使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布
使用sklearn进行数据挖掘系列文章:
- 1.使用sklearn进行数据挖掘-房价预测(1)
- 2.使用sklearn进行数据挖掘-房价预测(2)—划分测试集
- 3.使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布
- 4.使用sklearn进行数据挖掘-房价预测(4)—数据预处理
- 5.使用sklearn进行数据挖掘-房价预测(5)—训练模型
- 6.使用sklearn进行数据挖掘-房价预测(6)—模型调优
可视化数据###
目前我们只是大概了解了数据的类型,以及对数据集进行了划分,下面我们要对数据进行更深一步的探索,以下的操作只在训练集上面进行,由于该数据集比较的小,我们就直接在数据集上面进行操作,为了防止数据集被修改,我们先复制一份。
housing = strat_train_set.copy()
这个数据集提供经纬度这些地理位置信息,那么我们可以根据这些信息将数据分布绘制出来

看着像什么?你没有猜错,这就是加利福尼亚州的形状,这个图形看着有点稠密,可以通过设置alpha来设置图形的显示。
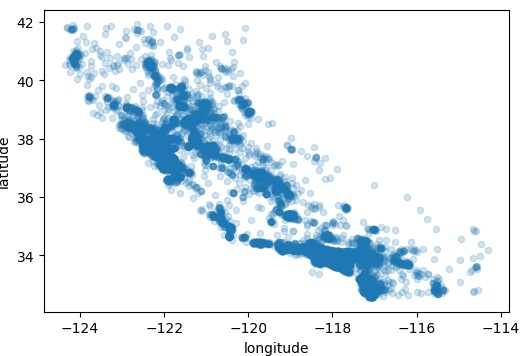
我们对图像敏感,但要发现图像中的某些规律还是需要我们调节一下参数的,现在我们就能清楚的从图中看到稠密的地区了,接下来我们将房价、人口也加入图中,
import matplotlib.pyplot as plt
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population", figsize=(10,7),
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
sharex=False)
plt.legend()
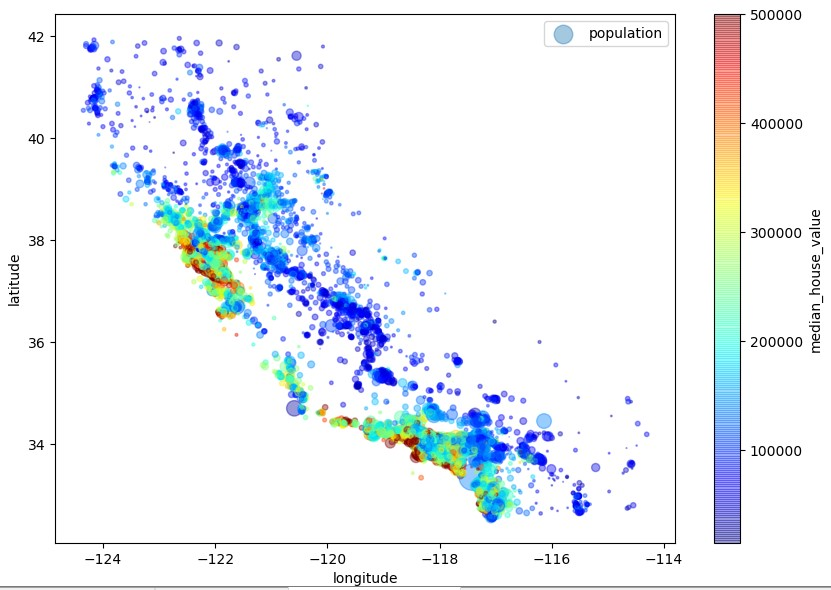
图中的小圆圈是代表该区域的人口由参数s控制,颜色代表该区域的房价由参数c控制。
从上面的图中可以得出一些规律:房价不仅与地理位置有关,还和人口稠密度有关,这些也都是一些常识。
相关性
下面我们看一看各个特征与median_house_value这一特征的相关性,使用的是皮尔逊相关系数Pearson
corr_matrix = housing.corr()
>>print corr_matrix['median_house_value'].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.687160
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population -0.026920
longitude -0.047432
latitude -0.142724
Name: median_house_value, dtype: float64
相关系数的取值范围为[-1,1],当值趋近1时,表示特征之间具有强的正相关性,反之为负相关。值趋近于0表示特征之间不存在线性关系。值得注意的是,这里说的相关性只针对线性相关。如果为非线性关系则该衡量标准失效,如下图最后一行,它们的相关系数为0,显然他们是存在某种关系的。第二行的相关性都为1或-1说明了相关性与斜率无关。

上面是通过计算相关系数矩阵找出特征之间的相关性,还有一种方法是通过绘制特征之间分布,pandas提供了scatter_matrix方法,顾名思义就是使用散点图形式绘制出特征与特征之间的关系。取出相关系数排名前四的特征作为我们需要绘制的属性,会得到一个4*4个图像,代码如下:
from pandas.tools.plotting import scatter_matrix
attribute = ['median_house_value','median_income','total_rooms','housing_median_age']
scatter_matrix(housing[attribute],figsize=(10,6))

