AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记
这篇文章的任务是 “根据文本描述” 生成图像。以往的常规做法是将整个句子编码为condition向量,与随机采样的高斯噪音\(z\)进行拼接,经过卷积神经网络(GAN,变分自编码等)来上采样生成图像。这篇文章发现的问题是:仅通过编码整个句子去生成图像会忽略掉一些细粒度的信息,而这些细粒度的信息是由单词层面来决定的(例如颜色、形状等)。
解决的方法是在生成过程中引入对单词的注意力机制,这种注意力机制需要把相关的单词与对应的图像区域匹配起来, 如果让我自己去设计这种匹配关系,我的第一反应是要先进行大量的人工标注(根据单词先人工框出来图像中对应的区域),这样搞的话光标注就需要巨大的人力与时间(特别是在COCO这么大的数据集上。。。)。
AttnGAN没有对数据集进行额外的标注, 利用生成过程中的 \(C \times N \times N\) feature map ,有 \(N^{2}\) 个位置。每一位置的向量维度是 \(C\),为了表示某一位置与句子中某一单词的相关性,可以根据 某一位置向量与单词向量的内积 / 某一位置向量与句子中所有单词向量内积之和 来得到与某一单词的权重(相关)系数,那么在某一位置上的单词表征可以表示为所有单词向量的加权和。

方法
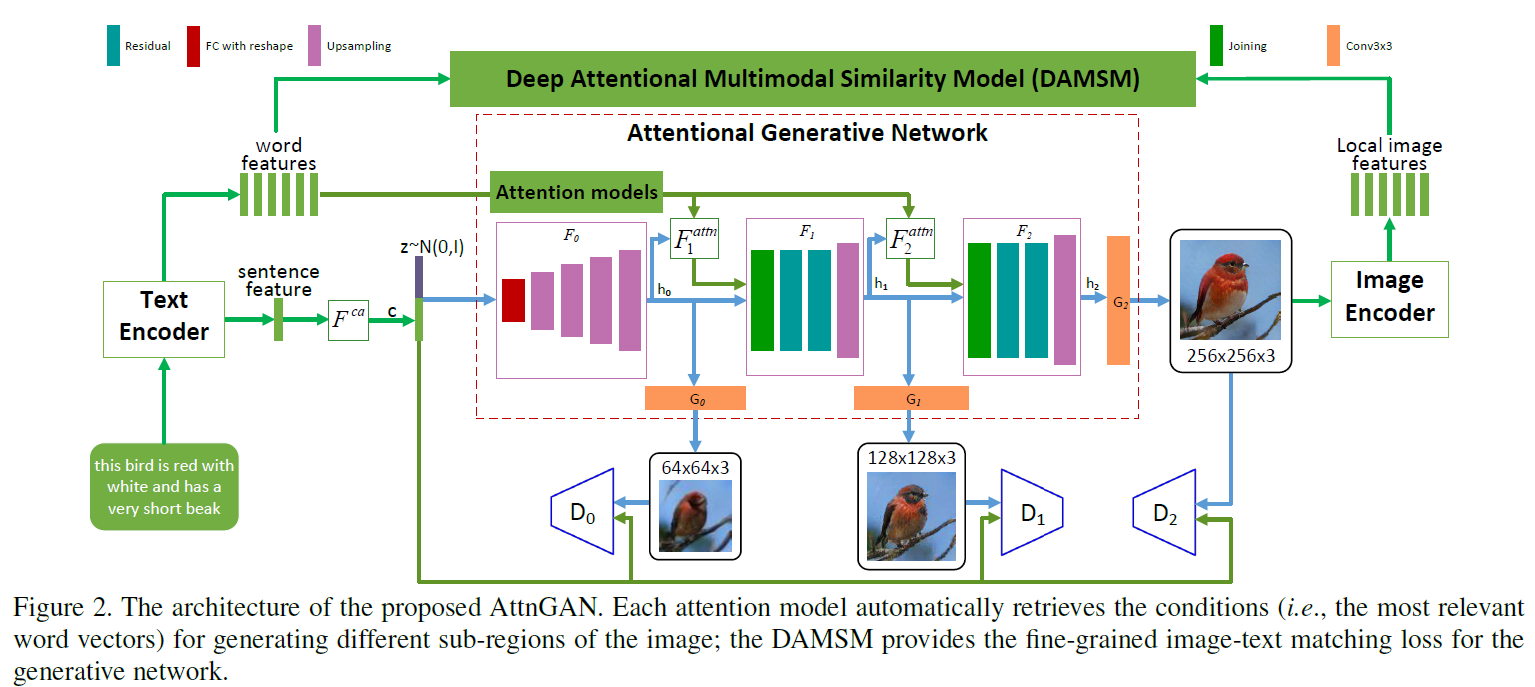
模型包含两个部分,
- 注意力生成网络
- 多模态注意力相似模型(DAMSM,是个匹配网络)
注意力生成网络包含多个阶段的生成(这里是三次生成,只要计算资源足,还可以加), coarse-to-fine的图像生成模式。 DAMSM需要在真实的数据对上预训练,相当于给生成网络加了一个监督信息,使生成的图像能像真实图像那样与相应的文本匹配。
Attentional Generative Network(注意力生成网络)
输入文本,经过Text Encoder(用的是双向LSTM)编码输出“整句特征”(global sentence vector)\(\bar{e}\) 和拼接起来的“单词特征” \(e \in \mathbb{R}^{D \times T}\)。 \(\bar{e}\) 经过 Conditioning Augmentation(具体可以看stackgan和vae的文章,目的是为了降维以及增加多样性) 进行降维转换来作为条件向量,用 \(F^{ca}\) 来表示Conditioning Augmentation操作。
第一次的image features的生成过程为:
\[
h_{0} = F_{0}(z, F^{ca}(\bar{e}))
\]
从图中可以看出\(F_{0}\)代表着一系列的上采样操作,但还没有生成最后的图像,输出了一个隐含特征\(h_{0}\)。这个隐含特征已经初具图像的位置和物体信息。后面的生成过程为:
\[
h_{i} = F_{i}(h_{i-1}, F^{attn}_{i}(e,h_{i-1}))
\]
