高并发HHTP实践

当今,正处于互联网高速发展的时代,每个人的生活都离不开互联网,互联网已经影响了每个人生活的方方面面。我们使用淘宝、京东进行购物,使用微信进行沟通,使用美图秀秀进行拍照美化等等。而这些每一步的操作下面,都离不开一个技术概念HTTP(Hypertext Transfer Protocol,超文本传输协议)。
举个,当我们打开京东APP的时候,首先进入的是开屏页面,然后进入首页。在开屏一般是广告,而首页是内容相关,包括秒杀,商品推荐以及各个tag页面,而各个tag也有其对应的内容。当我们在进入开屏之前或者开屏之后(这块依赖于各个app的技术实现),会向后端服务发送一个http请求,这个请求会带上该页面广告位信息,向后端要内容,后端根据广告位的配置,挑选一个合适的广告或者推荐商品返回给APP端进行展示。在这里,为了描述方便,后端当做一个简单的整体,实际上,后端会有非常复杂的业务调度,比如获取用户画像,广告定向,获取素材,计算坐标,返回APP,APP端根据坐标信息,下载素材,然后进行渲染,从而在用户端进行展示,这一切都是秒级甚至毫秒级响应,一个高效的HTTP Client在这里就显得尤为重要,本文主要从业务场景来分析,如何实现一个高效的HTTP Client。
1 概念
当我们需要模拟发送一个http请求的时候,往往有两种方式:
1、通过浏览器
2、通过curl命令进行发送请求

如果我们在大规模高并发的业务中,如果使用curl来进行http请求,其效果以及性能是不能满足业务需求的,这就引入了另外一个概念libcurl。
curl
利用URL语法在命令行方式下工作的开源文件传输工具。
它支持很多协议:DICT, FILE, FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, Telnet and TFTP。支持SSL证书,HTTP POST, HTTP PUT,FTP上传,基于表单的HTTP上传,代理(proxies)、cookies、用户名/密码认证(Basic, Digest, NTLM等)、下载文件断点续传,上载文件断点续传(file transfer resume),http代理服务器管道(proxy tunneling)以及其他特性。
libcurl
一个免费开源的,客户端url传输库,支持DICT, FILE, FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, Telnet and TFTP等协议。
支持SSL证书,HTTP POST, HTTP PUT,FTP上传,基于表单的HTTP上传,代理(proxies)、cookies、用户名/密码认证(Basic, Digest, NTLM等)、下载文件断点续传,上载文件断点续传(file transfer resume),http代理服务器管道(proxy tunneling)等。
高度可移植,可以工作在不同的平台上,支持Windows,Unix,Linux等。
免费的,线程安全的,IPV6兼容的,同事它还有很多其他非常丰富的特性。libcurl已经被很多知名的大企业以及应用程序所采用。
特点
curl和libcurl都可以利用多种多样的协议来传输文件,包括HTTP, HTTPS, FTP, FTPS, GOPHER, LDAP, DICT, TELNET and FILE等
支持SSL证书,HTTP POST, HTTP PUT,FTP上传,基于表单的HTTP上传,代理(proxies)、cookies、用户名/密码认证(Basic, Digest, NTLM等)、下载文件断点续传,上载文件断点续传(file transfer resume),http代理服务器管道(proxy tunneling)等。
libcurl是一个库,通常与别的程序绑定在一起使用,如命令行工具curl就是封装了libcurl库。所以我们也可以在你自己的程序或项目中使用libcurl以获得类似CURL的强大功能。
2 实现
在开始实现client发送http请求之前,我们先理解两个概念:
同步请求
当客户端向服务器发送同步请求时,服务处理在请求的过程中,客户端会处于等待的状态,一直等待服务器处理完成,客户端将服务端处理后的结果返回给调用方。
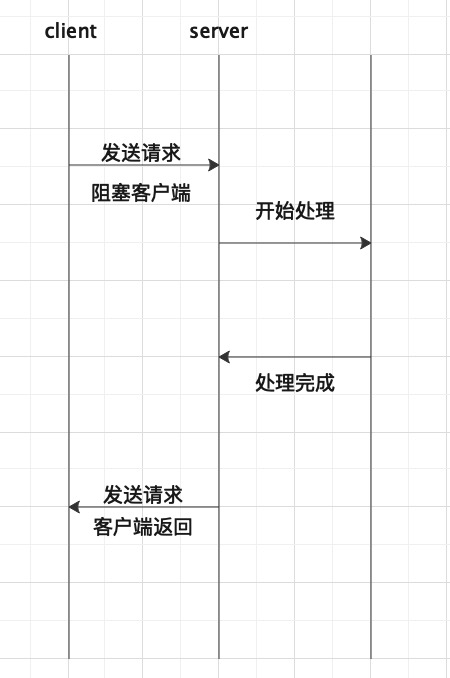
异步请求
客户端把请求发送给服务器之后,不会等待服务器返回,而是去做其他事情,待服务器处理完成之后,通知客户端该事件已经完成,客户端在获取到通知后,将服务器处理后的结果返回给调用方。
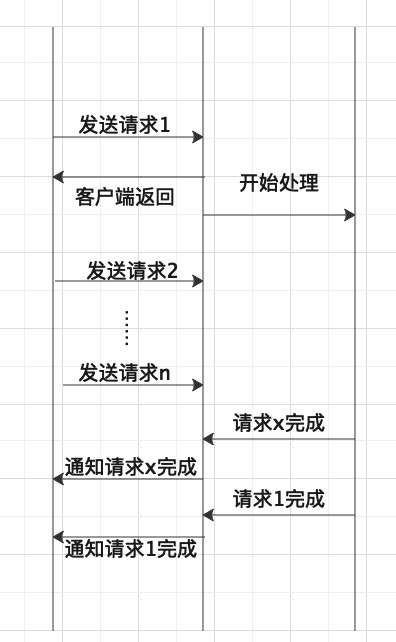
通过这俩概念,就能看出,异步在实现上,要比同步复杂的多。同步,即我们简单的等待处理结果,待处理结果完成之后,再返回调用方。而对于异步,往往在实现上,需要各种回调机制,各种通知机制,即在处理完成的时候,需要知道是哪个任务完成了,从而通知客户端去处理该任务完成后剩下的逻辑。
下面,我们将从代码实现的角度,来更深一步的理解libcurl在实现同步和异步请求操作上的区别,从而更近异步的了解同步和异步的实现原理图片。
同步
