this is a hash collision. This happens because a hash function maps arbitrary objects to a small number of bits, and—in addition—the hash table is indexed with a subset of those bits. In order to resolve the collision, the algorithm then takes different bits in the hash, massages them in a par‐ticular way, and uses the result as an offset to look up a different bucket. If that is empty, KeyError is raised; if not, either the keys match and the item value is returned, or the collision resolution process is repeated.
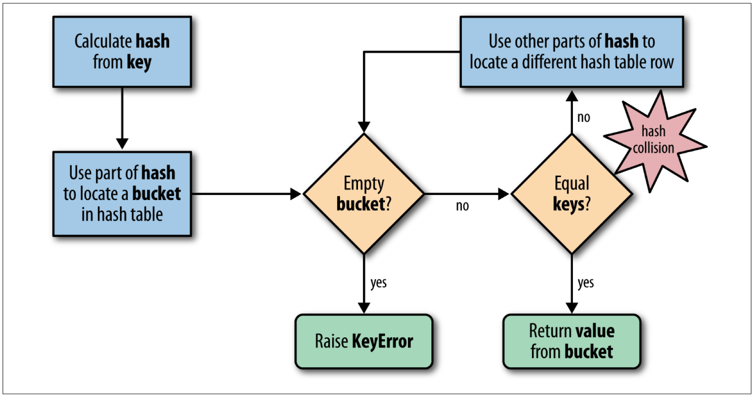
- when inserting items, Python may determine that the hash table is too crowded and rebuild it to a new location with more room. As the hash table grows, so does the number of hash bits used as bucket offsets, and this keeps the rate of collisions low.
- even with millions of items in a dict, many searches happen with no collisions, and the average number of collisions per search is between one and two.
8.2 Practical Consequences of How dict Works
- Keys must be hashable objects:
- Hashable:
- It supports the hash() function via a hash() method that always returns the same value over the lifetime of the object.
- It supports equality via an eq() method.
- If a == b is True then hash(a) == hash(b) must also be True.
- User-defined types are hashable by default because their hash value is their id() and they all compare not equal.
If you implement a class with a custom __eq__ method, you must also implement a suitable __hash__, because you must always make sure that if a == b is True then hash(a) == hash(b) is also True. Otherwise you are breaking an invariant of the hash table algo‐rithm, with the grave consequence that dicts and sets will not deal reliably with your objects. If a custom __eq__ depends on mutable state, then __hash__ must raise TypeError.
- Hashable:
- Dicts have significant memory overhead:
- Because a dict uses a hash table internally, and hash tables must be sparse to work, they are not space efficient.
- Replacing dicts with tuples reduces the memory usage in two ways: by removing the overhead of one hash table per record and by not storing the field names again with each record.
- Key search is very fast:
- trading space for time.
- Key ordering depends on insertion order:
- a dict built as dict([(key1, value1), (key2, value2)]) compares equal to dict([(key2, value2), (key1, value1)]), but their key ordering may not be the same if the hashes of key1 and key2 collide.
- Adding items to a dict may change the order of existing keys:
- In Python 3, the .keys(), .items(), and .values() methods return dictionary views, which behave more like sets than the lists returned by these methods in Python 2. Such views are also dynamic: they do not replicate the contents of the dict, and they immediately reflect any changes to the dict.
3. Dictionaries and Sets的更多相关文章
- C#中的Collection 1
Collection定义 Collection是个关于一些变量的集合,按功能可分为Lists,Dictionaries,Sets三个大类. Lists:是一个有序的集合,支持index look up ...
- Python教学相关资料
Python教学调查链接 一.专题 1.绘图 如何开始使用Python来画图 Python画图总结 2.科学计算与数据分析 3.可视化 4.网络爬虫 5. 做笔记 Python-Jupyter Not ...