这里面最重要的就是\(F_{i}^{attn}\)的操作,也是作者所提出的创新点,即如何将单词信息融入到生成的过程中去,而且不同单词对于图像中不同区域的attention作用也是不同的。先来看看\(F^{attn}_{i}\)的操作,输入是单词向量矩阵 \(e\) 以及前一阶段所得到的image features \(h_{i-1}\)(\(h \in \mathbb{R}^{\hat{D} \times N}\))。单词向量要经过一次乘积转换(可以加个全连接层)来改变维度到\(\hat{D}\)维,\(e^{'}=Ue\) where \(U\in\mathbb{R}^{\hat{D}\times D}\),与image features的维度保持一致, 有助于后面进行内积操作计算相似性。 \(h\) 中的每一列其实都代表着图像的一个sub-region,其中\(N=\sqrt{N}\times \sqrt{N}\)。对于第 \(j\) 个sub-region,用句子中所有的单词向量来进行表示,那么相关的单词向量应具有更大的权重,不相关的单词向量与其的相关权重应很小,每个sub-region进行单词向量加权和的结果称为“word-context”(相当于加入了具有侧重点的文本condition)。每一个sub-region与所有的单词向量权重计算以及最后的word-context计算过程为
\[
c_{j} = \sum\limits_{i=0}\limits^{T-1}\beta_{j,i}e^{'}_{i}, where \beta_{j,i}=\frac{exp(s^{'}_{j,i})}{\sum_{k=0}^{T-1}exp(s^{'}_{j,k})}
\]
\(s^{'}_{j,i}=h^{T}_{j}e^{'}_{i}\), \(\beta_{j,i}\)表示当生成图像第\(j\)个子区域时,第\(i\)个单词所获得的关注程度。\(c_{j}\)代表着第\(j\)个子区域的word-context向量,\(F^{attn}\)就是为了生成所有子区域的word-context向量:\(F^{attn}(e,h)=(c_{0},c_{1},\ldots,c_{N-1})\in \mathbb{R}^{\hat{D}\times N}\)。
图像的生成是根据Image features \(h_{i}\)
\[
\hat{x_{i}}=G_{i}(h_{i})
\]
在注意力生成网络里的损失也就是常规的conditionGAN损失的变种(包含带有文本条件与不带有条件):
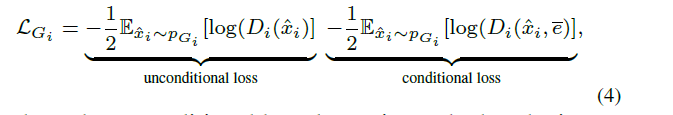
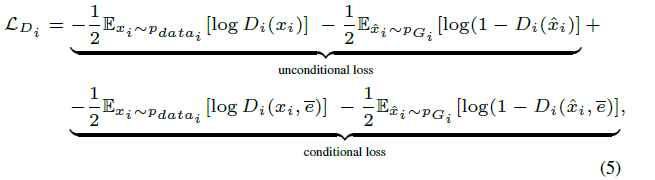
Deep Attentional Multimodal Similarity Model(匹配模型)
这一部分的提出相当于额外加了一个文本-图像匹配的监督信息,由于DAMSM是在真实数据集上预训练好的(即真实图像与相关的文本匹配损失会比较小),在输入生成的图像与相关的文本信息时,它会倒逼着注意力生成网络生成更加真实且与文本相关的图像。在这一模型中,从两个部分来计算匹配损失,分别是基于整个句子的和基于逐个单词的。
图像编码器(image encode)将图像下采样到feature matrix \(f\in \mathbb{R}^{768\times 289}\)(这是从\(768\times 17\times 17\) reshape 过来的),为了度量图像与文本的相似性,文本与图像的特征维度应保持一致,在这里,是将图像的特征进行转换与单词向量的维度保持一致:
\[
v=Wf, \bar{v}=\bar{W}\bar{f}
\]
\(v\)是图像特征转换过之后的特征\(v\in \mathbb{R}^{D\times 289}\),\(\bar{v}\in \mathbb{R}^{D}\)表示图像的全局向量,\(\bar{f}\)是从Inception-v3网络的最后一层(全连接分类层)提取出来的,作为全局特征。
