201871030138-杨蕊媛 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
| 项目 | 内容 |
|---|---|
| 班级博客链接 | https://edu.cnblogs.com/campus/xbsf/2018CST |
| 这个作业要求链接 | https://www.cnblogs.com/nwnu-daizh/p/14604444.html |
| 我的课程学习目标 | 1.体验软件项目开发中的两人合作,练习结对编程(Pair programming) 2.掌握Github协作开发程序的操作方法 |
| 这个作业在哪些方面帮助我实现学习目标 | 1.通过阅读《现代软件工程—构建之法》相关内容,对代码风格规范、代码设计规范、代码复审以及结对编程有了一定的认识和掌握 2.通过复审结对方代码并通过github的Fork、Clone、Push、Pull request、Merge pull request等操作对其个人项目仓库的源码进行合作修改,掌握了Github协作开发程序的操作方法 3.以结对编程的方式,共同设计开发出一款D{0-1}KP 实例数据集算法实验平台,对结对编程有了更深刻的体验与理解 |
| 结对方学号-姓名 | 201871030137-杨钦颖 |
| 结对方本次博客作业链接 | https://www.cnblogs.com/YQY128/p/14655949.html |
| 本项目Github的仓库链接地址 | https://github.com/YQY128/SoftwareEngineering/tree/main/D{0-1}KP 实例数据集算法实验平台 |
任务1:
阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念
代码风格规范
代码风格的原则是:简明,易读,无二义性。
代码风格规范主要包含这些方面:缩进、行宽、括号、断行与空白的{}行、分行、命名、下划线问题、大小写问题、注释等。
代码设计规范
代码设计规范不光是程序书写的格式问题,而且牵涉到程序设计、模块之间的关系、设计模式等方方面面。
代码设计规范主要包含这些方面:函数、goto、错误处理、如何处理C++的类等。
代码复审
代码复审的定义:看代码是否在“代码规范”的框架内正确地解决了问题。
复审的形式
名 称 形 式 目 的 自我复审 自己 vs. 自己 用同伴复审的标准来要求自己。不一定最有效,因为开发者对自己总是过于自信。如果能持之以恒,则对个人有很大好处 同伴复审 复审者 vs. 开发者 简便易行 团队复审 团队 vs. 开发者 有比较严格的规定和流程,用于关键的代码,以及复审后不再更新的代码。覆盖率高——有很多双眼睛盯着程序。但是有可能效率不高(全体人员都要到会) 结对编程
在结对编程模式下,一对程序员肩并肩地、平等地、互补地进行开发工作。两个程序员并排坐在一台电脑前,面对同一个显示器,使用同一个键盘,同一个鼠标一起工作。他们一起分析,一起设计,一起写测试用例,一起编码,一起单元测试,一起集成测试,一起写文档等。
任务2:
两两自由结对,对结对方《实验二 软件工程个人项目》的项目成果进行评价
结对方博客链接
结对方Github项目仓库链接
https://github.com/YQY128/SoftwareEngineering/tree/main/折扣01背包
博客评论
从博文结构来看,排版简洁清晰,很清楚地展现了各部分的内容,对读者而言是友好的。
从博文内容来看,基本完成了项目所要求完成的任务,任务3的功能实现也比较完善,可以看出来博主是有在认真完成这项作业的。不过,博主对总结中要求的“模块化”原则这一点没有总结出来,另外,代码展示部分也缺少必要的一些注释,博主可以再完善一下。
从博文结构与PSP中“任务内容”列的关系来看,博主将大部分时间投入到具体编码以及测试中,这也的确是现阶段的我们需要花费较多时间的环节,另外,开发部分实际花费的时间要比预估的时间少一些,博主在完成任务时效率应该还是不错的。