使用libcurl完成同步http请求,原理和代码都比较简单,主要是分位以下几个步骤:
1、初始化easy handle
2、在该easy handle上设置相关参数,在本例中主要有以下几个参数
CURLOPT_URL,即请求的url
CURLOPT_WRITEFUNCTION,即回调函数,将http server返回数据写入对应的地方
CURLOPT_FOLLOWLOCATION,是否获取302跳转后的内容
CURLOPT_POSTFIELDSIZE,此次发送的数据大小
CURLOPT_POSTFIELDS,此次发送的数据内容
更多的参数设置,请参考libcurl官网
3、curl_easy_perform,调用该函数发送http请求,并同步等待返回结果
4、curl_easy_cleanup,释放步骤一中申请的easy handle资源
代码实现(easy_curl.cc)
#include <curl/curl.h>
#include <iostream>
#include <string>
std::string resp;
size_t WriteData(
char* buffer, size_t size,
size_t nmemb, void* userp) {
resp.append(buffer, size * nmemb);
return size * nmemb;
}
int main(void) {
CURLcode res;
CURL *curl = curl_easy_init();
std::string post = "abc";
if(curl) {
// 设置url
curl_easy_setopt(curl, CURLOPT_URL, "https://www.baidu.com");
// 设置回调函数,即当有返回的时候,调用回调函数WriteData
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteData);
// 抓取302跳转后d额内容
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION,1);
// 设置发送的内容大小
curl_easy_setopt(curl, CURLOPT_POSTFIELDSIZE, post.size());
// 设置发送的内容
curl_easy_setopt(curl, CURLOPT_POSTFIELDS, post.c_str());
// 开始执行http请求,此处是同步的,即等待http服务器响应
res = curl_easy_perform(curl);
/* Check for errors */
if(res != CURLE_OK)
fprintf(stderr, "curl_easy_perform() failed: %s\n",
curl_easy_strerror(res));
/* always cleanup */
curl_easy_cleanup(curl);
}
std::cout << resp << std::endl;
return 0;
}
编译
g++ --std=c++11 easy_curl.cc -I ../artifacts/include/ -L ../artifacts/lib -lcurl -o easy_curl
结果
<!DOCTYPE html>
<!--STATUS OK-->
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<meta content="always" name="referrer">
<script src="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/nocache/imgdata/seErrorRec.js"></script>
<title>页面不存在_百度搜索</title>
<style data-for="result">
body {color: #333; background: #fff; padding: 0; margin: 0; position: relative; min-width: 700px; font-family: arial; font-size: 12px }
p, form, ol, ul, li, dl, dt, dd, h3 {margin: 0; padding: 0; list-style: none }
input {padding-top: 0; padding-bottom: 0; -moz-box-sizing: border-box; -webkit-box-sizing: border-box; box-sizing: border-box } img {border: none; }
.logo {width: 117px; height: 38px; cursor: pointer }
#wrapper {_zoom: 1 }
#head {padding-left: 35px; margin-bottom: 20px; width: 900px }
...
