Hadoop 部署之 ZooKeeper (二)
一、Zookeeper功能简介
ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现。分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列等功能。
二、ZooKeeper基本概念
1、集群角色
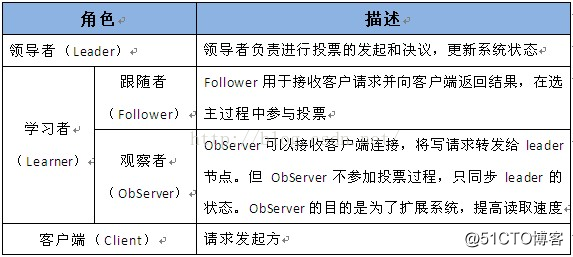
一个 ZooKeeper 集群同一时刻只会有一个 Leader,其他都是 Follower 或 Observer。
ZooKeeper 配置很简单,每个节点的配置文件(zoo.cfg)都是一样的,只有 myid 文件不一样。myid 的值必须是 zoo.cfg中server.{数值} 的{数值}部分。
ZooKeeper 默认只有 Leader 和 Follower 两种角色,没有 Observer 角色。为了使用 Observer 模式,在任何想变成Observer的节点的配置文件中加入:peerType=observer 并在所有 server 的配置文件中,配置成 observer 模式的 server 的那行配置追加 :observer
三、ZooKeeper 的安装
1、下载安装(在datanode节点安装)
下载安装包
wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
解压安装包
tar xf zookeeper-3.4.10.tar.gz
mv zookeeper-3.4.10 /usr/local/zookeeper
mkdir -p /home/zookeeper
zk01节点(datanode1)配置id
echo "1">/home/zookeeper/myid
zk02节点(datanode2)配置id
echo "2">/home/zookeeper/myid
zk03节点(datanode3)配置id
echo "3">/home/zookeeper/myid
2、配置ZooKeeper环境变量
编辑文件/etc/profile.d/zookeeper.sh。
# ZOOKEEPER ENV
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
使ZK环境变量生效。
source /etc/profile.d/zookeeper.sh
3、配置 zoo.cfg
编辑文件/usr/local/zookeeper/conf/zoo.cfg。
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=zk01:2888:3888
server.2=zk02:2888:3888
server.3=zk03:2888:3888
比较重要的配置如下:
dataDir=/home/zookeeper
server.1=zk01:2888:3888
server.2=zk02:2888:3888
server.3=zk03:2888:3888
4、启动各节点 ZK 服务
[root@datanode01 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@datanode02 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@datanode03 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
5、查看各节点启动状态和角色
[root@datanode01 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@datanode02 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[root@datanode03 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
官方文档:https://zookeeper.apache.org/doc/current/zookeeperStarted.html
Hadoop 部署之 ZooKeeper (二)的更多相关文章
- Hadoop的HA(ZooKeeper)安装与部署
非HA的安装步骤 https://www.cnblogs.com/live41/p/15467263.html 一.部署设定 1.服务器 c1 192.168.100.105 zk.name ...
- 启动Hadoop HA Hbase zookeeper spark
服务器角色 服务器 192.168.58.180 192.168.58.181 192.168.58.182 192.168.58.183 Name CentOSMaster Slvae1 Slave ...
- hadoop进阶----hadoop经验(一)-----生产环境hadoop部署在超大内存服务器的虚拟机集群上vs几个内存较小的物理机
生产环境 hadoop部署在超大内存服务器的虚拟机集群上 好 还是 几个内存较小的物理机上好? 虚拟机集群优点 虚拟化会带来一些其他方面的功能. 资源隔离.有些集群是专用的,比如给你三台设备只跑一个 ...
- Hadoop部署方式-完全分布式(Fully-Distributed Mode)
Hadoop部署方式-完全分布式(Fully-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本博客搭建的虚拟机是伪分布式环境(https://w ...
- Hadoop部署方式-伪分布式(Pseudo-Distributed Mode)
Hadoop部署方式-伪分布式(Pseudo-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载相应的jdk和Hadoop安装包 JDK:h ...
- Hadoop部署方式-本地模式(Local (Standalone) Mode)
Hadoop部署方式-本地模式(Local (Standalone) Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop总共有三种运行方式.本地模式(Local ...
- 基于Docker搭建大数据集群(三)Hadoop部署
主要内容 Hadoop安装 前提 zookeeper正常使用 JAVA_HOME环境变量 安装包 微云下载 | tar包目录下 Hadoop 2.7.7 角色划分 角色分配 NN DN SNN clu ...
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- SQL Server 2008 数据库镜像部署实例之二 配置镜像,实施手动故障转移
SQL Server 2008 数据库镜像部署实例之二 配置镜像,实施手动故障转移 上一篇文章已经为配置镜像数据库做好了准备,接下来就要进入真正的配置阶段 一.在镜像数据库服务器上设置安全性并启动数据 ...
随机推荐
- Nginx中ngx_http_auth_basic_moudel和ngx_http_stub_status_module模块
ngx_http_auth_basic_module实现基于⽤用户的访问控制,使⽤用basic机制进⾏行行⽤用户认证指令:5.1 auth_basicSyntax: auth_basic string ...
- C# GridView 的使用
1.GridView无代码分页排序: 1.AllowSorting设为True,aspx代码中是AllowSorting="True":2.默认1页10条,如果要修改每页条数,修改 ...
- eclipse中toolbar位置的系统URI
org.eclipse.ui.ide.IIDEActionConstants 这个类里存了系统toolbar,菜单等URI 定义自己的toolbar或者menu时,指定位置after=addition ...
- 15、Spring Boot 2.x 集成 Swagger UI
1.15.Spring Boot 2.x 集成 Swagger UI 完整源码: Spring-Boot-Demos 1.15.1 pom文件添加swagger包 <swagger2.versi ...
- Pollard-Rho 总结
将一个大数\(N\)分解质因子. 试除法,暴力枚举\(1-\sqrt{N}\)的数.时间复杂度:\(O(\sqrt{N})\). 通常,这个复杂度够了,但有时,\(N\leq10^{18}\). 这就 ...
- The Preliminary Contest for ICPC Asia Xuzhou 2019 【 题目:so easy】{并查集维护一个数的下一个没有被删掉的数} 补题ING
题意:给[1,n],n个数,有两种操作: 1 x,删去x2 x,查询还未被删去的数中大于等于x的最小的数是多少. input: output: 做法:按照并查集的方法压缩路径 代码: #include ...
- ES6-3 变量的解构赋值
1.数组的解构赋值 数组的解构赋值其实是=左右进行“模式匹配”. ❗️❗️❗️=右侧是具体的数值,不是变量!,=左侧的是变量!如果右侧是变量形式,需要先计算出具体的数值!! let [a,[b],c] ...
- 2018-2019 ACM-ICPC, China Multi-Provincial Collegiate Programming Contest
目录 Contest Info Solutions A. Maximum Element In A Stack B. Rolling The Polygon C. Caesar Cipherq D. ...
- qt5 + vs2015自定义控件错误:undefend interface
控件中编译时因为是把所有的单个控件集成到一个lib中,所以会引用#include<QDesignerCustomWidgetInterface>以及#include<QDesigne ...
- 【线性代数】4-4:正交基和Gram算法(Orthogonal Bases and Gram-Schmidt)
title: [线性代数]4-4:正交基和Gram算法(Orthogonal Bases and Gram-Schmidt) categories: Mathematic Linear Algebra ...