关于PSP中“计划共完成需要的时间”与“实际完成需要的时间”两列数据的差异化分析与原因探究,这部分没有很好地完成,希望博主可以后续完善一下,在发现问题,分析原因中继续成长进步。
代码核查表
概要部分
- 代码基本符合需求
- 代码设计有周全的考虑
- 代码可读性还不错
- 代码的每一行都执行并检查过了
设计规范部分
- 代码没有依赖于某一平台,不会影响将来的移植
- 没有无用的代码可以清除
代码规范部分
修改的部分符合代码标准和风格具体代码部分
- 没有对错误进行处理;对于调用的外部函数,没有检查返回值或处理异常
- 参数传递没有错误,字符串是以0开始计数
- 没有使用断言(Assert)来保证我们认为不变的条件真的满足
- 数据结构中没有无用的元素
效能
代码的效能一般,数据量比较小时运行较快,但是当数据量较大时耗时较多可读性
代码可读性不错,该有注释的地方基本做了注释
结对方项目仓库中的Fork、Clone、Push、Pull request、Merge pull request日志数据
要想将别人的项目clone 到本地,需要下载、安装和配置Git。Git负责用户在计算机上本地发生的、与GitHub有关的所有内容。
以下是部分配置操作截图,详细可参考这篇博文对Git进行安装、配置。
获取公钥
将公钥添加到Github管理平台
对Git进行环境配置
- Fork:将别人发布的项目复制,相当于一个分支;项目复制到自己的github中,于是本地就有了一个仓库。
fork成功后即可在自己的github中看到复制的仓库:

- Clone:从自己的github上把fork过来的项目复制到本地,这样本地就有了一个项目。
在本地新建一个MyGit文件夹,将项目文件clone到该文件夹:
- Push:将本地项目进行修改开发后,同步到你的github上的仓库中。
在下载下来的本地项目中进行修改,通过“git add”将修改后的文件添加至队列,再通过“git commit”提交本次修改:
通过“git push”将修改的版本提交至github账户:
Pull request:把自己github中的已经修改的内容申请同步到最初那个开发者的项目中。
“push”之后在github中即可看到修改的记录,点击右上方”Pull request“即可提交请求:
Merge pull request:最初的开发者同意你的修改,将其合并到自己的项目中。
对方同意之后,即可在对方github上看到对项目的修改:
任务3:
采用两人结对编程方式,设计开发一款D{0-1}KP 实例数据集算法实验平台
需求分析陈述
- 将实验二任务3的功能嵌入平台,作为平台的基础功能
- D{0-1}KP 实例数据集需存储在数据库
- 动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据
- 人机交互界面要求为GUI界面
- 设计遗传算法求解D{0-1}KP,并利用此算法测试要求
软件设计说明
使用python语言来做GUI界面是比较方便的,故软件使用python语言开发。在数据库存储方面,使用SQLite实现数据库存储功能。
软件实现及核心功能代码展示
软件实现
软件从整体上分为三个窗口类:MyFrame、MyFrame2、MyFrame3:
- MyFrame用于获取用户想要读取的文件,输入文件序号,点击按钮后,读取输出的序号,判断输入序号是否合法,弹出提示框,如果读取成功则调用MyFrame2。
- MyFrame2用于获取用户想要读取文件中的哪组数据,类中功能与MyFrame类似,如果读取成功则调用MyFrame3。
- MyFrame3是功能实现比较集中的一个类。
MyFrame3中实现的功能有:
- 通过函数CreateDataBase(self)创建数据库,并且将指定的文件数据存放至数据库中创建的表中。
- 对读取道德文件数据进行编号,并且显示数据.
