GAN实战笔记——第一章GAN简介
GAN简介
一、什么是GAN
GAN是一类由两个同时训练的模型组成的机器学习技术:一个是生成器,训练其生成伪数据:另一个是鉴别器,训练其从真实数据中识别伪数据。
- 生成(generative)一词预示着模型的总目标——生成新数据。GAN通过学习生成的数据取决于所选择的训练集,例如,如果我们想用GAN合成一幅看起来像达・芬奇作品的画作,就得用达·芬奇的作品作为训练集。
- 对抗(adversarial)一词则是指构成GAN框架的两个动态博弈、竞争的模型:生成器和判别器。生成器的目标是生成与训练集中的真实数据无法区分的伪数据——在刚才的示例中这就意味着能够创作出和达・芬奇画作一样的绘画作品。判别器的目标是能辨别出哪些是来自训练集的真实数据,哪些是来自生成器的伪数据。也就是说,判别器充当着艺术品鉴定专家的角色,评估被认为是达·芬奇画作的作品的真实性。这两个网络不断新地“斗智斗勇”,试图互相欺骗:生成器生成的伪数据越逼真,判别器辨别真伪的能力就要越强。
- 网络(network)一词表示最常用于生成器和判别器的一类机器学习模型:神经网络。依据GAN实现的复杂程度,这些网络包括从最简单的前馈神经网络到卷积神经网络以及更为复杂的变体。
二、GAN是如何工作的
还有一个比喻经常用来形容GAN,假币制造者(生成器)和试图逮捕他的侦探(判别器)——假钞看起来越真实,就需要越好的侦探才能辨别出他们,反之亦然。
用更专业的术语来说,生成器的目标是生成能最大程度有效捕捉训练集特征的样本,以至于生成出的样本与训练数据别无二致。生成器可以看作一个反向的对象识别模型——对象识别算法学习图像中的模式,以期能够识别图像的内容。生成器不是去识别这些模式,而是要学会从头开始学习创建它们,实际上,生成器的输入通常不过是一个随机数向量。
生成器通过从鉴别器的分类结果中接收反馈来不断学习。判别器的目标是判断一个特定的样本是真的(来自训练集)还是假的(由生成器生成)。因此,每当判别器“上当受骗”将假的图像错判为真实图像时,生成器就会知道自己做得很好:相反,每当判别器正确地将生成器生成的假图像辨别出来时,生成器就会收到需要继续改进的反馈。
判别器也会不断地改善,像其他分类器一样,它会从预测标签与真实标签(真或假)之间的偏差中学习。所以随着生成器能更好地生成更逼真的数据,判别器也能更好地辨别真假数据,两个网络都在同时不断地改进着。
表1.1 生成器和判别器的关键信息
| 生成器 | 判别器 | |
|---|---|---|
| 输入 | 一个随机数向量 | 判别器的输入有两个来源:来自训练集的真实样本和来自生成器的伪样本 |
| 输出 | 尽可能令人信服的伪样本 | 预测输入样本是真实的概率 |
| 目标 | 生成与训练集中数据别无二致的伪数据 | 区分来自生成器的伪样本和来自训练集的真实样本 |
