大数据学习(21)—— ZooKeeper原理
这一篇我们对zookeeper的主要原理做一个简单介绍。zookeeper的核心原理是zookeeper atomic broadcast(ZAB协议),它来源于paxos协议。这里用通俗易懂的话,介绍一下paxos。
拜占庭将军问题
在介绍paxos协议之前,先来听一个故事:拜占庭将军问题。
拜占庭位于如今的土耳其的伊斯坦布尔,是东罗马帝国的首都。由于当时拜占庭罗马帝国国土辽阔,为了达到防御目的,每个军队都分隔很远,将军与将军之间只能靠信差传消息。在战争的时候,拜占庭军队内所有将军和副官必须达成一致的共识,决定是否有赢的机会才去攻打敌人的阵营。但是,在军队内有可能存有叛徒和敌军的间谍,左右将军们的决定又扰乱整体军队的秩序。在进行共识时,结果并不代表大多数人的意见。这时候,在已知有成员谋反的情况下,其余忠诚的将军在不受叛徒的影响下如何达成一致的协议,拜占庭问题就此形成。
拜占庭帝国军队的将军们必须全体一致的决定是否攻击某一支敌军。问题是这些将军在地理上是分隔开来的,并且将军中存在叛徒。叛徒可以任意行动以达到以下目标:欺骗某些将军采取进攻行动;促成一个不是所有将军都同意的决定,如当将军们不希望进攻时促成进攻行动;或者迷惑某些将军,使他们无法做出决定。如果叛徒达到了这些目的之一,则任何攻击行动的结果都是注定要失败的,只有完全达成一致的努力才能获得胜利。
拜占庭假设是对现实世界的模型化,由于硬件错误、网络拥塞或断开以及遭到恶意攻击,计算机和网络可能出现不可预料的行为。其内涵可概括为:在缺少可信任的中央节点和可信任的通道的情况下,分布在网络中的各个节点应如何达成共识。
如果不考虑拜占庭将军问题,认为网络中的通讯是可信的,那么就有办法让分布式节点在有限的时间内达成最终一致,这就是paxos协议。
Paxos协议
paxos协议的理论推导不容易懂,如何用通俗易懂地大白话把它的来龙去脉描述清楚,这就需要请出下面这位学者了(图片和本节内容来源于知乎如何浅显易懂地解说Paxos的算法)。

paxos是在多副本分布式系统中保证数据强一致的算法。
事情的背景是这样子的:多个节点组成的系统对外提供统一的服务,在数据多副本存放的场景下,在通信可信的前提下,如何保证数据是一致的。
几乎所有的分布式存储都必须用某种冗余的方式在廉价硬件的基础上搭建高可靠的存储。而冗余的基础就是多副本策略,一份数据存多份,多副本保证了可靠性,而副本之间的一致就需要paxos这类分布式一致性算法来保证。
我们从一些简单的复制策略开始,逐步分析这些策略的问题。
主从异步复制
这是最简单的复制策略之一。主节点收到写入请求后,向客户端返回成功,同时异步将内容同步至从节点。这种策略的问题显而易见:在异步同步成功之前,如果主节点故障,那么数据丢失。
主从同步复制
这种策略感觉更可靠一些了,在从节点同步成功之后才向客户端返回成功。缺点是,如果有一个从节点故障了,那么写请求会一直阻塞下去。
半同步复制
这种策略不强求所有的节点全部复制成功,只要把数据复制到足够多的节点上就行。这种策略也有问题,如果两条记录复制到没有交集的节点上了,那么主节点失效的时候,虽然可以恢复全部数据,但是存在同一个数据内容不一致的情况。
多数派读写
每条数据必须写入到半数以上的机器上,读取的时候也要检查是否半数以上的机器上有这条记录。这种策略可以保证数据是全量的,不会因为少数机器的失效而丢失。
然鹅多数派读写的策略也有个但是,就是对于一条数据的更新时,会产生不一致的状态。例如:
- node-1, node-2都写入了a=x。
- 下一次更新时node-2,node-3写入了a=y。
这时, 一个要进行读取a的客户端如果联系到了node-1和node-2,它将看到2条不同的数据。
为了不产生歧义,多数派读写还必须给每笔写入增加一个全局递增的时间戳。更大时间戳的记录如果被看见,就应该忽略小时间戳的记录。这样在读取过程中,客户端就会看到a=x₁,a=y₂ 这2条数据,通过比较时间戳1和2,发现y是更新的数据,所以忽略a=x₁,这样保证多次更新一条数据不产生歧义。
- node-1:a=x₁
- node-2:a=x₁
- node-3:a=y₂
这时另一个读取的客户端来了,
- 如果它联系到node-1和node-2,那它得到的结果是a=x₁。
- 如果它联系到node-2和node-3,那它得到的结果是a=y₂。
整个系统对外部提供的信息仍然是不一致的。
paxos基本思路
现在我们已经非常接近最终奥义了,paxos可以认为是多数派读写的进一步升级,paxos中通过2次原本并不严谨的多数派读写,实现了严谨的强一致consensus算法。
首先为了清晰的呈现出分布式系统中的核心问题:一致性问题,我们先设定一个假象的存储系统,在这个系统上,我们来逐步实现一个强一致的存储,就得到了paxos对一致性问题的解决方法。
在实现中,set命令直接实现为一个多数派写,这一步非常简单。而inc操作逻辑上也很简单,读取一个变量的值i₁,给它加上一个数字得到i₂,再通过多数派把i₂写回到系统中。冰雪如你一定已经看到了这种实现方式中的问题:如果有2个并发的客户端进程同时做这个inc的操作,在多数派读写的实现中,必然会产生一个Y客户端覆盖X客户端的问题。从而产生了数据更新点的丢失。而paxos就是为了解决这类问题提出的,它需要让Y能检测到这种并发冲突,进而采取措施避免更新丢失。
