JDK源码那些事儿之并发ConcurrentHashMap上篇
前面已经说明了HashMap以及红黑树的一些基本知识,对JDK8的HashMap也有了一定的了解,本篇就开始看看并发包下的ConcurrentHashMap,说实话,还是比较复杂的,笔者在这里也不会过多深入,源码层次上了解一些主要流程即可,清楚多线程环境下整个Map的运作过程就算是很大进步了,更细的底层部分需要时间和精力来研究,暂不深入
前言
jdk版本:1.8
JDK7中,ConcurrentHashMap把内部细分成了若干个小的HashMap,称之为段(Segment),默认被分为16个段。多线程写操作对每个段进行加锁,段与段之间互不影响。而JDK8则抛弃了这种结构,类似HashMap,多线程下为了保证线程安全,通过CAS和synchronized进行并发控制,降低锁颗粒度,性能上也就提高许多
同时由于降低锁粒度,同时需要兼顾读操作的正确性,增加了许多内部类来帮助完成并发控制,保证读操作的正确执行,同时支持了并发扩容操作,算是相当复杂了,由于过于复杂,对ConcurrentHashMap的说明将分为两章说明,本章就对ConcurrentHashMap的常量,变量,内部类和构造方法进行说明,下一章将重点分析其中的重要方法
这里先提前说明下,有个整体印象:
- ConcurrentHashMap结构上类似HashMap,即数组+链表+红黑树
- 锁颗粒度降低,复杂度提升
- 多线程并发扩容
- 多线程下保证读操作正确性
- 计数方式处理:分段处理
- 函数式编程(不是本文重点,自行查阅)
类定义
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable
继承AbstractMap,实现了ConcurrentMap接口,ConcurrentMap也可以看看源码,加入了并发操作方法,是一个实现了并发访问的集合接口
常量
有些常量和变量可能不是很好理解,在后边到方法时会尽量详细说明
/**
* 最大容量
*/
private static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认初始化容量,同HashMap,必须为2的倍数
*/
private static final int DEFAULT_CAPACITY = 16;
/**
* 可能达到的最大的数组大小值(非2的次幂),2的31次方-8
*/
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 默认并发级别,新版本无用,为了兼容旧版本,使用的地方在序列化方法writeObject中
*/
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
/**
* 负载因子,只是为了兼容性
* 构造方法里指定的负载因子只会影响初始化的table容量
* 一般也不使用浮点数计算
* ConcurrentHashMap不会使用这个常量,而使用类似 n -(n >>> 2) 的方式来进行调整大小
*/
private static final float LOAD_FACTOR = 0.75f;
/**
* 树化阈值
* 同HashMap
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 调整大小时树转化为链表的阈值
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 可以转化为红黑树的最小数组容量,即调整为红黑树时数组长度最小值必须为MIN_TREEIFY_CAPACITY
* 如果bin包含太多节点,则会调整表的大小
* 该值应至少为4 * TREEIFY_THRESHOLD,避免扩容和树化阈值之间的冲突。
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
*
* 扩容的每个线程每次最少要迁移16个hash桶
* 每个线程都可参与迁移任务,每个线程至少要连续迁移MIN_TRANSFER_STRIDE个hash桶
* 帮助扩容提高了效率,当然复杂性也提高了很多,要处理的事情更多
*/
private static final int MIN_TRANSFER_STRIDE = 16;
/**
* 与移位量和最大线程数相关
* 先了解就好,后边涉及到方法会进行说明
*/
private static int RESIZE_STAMP_BITS = 16;
/**
* 帮助扩容的最大线程数
*/
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
/**
* 移位量
*/
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
/**
* Node hash值编码,规定了各自的含义
*/
// forwarding nodes节点hash值
// 临时节点,扩容时出现,不存储实际数据
// 如果旧数组的一个hash桶中全部的节点都迁移到新数组中,旧数组就在这个hash桶中放置一个ForwardingNode
// 读操作遇见该节点时,转到新的table数组上执行,写操作遇见时,则帮助扩容
static final int MOVED = -1; // hash for forwarding nodes
// TREEBIN节点
// TreeBin是ConcurrentHashMap中用于代理操作TreeNode的特殊节点
// 保存实际的红黑树根节点,在红黑树插入节点时会对读操作造成影响,该对象维护了一个读写锁来保证多线程的正确性
static final int TREEBIN = -2; // hash for roots of trees
// ReservationNode节点hash值
// 保留节点,JDK8的新特性会用到,这里不过多说明
static final int RESERVED = -3; // hash for transient reservations
// 负数转正数,定位hash桶时用到了,负数Hash值有特殊含义,具体看后边
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
