论文阅读 | Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems
主要工作
文章首先证明了对抗攻击对NLP系统的影响力,然后提出了三种屏蔽方法:
visual character embeddings
adversarial training
rule-based recovery
但屏蔽方法在非攻击场景下的性能仍然较差,说明了处理视觉攻击的难度。
在NLP中,Jia和Liang(2017)将语法正确但语义无关的段落插入到故事中,以愚弄神经阅读理解模型。Singh等人(2018)发现,当使用简单的原问题释义时,用于回答问题的神经模型的性能显著下降。
不像以前的NLP攻击场景,视觉攻击,即(1)它们不需要任何超出字符级别的语言知识,使攻击直接适用于不同的语言、领域和任务。2)据称,它们对人类感知和理解的损害要小于语法错误或插入否定词(Hosseini et al., 2017)。3)不需要知道被攻击模型的参数或损失函数(Ebrahimi et al., 2018)。
在这项工作中,我们研究了最新的先进(SOTA)深度学习模型在多大程度上对视觉攻击敏感,并探索了各种屏蔽技术。我们的贡献:
引入了VIPER,这是一种视觉扰流器,它在视觉嵌入空间中随机地将输入中的字符替换为它们的视觉近邻。
我们发现SOTA深度学习模型的性能在不同情况下都有显著的下降 被VIPER攻击时的NLP任务。在单独的任务(如分块)和攻击场景中,我们观察到的下降率高达82%。
相比之下人类收到的影响甚微。
提出三种屏蔽方法。验证它们有用的程度和环境。
相关工作
两个方面,一是对抗攻击,二是可视的字符嵌入。Ebrahimi等人(2018)提出了一种字符翻转算法来生成对抗性的例子,并用它来欺骗字符级神经分类器。Chen等(2018)发现,阅读理解系统经常忽略重要的问题术语,因此当这些术语被替换时,会给出不正确的答案。Belinkov和Bisk(2018)的研究表明,神经机器翻译系统会因人类所能承受的各种噪音而崩溃,比如单词的重新排序、键盘打字错误和拼写错误。Alzantot等人(2018)用同义词替换单词来愚弄文本分类器。Iyyer等人(2018)对句子进行句法重组,生成对抗性的例子。
与那些在字符级别上进行攻击的相关工作相反,我们的攻击允许在一个单词中对任何字符进行干扰,同时尽可能地减少对人类的损害。例如,Belinkov and Bisk(2018)中最强的攻击是对所有字符的随机打乱,这对于人类来说是更加难以恢复的。
为了应对对抗性攻击,提出了对抗性训练(Goodfellow et al., 2015)作为一种标准的补救方法,其中训练数据用类似于攻击神经分类器的数据来扩充。Rodriguez和Rojas-Galeano(2018)提出了基于规则的简单更正,以解决有限数量的攻击,包括混淆(例如,idiot to !d10ts)和否定(例如,idiot to NOT idiot)。大多数其他方法都是在CV的背景下探索的,比如在训练过程中添加稳定目标(Zheng et al., 2016)和蒸馏(Papernot et al., 2016)。然而,提高CV鲁棒性的方法被证明对更复杂的攻击效果较差(Carlini和Wagner, 2017)。
视觉字符嵌入