异步
接触过网络编程的读者,都或多或少的了解多路复用的原理。IO多路复用在Linux下包括了三种,select、poll、epoll,抽象来看,他们功能是类似的,但具体细节各有不同:首先都会对一组文件描述符进行相关事件的注册,然后阻塞等待某些事件的发生或等待超时。
在使用Libcurl进行异步请求,从上层结构来看,简单来说,就是对easy handle 和 multi 接口的结合使用。其中,easy handle底层也是一个socket,multi接口,其底层实现也用的是epoll,那么我们如何使用easy handle和multi接口,来实现一个高性能的异步http 请求client呢?下面我们将使用代码的形式,使得读者能够进一步了解其实现机制。
multi 接口的使用是在easy 接口的基础之上,将easy handle放到一个队列中(multi handle),然后并发发送请求。与easy 接口相比,multi接口是一个异步的,非阻塞的传输方式。
- multi接口的使用,主要有以下几个步骤:
- curl_multi _init初始化一个multi handler对象
- 初始化多个easy handler对象,使用curl_easy_setopt进行相关设置
- 调用curl_multi _add_handle把easy handler添加到multi curl对象中
- 添加完毕后执行curl_multi_perform方法进行并发的访问
- 访问结束后curl_multi_remove_handle移除相关easy curl对象,先用curl_easy_cleanup清除easy handler对象,最后curl_multi_cleanup清除multi handler对象。
http_request.h
/*
该类是对easy handle的封装,主要做一些初始化操作,设置url 、发送的内容
header以及回调函数
*/
class HttpRequest {
public:
using FinishCallback = std::function<int()>;
HttpRequest(const std::string& url, const std::string& post_data) :
url_(url), post_data_(post_data) {
}
int Init(const std::vector<std::string> &headers);
CURL* GetHandle();
const std::string& Response();
void SetFinishCallback(const FinishCallback& cb);
int OnFinish(int response_ret);
CURLcode Perform();
void AddMultiHandle(CURLM* multi_handle);
void Clear(CURLM* multi_handle);
private:
void AppendData(char* buffer, size_t size, size_t nmemb);
static size_t WriteData(char *buffer, size_t size, size_t nmemb, void *userp);
std::string url_;
std::string post_data_;
CURL* handle_ = nullptr;
struct curl_slist *chunk_ = nullptr;
FinishCallback cb_;
int response_ret_;
};
http_request.cc
/*http_request.h的实现*/
int HttpRequest::Init(const std::vector<std::string> &headers) {
handle_ = curl_easy_init();
if (handle_ == nullptr) {
return kCurlEasyInitFailed;
}
CURLcode ret = curl_easy_setopt(handle_, CURLOPT_URL, url_.c_str());
if (ret != CURLE_OK) {
return ret;
}
ret = curl_easy_setopt(handle_, CURLOPT_WRITEFUNCTION,
&HttpRequest::WriteData);
if (ret != CURLE_OK) {
return ret;
}
ret = curl_easy_setopt(handle_, CURLOPT_WRITEDATA, this);
if (ret != CURLE_OK) {
return ret;
}
ret = curl_easy_setopt(handle_, CURLOPT_NOSIGNAL, 1);
if (ret != CURLE_OK) {
return ret;
}
ret = curl_easy_setopt(handle_, CURLOPT_PRIVATE, this);
if (ret != CURLE_OK) {
return ret;
}
ret = curl_easy_setopt(handle_, CURLOPT_POSTFIELDSIZE, post_data_.length());
if (ret != CURLE_OK) {
return ret;
}
ret = curl_easy_setopt(handle_, CURLOPT_POSTFIELDS, post_data_.c_str());
if (ret != CURLE_OK) {
return ret;
}
ret = curl_easy_setopt(handle_, CURLOPT_TIMEOUT_MS, 100);