- 对获取到的数据按项集中的第三项物品的价值/重量比进行排序。
- 通过bag(self,n,c,w,v)函数实现动态规划算法求解D{0-1}KP问题,并显示运行时间。
- 实现散点图的绘制。
- 关于遗传算法,其主要的实现函数有:
init(self,N,n)用来初始化,N为种群规模,n为染色体长度
fitness(self,C,N,n,W,V,w)为评估函数
best_x(self,F,S,N)为适应值函数
rate(self,x)计算比率
chose(self,p, X, m, n)用来选择
match(self,X, m, n, p)用来交配
vari(self,X, m, n, p)用来变异
核心功能代码展示
# 创建数据库
def CreateDataBase(self):
global i
global d
global cubage # 背包最大容量
global profit # 物品价值
global weight # 物品重量
global pw # 物品价值/重量比
# 连接到SQLite数据库,数据库文件是mrsoft.db
conn = sqlite3.connect('mrsoft.db')
cursor = conn.cursor()
# 如果表已经存在则删除
cursor.execute('DROP TABLE IF EXISTS user')
# 如果表不存在则创建表
cursor.execute('create table if not exists user (num int(10) primary key,profit int(20), weight int(20))')
cubage[i] = max(list(map(int,re.findall(r'\d+',line[i*8+3]))))
profit[i] = list(map(int,re.findall(r'\d+',line[i*8+5])))
weight[i] = list(map(int,re.findall(r'\d+',line[i*8+7])))
pw[i] = list(map(lambda x:x[0]/x[1],zip(profit[i],weight[i])))
# 往表中插入数据
for j in range(0,d):
cursor.execute('insert into user (num,profit,weight) values ("%d","%d","%d")'%(j,profit[i][j],weight[i][j]))
cursor.execute('select * from user')
