[Machine Learning]学习笔记-Neural Networks
引子
对于一个特征数比较大的非线性分类问题,如果采用先前的回归算法,需要很多相关量和高阶量作为输入,算法的时间复杂度就会很大,还有可能会产生过拟合问题,如下图:

这时就可以选择采用神经网络算法。
神经网络算法最早是人们希望模仿大脑的学习功能而想出来的。

一个神经元,有多个树突(Dendrite)作为信息的输入通道,也有多个轴突(Axon)作为信息的输出通道。一个神经元的输出可以作为另一个神经元的输入。神经元的概念和多分类问题的分类器概念很相近,都是可以接收多个输入,在不同的权值(weights)下产生出多个不同的输出。
模型表示

模型可以写成如下形式:
\[
\begin{bmatrix}x_0 \newline x_1 \newline x_2 \newline \end{bmatrix}\rightarrow\begin{bmatrix}\ \ \ \newline \end{bmatrix}\rightarrow h_\theta(x)
\]
上图可以称为单隐层前馈网络,由输入层\(X\),输出层和它们之间的隐含层构成。
每个输出层都有一个权重矩阵(weights matrix)和一个偏置单元(bias unit),用来计算输出。
前向传播
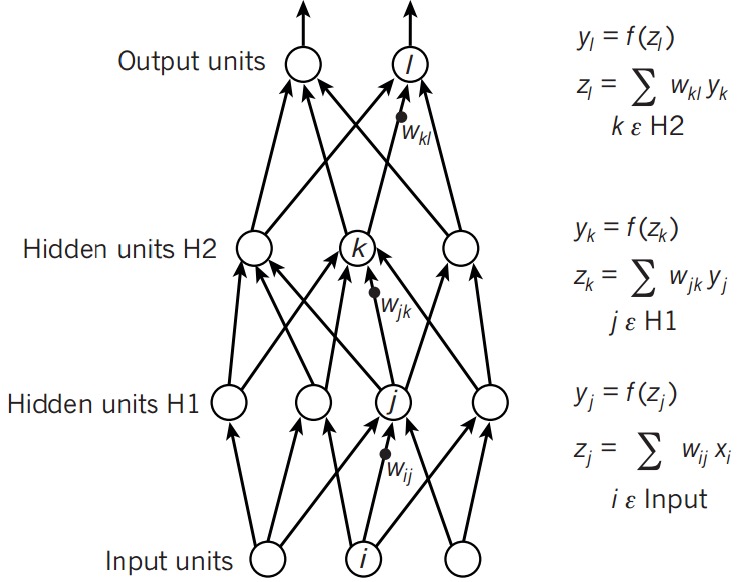
首先回顾一下Logistic Regression的单分类问题中\(h_\theta\)的计算:
\[\begin{align*}\begin{bmatrix}x_0 \newline x_1 \newline x_2\end{bmatrix} \rightarrow\begin{bmatrix}g(z^{(2)})\end{bmatrix} \rightarrow h_\Theta(x)\end{align*}\]
可以写为:
\[z^{(2)}=\omega^{(2)}a^{(1)}+b^{(2)}\\\
a^{(2)}=g(z^{(2)})\\\
h_\theta(x)=a^{(2)}
\]
而神经网络的前向传播,也就是在此基础上增加了层数,让一层的输出作为下一层的输入:
\[z^{(i)}=\omega^{(i)}a^{(i-1)}+b^{(i)}\\\
a^{(i)}=g(z^{(i)})\\\
z^{(i+1)}=\omega^{(i+1)}a^{(i)}+b^{(i+1)}\\\
...