if (ret != CURLE_OK) {
return ret;
}
// ret = curl_easy_setopt(handle_, CURLOPT_CONNECTTIMEOUT_MS, 10);
ret = curl_easy_setopt(handle_, CURLOPT_DNS_CACHE_TIMEOUT,
600);
if (ret != CURLE_OK) {
return ret;
}
chunk_ = curl_slist_append(chunk_, "Expect:");
for (auto item : headers) {
chunk_ = curl_slist_append(chunk_, item.c_str());
}
ret = curl_easy_setopt(handle_, CURLOPT_HTTPHEADER, chunk_);
if (ret != CURLE_OK) {
return ret;
}
// 设置http header
if (boost::algorithm::starts_with(url_, "https://")) {
curl_easy_setopt(handle_, CURLOPT_SSL_VERIFYPEER, false);
curl_easy_setopt(handle_, CURLOPT_SSL_VERIFYHOST, false);
}
return 0;
}
//获取easy handle
CURL* HttpRequest::GetHandle() {
return handle_;
}
// 获取http server端的响应
const std::string& HttpRequest::Response() {
return response_;
}
//设置回调函数,当server返回完成之后,调用
void HttpRequest::SetFinishCallback(const FinishCallback& cb) {
cb_ = cb;
}
// libcurl 错误码信息
int HttpRequest::OnFinish(int response_ret) {
response_ret_ = response_ret;
if (cb_) {
return cb_();
}
return -1;
}
// 执行http请求
CURLcode HttpRequest::Perform() {
CURLcode ret = curl_easy_perform(handle_);
return ret;
}
// 将easy handle 加入到被监控的multi handle
void HttpRequest::AddMultiHandle(CURLM* multi_handle) {
if (multi_handle != nullptr) {
curl_multi_add_handle(multi_handle, handle_);
}
}
// 释放资源
void HttpRequest::Clear(CURLM* multi_handle) {
curl_slist_free_all(chunk_);
if (multi_handle != nullptr) {
curl_multi_remove_handle(multi_handle, handle_);
}
curl_easy_cleanup(handle_);
}
// 获取返回
void HttpRequest::AppendData(char* buffer, size_t size, size_t nmemb) {
response_.append(buffer, size * nmemb);
}
// 回调函数,获取返回内容
size_t HttpRequest::WriteData(
char* buffer, size_t size,
size_t nmemb, void* userp) {
HttpRequest* req = static_cast<HttpRequest*>(userp);
req->AppendData(buffer, size, nmemb);
return size * nmemb;
}
main.cc
curl_global_init(CURL_GLOBAL_DEFAULT);
auto multi_handle_ = curl_multi_init();
int numfds = 0;
int running_handles = 0;
while (true) {
//此处读者来实现,基本功能如下:
// 1、获取上游的请求内容,从里面获取要发送http的相关信息
// 2、通过步骤1获取的相关信息,来创建HttpRequest对象
// 3、将该HttpRequest对象跟multi_handle_对象关联起来
curl_multi_perform(multi_handle_, &running_handles);
CURLMcode mc = curl_multi_wait(multi_handle_, nullptr, 0,
200, &numfds);
if (mc != CURLM_OK) {
std::cerr << "RequestDispatcher::Run"
<< " curl_multi_wait failed, ret: "
<< mc;
continue;
}
curl_multi_perform(multi_handle_, &running_handles);
CURLMsg* msg = nullptr;
int left = 0;
while ((msg = curl_multi_info_read(multi_handle_, &left))) {
// msg->msg will always equals to CURLMSG_DONE.