result=cursor.fetchall()
# 关闭游标
cursor.close()
# 提交事务
conn.commit()
# 关闭Connection
conn.close()
return result
class MyFrame3(wx.Frame):
def __init__(self, parent, id):
wx.Frame.__init__(self, parent, id, '有效数据', size=(800, 800))
# 遗传算法
start2 = time.perf_counter()
heigh = heigh+70
m = 32 # 规模
N = 500 # 迭代次数
Pc = 0.8 # 交配概率
Pm = 0.05 # 变异概率
V =profit[i] # 物品价值
W =weight[i] # 物品重量
n = len(W) # 染色体长度
w = cubage[i] # 背包最大容量
C = self.init(m, n)
S,F = self.fitness(C,m,n,W,V,w)
B ,y = self.best_x(F,S,m)
Y =[y]
for i in range(N):
p = self.rate(F)
C = self.chose(p, C, m, n)
C = self.match(C, m, n, Pc)
C = self.vari(C, m, n, Pm)
S, F = self.fitness(C, m, n, W, V, w)
B1, y1 = self.best_x(F, S, m)
if y1 > y:
y = y1
Y.append(y)
wx.StaticText(self.panel,label='遗传算法:', pos=(500,heigh))
heigh = heigh+30
wx.StaticText(self.panel,label='最大价值为:%d'%(y), pos=(500,heigh))
# 初始化,N为种群规模,n为染色体长度
def init(self,N,n):
C = []
for i in range(N):
c = []
for j in range(n):
a = np.random.randint(0,2)
c.append(a)
C.append(c)
return C
# 评估函数
# x(i)取值为1表示被选中,取值为0表示未被选中
# w(i)表示各个分量的重量,v(i)表示各个分量的价值,w表示最大承受重量
def fitness(self,C,N,n,W,V,w):