最初是为了处理汉语和日语等组装式语言中的大型字符词汇。Shimada et al.(2016)和Dai and Cai(2017)使用卷积自动编码器为日文和中文文本生成基于图像的字符嵌入(ICE),并展示了作者和发布者识别任务的改进。同样,Liu等人(2017)从CNN中创建了ice,并证明了ice具有更多的语义内容,更适合罕见字符。然而现有的关于视觉字符嵌入的工作还没有使用视觉信息来攻击NLP系统或它们。
方法
VIPER:
CES:选择每个字符的近邻字符的方法。 p 伯努利分布概率。

黑盒攻击。也有可能设计一种方法只攻击内容词 hot words,但这样黑盒就很困难。
字符embedding
三种字符embedding spaces:
1. continuous, 每个字符用576维来表示,可以计算每个输入字符和包括最近邻的任意两个字符之间的余弦相似度。
另外两种是离散的。每个字符c从最近邻集合中选。所有最近邻和c等距。
这三种CES都带有 visual information
Image-based character embedding space (ICES)
为每个Unicode字符提供基于图像的连续字符嵌入(ICE)。我们检索字符的24*24的图像表示(使用Python的PIL库),
24 * 24 = 576 dimensional embedding vector
Description-based character embedding space(DCES)
基于Unicode字符的文本描述。首先从Unicode 11.0.0最终名称列表中获得每个字符的描述(例如,字符a的latin small letter a)。然后,我们通过选择所有在相同情况下描述相同字母的字符来确定一组最近的邻居,例如,latin small letter a的另一种选择是latin small letter a with grave,因为它包含关键字small和a。
Easy character embedding space (ECES)
提供手动选择的简单视觉干扰。它为52个字符a- z A-Z中的每个字符精确地包含一个最近的邻居,这些字符被选为字符下面或上面的变音符号,例如字符c的c^。
几种CES的不同
这三种方法有不同的角色。使用ICES在深度学习系统中。DCES和ECES用来加入VIPER扰动在测试集。ECES应用于最小扰动产生最大影响。
ICES和DCES中是有一些重叠的。?

Word Embedding
大部分NLP框架是字符或词级别的。word embeddings使用ELMo框架,包含不定长的词典,而且不允许词典外的扰动。文中提供了ELMo变体,包含visual signals。
SELMo:由Peters等人(2018)提出的ELMo首先检索输入中每个字符的嵌入,这些嵌入是作为网络的一部分学习的。然后,ELMo通过在单词中的所有字符嵌入上应用CNNs来推断非上下文化的单词嵌入。深层双向语言模型的两层进一步处理本地语句上下文中的单词嵌入和输出上下文化的单词嵌入。
我们稍微扩展了ELMo,使其包含前30k Unicode字符的字符嵌入(而不是默认的256)。我们称这种变体为SELMo(标准ELMo)。值得指出的是,SELMo的学习型字符嵌入几乎不包含任何视觉信息(最后一列),如表2所示。也就是说,除了少数非常标准的情况外,字符的最近邻在视觉上与原始字符并不相似,即使是经过10亿个单词的基准测试(Chelba et al., 2013)。
VELMo:为了获得一个直观的ELMo变体,我们用ICEs替换了已学习的字符嵌入,并在培训期间保持角色嵌入固定。这意味着,在训练期间,ELMo模型学会利用输入的视觉特性,从而潜在地增强了对视觉攻击的抵抗力。我们称这种变体为VELMo(可视化的ELMo)。为了保证SELMo和VELMo的训练时间是可行的,我们使用512的输出维数来代替原来的ELMo s 1024d输出。我们详细的超参数设置在A.1中给出。