\]
需要注意的是,每一层有多个单元,所以这里面的权重也是个二维矩阵。
反向传播(Backpropagation)
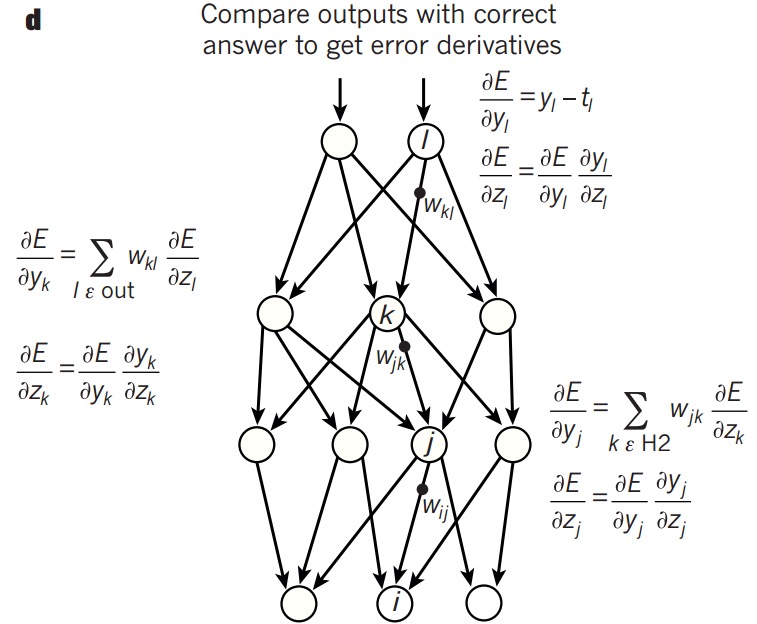
直观理解
但给予初始的偏置单元和权重矩阵后,预测值会不太理想。
那么,如何使预测值符合真实值呢?
\[z^{(i)}=\omega^{(i-1)}a^{(i-1)}+b^{(i-1)}\]
可以发现,可以通过改变每一层的\(a,\omega,b\)来改变最终的输出,但实际上\(a\)是不能直接改变的。
所以本质上要做的就是改变\(\omega\)和\(b\)来使预测值接近真实值。
思路和之前的logistic regression和线性回归模型一样,也是先构建代价函数,然后通过梯度下降法使代价方程的值降到最低点,也就得到了合适的\(\omega\)和\(b\)。
