洛谷2093 JZPFAR + KD-Tree学习笔记 (KD-Tree)
KD-Tree这玩意还真的是有趣啊....
(基本完全不理解)
只能谈一点自己的对KD-Tree的了解了。
首先这个玩意就是个暴力...
他的结构有点类似二叉搜索树
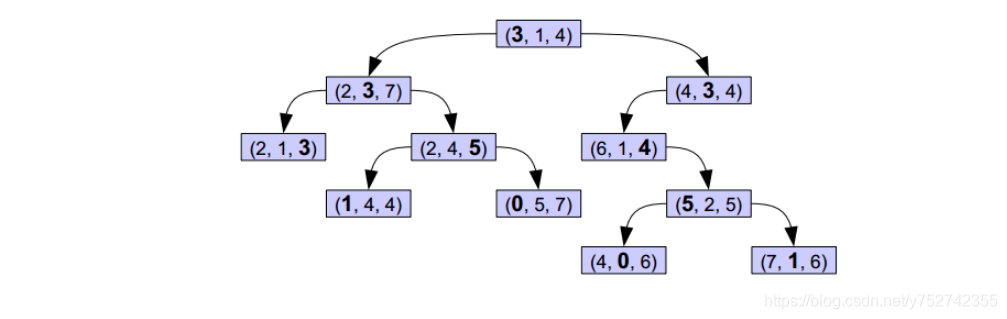
每一层都是以一个维度作为划分标准。
我们对于当前层,选择所有剩余点中,该维度比较中间的那个点作为基准点,比他小(这一维度)就放到左子树,不然右子树。
然后维度的选取是交替选取
就比如说,我们第一层是按照第一个维度,第二层是第二维度,第三层是第一维度....以此类推,直到没有剩余的点为止。
那么构造的时候,由于我们涉及到要把大于某个数的数移动到这个数后面这个操作,这时候就需要一个黑科技!!!!
\]
这个操作表示我们将\([l,r]\)区间第\(x\)大移动到第\(x\)个位置,然后大于他的放到后面,小于的放到前面
那么这时候其实就比较好解决\(build\)的问题了
void build(int &x,int l,int r,int dd) //建树的时候,我们对于不同的维度,我们选择交替建树,每次选择这个维度里面,值最中间的点作为基准点。
{
ymh = dd;
int mid = l+r >> 1;
x = mid;
nth_element(t+l,t+x,t+r+1); //将第k大的放到第k个位置,然后比他大的都在前面,小的都在后面
for (int i=0;i<=1;i++)
t[x].mx[i]=t[x].mn[i]=t[x].d[i];
if (l<x) build(t[x].l,l,mid-1,dd^1); //递归处理
if (r>x) build(t[x].r,mid+1,r,dd^1);
up(x);
}
那么现在我们该怎么解决\(query\)的问题呢
首先,KD-Tree的询问是不一定复杂度的(可能很高),但是据说是\(\sqrt n\)的?我也不是很确定的
首先,我们要写一个估价函数:
其实这个玩意,就是用来判断这个子树有没有更新答案的可能性
那么既然我们只需要判断可能性,可以直接用一些理论上的东西(比如说子树某一维度的\(mn或者mx\))
也就说,我们将每个维度和当前询问点差距最大的那个距离加起来,看看是否合法
int calc(int x) //这里这个函数的作用是个估价函数
//如果在一颗子树中,计算理论上的距离当前询问点的最远距离(因为用mn和mx算,所以是理论上)
{
if(!x) return -100;
int ans=0;
for (int i=0;i<=1;i++)
ans+=max((t[x].mx[i]-now.d[i])*(t[x].mx[i]-now.d[i]),(t[x].mn[i]-now.d[i])*(t[x].mn[i]-now.d[i]));
return ans;
}
query的时候,我们每次只需要用当前点更新答案,然后看看需要不需要进入子树里面计算,但是这里有个小\(tips\),就是
我们进入子树的时候,要选择那个可能性更大子树进入(因为存在进入完更优秀的那个子树之后,另一个子树就没有必要再进去了)
void query(int x)
{
if (!x) return;
int dl = calc(t[x].l);
int dr = calc(t[x].r);
int d = getdis(t[x],now);
if (d>q.top().dis || (d==q.top().dis && t[x].num<q.top().num)) //这里用堆维护出最大的k个距离
{
q.pop();
q.push((Node){d,t[x].num});
}
if (dl>dr) //之所以要分这个顺序,是因为有可能更新完大的那个子树,就没有必要进入小的子树
{
if (dl>=q.top().dis) query(t[x].l); //进入的条件是你的理论距离是大于当前堆顶的(也就是有可能会入堆)
if (dr>=q.top().dis) query(t[x].r);
}
else
{
if (dr>=q.top().dis) query(t[x].r);
if (dl>=q.top().dis) query(t[x].l);
}
}
那么基本上所有\(KD-Tree\)题的套路部分就这么多了。。
剩下的就是因题而异了
回到这个题。
他要求的是第k大的点对。
那我们这时候就要用一个\(priority_queue\)来维护一个k个值的堆
每次对于一个新的值,我们看是否比当前堆中最小的大,如果大就弹出原来的\(top\),然后\(push\)新的这个
然后求出来距离尽量大的k个点,最后直接输出\(q.top()\)
不过还是有很多要注意的地方
直接看代码吧
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#include<queue>
#include<map>
#include<set>
#define mk makr_pair
#define ll long long
#define int long long
using namespace std;
inline int read()
{
int x=0,f=1;char ch=getchar();
while (!isdigit(ch)) {if (ch=='-') f=-1;ch=getchar();}
while (isdigit(ch)) {x=(x<<1)+(x<<3)+ch-'0';ch=getchar();}
return x*f;