对于人的测试
这部分没仔细看,最后得出的结论是:
综上所述,人类似乎非常善于理解视觉干扰。由于对抗性攻击对人类的影响应该最小(Szegedy et al., 2014),人类的良好性能,特别是在ECES和DCES上的良好表现,使得这两个空间成为攻击NLP系统的理想候选空间。
实验
model : SOTA visual attack,4个任务
G2P:grapheme-to-phoneme
我们首先考虑的是字元到音素(G2P)转换的字符级任务。它包括将字符输入流转录成语音表示。作为我们的数据集,我们选择了Combilex美式英语发音数据集(Richmond et al 2009) 。我们将G2P定义为一个序列标记任务。为此,我们首先使用1-0、1-1、1-2对齐方案对输入和输出序列进行硬对齐(Schnober et al., 2016),其中输入字符与0、1或2个输出字符匹配。一旦预处理完成,输入和输出序列的长度相等,我们就可以在字符级对对齐的序列应用标准BiLSTM (Reimers和Gurevych, 2017)。
POS和分块:我们考虑两个单词级的任务。词性标注将每个标记与其对应的词类(例如,名词、形容词、动词)相关联。将单词分组成句法块,如名词短语和动词短语(NP和VP),为每个单词分配一个独特的标记,该标记对句法成分的位置和类型进行编码,如begin- -词组(B-NP)。我们使用由CoNLL-2000共享任务(Sang和Buchholz, 2000)提供的培训、开发和测试分割,并使用与上面SELMo/VELMo embeddings相同的BiLSTM体系结构。
Toxic comment (TC) classification
有6个类别的句子分类任务。使用SELMo VELMo embeddings 作为输入给MLP。
(好像这三类任务我之前都没有接触过)
VIPER 攻击
使用DCES生成测试集攻击SOTA。除了自己的系统,还有Marmot和SPT Stanford POS tagger. 前一个是基于特征的,SPT是双向依赖网络tagger。对于SPT,我们使用工具包提供的预先训练过的英语模型。此外,我们还包括了一个快速文本TC分类器,它已经实现了SOTA性能。我们还对词级依赖嵌入进行了实验,用于词性标注和TC分类(Komninos和Manandhar, 2016)。
为了比较不同任务的性能,图2显示了:
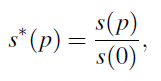
s(p) 是 p任务的分数。measured in edit distance for G2P, accuracy for POS tagging, micro-F1 for chunking, and AUCROC for TC classification
s*(0) isalways 1 and s*(p) is the relative performance compared to the clean case of no perturbations.
屏蔽方法
four forms of shielding against VIPER attacks:
adversarial training (AT)
visual character embeddings (CE)
AT+CE