// CPU数量,限制边界,计算一个线程需要做多少迁移量
static final int NCPU = Runtime.getRuntime().availableProcessors();
// 序列化兼容性
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("segments", Segment[].class),
new ObjectStreamField("segmentMask", Integer.TYPE),
new ObjectStreamField("segmentShift", Integer.TYPE)
};
变量
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*
* volatile保证可见性
* Node类和HashMap中的类似,val和next属性通过volatile保证可见性
*/
transient volatile Node<K,V>[] table;
/**
* The next table to use; non-null only while resizing.
*
* 扩容时使用的数组,只在扩容时非空,扩容时会创建
*/
private transient volatile Node<K,V>[] nextTable;
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*
* sizeCtl = -1,表示有线程在进行初始化操作
* sizeCtl < 0且不为-1表示有多个线程正在进行扩容操作,jdk源码解释部分感觉有点问题
* 每次第一个线程参与扩容时,会将sizeCtl设置为一个与当前table长度相关的数值,避免出现问题,讲解方法时进行说明
* sizeCtl > 0,表示第一次初始化操作中使用的容量,或者初始化/扩容完成后的阈值
* sizeCtl = 0,默认值,此时在真正的初始化操作中使用默认容量
*/
private transient volatile int sizeCtl;
/**
* 多线程帮助扩容相关
* 下一个transfer任务的起始下标index + 1 的值
* transfer时下标index从length - 1到0递减
* 扩容index从后往前和迭代从前往后为了避免冲突
*/
private transient volatile int transferIndex;
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*
* 计数器基础值,记录元素个数,通过CAS操作进行更新
*/
private transient volatile long baseCount;
/**
* Spinlock (locked via CAS) used when resizing and/or creating CounterCells.
*
* CAS自旋锁标志位,counterCells扩容或初始化时使用
*/
private transient volatile int cellsBusy;
/**
* Table of counter cells. When non-null, size is a power of 2.
*
* 高并发下计数数组,counterCells数组非空时大小是2的n次幂
*/
private transient volatile CounterCell[] counterCells;
// views
private transient KeySetView<K,V> keySet;
private transient ValuesView<K,V> values;
private transient EntrySetView<K,V> entrySet;
同时需要注意静态代码块中已经获取了一些变量在对象中的内存偏移量,这个是为了方便我们在CAS中的使用,如果不明白CAS,请自行查阅资料学习,源码如下:
// Unsafe mechanics
private static final sun.misc.Unsafe U;
private static final long SIZECTL;
private static final long TRANSFERINDEX;
private static final long BASECOUNT;
private static final long CELLSBUSY;
private static final long CELLVALUE;
private static final long ABASE;
private static final int ASHIFT;
static {
try {
U = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentHashMap.class;
// 获取sizeCtl在对象中的内存偏移量,下同
SIZECTL = U.objectFieldOffset
(k.getDeclaredField("sizeCtl"));
TRANSFERINDEX = U.objectFieldOffset
(k.getDeclaredField("transferIndex"));
BASECOUNT = U.objectFieldOffset
(k.getDeclaredField("baseCount"));
CELLSBUSY = U.objectFieldOffset
(k.getDeclaredField("cellsBusy"));
Class<?> ck = CounterCell.class;
CELLVALUE = U.objectFieldOffset
(ck.getDeclaredField("value"));
Class<?> ak = Node[].class;
ABASE = U.arrayBaseOffset(ak);
int scale = U.arrayIndexScale(ak);
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