特征的组合###
前面介绍了通过可视化数据的方法来从发现潜在的规律,我们发现了特征之间的关系、还发现了一些特征有着长尾分布,以上发现的这些规律有助于我们对特征进行选择,或者对数据进行转化(如取log)等等,还有一个步骤我们可以尝试使用,那就是特征组合。在这里本文使用了总房间数、家庭人数以及人口数这三个特征的组合。
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
corr_matrix = housing.corr()
print corr_matrix["median_house_value"].sort_values(ascending=False)
相关系数结果:
median_house_value 1.000000
median_income 0.687160
rooms_per_household 0.146285 //
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population_per_household -0.021985//
population -0.026920
longitude -0.047432
latitude -0.142724
bedrooms_per_room -0.259984//
从上面结果可以看出bedrooms_per_room较total_bedrooms 有着更高的相关性,bedrooms/rooms比越小的房价越高,从rooms_per_household可以看出,房子越大房价越贵。
使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布的更多相关文章
- 使用sklearn进行数据挖掘-房价预测(4)—数据预处理
在使用机器算法之前,我们先把数据做下预处理,先把特征和标签拆分出来 housing = strat_train_set.drop("median_house_value",axis ...
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- 使用sklearn进行数据挖掘-房价预测(1)
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(2)—划分测试集
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(5)—训练模型
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 基于sklearn的波士顿房价预测_线性回归学习笔记
> 以下内容是我在学习https://blog.csdn.net/mingxiaod/article/details/85938251 教程时遇到不懂的问题自己查询并理解的笔记,由于sklear ...
- 第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测 1. 导入boston房价数据集 2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示. 3. 多元线性回归模型,建立13个变量与房价之间的预测模 ...
- Ames房价预测特征工程
最近学人工智能,讲到了Kaggle上的一个竞赛任务,Ames房价预测.本文将描述一下数据预处理和特征工程所进行的操作,具体代码Click Me. 原始数据集共有特征81个,数值型特征38个,非数值型特 ...
- Python之机器学习-波斯顿房价预测
目录 波士顿房价预测 导入模块 获取数据 打印数据 特征选择 散点图矩阵 关联矩阵 训练模型 可视化 波士顿房价预测 导入模块 import pandas as pd import numpy as ...
随机推荐
- Vue.js2.0中的变化(持续更新中)
最近自己在学习Vue.js,在看一些课程的时候可能Vue更新太块了导致课程所讲知识和现在Vue的版本不符,从而报错,我会在以后的帖子持续更新Vue的变化与更新,大家也可以一起交流,共同监督学习! 1. ...
- 程序员节应该写博客之.NET下使用HTTP请求的正确姿势
程序员节应该写博客之.NET下使用HTTP请求的正确姿势 一.前言 去年9月份的时候我看到过外国朋友关于.NET Framework下HttpClient缺陷的分析后对HttpClient有了一定的了 ...
- Python 3 使用venv创建虚拟环境
Python 3.3以上使用venv来代替了原来Python2使用的virtualenv创建虚拟环境. 虚拟环境的作用是使得不同项目的Python包之间不会相互干扰,避免了由此产生的各种问题. 现在演 ...
- VNC 远程连接vmware下centOS7
VNC ( Virtual Network Computing)是一个linux下提供远程桌面支持的服务,类似于windows下的远程桌面服务,本来我是准备用xmanager来远程连我虚拟机中的cen ...
- lintcode 132 模式
题目要求 给你一个 n 个整数的序列 a1,a2,...,an,一个 132 模式是对于一个子串 ai,aj,ak,满足 i < j < k 和 ai < ak < aj.设计 ...
- Akka(34): Http:Unmarshalling,from Json
Unmarshalling是Akka-http内把网上可传输格式的数据转变成程序高级结构话数据的过程,比如把Json数据转换成某个自定义类型的实例.按具体流程来说就是先把Json转换成可传输格式数据如 ...
- ssh秘钥分发错误“/usr/bin/ssh-copy-id: ERROR: No identities found”
在做ssh的时候出现下面的错误,这个错误根本没有遇到过啊,仔细一看,后面的端口不对,我要发到的服务器端口是22,我想肯定是这个原因,结果不加端口,还是提示 这个错误,于是咨询下其他人,结果发现要分发的 ...
- float 浮动
浮动最开始的目的是为了让文字环绕图片(一个图片和多行文字对齐) 1.包裹性:元素添加 float 属性之后 自动变成 inline-block 元素,能设置 宽高 2.破坏性:破坏自身高度,还会使 ...
- MVC架构下,使用NPOI读取.DOCX文档中表格的内容
1.使用NPOI,可以在没有安装office的设备上读wiod.office.2.本文只能读取.docx后缀的文档.3.MVC架构中,上传文件只能使用form表单提交,转到控制器后要依次实现文件上传. ...
- 聊聊RPC及其原理
什么是RPC? RPC是Remote Procedure Call的缩写,想Client-Servier一样的远程过程调用,也就是调用远程服务就跟调用本地服务一样方便,一般用于将程序部署在不同的机器上 ...