S = [] # 用于存储被选中的下标
F = [] # 用于存放当前该个体的最大价值
for i in range(N):
s = []
h = 0 # 重量
f = 0 # 价值
for j in range(n):
if C[i][j]==1:
if h+W[j]<=w:
h=h+W[j]
f = f+V[j]
s.append(j)
S.append(s)
F.append(f)
return S,F
# 适应值函数,B位返回的种族的基因下标,y为返回的最大值
def best_x(self,F,S,N):
y = 0
x = 0
B = [0]*N
for i in range(N):
if y<F[i]:
x = i
y = F[x]
B = S[x]
return B,y
# 计算比率
def rate(self,x):
p = [0] * len(x)
s = 0
for i in x:
s += i
for i in range(len(x)):
p[i] = x[i] / s
return p
# 选择
def chose(self,p, X, m, n):
X1 = X
r = np.random.rand(m)
for i in range(m):
k = 0
for j in range(n):
k = k + p[j]
if r[i] <= k:
X1[i] = X[j]
break
return X1
# 交配
def match(self,X, m, n, p):
r = np.random.rand(m)
k = [0] * m
for i in range(m):
if r[i] < p:
k[i] = 1
u = v = 0
k[0] = k[0] = 0
for i in range(m):
if k[i]:
if k[u] == 0:
u = i
elif k[v] == 0:
v = i
if k[u] and k[v]:
# print(u,v)
q = np.random.randint(n - 1)
# print(q)
for i in range(q + 1, n):
X[u][i], X[v][i] = X[v][i], X[u][i]
k[u] = 0
k[v] = 0
return X
# 变异
def vari(self,X, m, n, p):
for i in range(m):
for j in range(n):
q = np.random.rand()
if q < p:
X[i][j] = np.random.randint(0,2)
return X
程序运行