} catch (Exception e) {
throw new Error(e);
}
}
内部类
ConcurrentHashMap中增加了许多内部类来帮助完成并发下的操作
Node
普通Entry,与HashMap.Node类似,不同主要在于val和next属性设置为了volatile,同时不支持setValue方法,直接抛错,增加了find方法
TreeNode
继承自Node节点,与HashMap.TreeNode类似,之前文章专门介绍过这个内部类,可以去看看,同时需要说明的是,在ConcurrentHashMap中并不是直接操作TreeNode节点,而是通过TreeBin来代理操作的
TreeBin
代理操作TreeNode节点,保存红黑树的根节点,Hash值固定为-2,构造方法里传入对应的节点创建一棵红黑树。故在数组中保存的hash桶为红黑树结构时,在数组上的节点类型为TreeBin,该节点类自带读写锁
static final class TreeBin<K,V> extends Node<K,V> {
// 保存树的根节点
TreeNode<K,V> root;
// 链表头节点
volatile TreeNode<K,V> first;
// 最近一次waiter状态的线程
volatile Thread waiter;
// 锁状态
volatile int lockState;
// values for lockState
// 写锁,二进制001
static final int WRITER = 1; // set while holding write lock
// 等待获取写锁的状态,二进制010
static final int WAITER = 2; // set when waiting for write lock
// 读锁状态,二进制100
static final int READER = 4; // increment value for setting read lock
/**
* 红黑树结构重构时需要获取写锁
*/
private final void lockRoot() {
// CAS尝试获取写锁
if (!U.compareAndSwapInt(this, LOCKSTATE, 0, WRITER))
// 当线程获取到写锁时,才会返回
contendedLock(); // offload to separate method
}
/**
* 释放写锁
*/
private final void unlockRoot() {
lockState = 0;
}
/**
* 写线程不断尝试获取写锁,出现的几种情况的处理,这里不会有写线程和写线程竞争的情况出现
* 在写线程进入这个方法时,这个红黑树对应的桶已经被外部锁住,不会让写线程进入,故不需要考虑写写竞争的情况
* 故当前线程为写线程,则判断读线程即可
*/
private final void contendedLock() {
boolean waiting = false;
for (int s;;) {
// 取反与操作,其他线程未持有读锁
if (((s = lockState) & ~WAITER) == 0) {
// CAS尝试修改状态为写锁状态
if (U.compareAndSwapInt(this, LOCKSTATE, s, WRITER)) {
// 当前线程曾经处于waiting状态,将其清除
if (waiting)
waiter = null;
return;
}
}
// 有读线程
else if ((s & WAITER) == 0) {
// 当前线程置为wait状态,waiter记录线程
if (U.compareAndSwapInt(this, LOCKSTATE, s, s | WAITER)) {
waiting = true;
waiter = Thread.currentThread();
}
}
// 当前线程处于waiting状态
else if (waiting)
// 阻塞线程
LockSupport.park(this);
}
}
/**
* 从根节点开始进行遍历,查找到对应匹配的节点
* 同时需要注意多线程环境下如果有写锁则通过链表结构(不是用红黑树结构查询)进行查询
*/
final Node<K,V> find(int h, Object k) {
if (k != null) {
// 从first开始
for (Node<K,V> e = first; e != null; ) {
int s; K ek;
// 1.有写线程操作,通过链表查询不进行阻塞
// 2.WAITER状态
if (((s = lockState) & (WAITER|WRITER)) != 0) {
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
e = e.next;
}
// 读线程累加
else if (U.compareAndSwapInt(this, LOCKSTATE, s,
s + READER)) {
TreeNode<K,V> r, p;
try {
p = ((r = root) == null ? null :
r.findTreeNode(h, k, null));
} finally {
Thread w;
// 当线程为最后一个读线程并且有写锁被阻塞,此时应该通知阻塞的写线程重新尝试获得写锁
// getAndAddInt更新之后返回旧值
if (U.getAndAddInt(this, LOCKSTATE, -READER) ==
(READER|WAITER) && (w = waiter) != null)
// 唤醒阻塞的线程
LockSupport.unpark(w);
}
return p;
}
}
}
return null;
}
/**
* 大部分与HashMap.TreeNode中的putTreeVal操作类似
* 这里只说下不同的部分
* 多线程环境下主要是在平衡时加锁操作,防止读线程操作时树结构在变化
*/
final TreeNode<K,V> putTreeVal(int h, K k, V v) {
......
