100行代码打造属于自己的代理ip池
经常使用爬虫的朋友对代理ip应该比较熟悉,代理ip就是可以模拟一个ip地址去访问某个网站。我们有时候需要爬取某个网站的大量信息时,可能由于我们爬的次数太多导致我们的ip被对方的服务器暂时屏蔽(也就是所谓的防爬虫防洪水的一种措施),这个时候就需要我们的代理ip出场了
思路分析(写爬虫前大家都必须要分析一下)
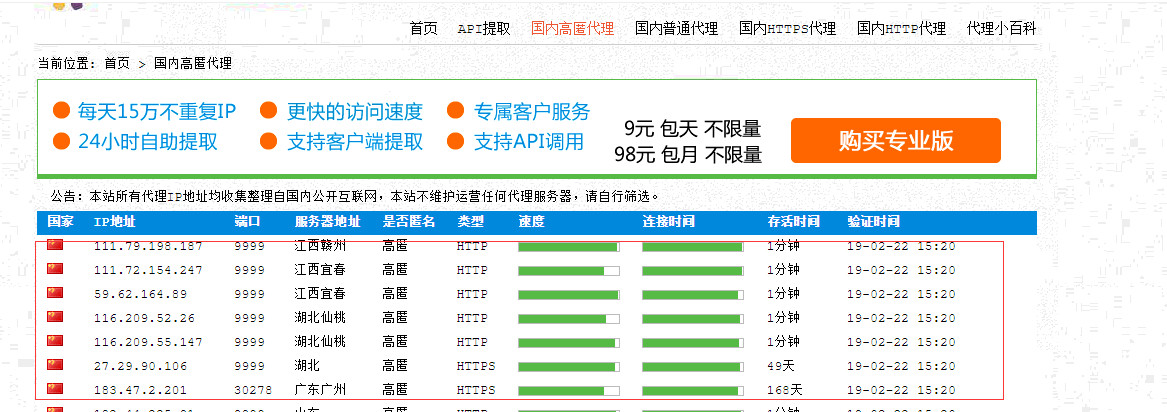
上图就是我们的西刺代理网站,今天我们就是来拿它的数据,老司机一看这个界面就会自动右击鼠标->查看源代码,

我们会发现数据都在<tr>里面,并且<tr>里面有很多的<td>,每一个<td>都包含了我们所需要的数据。
看过我以前一些爬虫文章的朋友估计一下就知道该怎么下手了,但是不急我们还是来分析一下,毕竟这次数据量有点大,而且还得校验代理ip的有效性。
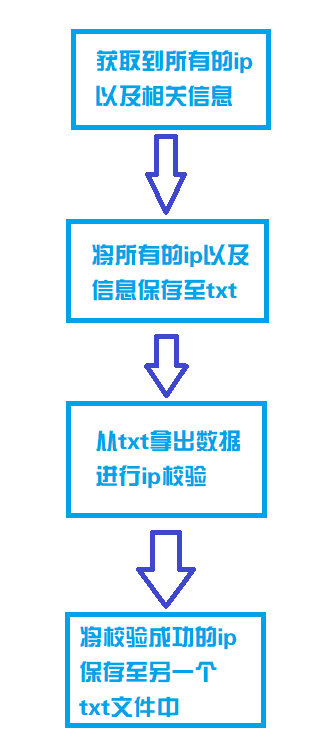
获取所有的代理ip以及相关信息并保存至文件txt中
就按照我们的思路来,在这里我们需要用到的几个库,
from bs4 import BeautifulSoup
import requests
from urllib import request,error
import threading
导入库后,我们首先获得代理ip,我们来定义一个方法:(每一句的解释我都写在注释里了)
def getProxy(url):
# 打开我们创建的txt文件
proxyFile = open('proxy.txt', 'a')
# 设置UA标识
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit '
'/ 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36'
}
# page是我们需要获取多少页的ip,这里我们获取到第9页
for page in range(1, 10):
# 通过观察URL,我们发现原网址+页码就是我们需要的网址了,这里的page需要转换成str类型
urls = url+str(page)
# 通过requests来获取网页源码
rsp = requests.get(urls, headers=headers)
html = rsp.text
# 通过BeautifulSoup,来解析html页面
soup = BeautifulSoup(html)
# 通过分析我们发现数据在 id为ip_list的table标签中的tr标签中
trs = soup.find('table', id='ip_list').find_all('tr') # 这里获得的是一个list列表
# 我们循环这个列表
for item in trs[1:]:
# 并至少出每个tr中的所有td标签
tds = item.find_all('td')
# 我们会发现有些img标签里面是空的,所以这里我们需要加一个判断
if tds[0].find('img') is None:
nation = '未知'
locate = '未知'
else:
nation = tds[0].find('img')['alt'].strip()
locate = tds[3].text.strip()
# 通过td列表里面的数据,我们分别把它们提取出来
ip = tds[1].text.strip()
port = tds[2].text.strip()
anony = tds[4].text.strip()
protocol = tds[5].text.strip()
speed = tds[6].find('div')['title'].strip()
time = tds[8].text.strip()
# 将获取到的数据按照规定格式写入txt文本中,这样方便我们获取
proxyFile.write('%s|%s|%s|%s|%s|%s|%s|%s\n' % (nation, ip, port, locate, anony, protocol, speed, time))
上面的代码就是我们抓取西刺代理上的所有ip并将它们写入txt中,
校验代理ip的可用性
这里是通过代理ip去访问百度所返回的状态码来辨别这个代理ip到底有没有用的。
def verifyProxy(ip):
'''
验证代理的有效性
'''
requestHeader = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