- python快速上手教程
python版本 python目前的版本分为2.7和3.5,两种版本的代码目前无法兼容,查看python版本号: python --version 基本数据类型 数字类型 整型和浮点型数据和其它编程语 ...
- 《流畅的Python》Data Structures--第2章序列array
第二部分 Data Structure Chapter2 An Array of Sequences Chapter3 Dictionaries and Sets Chapter4 Text vers ...
- python学习之那些由print引起的困惑
该文索所起之因:在练习列表的操作时,要输出一波操作后的列表,但是一直让本人耿耿于怀的时下边的这个现象: 红色框框里是字符串,黄色框框里是列表,同样是只对一个元素进行的操作,为啥输出时字符串是作为一个整 ...
- Arrays, Hashtables and Dictionaries
Original article Built-in arrays Javascript Arrays(Javascript only) ArrayLists Hashtables Generic Li ...
- [Python] 03 - Lists, Dictionaries, Tuples, Set
Lists 列表 一.基础知识 定义 >>> sList = list("hello") >>> sList ['h', 'e', 'l', ' ...
- Look Further to Recognize Better: Learning Shared Topics and Category-Specific Dictionaries for Open-Ended 3D Object Recognition
张宁 Look Further to Recognize Better: Learning Shared Topics and Category-Specific Dictionaries for O ...
- TSQL 分组集(Grouping Sets)
分组集(Grouping Sets)是多个分组的并集,用于在一个查询中,按照不同的分组列对集合进行聚合运算,等价于对单个分组使用“union all”,计算多个结果集的并集.使用分组集的聚合查询,返回 ...
随机推荐
- django ORM中的复选MultiSelectField的使用
下载和介绍: https://pypi.org/project/django-multiselectfield/ 在django ORM的使用中,经常会出现选择的情况,例如: class person ...
- utgard OPC 主要功能简介
度娘还行,尽管不好用,但所有的开发人员不懈努力地写博客,能得到很多东西! 这里向所有未谋面的博主们致敬! 搜了一堆OPC资料,在这里整理一下,用一个封装类来说明utgard的主要接口.使用了java自 ...
- c++学习笔记_6
前言:本笔记所对应的课程为中国大学mooc中北京大学的程序设计与算法(三)C++面向对象程序设计,主要供自己复习使用,且本笔记建立在会使用c和java的基础上,只针对与c和java的不同来写 多态 虚 ...
- OpenCV.20190628
1.OpenCV提取ORB特征并匹配 - 简书.html(https://www.jianshu.com/p/420f8211d1cb) OpenCV提取ORB特征并匹配 - 简书.html(http ...
- Bloom Filter布隆过滤器原理和实现(1)
引子 <数学之美>介绍布隆过滤器非常经典: 在日常生活中,包括设计计算机软件时,经常要判断一个元素是否在一个集合中.比如: 在字处理软件中,需要检查一个英语单词是否拼写正确(也就是要判断它 ...
- appium+python教程1
Python3+Appium安装使用教程 一.安装 我们知道selenium是桌面浏览器自动化操作工具(Web Browser Automation) appium是继承selenium自动化思想旨在 ...
- oracle中Blob、Clob、Varchar之间的互相转换
以下是oracle中Blob.Clob.Varchar之间的互相转换(都是百度找的,亲测可用) Blob转Varchar2: CREATE OR REPLACE FUNCTION blob_to_va ...
- JDBCtemplete 模板
package com.augmentum.oes.common; import java.sql.Connection; import java.sql.PreparedStatement; imp ...
- cdoj 574 High-level ancients dfs序+线段树 每个点所加权值不同
High-level ancients Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://acm.uestc.edu.cn/#/problem/s ...
- 集成板的CodeBlocks编译器配置相关文档
如需安装包请后台留言!! 原文链接:https://w.url.cn/s/A1RSfZP 打开安装包进行安装,除安装路径大家可以自行调整外, 其他默认即可.最后安装完成,CodeBlocks的大门即将 ...