经过维度统一之后,下面的单词层面的匹配操作类似于attention生成过程中的word-context计算过程,只不过这里是针对每个单词计算出相应的sub-region的加权和,也就是说每个单词都有个视觉信息的加权表征。计算过程如下:
\[
s=e^{T}v
\]
\(s\in \mathbb{R}^{T\times 289}\),表示单词与sub-region的内积来度量相似性。这里搞了一个归一化,说是能提升效果
\[
\bar{s}_{i,j} = \frac{exp(s_{i,j})}{\sum_{k=0}^{T-1}exp(s_{k,j})}
\]
也就是针对同一个sub-region,所有单词相似性的归一化。
针对每一个单词所有的sub-region视觉信息加权和称为“region-context”向量,记作\(c_{i}\),计算过程为
\[
c_{i}=\sum_\limits{j=0}^\limits{288}\alpha_{j}v_{j}, where \alpha_{j}=\frac{exp(\gamma_{1}\bar{s}_{i,j})}{\sum_{k=0}^{288}exp(\gamma_{1}\bar{s}_{i,k})}
\]
\(\gamma_{1}\)表示对于相关的sub-regions扩大它的影响(相似性值越大的占的比重更大)。这样每一个单词都有一个对应的region-context视觉信息,可以进行单词-视觉信息相关的匹配度量,这里用余弦距离来衡量差异
\[
R(c_{i},e_{i})=(c_{i}^{T}e_{i})/(||c_{i}||||e_{i}||)
\]
基于单词层面来衡量整个图像与文本的相似性
\[
R(Q,D)=log\left(\sum_\limits{i=1}^\limits{T-1}exp(\gamma_{2}R(c_{i},e_{i}))\right)^{\frac{1}{\gamma_{2}}}
\]
之所以用这个形式,是为了突出最相关的word-to-region-context pair,用\(\gamma_{2}\)来调节突出程度,当\(\gamma_{2} \rightarrow \infty\) 时,上式结果
趋近于\(\max_{i=1}^{T-1}R(c_{i},e_{i})\)。
DAMSM的监督标签是"图片与整个句子是否匹配"。用图片去匹配句子,目标函数的后验概率形式为
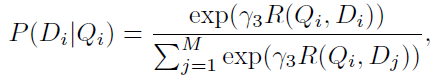
\(Q\)表示图像,\(D\)表示句子
基于单词水平的匹配损失函数为:
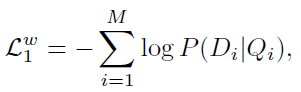
对应的,在以句子匹配图像的情况下,损失函数为
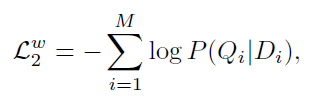
另外,基于整个句子的匹配损失设计与上面的类似,不同点是直接用全局向量计算相似距离。
\[
R(Q,D)=(\bar{v}^{T}\bar{e}/\left(||\bar{v}||||\bar{e}||\right))
\]
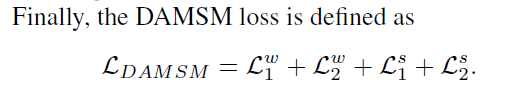
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记的更多相关文章
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 本文将利 ...