而使用梯度下降法时,需要计算每个\(\omega\)和\(b\)的梯度,梯度的绝对值越大,说明当前的代价函数对该参数的改变越敏感,改变这个参数使代价函数下降的越快。
微积分公式推导
以3B1B视频中的网络为例:
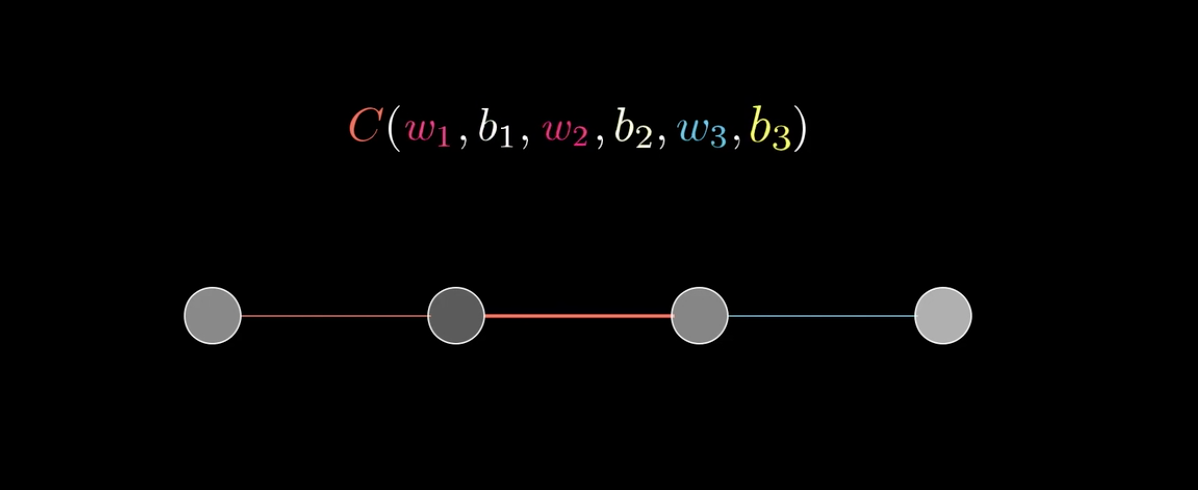
代价方程可以由最后一层的激活值\(a^{(L)}\)和真实值y的均方误差:\((a^{(L)}-y)^2\)表示。(PS:这里L=4,有些教材计算均方误差时乘上\(1/2\))
然后,我们要求解\(\omega\)和\(b\)的梯度。
在这里以\(\frac{C_0}{\partial \omega^{(L)}}\)为例:
求梯度,也就是求代价函数对参数变化的敏感度。
可以发现,改变\(\omega^{(L)}\),会先影响到\(z^{(L)}\),然后再影响到\(a^{(L)}\),最后影响\(C_0\)。
利用这个特性,可以将\(\frac{C_0}{\partial \omega^{(L)}}\)分解:
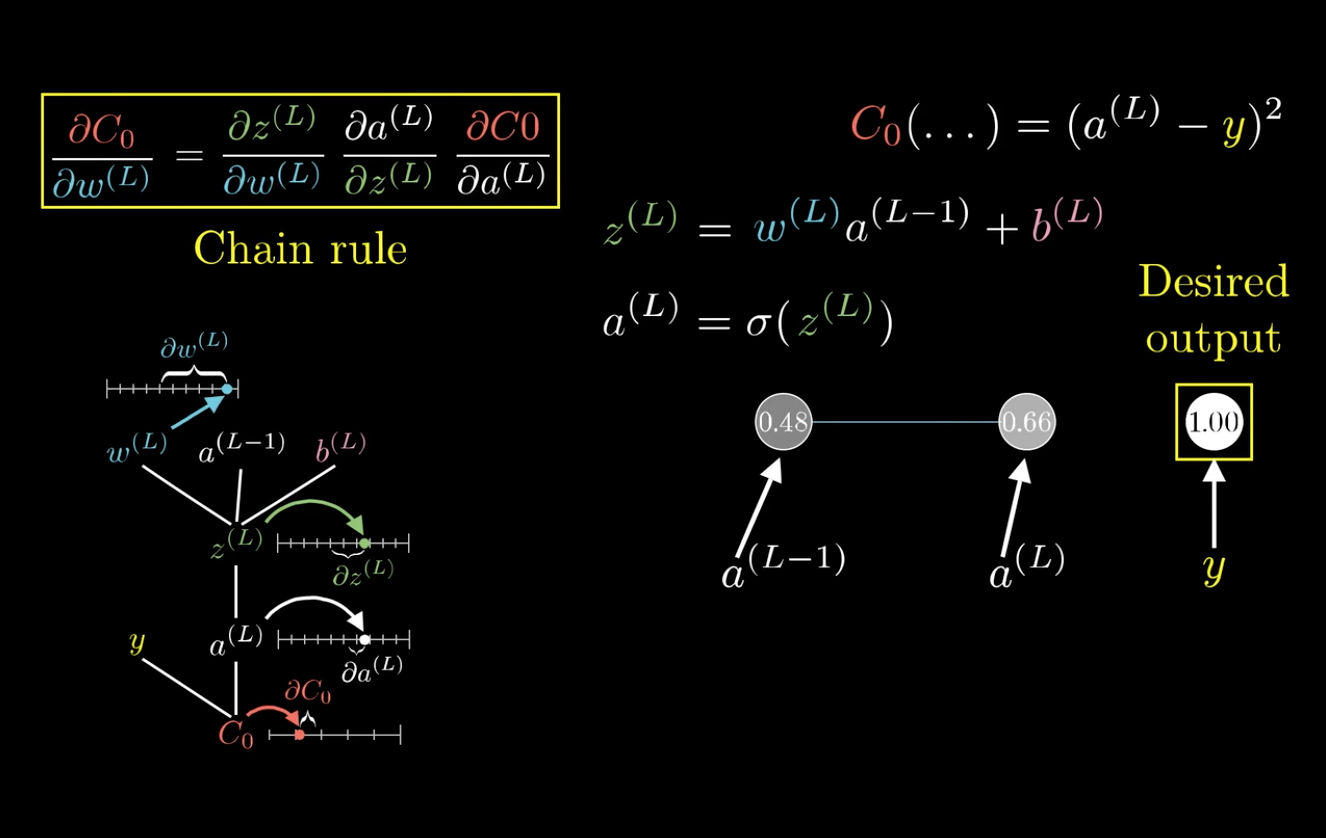
这就是所谓的链式法则(Chain rule):
\[\begin{split}
\frac{C_0}{\partial \omega^{(L)}}=&\frac{\partial z^{(L)}}{\partial \omega^{(L)}}\frac{\partial a^{(L)}}{\partial z^{(L)}}\frac{\partial C_0}{\partial a^{(L)}}\\\
=&a^{L-1}\sigma\prime(z^{(L)})2(a^{(L)}-y)
\end{split}\]
同样也可以求得\(b^{(L)}\)的梯度:
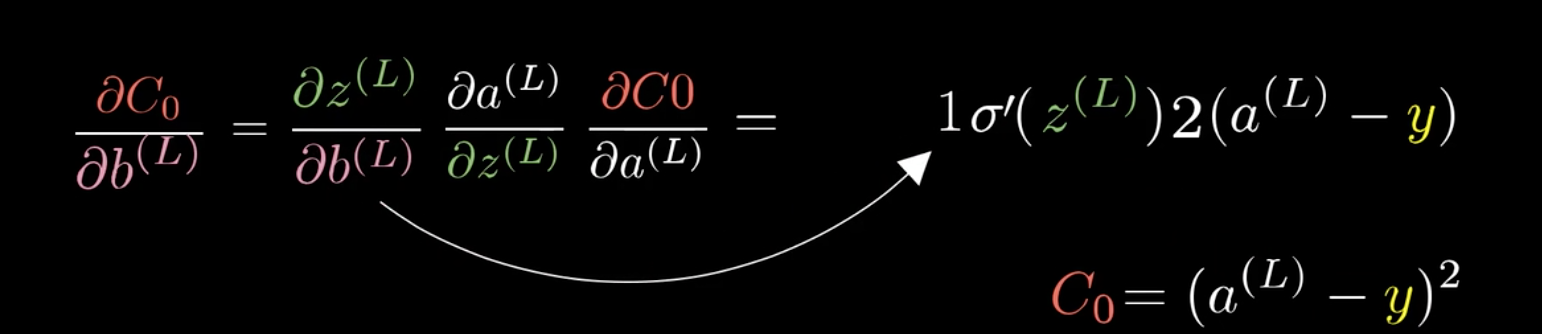
以上的网络每层只有一个神经元,如果有多个单元的话,以上的公式也是成立的。