}
const int maxn = 3e5+1e2;
const int inf = 1e18;
struct KD{
int d[2],mx[2]; //d表示每一维的数是多少,mn表示子树mn,mx表示子树mx
int mn[2];
int l,r,num;
};
KD t[maxn],now;
int n,m,root,ymh;
bool operator< (KD a,KD b)
{
return a.d[ymh]<b.d[ymh]; //便于之后的nth_element的计算
}
void up(int root) //更新信息
{
for (int i=0;i<=1;i++)
{
t[root].mn[i]=min(t[root].mn[i],min(t[t[root].l].mn[i],t[t[root].r].mn[i]));
t[root].mx[i]=max(t[root].mx[i],max(t[t[root].l].mx[i],t[t[root].r].mx[i]));
}
}
void build(int &x,int l,int r,int dd) //建树的时候,我们对于不同的维度,我们选择交替建树,每次选择这个维度里面,值最中间的点作为基准点。
{
ymh = dd;
int mid = l+r >> 1;
x = mid;
nth_element(t+l,t+x,t+r+1); //将第k大的放到第k个位置,然后比他大的都在前面,小的都在后面
for (int i=0;i<=1;i++)
t[x].mx[i]=t[x].mn[i]=t[x].d[i];
if (l<x) build(t[x].l,l,mid-1,dd^1); //递归处理
if (r>x) build(t[x].r,mid+1,r,dd^1);
up(x);
}
//上面是KD_Tree问题(
struct Node{
int dis,num;
};
bool operator < (Node a,Node b)
{
return a.dis>b.dis || ((a.dis==b.dis)&&(a.num<b.num));
}
priority_queue<Node> q;
int getdis(KD a,KD b) //计算两个点之间的距离
{
return (a.d[0]-b.d[0])*(a.d[0]-b.d[0])+(a.d[1]-b.d[1])*(a.d[1]-b.d[1]);
}
int calc(int x) //这里这个函数的作用是个估价函数
//如果在一颗子树中,计算理论上的距离当前询问点的最远距离(因为用mn和mx算,所以是理论上)
{
if(!x) return -100;
int ans=0;
for (int i=0;i<=1;i++)
ans+=max((t[x].mx[i]-now.d[i])*(t[x].mx[i]-now.d[i]),(t[x].mn[i]-now.d[i])*(t[x].mn[i]-now.d[i]));
return ans;
}
void query(int x)
{
if (!x) return;
int dl = calc(t[x].l);
int dr = calc(t[x].r);
int d = getdis(t[x],now);
if (d>q.top().dis || (d==q.top().dis && t[x].num<q.top().num)) //这里用堆维护出最大的k个距离
{
q.pop();
q.push((Node){d,t[x].num});
}
if (dl>dr) //之所以要分这个顺序,是因为有可能更新完大的那个子树,就没有必要进入小的子树
{
if (dl>=q.top().dis) query(t[x].l); //进入的条件是你的理论距离是大于当前堆顶的(也就是有可能会入堆)
if (dr>=q.top().dis) query(t[x].r);
}
else
{
if (dr>=q.top().dis) query(t[x].r);
if (dl>=q.top().dis) query(t[x].l);
}
}
signed main()
{
t[0].mn[0]=t[0].mn[1]=inf;
t[0].mx[0]=t[0].mx[1]=-inf;
n=read();
for (int i=1;i<=n;i++)
{
t[i].d[0]=read();
t[i].d[1]=read();
t[i].num=i;
}
build(root,1,n,1);
m=read();
for (int i=1;i<=m;i++)
{
while (!q.empty()) q.pop();
now.d[0]=read();
now.d[1]=read();
int k=read();
for (int i=1;i<=k;i++)
q.push((Node){-1,-1}); //事先插入k个极小值
query(root);
cout<<q.top().num<<"\n";
}
return 0;
}
//https://blog.csdn.net/ws_yzy/article/details/50790735
洛谷2093 JZPFAR + KD-Tree学习笔记 (KD-Tree)的更多相关文章
- 解题:洛谷2093 JZPFAR
题面 初见K-D Tree 其实这样的题(欧几里得距离第$x$近点对)不应该用K-D Tree做,因为会被构造数据卡成$O(n^2)$,随机的另说. 但是并没有找到合适的K-D Tree的题(区域统计 ...