// CURLMSG_NONE and CURLMSG_LAST were not used.
if (msg->msg != CURLMSG_DONE) {
std::cerr << "RequestDispatcher::Run"
<< " curl_multi_info_read failed, msg: "
<< msg->msg;
continue;
}
CURL* easy_handle = msg->easy_handle;
CURLcode curl_ret = msg->data.result;
int response_ret = kOk;
if (curl_ret != CURLE_OK) {
std::cerr << "RequestDispatcher::Run"
<< " msg->data.result != CURLE_OK, curl_ret: "
<< curl_ret;
response_ret = static_cast<int>(curl_ret);
}
int http_status_code = 0;
curl_ret = curl_easy_getinfo(easy_handle,
CURLINFO_RESPONSE_CODE, &http_status_code);
if (curl_ret != CURLE_OK) {
std::cerr << "RequestDispatcher::Run"
<< " curl_easy_getinfo failed, curl_ret="
<< curl_ret;
if (response_ret == kOk) {
response_ret = static_cast<int>(curl_ret);
}
}
if (http_status_code != 200) {
std::cerr << "RequestDispatcher::Run"
<< " http_status_code=" << http_status_code;
if (response_ret == kOk) {
response_ret = http_status_code;
}
}
HttpRequest* req = nullptr;
// In fact curl_easy_getinfo will
// always return CURLE_OK if CURLINFO_PRIVATE was set.
curl_ret = curl_easy_getinfo(easy_handle, CURLINFO_PRIVATE, &req);
if (curl_ret != CURLE_OK) {
std::cerr << "RequestDispatcher::Run"
<< " curl_easy_getinfo failed, curlf_ret="
<< curl_ret;
if (response_ret == kOk) {
response_ret = static_cast<int>(curl_ret);
}
}
if (req != nullptr) {
ret = req->OnFinish(response_ret);
}
}
}
至此,我们已经可以使用libcurl来实现并发发送http请求,当然这个只是一个简单异步实现功能,更多的功能,还需要读者去使用libcurl中的其他功能去实现,此处留给读者一个问题(这个问题,也是笔者项目中使用的一个功能,该项目已经线上稳定运行4年,日请求量在20E图片),业务需要,某一个请求需要并发发送给指定的几家,即该请求,需要并发发送给几个http server,在一个特定的超时时间内,获取这几个http server的返回内容,并进行处理,那么这种功能应该如何使用libcurl来实现呢?透露下,可以使用libcurl的另外一个参数CURLOPT_PRIVATE。
3 性能对比
至此,我们已经基本完成了高性能http 并发功能的设计,那么到底性能如何呢?笔者从 以下几个角度来做了测试:
1、串行发送同步请求
2、多线程情况下,发送同步请求(此处线程为4个,笔者测试的服务器为4C)
3、使用multi接口
4、使用multi接口,并复用其对应的easy handle
5、使用dns cache(对easy handle设置CURLOPT_DNS_CACHE_TIMEOUT),即不用每次都进行dns解析
| 方法 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|
| 串行同步 | 21.381 | 30.617 |
| 多线程同步 | 4.331 | 16.751 |
| multi接口 | 1.376 | 11.974 |
| multi接口 连接复用 | 0.352 | 0.748 |
| multi 接口使用dns cache | 0.381 | 0.731 |
4 一点心得
libcurl是一个高性能,较易用的HTTP client,在使用其直接,一定要对其接口功能进行详细的了解,否则很容易入坑,犹记得在18年中的时候,上线了某一个功能,会偶现coredump(在上线之前,也进行了大量的性能测试,都没有出现过一次coredump),为了分析这个原因,笔者将服务的代码一直精简精简,然后模拟测试,缩小coredump定位范围,最终发现,只有在超时的时候,才会导致coredump,这就说明了为什么测试环境没有coredump,而线上会产生coredump,这是因为线上的超时时间设置的是5ms,而测试环境超时时间是20ms,这就基本把原因定位到超时导致的coredump。
然后,分析libcurl源码,发送时一个libcurl的参数设置导致coredump,至此,笔者耗费了23个小时,问题才得以解决。
更多精彩内容,请移步
studyinfo.top
高并发HHTP实践的更多相关文章
- MySQL面试必考知识点:揭秘亿级高并发数据库调优与最佳实践法则
做业务,要懂基本的SQL语句: 做性能优化,要懂索引,懂引擎: 做分库分表,要懂主从,懂读写分离... 数据库的使用,是开发人员的基本功,对它掌握越清晰越深入,你能做的事情就越多. 今天我们用10分钟 ...
- 达达O2O后台架构演进实践:从0到4000高并发请求背后的努力
1.引言 达达创立于2014年5月,业务覆盖全国37个城市,拥有130万注册众包配送员,日均配送百万单,是全国领先的最后三公里物流配送平台. 达达的业务模式与滴滴以及Uber很相似,以众包的方式利 ...