之前提过,权重矩阵是二维的,可以给两个下标\(j,k\)表示\(\omega\):
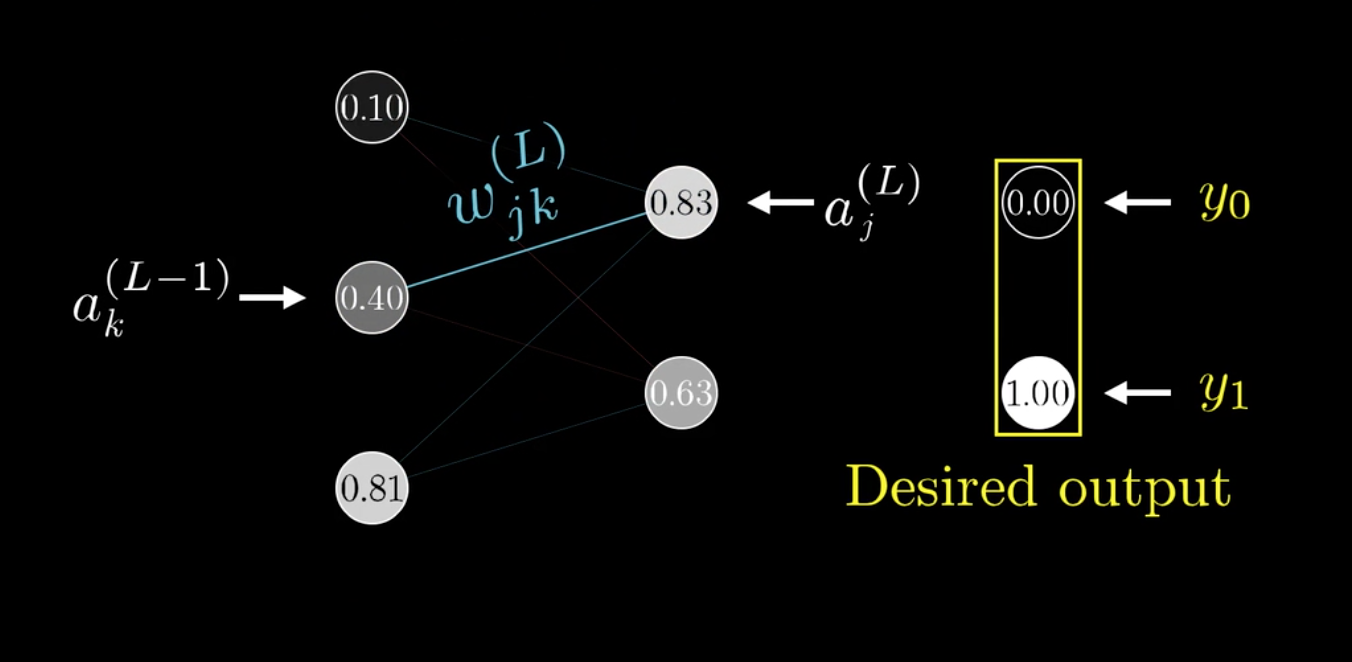
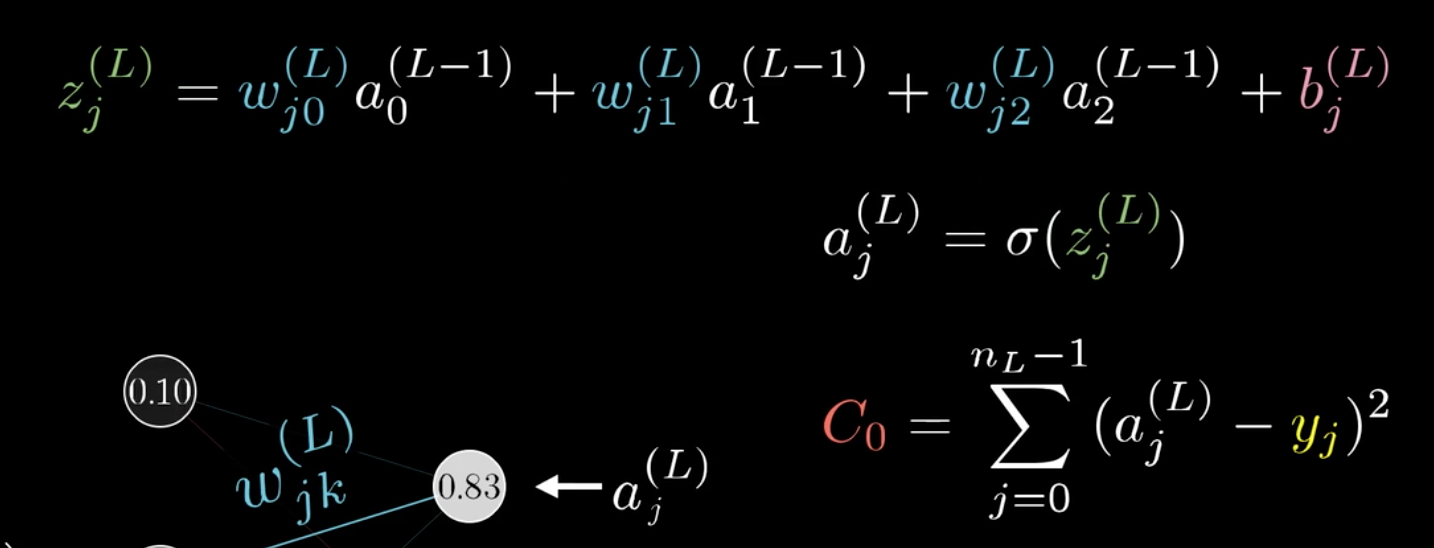
链式法则更新如下:
\[
\begin{split}\frac{C_0}{\partial \omega_{jk}^{(L)}}&= \frac{\partial z_j^{(L)}}{\partial \omega_{jk}^{(L)}}\frac{\partial a_j^{(L)}}{\partial z_j^{(L)}}\frac{\partial C_0}{\partial a_j^{(L)}}\\
&=a^{L-1}_k \sigma\prime(z^{(L)}_j)2(a^{(L)}_j-y_j)
\end{split}\]