提取一下上面提到的问题:让Y去更新的时候不能直接更新i₂,而是应该能检测到i₂的存在,进而将自己的结果保存在下一个版本i₃中,再写回系统中。而这个问题可以转化成:i的每个版本只能被写入一次,不允许修改。如果系统设计能满足这个要求,那么X和Y的inc操作就都可以正确被执行了。于是我们的问题就转化成一个更简单,更基础的问题:如何确定一个值(例如in)已经被写入了。直观来看,解决方法也很简单,在X或Y写之前先做一次多数派读,以便确认是否有其他客户端进程已经在写了,如果有,则放弃。
但是,这里还有个并发问题,X和Y可能同时做这个写前读取的操作,并且同时得出一个结论:还没有其他进程在写入,我可以写。这样还是会造成更新丢失的问题。为了解决上面的问题,存储节点还需要增加一个功能,就是它必须记住谁最后一个做过写前读取的操作。并且只允许最后一个完成写前读取的进程可以进行后续写入,同时拒绝之前做过写前读取的进程写入的权限。可以看到,如果每个节点都记得谁读过,那么当Y最后完成了写前读取的操作后,整个系统就可以阻止过期的X的写入。
这个方法之所以能工作也是因为多数派写中,一个系统最多只能允许一个多数派写成功。paxos也是通过2次多数派读写来实现的强一致。
以上就是paxos算法的全部核心思想了,是不是很简单?剩下的就是如何实现的简单问题了:如何标识一个客户端如X和Y,如何确认谁是最后一个完成写前读写的进程,等等。
ZooKeeper原子广播
以上大致讲解了一下paxos协议,让我们再回到zk。ZooKeeper的核心是原子消息系统,它可以让所有Server保持同步,对外提供统一视图。
这个消息系统有如下特征:
- 可靠的消息传递:当一台服务器传递消息m的时候,它将被所有服务器传递(类似泛洪操作)。
- 单服务器一致性:当一台服务器先传递消息a,再传递消息b,那么消息a将比b更早地被所有服务器传递。
- 全局一致性:当一台服务器先传递消息a,另一台服务器后传递消息b,那么a的顺序在b之前。第三台服务器在b之后又传递消息c,那么c的顺序在b之后。(应该有个全局的时间同步服务器)
这些特征由ZooKeeper采用的协议保障。ZooKeeper集群的每两个节点之间建立TCP连接,构造一个FIFO通道,它每秒能够发送数千个请求,保证整个系统可靠、高效、快速恢复。这些功能基于TCP协议的如下特性:
- 顺序传递:数据传递的顺序和它被发送的顺序一致。举个例子,消息m在所有之前发送的消息全部传递之后才会传递。(如果消息m丢失了,那么它之后的所有消息都会丢失。)
- 连接关闭后没有消息:当一个FIFO通道关闭后,不会再收到任何消息。
FLP不可能原理告诉人们,不要浪费时间,去为异步分布式系统设计在任意场景下都能实现共识的算法。 为保证在节点失效的情况下达成共识,zookeeper使用超时机制来处理,但是超时只检查节点是否存活,而不是是否正确。在超时机制出现问题时,消息系统可能会挂起,这种情况不会违背一致性。
描述zk消息协议会涉及到三个部分。
- 数据包:通过FIFO通道发送的字节序列。
- 提案:达成共识的最小单元。提案在法定人数(俗话就是过半通过)的zk节点达成一致后通过,大多数的提案包含消息,极少像选举新leader的提案不包含消息。
- 消息:一个被原子广播到所有zk服务器的字节序列。
如上所述,zk保证消息和提案的全局顺序。zk有个全局的事务id,叫zxid,可以想到,由于写操作都是通过leader执行的,单点很容易维护一个递增的事务id。所有的提案在提出的时候都会打上zxid的戳,当这个提案发送给所有zk服务器的时候,只要超过半数的服务器收到该提案,那么它就达成了共识。如果提案包含消息,那么消息将在提案提交的时候被送达。一个共识会被服务器持久化到本地存储。
zxid包含两部分,说起来跟中国古代的年号纪年很像,一部分是时代,一部分是计数,就像“顺治二年”这种记法一样。zxid是一个64位数字,前32位是时代,后32位是计数,它既可以看成一个数字,又可以看成是一个整数对。时代的变化表示leader变了,也就是朝代的更替。在leader是单点的情况下,计数很容易分配,每一个新的提案加1就行了。
leader激活
leader激活包含了leader选举。
- leader在所有的follower中拥有最高的zxid(经验最丰富)
- 过半的服务器投票给这个leader
如果多个follower的zxid一样咋办?它们会推选出myid最大的那个节点成为leader。
leader选举的过程比较复杂,用文字描述很难说清楚。当一个新的leader选出来后,时代+1,计数清零。在选举新leader的提议达成共识之前,集群对外停止服务。
消息传递
leader选举成功之后,消息机制就能正常工作了。zk的消息机制类似于两阶段提交。
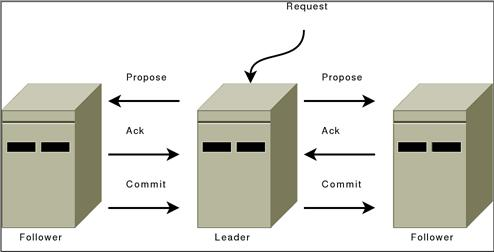
所有的提案(消息)都是leader发起的,它维护了一个队列,所以跟其他follower的通讯是有顺序的。