- 《MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment》论文阅读笔记
出处:2018 AAAI SourceCode:https://github.com/salu133445/musegan abstract: (写得不错 值得借鉴)重点阐述了生成音乐和生成图片,视频 ...
- AsciiDoc Text based document generation
AsciiDoc Text based document generation AsciiDoc Home Page http://asciidoc.org/ AsciiDoc is a t ...
- 论文笔记之:Generative Adversarial Text to Image Synthesis
Generative Adversarial Text to Image Synthesis ICML 2016 摘要:本文将文本和图像练习起来,根据文本生成图像,结合 CNN 和 GAN 来有效的 ...
- 《MIDINET: A CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORK FOR SYMBOLIC-DOMAIN MUSIC GENERATION》论文阅读笔记
出处 arXiv.org (引用量暂时只有3,too new)2017.7 SourceCode:https://github.com/RichardYang40148/MidiNet Abstrac ...
- 《Image Generation with PixelCNN Decoders》论文笔记
论文背景:Google Deepmind团队于2016发表在NIPS上的文章 motivation:提出新的image generation model based on pixelCNN[1]架构. ...
- 论文阅读 | Adversarial Example Generation with Syntactically Controlled Paraphrase Networks
[pdf] [code] 句法控制释义网络 SCPNS 生成对抗样本 我们提出了句法控制意译网络(SCPNs),并利用它们来生成对抗性的例子.给定一个句子和一个目标语法形式(例如,一个选区解析),s ...
- CSAGAN:LinesToFacePhoto: Face Photo Generation from Lines with Conditional Self-Attention Generative Adversarial Network - 1 - 论文学习
ABSTRACT 在本文中,我们探讨了从线条生成逼真的人脸图像的任务.先前的基于条件生成对抗网络(cGANs)的方法已经证明,当条件图像和输出图像共享对齐良好的结构时,它们能够生成视觉上可信的图像.然 ...
- 《StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN》论文笔记
出处:arxiv 2016 尚未出版 Motivation 根据文字描述来合成相片级真实感的图片是一项极具挑战性的任务.现有的生成手段,往往只能合成大体的目标,而丢失了生动的细节信息.StackGAN ...
随机推荐
- js学习笔记(1)
前言 因为后期的软件工程组队作业需要js,在纪华裕大佬的带领下(我觉得他好像更喜欢纪华裕这个名字),我开始了js的学习.其实这篇博客应该在两天前的晚上就发出来了,因为忙着写个人编程,拖到了现在,组 ...
- cross socket和msgpack的数据序列和还原
cross socket和msgpack的数据序列和还原 procedure TForm1.Button1Click(Sender: TObject); begin var pack: TSimple ...
- Flutter移动电商实战 --(53)购物车_商品列表UI框架布局
cart_page.dart 清空原来写的持久化的代码; 添加对应的引用,stless生成一个静态的类.建议始终静态的类,防止重复渲染 纠正个错误,上图的CartPage单词拼错了,这里改过来防止后面 ...
- C++ 中virtual 用法
一.virtual 修饰基类中的函数,派生类重写该函数: #include using namespace std; class A{ public: virtual void display(){ ...
- cat file | while read line的问题
循环中的重定向 或许你应该在其他脚本中见过下面的这种写法: while read line do … done < file 刚开始看到这种结构时,很难理解< file是如何 ...
- flume 诞生背景 数据同步
flume一开始是cloudlera的项目 当时他们的工程师需要一次次地为客户编写工具 来实现数据的自动化导入
- oracle库两个表关联查询时用 count 报错【我】
oracle数据库,需要对两个表进行关联查询(根据两个字段),结果发现关联后不能改为 count 获取数量,报错如下: 同样的sql换到另外一个数据库就可以(只是因为数据量在千万级,所以很慢,用时40 ...
- ES6 Syntax and Feature Overview
View on GitHub Note: A commonly accepted practice is to use const except in cases of loops and reass ...
- SpringCloud学习成长之路三 服务消费者(Feign)
一.Feign简介 Feign是一个声明式的伪Http客户端,它使得写Http客户端变得更简单.使用Feign,只需要创建一个接口并注解. 它具有可插拔的注解特性,可使用Feign 注解和JAX-RS ...
- PAT 甲级 1051 Pop Sequence (25 分)(模拟栈,较简单)
1051 Pop Sequence (25 分) Given a stack which can keep M numbers at most. Push N numbers in the ord ...