而要把这个公式递推到其它层求\(\frac{C}{\partial \omega_{jk}^{(l)}}\)时,只需要变动公式中的\(\frac{\partial C}{\partial a_j^{(l)}}\)即可。
总结如下:
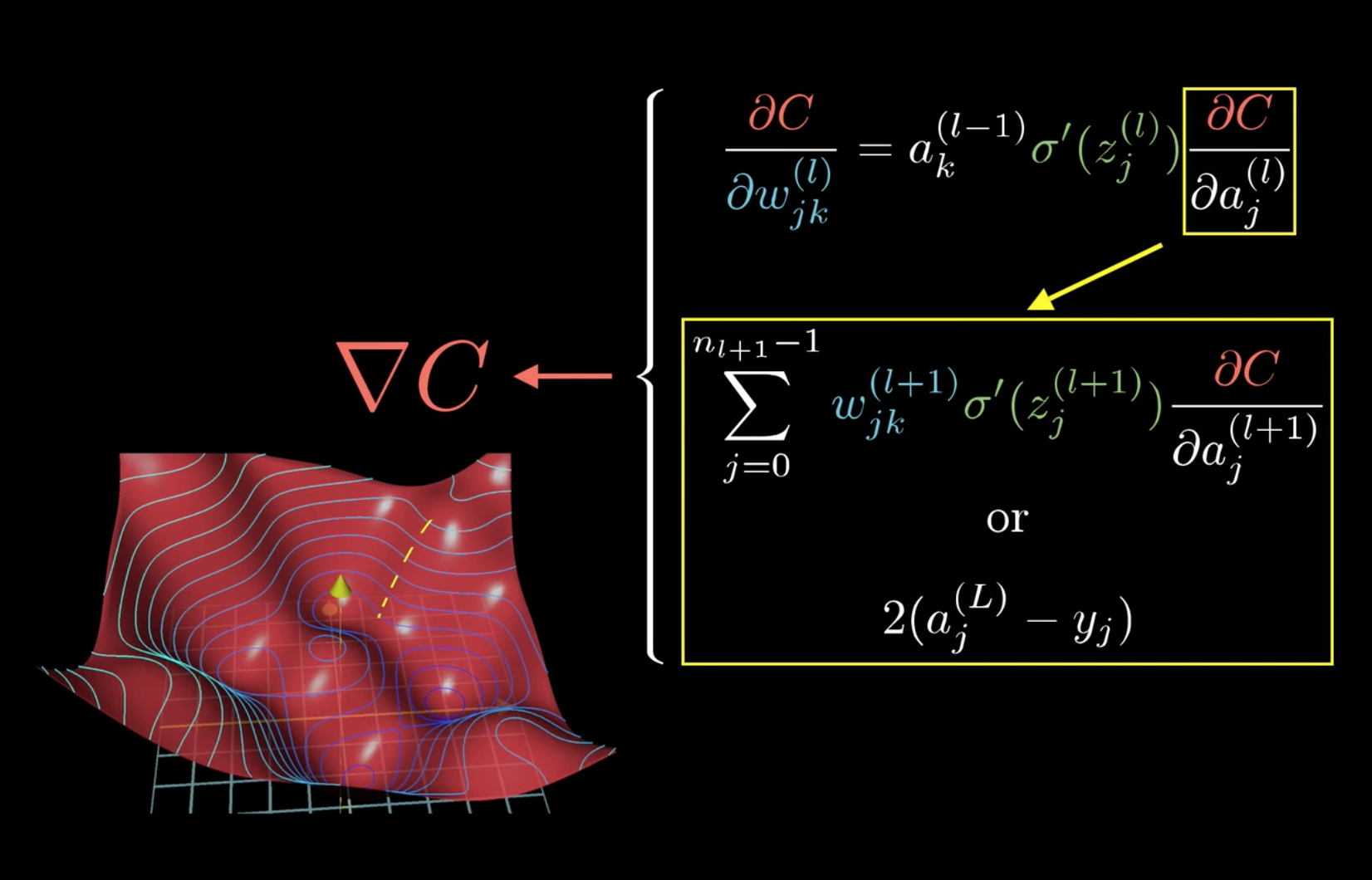
所以,可以发现,计算梯度时,前两项\(a^{l-1}_k ,\sigma\prime(z^{(l)}_j)\)是可以直接算出的,而最后一项,则可以先计算出\(\frac{\partial C0}{\partial a_j^{(L)}}\),然后一层层向前传播即可,反向传播大概也就是这么个意思吧。
Andrew机器学习课程中给出了计算方法,也可以按这个思路去理解了。

TIPS:随机梯度下降法(Stochastic gradient descent)
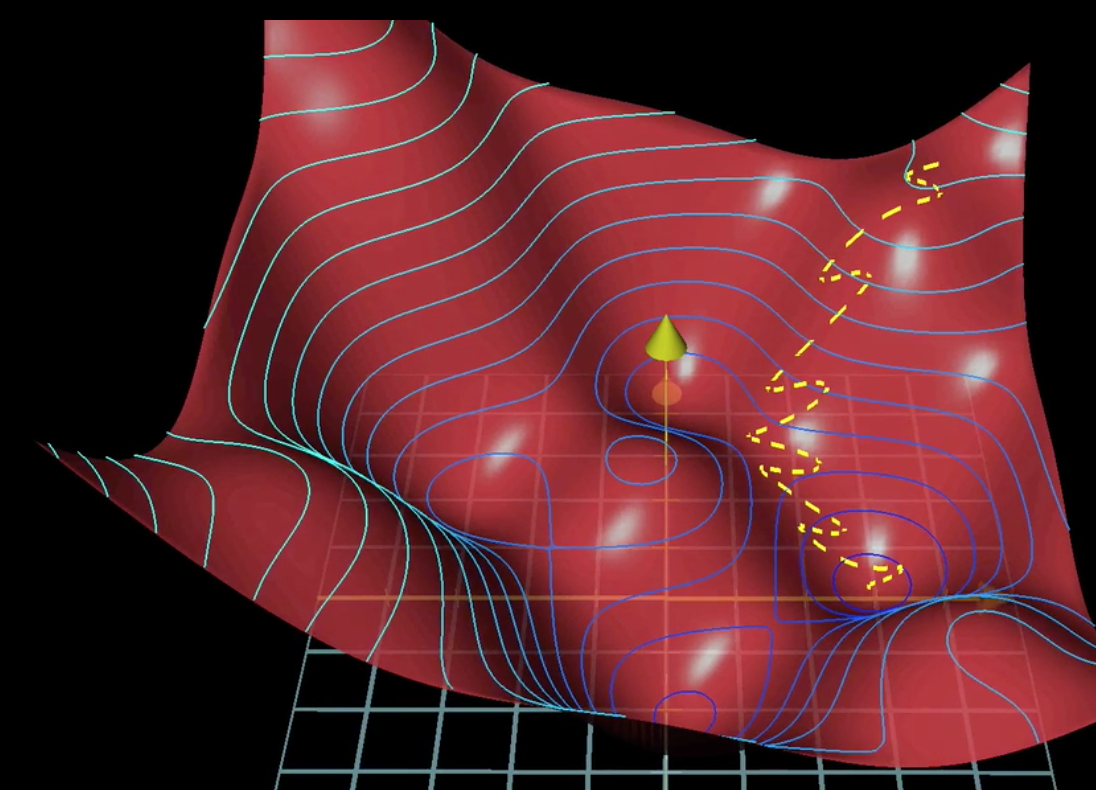
在之前的batch model中,每次更新权值都要遍历所有的样本然后取均值,这样效率太低,可以把样本分成数个大小相等的mini-batch,每次遍历完一个mini-batch,就更新下权值,虽然下降的路线未必最短,但速度上提升不少,这就是随机梯度下降算法。
[Machine Learning]学习笔记-Neural Networks的更多相关文章
- [Machine Learning]学习笔记-Logistic Regression
[Machine Learning]学习笔记-Logistic Regression 模型-二分类任务 Logistic regression,亦称logtic regression,翻译为" ...
- Machine Learning 学习笔记
点击标题可转到相关博客. 博客专栏:机器学习 PDF 文档下载地址:Machine Learning 学习笔记 机器学习 scikit-learn 图谱 人脸表情识别常用的几个数据库 机器学习 F1- ...