三、GAN的结构
假定我们的目标是教GAN生成逼真的手写数字。GAN的核心结构如下图所示。
让我们看看其中的细节。
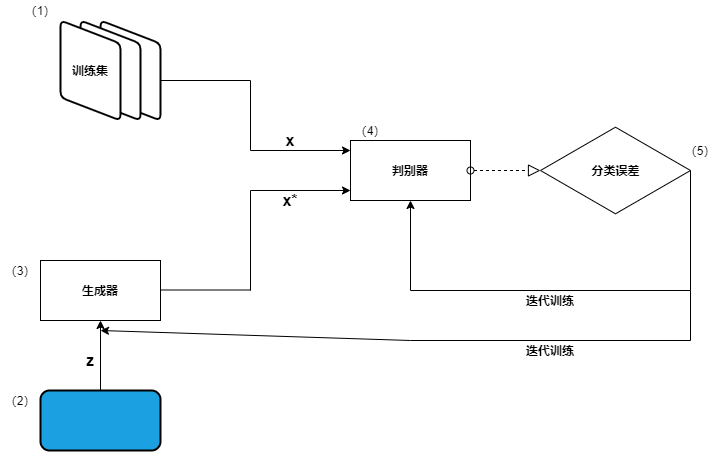
(1) 训练数据集——包含真实样本的数据集,是我们希望生成器能以近乎完美的质量去学习模仿的数据。在这个示例中,数据集由手写数字的图像组成。该数据集用作判别器网络的输入(\(x\))。
(2) 随机噪声向量——生成器网络的初始输入(z)。此输入是一个由随机数组成的向量,生成器将其用作合成伪样本的起点。
(3) 生成器网络——生成器接收随机数向量(z)作为输入并输出伪样本(x*)。它的目标是生成和训练数据集中的真实样本别无二致的伪样本。(卷积神经网络)
(4) 判别器网络——判别器接收来自训练集的真实样本(x)或生成器生成的伪样本(x*)作为输入。对每个样本,判别器会进行判定并输出其为真实的概率。(反卷积神经网络)
(5) 迭代训练/调优——对于每个判别器的预测,我们会衡量它效果有多好——就像对常规的分类器一样——并用结果反向传播去迭代优化判别器网络和生成网络。
- 更新判别器的权重和偏置,以最大化其分类的精确度(最大化正确预测的概率:x为真,x*为假)。
- 更新生成器的权重和偏置,以最大化判别器将x*误判为真的概率。
3.1 GAN的训练
为了了解GAN各组件的用途,我们首先介绍GAN的训练算法,其次演示训练过程,以便我们能够可以清楚的看到实际的框架图。
GAN训练算法
对于每次训练迭代,执行如下操作。
(1)训练判别器
a.从训练集中随机抽取真实样本x。
b.获取一个新的随机噪声向量z,用生成器网络合成一个伪样本x*。
c.用判别器网络对x和x*进行分类。
d.计算分类误差并反向传播总误差以更新判别器的可训练参数,寻求最小化分类误差。
(2)训练生成器
a.获取一个新的随机噪声向量z,用生成器网络合成一个伪样本x*。
b.用判别器网络对x*进行分类。
c.计算分类误差并反向传播以更新生成器的可训练参数,寻求最大化判别器误差。
结束
GAN训练过程可视化
GAN的训练算法如下图所示,其中的字母表示GAN训练算法中的步骤。
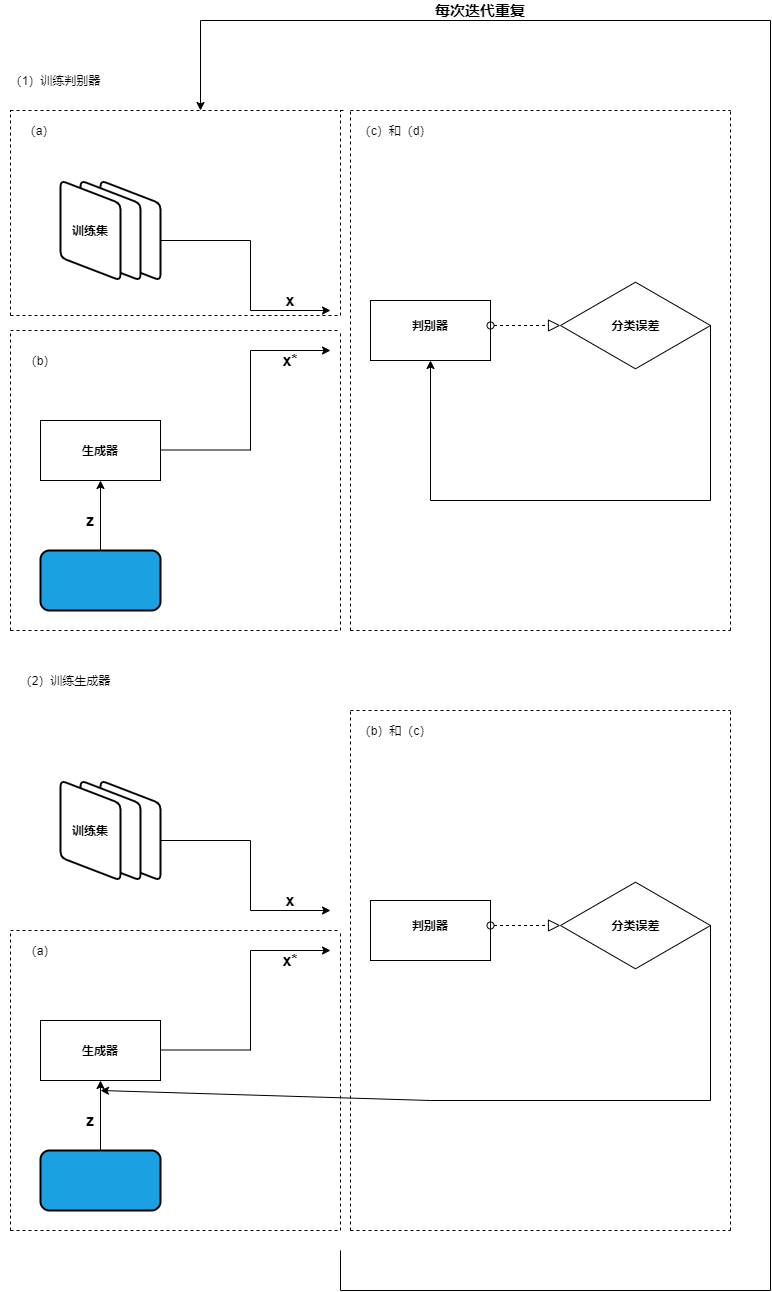
子程序图示说明
(1)训练判别器
a. 从训练集中随机抽取真实样本x。
b. 获取一个新的随机噪声向量z,用生成器网结合成一个伪样本x*。
c. 用鉴别器网络对x和x*进行分类。
d. 计算分类误差并反向传播总误差以更新判别器的权重和偏置,寻求最小化分类误差。
(2)训练生成器
a. 获取一个新的随机噪声向量z,用生成器网络合成一个伪样本x*。
b.用判别器网络对x*进行分类。