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
TreeNode<K,V> x, f = first;
first = x = new TreeNode<K,V>(h, k, v, f, xp);
if (f != null)
f.prev = x;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
// 新添加节点父节点为黑色,添加节点置为红色即可保证平衡
if (!xp.red)
x.red = true;
else {
//在进行插入平衡操作时会对读线程造成影响,需要加锁,让读线程以链表方式进行查询操作
lockRoot();
try {
root = balanceInsertion(root, x);
} finally {
unlockRoot();
}
}
break;
}
}
assert checkInvariants(root);
return null;
}
/**
* 删除时修改链表关系和删除平衡操作时需要添加锁,防止读线程读取错误
* 代码操作参考HashMap.TreeNode,这里不再详细说明了
*/
final boolean removeTreeNode(TreeNode<K,V> p) {
......
lockRoot();
try {
TreeNode<K,V> replacement;
TreeNode<K,V> pl = p.left;
TreeNode<K,V> pr = p.right;
if (pl != null && pr != null) {
TreeNode<K,V> s = pr, sl;
while ((sl = s.left) != null) // find successor
s = sl;
boolean c = s.red; s.red = p.red; p.red = c; // swap colors
TreeNode<K,V> sr = s.right;
TreeNode<K,V> pp = p.parent;
if (s == pr) { // p was s's direct parent
p.parent = s;
s.right = p;
}
else {
TreeNode<K,V> sp = s.parent;
if ((p.parent = sp) != null) {
if (s == sp.left)
sp.left = p;
else
sp.right = p;
}
if ((s.right = pr) != null)
pr.parent = s;
}
p.left = null;
if ((p.right = sr) != null)
sr.parent = p;
if ((s.left = pl) != null)
pl.parent = s;
if ((s.parent = pp) == null)
r = s;
else if (p == pp.left)
pp.left = s;
else
pp.right = s;
if (sr != null)
replacement = sr;
else
replacement = p;
}
else if (pl != null)
replacement = pl;
else if (pr != null)
replacement = pr;
else
replacement = p;
if (replacement != p) {
TreeNode<K,V> pp = replacement.parent = p.parent;
if (pp == null)
r = replacement;
else if (p == pp.left)
pp.left = replacement;
else
pp.right = replacement;