- Machine Learning 学习笔记1 - 基本概念以及各分类
What is machine learning? 并没有广泛认可的定义来准确定义机器学习.以下定义均为译文,若以后有时间,将补充原英文...... 定义1.来自Arthur Samuel(上世纪50 ...
- [Python & Machine Learning] 学习笔记之scikit-learn机器学习库
1. scikit-learn介绍 scikit-learn是Python的一个开源机器学习模块,它建立在NumPy,SciPy和matplotlib模块之上.值得一提的是,scikit-learn最 ...
- Coursera 机器学习 第6章(上) Advice for Applying Machine Learning 学习笔记
这章的内容对于设计分析假设性能有很大的帮助,如果运用的好,将会节省实验者大量时间. Machine Learning System Design6.1 Evaluating a Learning Al ...
- machine learning学习笔记
看到Max Welling教授主页上有不少学习notes,收藏一下吧,其最近出版了一本书呢还,还没看过. http://www.ics.uci.edu/~welling/classnotes/clas ...
- [Machine Learning]学习笔记-线性回归
模型 假定有i组输入输出数据.输入变量可以用\(x^i\)表示,输出变量可以用\(y^i\)表示,一对\(\{x^i,y^i\}\)名为训练样本(training example),它们的集合则名为训 ...
- 吴恩达Machine Learning学习笔记(一)
机器学习的定义 A computer program is said to learn from experience E with respect to some class of tasks T ...
- Machine Learning 学习笔记 01 Typora、配置OSS、导论
Typora 安装与使用. Typora插件. OSS图床配置. 机器学习导论. 机器学习的基本思路. 机器学习实操的7个步骤
随机推荐
- 根据选中不同的图元来显示不同的属性面板changePropertyPane.html
在现实生活中,我们有很多时候需要根据选中不同的东西来获取不同的属性,并且就算是同类型的东西我们有时也希望显示不同的属性,就像每个人都有不同的个性,可能会有相同点,但是不可能完全相同. 根据这个思想,我 ...
- 【转】open参数O_DIRECT的学习
open参数O_DIRECT的学习 使用 O_DIRECT 需要注意的地方 posix_memalign详细解释 free:这里好几个方法我都没测试成功,最后还是用posix_memalign 对齐的 ...
- java加密解密
java加密解密 public class MD5Util { /** * @param args */ public static void main(String[] args) { System ...
- aapt不是内部命令
解决方法:在E:\sdk\build-tools\目录下的任意文件夹下查找aapt,复制到E:\sdk\platform-tools,具体盘符是情况而定,如果还不行,尝试配置环境变量!
- 微信小程序图片放大预览
需求:当点击图片时,当前图片放大预览,且可以左右滑动 实现方式:使用微信小程序图片预览接口 我们可以看到api需要两个参数,分别通过下面的data-list和data-src来传到js中 wxml代码 ...
- ubuntu 常用命令集
一.安装的时候,让你输入代替root用户的名称与密码 使用sudo root切换root的时候会要求你输入密码,这时候你输入什么都不对的 要想使用的哈,需要给root设置密码,命令如下: sudo p ...
- rwx对于文件和目录的意义
1.对于文件 r:可读. w:可以编辑,可以修改. x:可以执行.在windows中,可执行指的是.exe,.bat等这些后缀结尾的文件,在linux没有这种限制. 2.对于目录 r:表示可以用ls命 ...
- SQLServer2008数据库安装图解
SQLServer2008数据库安装图解... ======================================= 解压下载的安装包,右键运行Setup.exe文件 =========== ...
- Python把给定的列表转化成二叉树
在LeetCode上做题时,有很多二叉树相关题目的测试数据是用列表给出的,提交的时候有时会出现一些数据通不过,这就需要在本地调试,因此需要使用列表来构建二叉树,方便自己调试.LeetCode上二叉树结 ...
- 【Kafka源码】KafkaConsumer
[TOC] KafkaConsumer是从kafka集群消费消息的客户端.这是kafka的高级消费者,而SimpleConsumer是kafka的低级消费者.何为高级?何为低级? 我们所谓的高级,就是 ...