c.计算分类误差并反向传播以更新生成器的可训练参数,寻求最大化判别器误差。
3.2 达到平衡
对于一般的神经网络,我们通常有一个明确的目标去实现以及用来衡量效果。例如,当训练一个分类器时,我们度量在训练集和验证集上的分类误差,一旦发现验证集开始变坏,就停止进程(为了避免过拟合)。在GAN结构中,判别器网络和生成器网络有两个互为竞争对手的目标:一个网络越好,另一个就越差。那么我们如何决定何时停止进程呢?
这其实是一个零和博弈问题,即一方的收益等于另一方的损失。当一方提高一定程度时,另一方会恶化同样的程度。零和博弈都有一个纳什均衡点,那就是任何一方无论怎么努力都不能改善他们的处境或结果。
当满足以下条件时,GAN达到纳什均衡点。
(1)生成器生成的伪样本与训练集中的真实数据别无二致。
(2)判别器所能做的只是随机猜测一个特定的样本是真的还是假的(也就是说,猜测一个示例为真的概率是50%)。
让我们来解释为何会出现这种情况。当每一个伪样本(x*)与来自训练集的真实样本无法区分时,判别器用任何手段都无法区分它们。因为判别器接收到的样本有一半是真的,半是假的,所以它所能做的最有用的事情就是抛硬币,以50%的概率把每个样本分为真和假。
同样,生成器也处于这样一个点上,它不能从进一步的调优中获得任何提高了。因为生成器生成的样本早已和真实样本无法区分了,以至于对随机噪声向量(z)转换为伪样本(x)的过程做出哪怕一丁点儿改变,也可能给判别器提供从真实样本中辨别出伪样本的机会,从而使生成器变得更糟。
当达到纳什均衡时,GAN就被认为是收敛的。这是一个棘手的问题,在实践中,由于在非凸博弈中实现收敛所涉及的巨大复杂性,几乎不可能达到GAN的纳什均衡。实际上,GAN的收敛仍是GAN研究中最重要的开放性问题之一。
小结
- GAN是一种利用两个神经网络之间的动态竞争来合成真实数据样本的深度学习技术,例如能合成具有照片级真实感的虚假图像。构成一个完整GAN的两个网络如下:
- 生成器,其目标是通过生成与训练数据集别无二致的数据来欺骗判别器;
- 判别器,其目标是正确区分来自训练数据集的真实数据和由生成器生成的伪数据。
GAN实战笔记——第一章GAN简介的更多相关文章
- 《跟我学Shiro》学习笔记 第一章:Shiro简介
前言 现在在学习Shiro,参照着张开涛老师的博客进行学习,然后自己写博客记录一下学习中的知识点,一来可以加深理解,二来以后遗忘了可以查阅.没有学习过Shiro的小伙伴,也可以和我一起学习,大家共同进 ...
- GAN实战笔记——第二章自编码器生成模型入门
自编码器生成模型入门 之所以讲解本章内容,原因有三. 生成模型对大多数人来说是一个全新的领域.大多数人一开始接触到的往往都是机器学习中的分类任务--也许因为它们更为直观:而生成模型试图生成看起来很逼真 ...
