python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程
在pycharm中打开此工程目录:并在Run中选择Edit Configuration
点击+创建一个Python
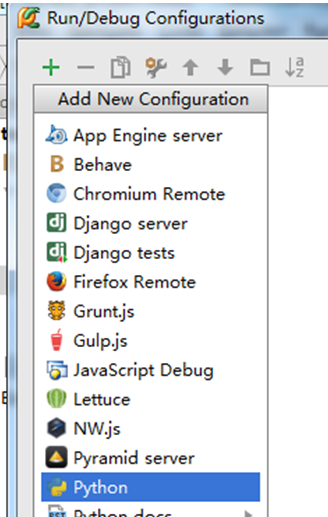
命令爬虫的名字,本例中以test_spider为例。并在script中输入安装scrapy的cmdline.py的路径。
在工程目录test1->spiders下面创建一个python文件,名字和上图中的name一致,这里都是test_spider
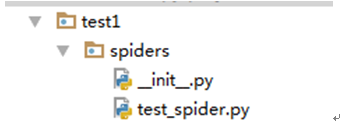
在代码中加入简单的代码:如下新建一个类名字为testSpider。注意类中必须添加name字段。这个设置爬虫工程的名称且必须和创建工程的scrapy startproject test1一样,因此这里为name=test1.
# -*- coding:UTF-8 -*- #
from scrapy.spiders import Spider
from scrapy.selector import Selector from test1.items import Test1Item
from scrapy.utils.response import open_in_browser class testSpider(Spider):
name="test1"
def parse(self, response):
pass
名字如果不一致,会出现报错:
如果改成这样:name=test2
class testSpider(Spider):
name="test2"
def parse(self, response):
pass
会产生如下错误:Spider not found: “test1”
下面来介绍下Scrapy工作原理:
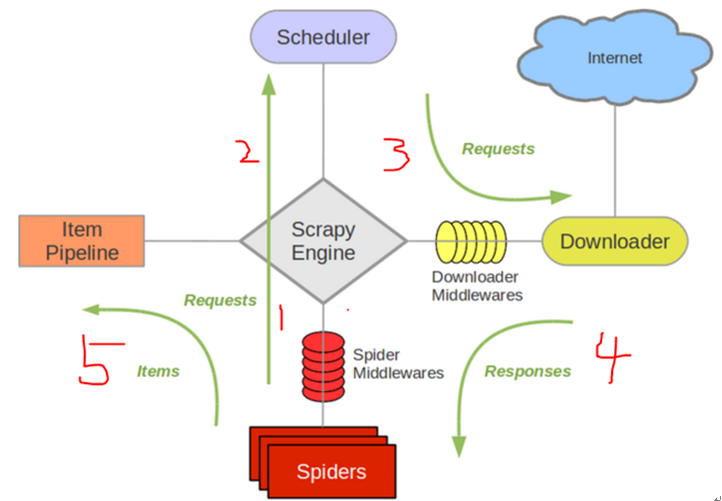
按照上面的图来说下scrapy的工作流程:
1.引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。 图中步骤1
如具体的spider函数中会定义:allowd_domains以及start_urls两个变量
allowd_domains=['http://www.xunread.com/']
start_urls=["http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/index.shtml"]
此时会将这2个变量发给引擎
2.引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。 图中步骤2
引擎获取到要爬去的URL后,进行网站链接
4.调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。 图中步骤3
5.一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。 图中步骤4
此时代码中通过sel=Selector(response)获取到下载的页面
def parse(self,response):
sel=Selector(response)
7.Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。步骤5
具体对item的处理过程在parse函数中. 并将处理的结果传入pipeline.py进行处理
8.引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。至此一个完整的一个网页调度流程结束。如果parse函数有继续返回网页,则从头开始上面的过程
9.(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
各模块的介绍如下:
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader
middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流详细过程如下:
Scrapy中的数据流由执行引擎控制,其过程如下:
1.引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。 步骤1
2.引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
3.引擎向调度器请求下一个要爬取的URL。
4.调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5.一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6.引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7.Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
8.引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
9.(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
python网络爬虫之scrapy 工程创建以及原理介绍的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- 16,Python网络爬虫之Scrapy框架(CrawlSpider)
今日概要 CrawlSpider简介 CrawlSpider使用 基于CrawlSpider爬虫文件的创建 链接提取器 规则解析器 引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话, ...
- python 网络爬虫框架scrapy使用说明
1 创建项目scrapy startproject tutorial 2 定义Itemimport scrapyclass DmozItem(scrapy.Item): title = scra ...
- python网络爬虫之scrapy 调试以及爬取网页
Shell调试: 进入项目所在目录,scrapy shell “网址” 如下例中的: scrapy shell http://www.w3school.com.cn/xml/xml_syntax.as ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
随机推荐
- Linux Shell——函数的使用
文/一介书生,一枚码农. scripts are for lazy people. 函数是存在内存里的一组代码的命名的元素.函数创建于脚本运行环境之中,并且可以执行. 函数的语法结构为: functi ...
- vue2.0 组件通信
组件通信: 子组件要想拿到父组件数据 props 子组件不允许直接给父级的数据, 赋值操作如果想更改,父组件每次穿一个对象给子组件, 对象之间引用. 例子: <script> window ...
- 使用Tomcat-redis-session-manager来实现Tomcat集群部署中的Session共享
一.工作中因为要使用到Tomcat集群部署,此时就涉及到了Session共享问题,主要有三种解决方案: 1.使用数据库来存储Session 2.使用Cookie来存储Session 3.使用Redis ...
- 转:Maven项目编译后classes文件中没有dao的xml文件以及没有resources中的配置文件的问题解决
问题1:在做spring+mybatis时,自动扫描都配置正确了,却在运行时出现了如下错误.后来查看target/classes/.../dao/文件夹下,发现只有mapper的class文件,而没有 ...
- .Net程序员学用Oracle系列(26):PLSQL 之类型、变量和结构
1.类型 1.1.属性类型 1.2.记录类型 2.变量 2.1.变量类型 2.2.变量定义 2.3.变量赋值 3.结构 3.1.顺序结构 3.2.选择结构 3.3.循环结构 4.总结 1.类型 在&l ...
- vue1.0和vue2.0的区别(二)
这篇我们继续之前的vue1.0和vue2.0的区别(一)继续说 四.循环 学过vue的同学应该知道vue1.0是不能添加重复数据的,否则它会报错,想让它重复添加也不是不可以,不过需要定义别的东西 而v ...
- int类型和byte类型的强制类型转换
今天在读<Java网络编程>这本书的第二章 流 时,看到书中有一个地方关于int强制转换为byte类型时应注意的地方.这个地方有点细节,不过就应该把这种细节把握住. 情况是这样的,讲到In ...
- python 爬取淘宝的模特照片
前段时间花了一部分时间学习下正则表达式,总觉得利用正则要做点什么事情,所以想通过爬取页面的方式把一些美女的照片保存下来,其实过程很简单. 1.首先读取页面信息: 2.过滤出来照片的url地址: 3.通 ...
- Spring框架学习1
AnonymouL 兴之所至,心之所安;尽其在我,顺其自然 新随笔 管理 Spring框架学习(一) 阅读目录 一. spring概述 核心容器: Spring 上下文: Spring AOP ...
- dbunit进行DAO层Excel单元测试
DAO层测试难点 可重复性,每次运行单元测试,得到的数据是重复的 独立性,测试数据与实际数据相互独立 数据库中脏数据预处理 不能给数据库中数据带来变化 DAO层测试方法 使用内存数据库,如H2.优点: ...