Python2下载单张图片和爬取网页图片
一、需求分析
1、知道图片的url地址,将图片下载到本地。
2、知道网页地址,将图片列表中的图片全部下载到本地。
二、准备工作
1、开发系统:win7 64位。
2、开发环境:python2.7。
3、开发工具:PyCharm。
4、浏览器:Chrome。
三、操作步骤
A.知道图片的url地址,将图片下载到本地。
a1、打开Chrome,随意找到一个图片网站。
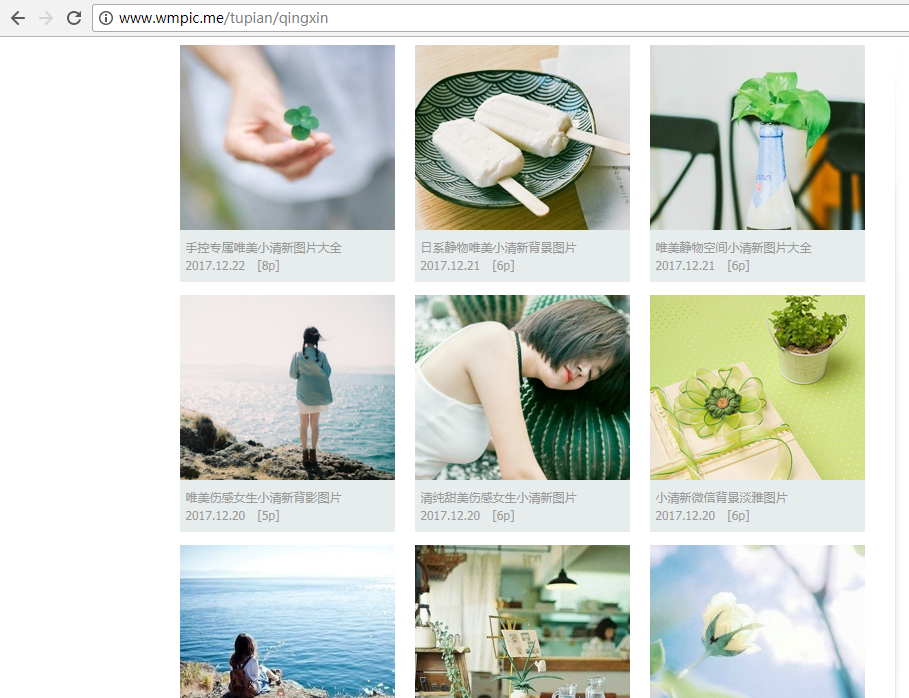
a2、打开开发者工具(f12键或者fn+f12键),选择第一张图片,可以看到它的src属性就是图片的地址,复制出来。
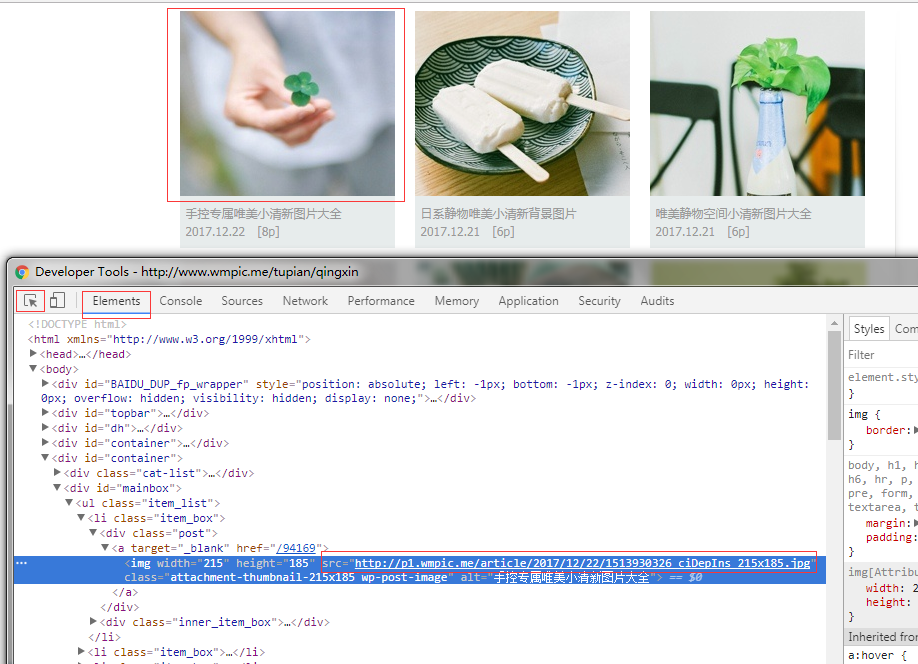
a3、编写代码。这里需要引用urllib库以及使用Python IO相关的知识。
# -*- coding:utf-8 -*
'''
知道图片地址,下载图片到本地
'''
import urllib #图片url地址
url = 'http://p1.wmpic.me/article/2017/12/22/1513930326_ciDepIns_215x185.jpg'
#方法一
#获取图片数据
res = urllib.urlopen(url).read()
#文件要保存的路径名和文件名
path = "e:\dlimg\pic2.jpg"
#使用io写入图片
f = open(path , "wb")
f.write(res)
f.close()
#方法二
res2 = urllib.urlretrieve(url , 'e:\dlimg\pic3.jpg')
B.知道网页地址,将图片列表中的图片全部下载到本地。
b1、还是以上面的网页为爬取对象,在该网页下,图片列表中有30张照片,获取每张图片的src属性值,再来下载即可。