rule-based recovery (RBR).
(个人觉得表达视觉的特征这一点比较重要,基本上是文本中对抗攻击的一大攻击点)
AT:没有增大训练集,只是替换了一些样本为对抗样本。
CE:使用定长的ICE
RBR:在输入流中修正一切不标准的字符,用ICE中的最近标准邻来替换。
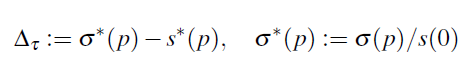
上式表达改进的程度,前面是每个任务应用了屏蔽方法后的分数。
个人认为对抗训练实际上起到的效果是有限的,还有一个问题就是,会不会引起过拟合。
另外,如果不扩大足够量的样本,能不能达到好的效果,因为这保证样本量不变的情况下,如果对抗样本占了大多数,clean 样本太少的话,在正确的部分会不会欠拟合?或者攻击是不可见的。
字符级 词级 句子级 应用这些方法的区别?
视觉字符嵌入恢复了部分输入,因而具有相当大的效果。然而,令人惊讶的是,可视化嵌入对两个单词级任务都没有积极的影响,反而导致了小的恶化。一种可能的解释是,当将字符嵌入到ELMo体系结构中时,它们的效果会减弱。实际上,我们执行了一个完整性检查(参见a .5),以测试(cos)在SELMo和VELMo下的单词或句子w与受扰动的版本w (w)的相似程度。我们发现,VELMo始终赋予了更好的相似性,但总体差距很小。
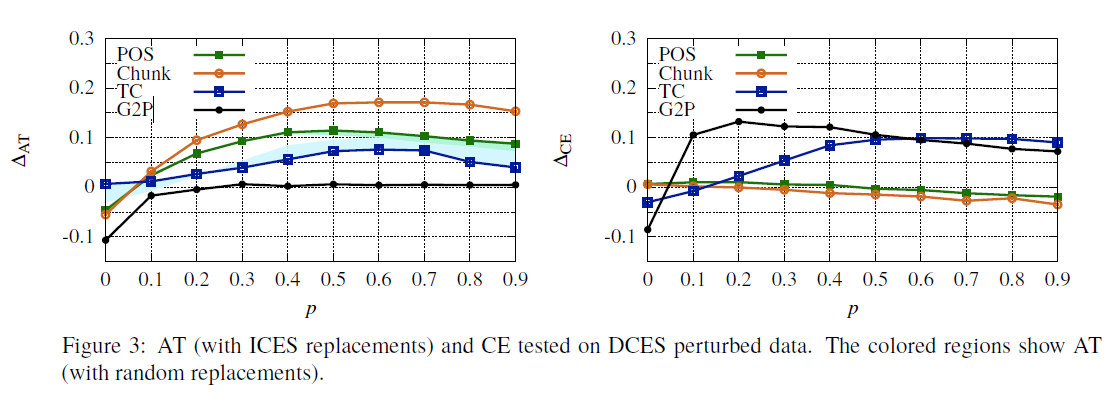
RBR非常适合于ECES(参见A.3)。它对干净数据的有一些负面影响,这意味着英语文本中存在一些被RBR破坏的外来材料,但对于任何p > 0, RBR下的性能几乎与ECES的p = 0水平相当。
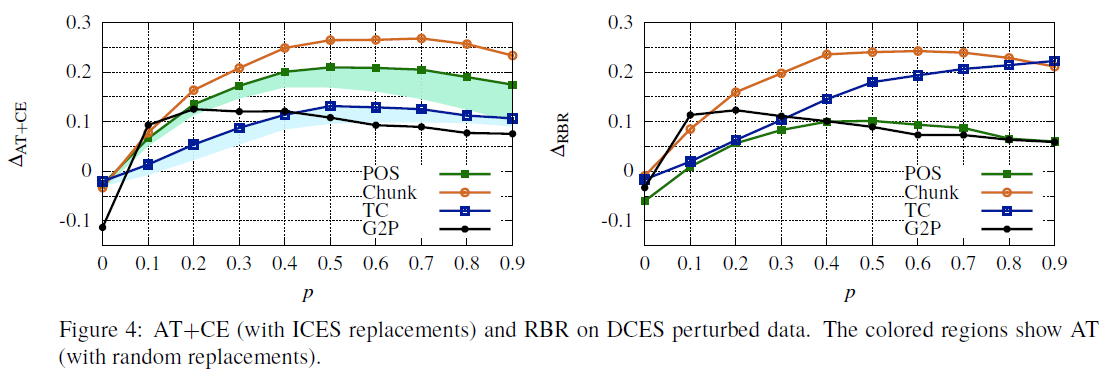
尽管两者都依赖于ice: CE是软方式,RBR是硬方式。我们最好的解释是,RBR类似于机器将外国文本翻译成英语,然后应用经过训练的分类器,而CE类似于直接传输方法(McDonald et al., 2011),它在一个领域进行训练,然后应用于另一个领域。这导致一种神经网络非常脆弱的领域转移形式(Ruder and Plank, 2018;Eger等,2018a)。对于DCES, RBR的性能优于AT+CE,除了TC之外,AT+CE比CE更能减轻域转移。
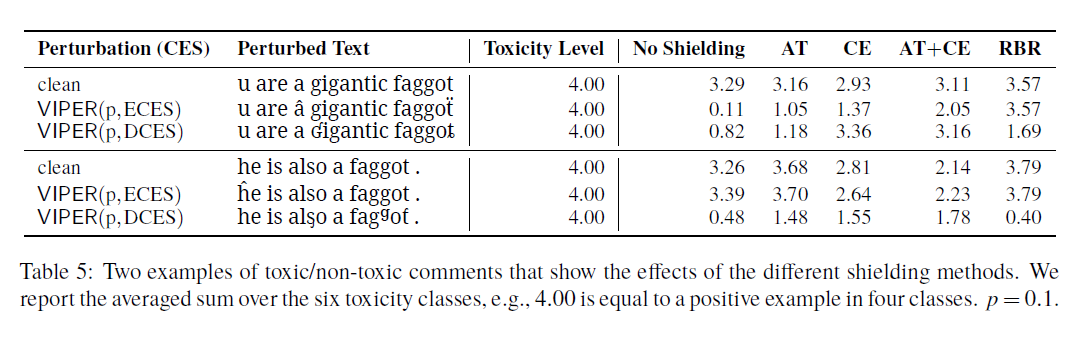
对热词的改变影响会比较大。
论文阅读 | Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems的更多相关文章
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- 论文阅读:《Bag of Tricks for Efficient Text Classification》
论文阅读:<Bag of Tricks for Efficient Text Classification> 2018-04-25 11:22:29 卓寿杰_SoulJoy 阅读数 954 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
- 【论文阅读】Motion Planning through policy search
想着CSDN还是不适合做论文类的笔记,那里就当做技术/系统笔记区,博客园就专心搞看论文的笔记和一些想法好了,[]以后中框号中间的都算作是自己的内心OS 有时候可能是问题,有时候可能是自问自答,毕竟是笔 ...