}
url = "http://www.baidu.com"
# 填写代理地址
proxy = {'http': ip}
# 创建proxyHandler
proxy_handler = request.ProxyHandler(proxy)
# 创建opener
proxy_opener = request.build_opener(proxy_handler)
# 安装opener
request.install_opener(proxy_opener) try:
req = request.Request(url, headers=requestHeader)
rsq = request.urlopen(req, timeout=5.0)
code = rsq.getcode()
return code
except error.URLError as e:
return e
在这个方法中会得到一个状态码的返回,如果返回码是200,那么这个代理ip就是可用的。
def verifyProxyList():
verifiedFile = open('verified.txt', 'a')
while True:
lock.acquire()
ll = inFile.readline().strip()
lock.release()
if len(ll) == 0 : break
line = ll.strip().split('|')
ip = line[1]
port = line[2]
realip = ip+':'+port
code = verifyProxy(realip)
if code == 200:
lock.acquire()
print("---Success:" + ip + ":" + port)
verifiedFile.write(ll + "\n")
lock.release()
else:
print("---Failure:" + ip + ":" + port)
写完校验方法后,就从事先爬取到的所有代理ip的txt文件中获取到ip和端口(ip地址:端口),通过判断返回值是否为200来进行写入到有效的txt文件中。
调用函数
万事俱备只欠调用!
if __name__ == '__main__':
tmp = open('proxy.txt', 'w')
tmp.write("")
tmp.close()
tmp1 = open('verified.txt', 'w')
tmp1.write("")
tmp1.close()
getProxy("http://www.xicidaili.com/nn/")
getProxy("http://www.xicidaili.com/nt/")
getProxy("http://www.xicidaili.com/wn/")
getProxy("http://www.xicidaili.com/wt/") all_thread = []
# 30个线程
for i in range(30):
t = threading.Thread(target=verifyProxyList)
all_thread.append(t)
t.start() for t in all_thread:
t.join() inFile.close()
verifiedtxt.close()
因为西刺代理提供了四种代理ip,所以分别有四个网址。这里我们也采用了线程的方法,主要是为了防止出现线程互相争夺导致我们的数据不精确,在上面几个方法中我们也通过了同步锁来对其进行线程安全的保证。
其实总体来说这个爬虫不是特别的难,主要的难点在于数据量可能有点多,很多人可能不会考虑到线程安全的问题,导致数据获取的不精确。
100行代码打造属于自己的代理ip池的更多相关文章
- 100行代码让您学会JavaScript原生的Proxy设计模式
面向对象设计里的设计模式之Proxy(代理)模式,相信很多朋友已经很熟悉了.比如我之前写过代理模式在Java中实现的两篇文章: Java代理设计模式(Proxy)的四种具体实现:静态代理和动态代理 J ...
- 【转】100行代码实现最简单的基于FFMPEG+SDL的视频播放器
FFMPEG工程浩大,可以参考的书籍又不是很多,因此很多刚学习FFMPEG的人常常感觉到无从下手.我刚接触FFMPEG的时候也感觉不知从何学起. 因此我把自己做项目过程中实现的一个非常简单的视频播放器 ...