b2、利用BeautifulSoup解析网页,利用标签选择器获取每张图片的src属性值。
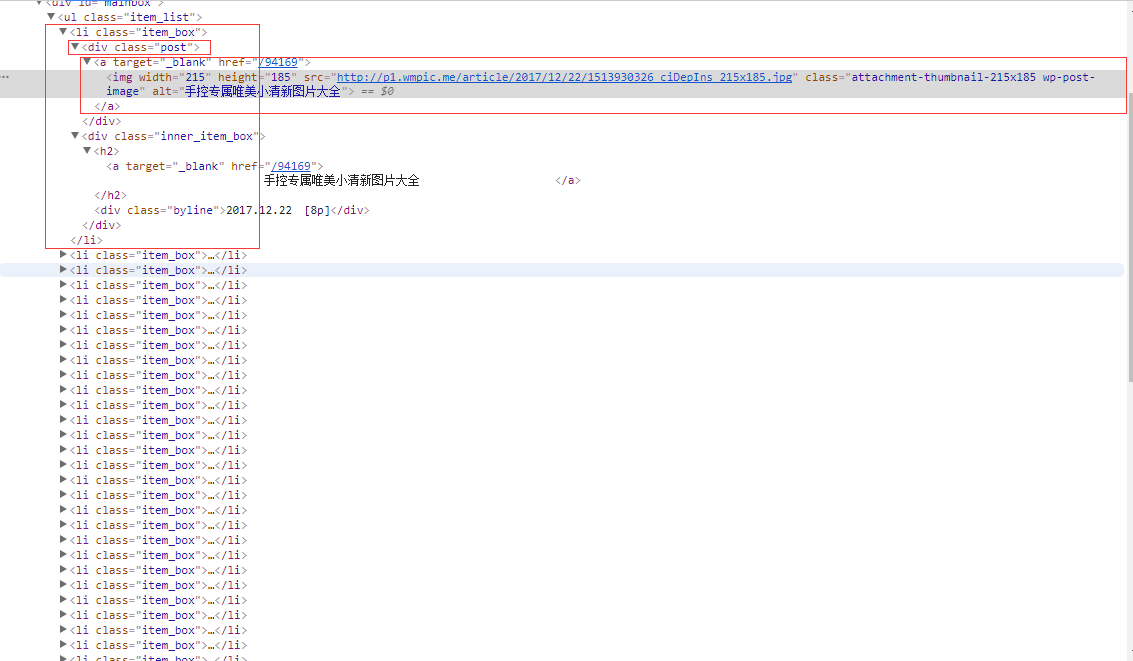
b3、编写代码。
# -*- coding: utf-8 -*- import requests
import urllib
from bs4 import BeautifulSoup url = 'http://www.wmpic.me/tupian/qingxin'
res = requests.get(url)
#使用BeautifulSoup解析网页
soup = BeautifulSoup(res.text , 'html.parser')
#通过标签选择器定位到图片位置(与css选择器差不多)
pic_list = soup.select('.item_box .post a img')
i = 0
for img_url in pic_list:
#获取每个img标签的src属性
url_list = img_url['src']
#保存路径,后面是文件名
save_path = 'E:\dlimg\\'+'downloadpic_'+str(i)+'.jpg'
#解析图片,写入到本地
pic_file = urllib.urlopen(url_list).read()
f = open(save_path, "wb")
f.write(pic_file)
f.close()
i = i+1
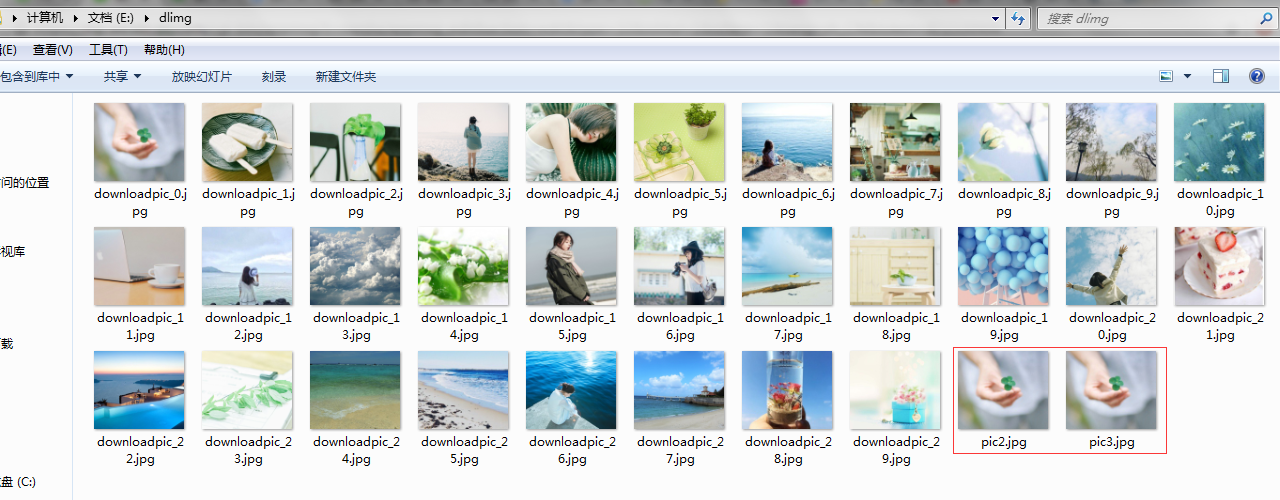
C.运行结果(红色框中pic2.jpg和pic3.jpg是A步骤运行结果,其余以downloadpic_*.jpg命名的图片是步骤B的运行结果)
文章首发于我的个人公众号:悦乐书。喜欢分享一路上听过的歌,看过的电影,读过的书,敲过的代码,深夜的沉思。期待你的关注!