p.left = p.right = p.parent = null;
}
root = (p.red) ? r : balanceDeletion(r, replacement);
if (p == replacement) { // detach pointers
TreeNode<K,V> pp;
if ((pp = p.parent) != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
p.parent = null;
}
}
} finally {
unlockRoot();
}
assert checkInvariants(root);
return false;
}
Traverser
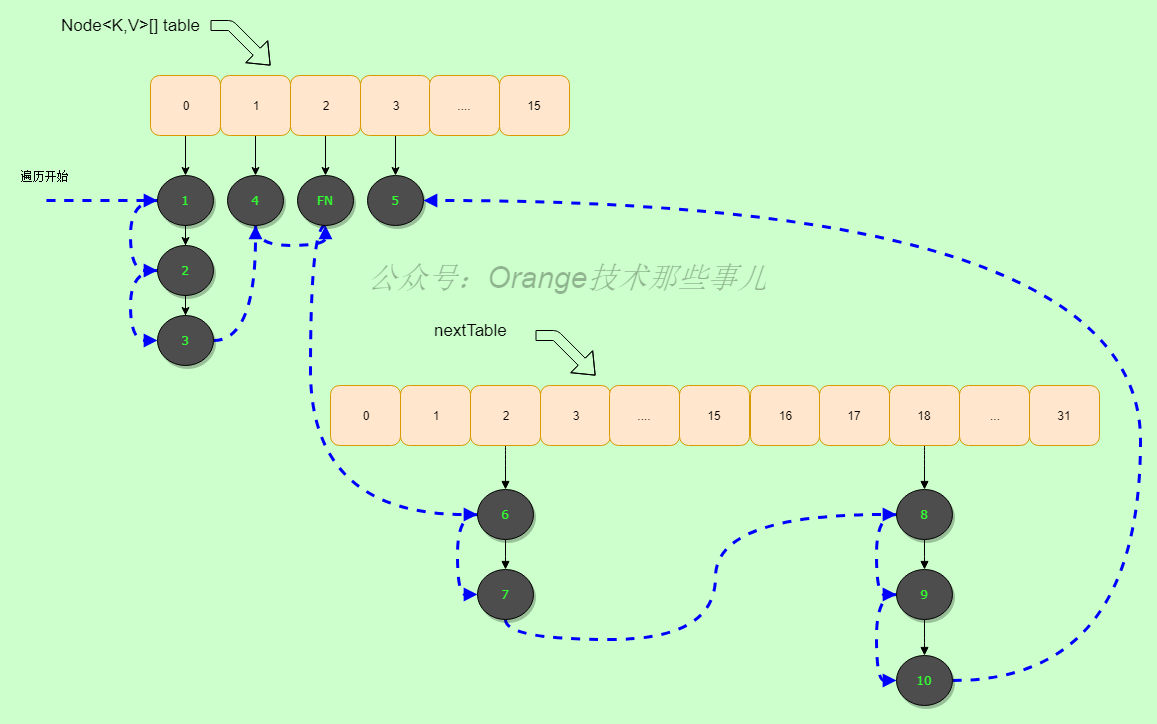
首先需要明白的是在并发下遍历读操作和扩容操作同时进行时,读操作有可能不会正确的进行,而为了解决这个问题,引入了Traverser这个内部类来完成并发操作下的读操作。在涉及到读取所有hash桶时,比如containsValue操作,不能使用HashMap的方式进行,一个一个hash桶遍历进行读取,此时扩容时,ConcurrentHashMap会在转移完一个hash桶后将一个ForwardingNode节点填入,如果还是非并发遍历,导致这个hash桶将不会被遍历到,正确的处理方式也就是遇到ForwardingNode节点时将当前数组信息和索引保存,然后在ForwardingNode节点的nextTable数组(也就是扩容后的数组)上进行遍历。这里还使用了栈结构TableStack,是为了处理多个ForwardingNode节点遍历的情况,同时需要注意的是,参考HashMap,在nextTable上需要遍历旧的hash桶和新的对应的扩容hash桶(index+size)
static class Traverser<K,V> {
// 当前table
Node<K,V>[] tab; // current table; updated if resized
// 下一个entry
Node<K,V> next; // the next entry to use
// 保存/恢复ForwardingNodes
TableStack<K,V> stack, spare; // to save/restore on ForwardingNodes
// 下一个遍历的hash桶index
int index; // index of bin to use next
// 开始index
int baseIndex; // current index of initial table
// 结尾index
int baseLimit; // index bound for initial table
// 数组长度
final int baseSize; // initial table size
Traverser(Node<K,V>[] tab, int size, int index, int limit) {
this.tab = tab;
this.baseSize = size;
this.baseIndex = this.index = index;
this.baseLimit = limit;
this.next = null;
}
/**
* 遍历到下一个有数据的节点并返回,无则返回null
*/
final Node<K,V> advance() {
Node<K,V> e;
// next值不为空,则直接获取其下一个节点
if ((e = next) != null)
e = e.next;
for (;;) {
Node<K,V>[] t; int i, n; // must use locals in checks
// e非空则直接返回当前值e并将next赋值为e便于下次再次调用该方法使用