- leader给followers发起提案采用相同的顺序,这个顺序与leader收到请求的顺序是完全一致。它的实现基于FIFO队列。
- followers按照接收的顺序来处理消息。这表示消息确认也是按顺序的,那么leader接收followers的确认也是按顺序的。如果消息m写入了follower的本地存储,那么在m之前的消息一定也持久化了(zk基于内存,所以速度快,但是定期会持久化)。
- 当一个提案被过半同意的时候,leader马上就会提交它,变成正式法令。由于消息确认是按消息接收的顺序来的,leader发送的正式法令也是按消息顺序来的。
啰嗦了这么多,其实就是一条:同一个客户端的操作是按发起顺序执行的,不同客户端的操作按leader接收顺序执行。
法定人数
官网叫Quorums,法定人数,什么鬼,能不能说人话。前面说选举和消息机制都是过半通过就行,这有一个前提:所有的followers权重相同。实际上也可以给followers分配不同的权重,只要权重超过总权重的一半就算通过。
除了leader和follower,还有一种角色是observer,它不参与投票,只同步leader的数据,有效提高了zk的扩展性,提高了写性能。只有follower参与投票可以更快地达成共识,减少写开销。
大数据学习(21)—— ZooKeeper原理的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习:storm流式计算
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: 1.Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 2.由于Storm的处理组件都是分布式的, ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据篇:Zookeeper
Zookeeper 1 Zookeeper概念 Zookeeper是什么 是一个基于观察者设计模式的分布式服务管理框架,它负责和管理需要关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Z ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
随机推荐
- springboot+kurento+coturn+contos的视频通讯服务搭建
springboot+kurento+coturn+contos的视频通讯服务搭建 服务器CentOS Linux release 7.9.2009 (Core) 本案例成功于20210628 1.默 ...
- Oracle数据泵导出数据库
Oracle数据泵导出数据库 特别注意:如果后续要导入的数据库版本低,所有导出命令就需要在后面加一个version=指定版本. 例如从11g导出数据导入到10g,假设10g具体版本为10.2.0.1, ...
- Kubernetes的亲和性和反亲和性
节点亲缘性规则可以影响pod被调度到哪个节点.但是,这些规则只影响了pod和节点之间的亲缘性.然而,有些时候也希望能有能力指定pod自身之间的亲缘性. 举例来说,想象一下有一个前端pod和一个后端po ...
- win10 共享文件夹设置无需用户名密码访问
文件夹设置共享,添加Everyone 文件夹右键属性,选择共享,添加Everyone,添加后可设置读写权限. 权限添加Everyone,不然没有权限访问 设置安全策略 Win+R 打开运行,输入 se ...
- 用阻塞队列实现一个生产者消费者模型?synchronized和lock有什么区别?
多线程当中的阻塞队列 主要实现类有 ArrayBlockingQueue是一个基于数组结构的有界阻塞队列,此队列按FIFO原则对元素进行排序 LinkedBlockingQueue是一个基于链表结构的 ...
- GKCTF X DASCTF 2021_babycat复现学习
17解的一道题,涉及到了java反序列化的知识,学习了. 看了下积分榜,如果做出来可能能进前20了哈哈哈,加油吧,这次就搞了两个misc签到,菜的扣脚. 打开后是个登录框,sign up提示不让注册, ...
- 7.Java数组
一.数组概念(最简单的数据结构) 数组是相同类型数据的有序集合. 数组描述的是相同类型的若干个数据,按照一定的先后次序排列组合而成. 其中每一个数据称作一个数组元素,每个数组元素可以通过一个下标来访问 ...
- qtscrcpy使用
点击"USB线"一栏中的"刷新设备列表"按钮,随后设备序列号会显示出来: ·点击"获取设备IP",随后在"无线"一栏中会 ...
- flex布局制作自适应网页
网页布局是css的一个重点应用.传统的布局都是依赖display.position.float属性来实现的,但是特殊布局就不易实现,如垂直居中. 01 flex布局是什么? Flex 是 Flexi ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...