- 100行代码实现现代版Router
原文:http://www.html-js.com/article/JavaScript-version-100-lines-of-code-to-achieve-a-modern-version ...
- 用JavaCV改写“100行代码实现最简单的基于FFMPEG+SDL的视频播放器 ”
FFMPEG的文档少,JavaCV的文档就更少了.从网上找到这篇100行代码实现最简单的基于FFMPEG+SDL的视频播放器.地址是http://blog.csdn.net/leixiaohua102 ...
- 100行代码实现最简单的基于FFMPEG+SDL的视频播放器(SDL1.x)【转】
转自:http://blog.csdn.net/leixiaohua1020/article/details/8652605 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] ...
- GuiLite 1.2 发布(希望通过这100+行代码来揭示:GuiLite的初始化,界面元素Layout,及消息映射的过程)
经过开发群的长期验证,我们发现:即使代码只有5千多行,也不意味着能够轻松弄懂代码意图.痛定思痛,我们发现:虽然每个函数都很简单(平均长度约为30行),可以逐个击破:但各个函数之间如何协作,却很难说明清 ...
- 【编程教室】PONG - 100行代码写一个弹球游戏
大家好,欢迎来到 Crossin的编程教室 ! 今天跟大家讲一讲:如何做游戏 游戏的主题是弹球游戏<PONG>,它是史上第一款街机游戏.因此选它作为我这个游戏开发系列的第一期主题. 游戏引 ...
- 100行代码实现HarmonyOS“画图”应用,eTS开发走起!
本期我们给大家带来的是"画图"应用开发者Rick的分享,希望能给你的HarmonyOS开发之旅带来启发~ 介绍 2021年的华为开发者大会(HDC2021)上,HarmonyOS ...
- python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检 ...
随机推荐
- 图片缩放——利用layui的滑块
@layui官网文档.@参考博客 参考博客中能实现,但是效果差强人意,在前辈的基础上进行了改造,并支持了动态多图列表 <%@ page language="java" con ...
- HTML布局排版5 测试某段html页面1
除了div,常见的还有用table布局,这里直接用前面博文的页头页尾,如下面的页面的部分,是个简单的table.该页面样式,如果拖动浏览器,可以看到table和文本框总是居中,但是文本框下方那两个按钮 ...
- Centos 更改MySQL5.7数据库目录位置
原文地址:https://blog.csdn.net/zyw_java/article/details/78512285 Centos7.3 安装Mysql5.7并修改初始密码 基于 CentOS M ...
- gcr 镜像无法下载问题
GCR Proxy Cache 帮助 GCR Proxy Cache服务器相当于一台GCR镜像服务器,国内用户可以经由该服务器从gcr.io下载镜像. 使用GCR Proxy Cache从gcr.io ...
- 方法重载overload与方法重写overwrite
方法重载overload: 在同一个类中,出现相同的方法名,与返回值无关,参数列表不同:1参数的个数不同 2参数类型不同 在调用方法时,java虚拟机会通过参数列表来区分不同同名的方法 方法重写ove ...
- eclipse设置text file encoding UTF-8和文件的换行符 Unix 格式
阿里华山版java开发手册代码格式第10条: 步骤:1.Window - Preferences, 2.左边选择 General - Workspace , 3.右边Text file encodin ...
- Python基础系列讲解——try_except异常处理机制
在Python编程中不可避免的会出现错误,在调试阶段出现语法之类的错误时,Pycharm会在Debug窗口提示错误,但是程序在运行时由于内部隐含的问题而引起错误,会导致程序终止执行.比如以下例程中,使 ...
- 剑指offer44:翻转单词顺序列
1 题目描述 牛客最近来了一个新员工Fish,每天早晨总是会拿着一本英文杂志,写些句子在本子上.同事Cat对Fish写的内容颇感兴趣,有一天他向Fish借来翻看,但却读不懂它的意思.例如,“stude ...
- python学习-58 configparse模块
configparse模块 1.生成文件 import configparser # 配置解析模块 config = configparser.ConfigParser() # config = { ...
- ~jmeter解决csrftoken登录问题
一.登录接口 url:http://192.168.163.128:/user/login/ 请求方法:post 请求参数: account:用户名 password:登录密码 remember:是否 ...