if (e != null)
return next = e;
// 判断边界同时做了一些赋值操作
// 数组 t = tab
// 数组长度 n = t.length
// 数组index i = index
// 不满足直接返回null
if (baseIndex >= baseLimit || (t = tab) == null ||
(n = t.length) <= (i = index) || i < 0)
return next = null;
// e赋值为t的第i处hash桶节点值,判断是否为特殊节点
if ((e = tabAt(t, i)) != null && e.hash < 0) {
// ForwardingNode节点说明正在扩容,此时遍历读需要转移到扩容数组上进行
if (e instanceof ForwardingNode) {
// tab指向扩容数组
tab = ((ForwardingNode<K,V>)e).nextTable;
// e置空,继续循环
e = null;
// 保存此时的未扩容前的数组状态,相当于入栈操作
pushState(t, i, n);
continue;
}
// TreeBin节点,e置为first节点
else if (e instanceof TreeBin)
e = ((TreeBin<K,V>)e).first;
else
// 保留节点
e = null;
}
if (stack != null)
// 出栈操作,恢复tab到未扩容之前的数组继续遍历
recoverState(n);
else if ((index = i + baseSize) >= n)
// 更新为下一个hash桶索引
index = ++baseIndex; // visit upper slots if present
}
}
/**
* 入栈操作,保存当前数组的状态
*/
private void pushState(Node<K,V>[] t, int i, int n) {
TableStack<K,V> s = spare; // reuse if possible
if (s != null)
spare = s.next;
else
s = new TableStack<K,V>();
s.tab = t;
s.length = n;
s.index = i;
s.next = stack;
stack = s;
}
/**
* 出栈操作,恢复扩容之前的数组状态
*/
private void recoverState(int n) {
TableStack<K,V> s; int len;
while ((s = stack) != null && (index += (len = s.length)) >= n) {
n = len;
index = s.index;
tab = s.tab;
s.tab = null;
TableStack<K,V> next = s.next;
s.next = spare; // save for reuse
stack = next;
spare = s;
}
if (s == null && (index += baseSize) >= n)
index = ++baseIndex;
}
}
遍历过程可参考下图(图中数据非真实数据):
ForwardingNode
ForwardingNode节点在扩容时被使用,hash值固定为-1,当进行扩容操作时,转移hash桶时会在原数组位置上放置一个ForwardingNode节点,表示当前位置hash桶已转移到新扩容数组上,当读线程读到ForwardingNode节点时则需要到新扩容数组对应的位置进行读操作,如果是写线程,则需要帮助进行扩容操作
/**
* A node inserted at head of bins during transfer operations.