- 选择要读取的文件:
- 选择要文件中要读取哪一组数据:
- 读取到的数据存入数据库:
- 散点图的显示:
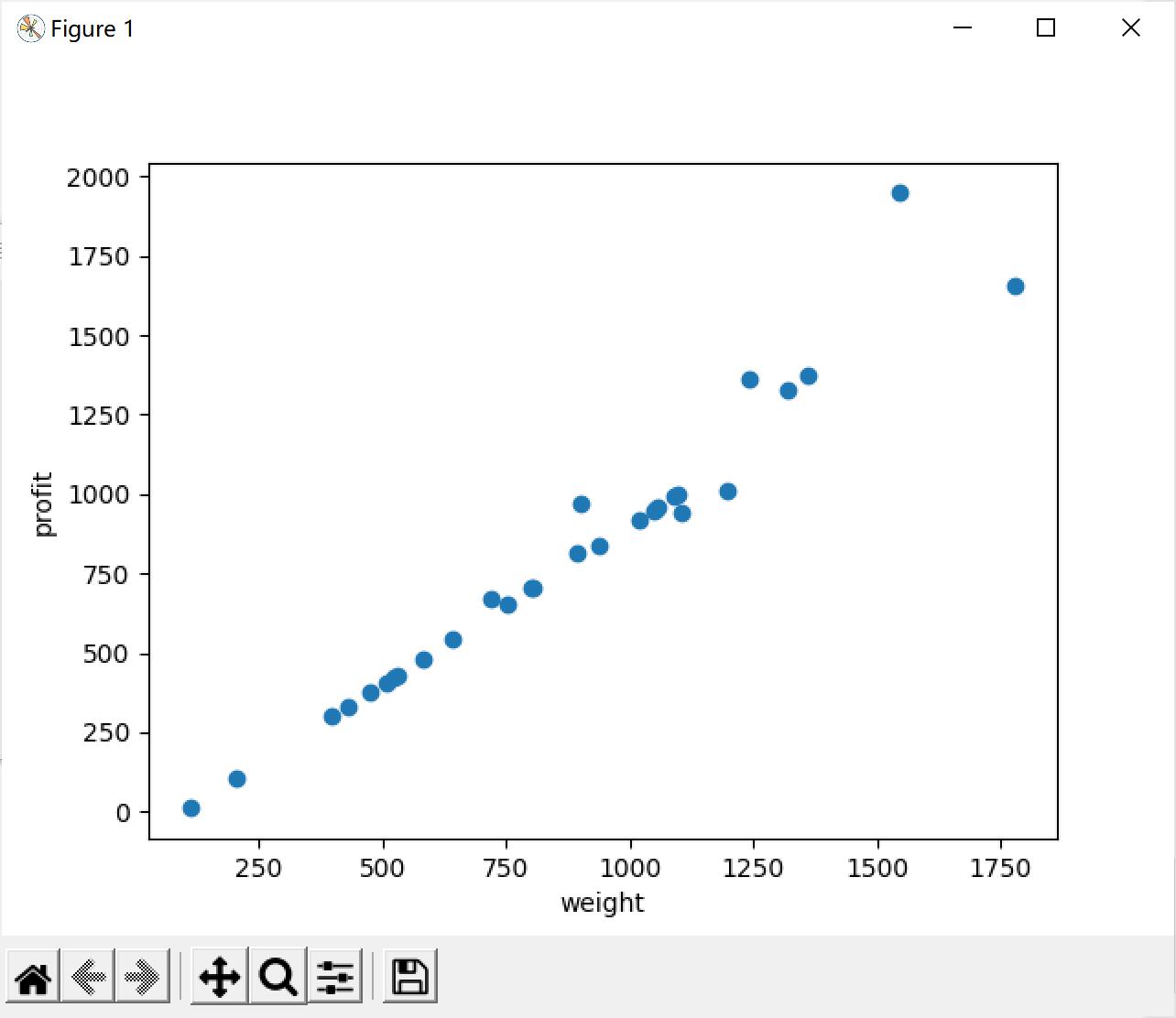
- 遗传算法运行结果(需要注意的是:遗传算法是一种近似最优化算法,它的每个解都是近似最优解,不能保证是全局最优。):
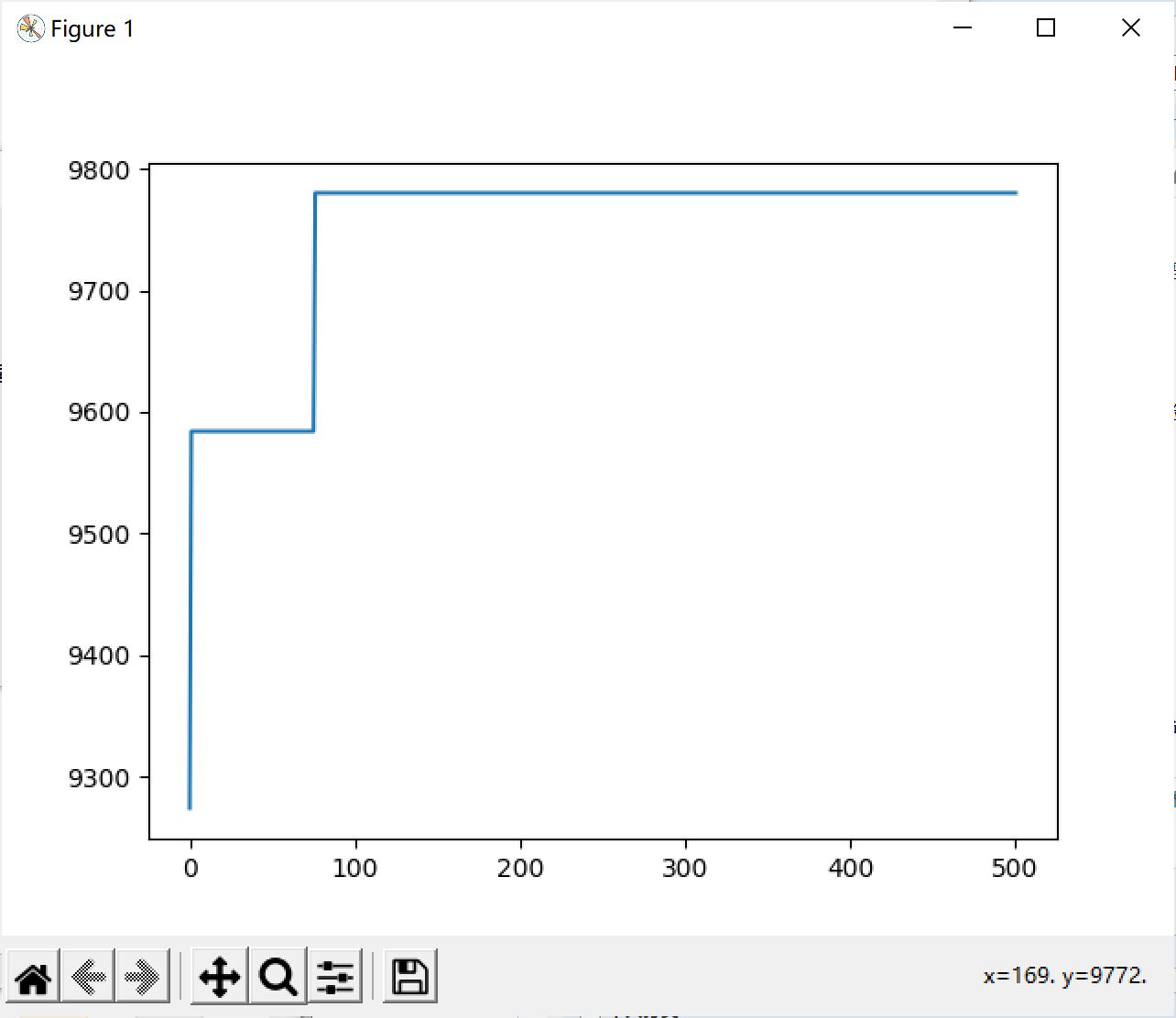
- 结果存储至txt中:

- 显示读取到的数据并对其编号,对读取到的数据按项集中的第三项的价值/重量比进行排序,显示动态规划算法以及遗传算法求解后的结果:
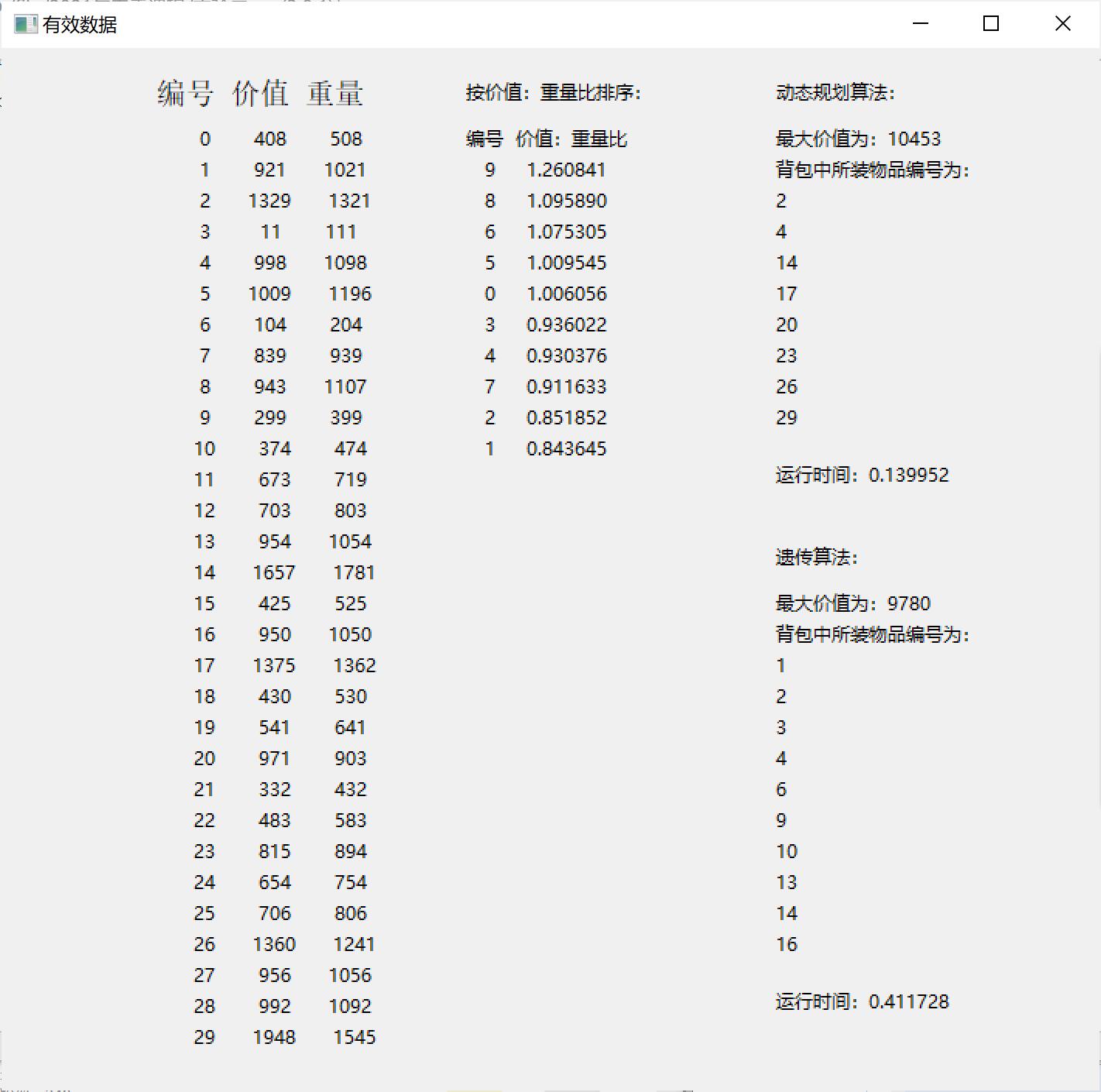
- 选择要读取的文件:
项目commit的记录
- 描述结对的过程,提供两人在讨论、细化和编程时的结对照片
因为都在一个宿舍,所以聚集在一起来共同完成这个项目是比较方便的,并且比较熟悉,在沟通方面也是顺畅的。最开始是一起分析确定了项目要实现哪一些功能,GUI界面如何呈现,各类功能如何嵌入GUI界面,选择什么语言来编程,大概的方向确定好之后,就开始着手写代码。在编程的过程中,两个人轮流编程,一人编程的时候,另一人帮忙查资料,检查代码中是否有错误,提醒修改,遇到麻烦的地方,两个人一起思考、商量解决办法。 - 提供此次结对作业的PSP
| PSP2.1 | 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 20 | 20 |
| Development | 开发 | 1090 | 1200 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 155 |
| Design Spec | 生成设计文档 | 30 | 20 |
| Design Review | 设计复审 (和同事审核设计文档) | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 35 |
| Design | 具体设计 | 60 | 50 |
| Coding | 具体编码 | 600 | 650 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 200 | 240 |
| Reporting | 报告 | 100 | 100 |
| Test Report | 测试报告 | 30 | 40 |
| Size Measurement | 计算工作量 | 40 | 30 |