- 分布式多任务学习论文阅读(四):去偏lasso实现高效通信
1.难点-如何实现高效的通信 我们考虑下列的多任务优化问题: \[ \underset{\textbf{W}}{\min} \sum_{t=1}^{T} [\frac{1}{m_t}\sum_{i=1 ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 《Data-Intensive Text Processing with mapReduce》读书笔记之一:前言
暑假闲得蛋痒,混混沌沌,开始看<Data-Intensive Text Processing with mapReduce>,尽管有诸多单词不懂,还好六级考多了,虽然至今未过:再加上自己当 ...
随机推荐
- [2019HDU多校第一场][HDU 6588][K. Function]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6588 题目大意:求\(\sum_{i=1}^{n}gcd(\left \lfloor \sqrt[3] ...
- 题解 [CF916E] Jamie and Tree
题面 解析 这题考试时刚了四个小时. 结果还是爆零了 主要就是因为\(lca\)找伪了. 我们先考虑没有操作1,那就是裸的线段树. 在换了根以后,主要就是\(lca\)不好找(分类讨论伪了). 我们将 ...
- 2 MVC设计模式
0 基础知识 (1)B/S与C/S结构 C/S(客户机/服务器 client/service):分为客户机和服务器两层,应用软件安装在客户端通过网络与服务器通信 B/S(liulanq/服务器 bro ...
- 头条编程题 万万没想到之抓捕孔连顺 JavaScript
[编程题] 万万没想到之抓捕孔连顺 时间限制:1秒 空间限制:131072K 我叫王大锤,是一名特工.我刚刚接到任务:在字节跳动大街进行埋伏,抓捕恐怖分子孔连顺.和我一起行动的还有另外两名特工,我提议 ...
- 路由器配置——OSPF协议(2)
一.实验目的:使用OSPF协议达到全网互通的效果 二.拓扑图 三.具体步骤配置 (1)R1路由器配置 Router>enableRouter#configure terminalEnter co ...
- Django基础之form表单
1. form介绍 我们之前在HTML页面中利用form表单向后端提交数据时,都会写一些获取用户输入的标签并且用form标签把它们包起来. 与此同时, 我们在好多场景下都需要对用户的输入做校验, 比如 ...
- AT3912 Antennas on Tree
AT3912 Antennas on Tree %%zzt 只能考虑性质了. 把最后选择的k个点的连通块求出来,连通块内部的点表示都是互异的 连通块外部的点只能形成若干条链,并且这k个点的每一个最多与 ...
- Ajax传递复杂对象报415
特别提示:本人博客部分有参考网络其他博客,但均是本人亲手编写过并验证通过.如发现博客有错误,请及时提出以免误导其他人,谢谢!欢迎转载,但记得标明文章出处:http://www.cnblogs.com/ ...
- Bootstrap4项目开发实战视频教程
一.企业网站项目 课件 0.课程简介 1.顶部区域的制作 2.导航区域的制作 3.轮播区域的制作 4.产品区域的制作 5.最新资讯区域的制作 6.底部区域的制作 二.化妆品网站项目 1.项目初始化_导 ...
- 性能监控系统 | 从0到1 搭建Web性能监控系统
工具介绍 1. Statsd 是一个使用Node开发网络守护进程,它的特点是通过UDP(性能好,及时挂了也不影响主服务)或者TCP来监听各种数据信息,然后发送聚合数据到后端服务进行处理.常见支持的「G ...