- 一套高可用、易伸缩、高并发的IM群聊架构方案设计实践
本文原题为“一套高可用群聊消息系统实现”,由作者“于雨氏”授权整理和发布,内容有些许改动,作者博客地址:alexstocks.github.io.应作者要求,如需转载,请联系作者获得授权. 一.引言 ...
- [转]10分钟梳理MySQL知识点:揭秘亿级高并发数据库调优与最佳实践法则
转:https://mp.weixin.qq.com/s/RYIiHAHHStIMftQT6lQSgA 做业务,要懂基本的SQL语句: 做性能优化,要懂索引,懂引擎: 做分库分表,要懂主从,懂读写分离 ...
- 朱晔的互联网架构实践心得S2E6:浅谈高并发架构设计的16招
朱晔的互联网架构实践心得S2E6:浅谈高并发架构设计的16招 概览 标题中的高并发架构设计是指设计一套比较合适的架构来应对请求.并发量很大的系统,使系统的稳定性.响应时间符合预期并且能在极端的情况下自 ...
- 高并发IM系统架构优化实践
互联网+时代,消息量级的大幅上升,消息形式的多元化,给即时通讯云服务平台带来了非常大的挑战.高并发的IM系统背后究竟有着什么样的架构和特性? 以上内容由网易云信首席架构师内部分享材料整理而成 相关阅读 ...
- 心知天气数据API 产品的高并发实践
心知天气数据API 产品的高并发实践 心知天气作为国内领先的商业气象服务提供商,天气数据API 产品从公司创立以来就一直扮演着很重要的角色.2009 年API 产品初次上线,历经十年,我们不断用心迭代 ...
- MySQL在大数据、高并发场景下的SQL语句优化和"最佳实践"
本文主要针对中小型应用或网站,重点探讨日常程序开发中SQL语句的优化问题,所谓“大数据”.“高并发”仅针对中小型应用而言,专业的数据库运维大神请无视.以下实践为个人在实际开发工作中,针对相对“大数据” ...
- Nginx Ingress 高并发实践
概述 Nginx Ingress Controller 基于 Nginx 实现了 Kubernetes Ingress API,Nginx 是公认的高性能网关,但如果不对其进行一些参数调优,就不能充分 ...
随机推荐
- 深入刨析tomcat 之---第6篇 how tomcat works 第5章 容器实现原理
writedby 张艳涛
- Linux下MySQL基础及操作语法
什么是MySQL? MySQL是一种开源关系数据库管理系统(RDBMS),它使用最常用的数据库管理语言-结构化查询语言(SQL)进行数据库管理.MySQL是开源的,因此任何人都可以根据通用公共许可证下 ...
- Apache httpd的web服务
Apache httpd的web服务 适用于Unix/Linux下的web服务器软件 Apache httpd(开源且免费),虚拟主机,支持HTTPS协议,支持用户认证,支持单个目录的访问控制,支持U ...
- C作用域
任何一种编程中,作用域是程序中定义的变量所存在的区域,超过该区域变量就不能被访问.C 语言中有三个地方可以声明变量: 在函数或块内部的局部变量 在所有函数外部的全局变量 在形式参数的函数参数定义中 局 ...
- 冲击BATZ!GitHub近8.3K+的Android进阶指南,面试再也不愁了
过去十年是移动互联网蓬勃发展的黄金期,相信每个人也都享受到了移动互联网红利,在此期间,移动互联网经历了曙光期.成长期.成熟期.现在来说已经进入饱和期. 依然记得在 2010-2013 年期间,从事移动 ...
- C++实现链表的相关基础操作
链表的相关基础操作 # include <iostream> using namespace std; typedef struct LNode { int data; //结点的数据域 ...
- Java代码搭建Dubbo+ZooKeeper 的示例
.personSunflowerP { background: rgba(51, 153, 0, 0.66); border-bottom: 1px solid rgba(0, 102, 0, 1); ...
- Linux进程理解与实践(三)进程终止函数和exec函数族的使用
进程的几种终止方式(Termination) (1)正常退出 从main函数返回[return] 调用exit 调用_exit或者_Exit 最后一个线程从其启动处返回 从最后一个线程调用pthrea ...
- WPF 线程开启等待动画
public static Dictionary<string, object> Dic = new Dictionary<string, object>();//定义一个字典 ...
- 1056 Mice and Rice (25分)队列
1.27刷题2 Mice and Rice is the name of a programming contest in which each programmer must write a pie ...