| Postmortem & Process Improvement Plan | 事后总结 ,并提出过程改进计划 | 30 | 30 |
- 小结感受:两人合作真的能够带来1+1>2的效果吗?通过这次结对合作,请谈谈你的感受和体会
两人合作是否能够带来1+1>2的效果,取决于两个人之间的沟通是否有效,是否能够朝着共同的目标去各自补充,合作完成任务。对于本次我们组的结对编程,我觉得两个人合作是能带来1+1>2的效果的。
通过这次结对合作,我觉得对于一个较复杂的任务而言,一个人的能力、掌握的知识毕竟有限,两个人合作编程,能够综合各自掌握的知识,在编码的过程中,两个人轮流编程,互相监督,能够及时发现错误,少走一些不必要的弯路,并且不会的地方,两个人也能够一起讨论对策,提升了编码效率。
两个人的合作,只要可以有效沟通,是可以很好地达到完成任务、共同进步的效果的。
201871030138-杨蕊媛 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告的更多相关文章
- 201871030137-杨钦颖 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
201871030137-杨钦颖 实验三 结对项目-<D{0-1}KP 实例数据集算法实验平台>项目报告 项目 内容 课程班级博客链接 班级连接 这个作业要求链接 作业连接 我的课程学习目 ...
- 201871030125-王芬 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
实验三 软件工程结对项目 项目 内容 课程班级博客链接 https://edu.cnblogs.com/campus/xbsf/2018CST 这个作业要求链接 https://www.cnblogs ...
- 201871030110-何飞 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
201871030110-何飞 实验三 结对项目-<D{0-1}KP 实例数据集算法实验平台>项目报告 项目 内容 课程班级博客链接 班级博客 这个作业要求链接 作业要求 我的课程学习目标 ...
- 201871030139-于泽浩 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
201871030139-于泽浩 实验三 结对项目-<D{0-1}KP 实例数据集算法实验平台>项目报告 项目 内容 课程班级博客链接 2018级卓越班 这个作业要求链接 软件工程结对项目 ...