*/
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
// MOVED hash值固定为-1
super(MOVED, null, null, null);
this.nextTable = tab;
}
// 提供find方法查找,这里通过nextTable进行遍历
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
// 前置判断
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
// 判断是hash桶第一个节点,返回这个节点
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
// 递归
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
// 特殊节点调用其自身方法
return e.find(h, k);
}
// 找到最后返回空
if ((e = e.next) == null)
return null;
}
}
}
}
ReservationNode
保留节点,源码仅compute,computeIfAbsent中使用,通过ReservationNode对hash桶进行加锁处理,写操作时正常情况下需要对第一个节点进行加锁处理,put操作使用CAS不需要加锁,而在compute,computeIfAbsent方法中比较复杂,需加锁处理,在hash桶节点为空时,添加一个ReservationNode节点,同时对其加锁处理
static final class ReservationNode<K,V> extends Node<K,V> {
ReservationNode() {
super(RESERVED, null, null, null);
}
Node<K,V> find(int h, Object k) {
return null;
}
}
构造方法
在有参构造函数中,传入初始容量参数,调用tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)),这里和HashMap就不一样了,可自行查阅源码,ConcurrentHashMap先扩大了1.5倍再调用tableSizeFor方法,可以回想下tableSizeFor方法的含义,和HashMap是相同的处理方式,同时构造方法也不是table进行初始化的地方,和HashMap类似,都是在插入K-V值时进行数组的初始化,构造方法仅仅是来设置属性值的,重要的在于sizeCtl,此时是用来记录数组初始化使用容量的,在initTable方法中使用
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
// 设置sizeCtl,此时表示数组初始化使用容量,因为在初始化时将会使用这个变量
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
// sizeCtl设置为默认容量,此时表示数组初始化使用容量
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
// concurrencyLevel 并发级别 兼容旧版本
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
// 同样进行设置sizeCtl,此时表示数组初始化使用容量
this.sizeCtl = cap;
}
initTable
构造方法并没有创建Node数组,最终执行是在put方法中的initTable方法,这个方法中也能看出sizeCtl在不同值下代表了不同的含义
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 在初始化时不能并发执行,在已经有线程进入初始化状态时,非初始化线程需让步操作,等待完成
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// CAS将sizeCtl置为-1
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 检查是否已经初始化,否则进入初始化过程
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// sc = 3n/4,相当于0.75n
sc = n - (n >>> 2);
}
} finally {
// sizeCtl代表了阈值,类似threshold
sizeCtl = sc;
}
break;
}
}
return tab;
}
总结
本文从整体上对ConcurrentHashMap进行了介绍,其中常量和变量以及其中重要的内部类都进行了相关的解释说明,当然,限于篇幅以及复杂度暂未涉及方法的源码部分,下一篇将结合本文的相关知识重点说明其中涉及的方法,在看本文时请完全理解HashMap的源码,将会事半功倍,毕竟结构上和HashMap非常相似
ConcurrentHashMap从HashMap的基础上进行演变,适应多线程并发情况下的操作,理解下列几点:
- 初始化数组,单线程创建
- 扩容时,多线程可帮助扩容(下一章将详细说明)
- hash桶头节点有4种类型,ForwardingNode节点表明当前hash桶正在扩容移动中,TreeBin节点表明为红黑树结构,ReservationNode节点暂不多说,还有就是正常链表节点
- 遍历操作通过一个特殊的内部类Traverser实现
- CAS操作大大增加了并发执行的效率
水平有限,如有错误,请及时指出,谢谢!
JDK源码那些事儿之并发ConcurrentHashMap上篇的更多相关文章
- JDK源码那些事儿之并发ConcurrentHashMap下篇
上一篇文章已经就ConcurrentHashMap进行了部分说明,介绍了其中涉及的常量和变量的含义,有些部分需要结合方法源码来理解,今天这篇文章就继续讲解并发ConcurrentHashMap 前言 ...
- JDK源码那些事儿之浅析Thread上篇
JAVA中多线程的操作对于初学者而言是比较难理解的,其实联想到底层操作系统时我们可能会稍微明白些,对于程序而言最终都是硬件上运行二进制指令,然而,这些又太过底层,今天来看一下JAVA中的线程,浅析JD ...
- 从JDK源码角度看java并发的公平性
JAVA为简化开发者开发提供了很多并发的工具,包括各种同步器,有了JDK我们只要学会简单使用类API即可.但这并不意味着不需要探索其具体的实现机制,本文从JDK源码角度简单讲讲并发时线程竞争的公平性. ...
- 从JDK源码角度看java并发的原子性如何保证
JDK源码中,在研究AQS框架时,会发现很多地方都使用了CAS操作,在并发实现中CAS操作必须具备原子性,而且是硬件级别的原子性,java被隔离在硬件之上,明显力不从心,这时为了能直接操作操作系统层面 ...
- JDK源码那些事儿之红黑树基础下篇
说到HashMap,就一定要说到红黑树,红黑树作为一种自平衡二叉查找树,是一种用途较广的数据结构,在jdk1.8中使用红黑树提升HashMap的性能,今天就来说一说红黑树,上一讲已经给出插入平衡的调整 ...