- dsu on tree学习笔记
前言 一次模拟赛的\(T3\):传送门 只会\(O(n^2)\)的我就\(gg\)了,并且对于题解提供的\(\text{dsu on tree}\)的做法一脸懵逼. 看网上的其他大佬写的笔记,我自己画 ...
- 珂朵莉树(Chtholly Tree)学习笔记
珂朵莉树(Chtholly Tree)学习笔记 珂朵莉树原理 其原理在于运用一颗树(set,treap,splay......)其中要求所有元素有序,并且支持基本的操作(删除,添加,查找......) ...
- splay tree 学习笔记
首先感谢litble的精彩讲解,原文博客: litble的小天地 在学完二叉平衡树后,发现这是只是一个不稳定的垃圾玩意,真正实用的应有Treap.AVL.Splay这样的查找树.于是最近刚学了学了点S ...
- 洛谷 P2056 [ZJOI2007]捉迷藏 || bzoj 1095: [ZJOI2007]Hide 捉迷藏 || 洛谷 P4115 Qtree4 || SP2666 QTREE4 - Query on a tree IV
意识到一点:在进行点分治时,每一个点都会作为某一级重心出现,且任意一点只作为重心恰好一次.因此原树上任意一个节点都会出现在点分树上,且是恰好一次 https://www.cnblogs.com/zzq ...
- Extjs学习笔记--Ext.tree.Panel
Ext.create('Ext.tree.Panel', { title: 'Simple Tree', width: 200, height: 150, store: store, rootVisi ...
- [学习笔记]K-D Tree
以前其实学过的但是不会拍扁重构--所以这几天学了一下 \(K-D\ Tree\) 的正确打开姿势. \(K\) 维 \(K-D\ Tree\) 的单次操作最坏时间复杂度为 \(O(k\times n^ ...
- k-d tree 学习笔记
以下是一些奇怪的链接有兴趣的可以看看: https://blog.sengxian.com/algorithms/k-dimensional-tree http://zgjkt.blog.uoj.ac ...
- K-D Tree学习笔记
用途 做各种二维三维四维偏序等等. 代替空间巨大的树套树. 数据较弱的时候水分. 思想 我们发现平衡树这种东西功能强大,然而只能做一维上的询问修改,显得美中不足. 于是我们尝试用平衡树的这种二叉树结构 ...
随机推荐
- Playwright-python 教程
安装 pip install playwright -i https://mirrors.aliyun.com/pypi/simple/ 使用阿里源,下载速度快一点. python -m playwr ...
- springboot静态资源路径制定
spring.resources.static-location参数指定了Spring Boot-web项目中静态文件存放地址, 该参数默认设置为: classpath:/static, classp ...
- 跨平台APP推荐收藏
时间:2019-04-11 整理:pangYuaner 标题:十大跨平台优秀软件 地址:https://www.cnblogs.com/the-king-of-cnblogs/p/3154758.ht ...
- MySQL-SQL基础-子查询
#子查询-某些情况下,当进行查询的时候,需要的条件是另外一个select语句的结果,这个时候就要用到子查询.用于子查询的关键字主要包括: in.not in.=.!=.exists.not exist ...
- 搭建本地yum源出现:mount: 在 /dev/sr0 上找不到媒体
2021-07-27 在练习环境搭建时,因为是离线环境,故先搭建本地yum源,但是出现了一个往常没有的问题:mount: 在 /dev/sr0 上找不到媒体,参考其他博主的文章得到解决方法. 排查问题 ...
- 手撕LRU缓存
面试官:来了,老弟,LRU缓存实现一下? 我:直接LinkedHashMap就好了. 面试官:不要用现有的实现,自己实现一个. 我:..... 面试官:回去等消息吧.... 大家好,我是程序员学长,今 ...
- 使用kubeadm安装kubernetes 1.21
文章原文 配置要求 至少2台 2核4G 的服务器 本文档中,CPU必须为 x86架构 CentOS 7.8 或 CentOS Stream 8 安装后的软件版本为 Kubernetes v1.21.x ...
- Redis单节点安装与使用
1.配置阿里云yum源 下载配置文件 wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7 ...
- SparkPi的编程计算
Pi的计算方式有很多,本文主要是通过Spark在概论统计的方法对Pi进行求解: 算法说明: 在边长为R的正方形中,其面积为R^2,而其内接圆的面积为pi * R^2 /4 ,圆的面积与正方形的面积比为 ...
- mybatis零碎
< < 小于号 > > 大于号 & & 和 ' ' 单 ...