- 201871010110-李华 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
项目 内容 课程班级博客链接 班级博客 这个作业要求链接 作业要求 我的课程学习目标 (1)理解并掌握代码风格及设计规范:(2)通过任务3进行协作开发,尝试进行代码复审,在进行同伴复审的过程中体会结对 ...
- 201871030108-冯永萍 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
实验三 软件工程结对项目 项目 内容 课程班级博客链接 https://edu.cnblogs.com/campus/xbsf/2018CST 这个作业要求链接 https://www.cnblogs ...
- 201871030116-李小龙 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
项目 内容 课程班级博客链接 https://edu.cnblogs.com/campus/xbsf/2018CST 这个作业要求链接 https://www.cnblogs.com/nwnu-dai ...
- 201871010113-贾荣娟 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
项目 内容 课程班级博客链接 18级卓越班 这个作业要求链接 实验三-软件工程结对项目 这个课程学习目标 掌握软件开发流程,提高自身能力 这个作业在哪些方面帮助我实现了学习目标 本次实验让我对软件工程 ...
- 201871030127-王明强 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
项目 内容 课程班级博客链接 18级卓越班 这个作业要求链接 实验三 软件工程结对项目 我的课程学习目标 1.熟悉PSP流程2. 熟悉github操作3.加深对D{0-1}问题的解法的理解4.熟悉ja ...
随机推荐
- DexExtractor的原理分析和使用说明
本文博客链接:http://blog.csdn.net/qq1084283172/article/details/53557894 周末有空就写下博客了,今天来扯一扯Android平台的脱壳工具Dex ...
- IDS入侵检测系统
目录 IDS入侵检测系统 入侵检测系统的作用 入侵检测系统功能 入侵检测系统的分类 入侵检测系统的架构 入侵检测工作过程 数据检测技术 误用检测 异常检测 IDS的部署 基于网络的IDS 基于主机的I ...
- 汇编环境搭建(vs2010(2012)+masm32)
我本地使用的环境VS2012(2010)+MASM32,下面的图是在网上找的几个博客拼在一起的,用的是vs2010,但是并不影响.(所有文件我都打包好了,如果懒的话可以直接下载这个包)地址是:http ...
- 用 vitePress 快速创建一个文档项目
其实开发一个项目最需要的就是操作文档,文档的质量决定了项目的开发流程,开发规范等等. 对于前端框架来说,文档最友好的还是vue,不仅是中国人的框架,而且文档支持了中文.仔细查看 Vue 的官方文档,还 ...
- SSM整合大体步骤
SSM整合步骤: 1. 导入jar spring: springMVC: mybatis: 第三方支持:log4j,pageHelper,AspectJ,jackson,jstl 2. 搭建sprin ...
- 21.Quick QML-FileDialog、FolderDialog对话框
1.FileDialog介绍 Qt Quick中的FileDialog文件对话框支持的平台有: 笔者使用的是Qt 5.8以上的版本,模块是import Qt.labs.platform 1.1. 它的 ...
- 分布式事务与Seate框架(2)——Seata实践
前言 在上一篇博文(分布式事务与Seate框架(1)--分布式事务理论)中了解了足够的分布式事务的理论知识后,到了实践部分,在工作中虽然用到了Seata,但是自己却并没有完全实践过,所以自己私下花点时 ...
- ubuntu中执行可执行文件时报错“没有那个文件或目录”的解决办法(非权限问题)
问题:可执行文件明明存在,也有可执行权限(x),但执行时就提示"没有那个文件或目录". 原因:这个程序的是32位的程序(比如arm-linux-gcc),而系统是64位的,运行时需 ...
- UVA 160 - Factors and Factorials
Factors and Factorials The factorial of a number N (written N!) is defined as the product of all t ...
- getInstance()得理解
使用getInstance()方法的原因及作用 https://www.cnblogs.com/roadone/p/7977544.html 使用getInstance()方法的原因及作用 https ...