- JDK源码分析(6)ConcurrentHashMap
JDK版本 ConcurrentHashMap源码分析 table:默认为null,初始化发生在第一次插入操作,默认大小为16的数组,用来存储Node节点数据,扩容时大小总是2的幂次方. nextTa ...
- JDK源码那些事儿之我眼中的HashMap
源码部分从HashMap说起是因为笔者看了很多遍这个类的源码部分,同时感觉网上很多都是粗略的介绍,有些可能还不正确,最后只能自己看源码来验证理解,写下这篇文章一方面是为了促使自己能深入,另一方面也是给 ...
- JDK源码那些事儿之LinkedBlockingDeque
阻塞队列中目前还剩下一个比较特殊的队列实现,相比较前面讲解过的队列,本文中要讲的LinkedBlockingDeque比较容易理解了,但是与之前讲解过的阻塞队列又有些不同,从命名上你应该能看出一些端倪 ...
- JDK源码那些事儿之LinkedTransferQueue
在JDK8的阻塞队列实现中还有两个未进行说明,今天继续对其中的一个阻塞队列LinkedTransferQueue进行源码分析,如果之前的队列分析已经让你对阻塞队列有了一定的了解,相信本文要讲解的Lin ...
随机推荐
- MangoDB
<MongoDB权威指南> 一.简介 MongoDB是一款强大.灵活.且易于扩展的通用型数据库 1.易用性 MongoDB是一个面向文档(document-oriented)的数据库,而不 ...
- C++用于类型转换的4个操作符
Dynamic_cast, const_cast, static_cast, reinterpret_cast. (1)reinterpret_cast 用于基本的类型转换.如 in *ip; ...
- python线程障碍对象Barrier(34)
python线程Barrier俗称障碍对象,也称栅栏,也叫屏障. 一.线程障碍对象Barrier简介 # 导入线程模块 import threading # 障碍对象barrier barrier = ...
- java学习笔记(7)--链表
标签(空格分隔):笔记 java其实已经将很多底层的数据结构进行了封装,虽然工作用不到,但是笔试和面试问的还是比较频繁的,而且这种面试题还是直接手撕代码,故专门总结一下. 1. 概念 1.1 链表(L ...
- [PDF] - 获取 RadioButtonList 控件值的方法
背景 目标是通过 iTextSharp 读取 PDF 模板,填充内容后以生成新 PDF 文件.利用 福昕PDF编辑器个人版 可以获取到 RadioButtonList 的组名,但是获取不到每一个 Ra ...
- Jenkins+maven+gitlab自动化部署之docker发布sprint boot项目(七)
Jenkins发布docker应用与发布java应用配置基本一致,需要配置Dockerfile及构建的步骤,步骤如下: 1.jenkins主机构建应用为jar包 2.jenkins主机把生产的jar包 ...
- CTeX 更改字体(软件)
CTeX默认显示字体太小了,写起来看着费眼睛.有没有办法更改字体呢? 更改字体方法:(图片是默认字体) 未完 ...... 点击访问原文(进入后根据右侧标签,快速定位到本文) </b
- Python06之分支和循环1(三目运算符)
Python 为了使得程序更加简洁而新引入过来的一个三目操作符,顾名思义就是有三个参数. 格式: x if 条件表达式 else y 先判断条件表达式真假,真则取 x 的值,否则取 y 的值. 例如: ...
- 字符串char vchar性能对比补充
Value CHAR(4) Storage Required VARCHAR(4) Storage Required '' ' ' 4 bytes '' 1 byte 'ab' 'ab ' 4 ...
- python 的django项目复制方法
python 的django项目复制方法 django_pyecharts_1修改为django_pyecharts_1_cs1.拷贝项目(确保原有项目是关闭状态下)2.粘贴项目并删除idea文件夹和 ...