- JS红宝书笔记——第一章 JavaScript简介
1.JavaScript简史 Netscape公司决定开发一种客户端语言用来处理浏览器端简单的表单验证. Netscape公司派布兰登·艾奇(BrendanEich)为计划于1995年2月发布的Net ...
- 第一章 C++简介
第一章 C++简介 1.1 C++特点 C++融合了3种不同的编程方式:C语言代表的过程性语言,C++在C语言基础上添加的类代表的面向对象语言,C++模板支持的泛型编程. 1.2 C语言及其编程 ...
- C++ Primer 笔记 第一章
C++ Primer 学习笔记 第一章 快速入门 1.1 main函数 系统通过调用main函数来执行程序,并通过main函数的返回值确定程序是否成功执行完毕.通常返回0值表明程序成功执行完毕: ma ...
- Android开发艺术探索笔记——第一章:Activity的生命周期和启动模式
Android开发艺术探索笔记--第一章:Activity的生命周期和启动模式 怀着无比崇敬的心情翻开了这本书,路漫漫其修远兮,程序人生,为自己加油! 一.序 作为这本书的第一章,主席还是把Activ ...
- Android群英传笔记——第一章:Android体系与系统架构
Android群英传笔记--第一章:Android体系与系统架构 图片都是摘抄自网络 今天确实挺忙的,不过把第一章的笔记做一下还是可以的,嘿嘿 1.1 Google的生态圈 还是得从Android的起 ...
- python 教程 第一章、 简介
第一章. 简介 官方介绍: Python是一种简单易学,功能强大的编程语言,它有高效率的高层数据结构,简单而有效地实现面向对象编程.Python简洁的语法和对动态输入的支持,再加上解释性语言的本质,使 ...
- GAN实战笔记——第五章训练与普遍挑战:为成功而GAN
训练与普遍挑战:为成功而GAN 一.评估 回顾一下第1章中伪造达・芬奇画作的类比.假设一个伪造者(生成器)正在试图模仿达・芬奇,想使这幅伪造的画被展览接收.伪造者要与艺术评论家(判别器)竞争,后者试图 ...
随机推荐
- RapidSVN设置diff和edit工具
菜单栏 -> View -> Preferences -> Programs选择相应的配置页即可 需要配置的路径,默认都在 /usr/bin目录下的 editor可以用ged ...
- VSCode 在.vscode/launch.json中设置启动时的参数
如下脚本设置启动参数,如题,在.vscode/launch.json文件中,红色部分设置运行参数 { // Use IntelliSense to learn about possible attri ...
- 发布日志 - kratos v2.0.4 版本发布
V2.0.4 Release Release v2.0.4 · go-kratos/kratos (github.com) 新的功能 proto-gen-http 工具在生产代码时如果 POST/PU ...
- 分布式技术专题-分布式协议算法-带你彻底认识Paxos算法、Zab协议和Raft协议的原理和本质
内容简介指南 Paxo算法指南 Zab算法指南 Raft算法指南 Paxo算法指南 Paxos算法的背景 [Paxos算法]是莱斯利·兰伯特(Leslie Lamport)1990年提出的一种基于消息 ...
- Intel® QAT 加速卡之IPSec示例
Intel QAT 加速卡之IPSec示例 文章目录 Intel QAT 加速卡之IPSec示例 1. QAT处理IPSec入站报文 2. QAT处理IPSec出站报文 3. 组织架构 4. 示例源码 ...
- SNMP协议之序言
最近两周公司分配一个任务:使用snmp协议做一个网管,来配置我们的产品.这可以说是我第一次听说这个协议,我问了一下周围的同事这是个什么协议,同事说"简单网络管理协议",其实这个协议 ...
- TreeView和ListView数据库查询数据联动操作
好久不用了,重新整理下放这里以备需要使用,功能见图 数据库表结构 定义TreeView addObject中data存储的记录集 type PNode = ^TNode; TNode = record ...
- js根据日期获取所在周
一.获取时间所在周的周一.周五 function getFirstLastDay (time) { let date = new Date(time) let Time = date.getTime( ...
- 5UCMS判断当前栏目高亮(用于当前所在栏目加背景图片或颜色)
5UCMS判断当前栏目高亮标签 比较简单的是频道页(channel.html): 大类代码: <!--menu:{ $row=10 $table=channel }--> <li { ...
- Java基础系列(39)- 二维数组
多维数组 多维数组可以看成是数组的数组,比如二维数组就是一个特殊的一维数组,其每一个元素都是一个一维数组. 二维数组 int a[][]=new int[2][5]; 解析:以上二维数组a可以看成一个 ...