Python2下载单张图片和爬取网页图片的更多相关文章
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- erlang 爬虫——爬取网页图片
说起爬虫,大家第一印象就是想到了python来做爬虫.其实,服务端语言好些都可以来实现这个东东. 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌 ...
- python爬取网页图片(二)
从一个网页爬取图片已经解决,现在想要把这个用户发的图片全部爬取. 首先:先找到这个用户的发帖页面: http://www.acfun.cn/u/1094623.aspx#page=1 然后从这个页面中 ...
- 利用Python爬取网页图片
最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片 ...
- Python3批量爬取网页图片
所谓爬取其实就是获取链接的内容保存到本地.所以爬之前需要先知道要爬的链接是什么. 要爬取的页面是这个:http://findicons.com/pack/2787/beautiful_flat_ico ...
- Python多线程爬虫爬取网页图片
临近期末考试,但是根本不想复习!啊啊啊啊啊啊啊!!!! 于是做了一个爬虫,网址为 https://yande.re,网页图片为动漫美图(图片带点颜色........宅男福利 github项目地址为:h ...
- Python学习--两种方法爬取网页图片(requests/urllib)
实际上,简单的图片爬虫就三个步骤: 获取网页代码 使用正则表达式,寻找图片链接 下载图片链接资源到电脑 下面以博客园为例子,不同的网站可能需要更改正则表达式形式. requests版本: import ...
随机推荐
- c#中获取路径方法
要在c#中获取路径有好多方法,一般常用的有以下五种: //获取应用程序的当前工作目录. String path1 = System.IO.Directory.GetCurrentDirectory() ...
- HtmlImageGenerator乱码问题解决、html2image放linux上乱码问题解决
使用html2image-0.9.jar生成图片. 在本地window系统正常,放到服务器linux系统时候中文乱码问题.英文可以,中文乱码应该就是字体问题了. 一.首先需要在linux安装字体,si ...
- 自动化部署必备技能—部署yum仓库、定制rpm包
部署yum仓库.定制rpm包 目录 第1章 扩展 - yum缓存 1.1 yum缓存使用步骤... 1 1.1.1 导言... 1 1.1.2 修改配置文件... 1 1.1.3 使用缓存... 1 ...
- Python的路径引用
1.以HOME目录为准,进行跳转 sys.path.append(os.path.dirname(__file__) + os.sep + '../') from config import swor ...
- Oracle单行函数基础运用
单行函数 整个SQL的精髓:select语句+单行函数(背) 字符串函数 常用的处理字符串的函数有如下: No. 函数名 含义 1 UPPER(c1) upper 将字符串全部转为大写 2 LOWE ...
- maven学习之二
三 profile介绍 可以有多个地方定义profile.定义的地方不同,它的作用范围也不同. (1) 针对于特定项目的profile配置我们可以定义在该项目的pom.xml中. (2) ...
- javaweb-3-在Eclipse中引入Tomcat
一.在Eclipse中引入Tomcat 第一步: 第二步: 第三步: 第四部:
- mac 安装protobuf,并编译
因公司接口协议是PB文件,需要将 PB 编译成JAVA文件,且MAC 电脑,故整理并分享MAC安装 google 下的protobuf 文件 MAC 安装protobuf 流程 1.下载 http ...
- Luogu P1073 最优贸易
题目描述 C 国有 n 个大城市和 m 条道路,每条道路连接这 n 个城市中的某两个城市.任意两个城市之间最多只有一条道路直接相连.这 m 条道路中有一部分为单向通行的道路,一部分为双向通行的道路,双 ...
- 如何有效的去使用一款免费的ERP
现在市场上免费的软件不少,怎么样去使用一款免费产品是很多人比较头疼的事情. 一般使用免费ERP软件的基本都是小企业,没用过想用又舍不得花钱.如果企业有懂数据库这块儿的管理员,那都还好.如果没有,那建议 ...