12Java进阶-IO与XML
1.File
File:java.io.File:代表一个实际的文件或目录。
常用构造方法File file = new File("path");
其它构造方法:
- File(String parent, String child):创建一个新的 File 实例,该实例的存放路径是由 parent 和 child 拼接而成的。
- File(File parent, String child):创建一个新的 File 实例。 parent 代表目录, child 代表文件名,因此该实例的存放路径是 parent 目录中的 child 文件。
- File(URI uri):创建一个新的 File 实例,该实例的存放路径是由 URI 类型的参数指定的。
构造File时,路径需要符合操作系统的命名规则。
路径分隔符File.pathSeperator:在windows中是“;”,在Linux中是":"
路径分隔符File.pathSeperatorChar:在windows中是’;‘,在Linux中是':'
层次路径分隔符File.seperator:在windows中是"\",在Linux中是"/"
层次路径分隔符File.seperatorChar:在windows中是’\‘,在Linux中是’/’
File常用方法:
File.listRoots():列出根目录
file.exists():文件是否存在
fie.isDirectory():文件是否是目录
String[] list():返回一个字符串数组,这些字符串代表此抽象路径名表示的目录中的文件和目录。
String[] list(FilenameFilter filter):返回一个字符串数组,这些字符串代表此抽象路径名表示的目录中,满足过滤器 filter 要求的文件和目录。
File[] listFiles():返回一个 File 对象数组,表示此当前 File 对象中的文件和目录。
File[] listFiles(FilenameFilter filter):返回一个 File 对象数组,表示当前 File 对象中满足过滤器 filter 要求的文件和目录。
2.IO流
抽象输入字节流接口:InputStream 抽象输出字节流接口:OutputStream
常见的输入流:new Scanner(System.in) 常见的输出流:System.out.print();
按照传输的单位分为:字节流和字符流。
字节流通常用来处理二进制文件,如音乐、图片文件等,并且由于字节是任何数据都支持的数据类型,因此字节流实际可以处理任意类型的数据。而对于字符流,因为 Java 采用 Unicode 编码,Java 字符流处理的即 Unicode 字符,所以在操作文字、国际化等方面,字符流具有优势。
- FileInputStream:把一个文件作为输入源,从本地文件系统中读取数据字节,实现对文件的读取操作。
- ByteArrayInputStream:把内存中的一个缓冲区作为输入源,从内存数组中读取数据字节。
- ObjectInputStream:对以前使用 ObjectOutputStream 写入的基本数据和对象进行反序列化,用于恢复那些以前序列化的对象,注意这个对象所属的类必须实现 Serializable 接口。
- PipedInputStream:实现了管道的概念,从线程管道中读取数据字节。主要在线程中使用,用于两个线程间的通信。
- SequenceInputStream:其他输入流的逻辑串联。它从输入流的有序集合开始,并从第一个输入流开始读取,直至到达文件末尾,接着从第二个输入流读取,依次类推。
- System.in:从用户控制台读取数据字节,在 System 类中,in 是 InputStream 类型的静态成员变量。
InputStream常见方法:
int read():从输入流中读取数据的下一字节,返回 0 ~ 255 范围内的整型字节值;如果输入流中已无新的数据,则返回 -1。
int read(byte[] b):从输入流中读取一定数量的字节,并将其存储在字节数组 b 中,以整数形式返回实际读取的字节数(要么是字节数组的长度,要么小于字节数组的长度)。
int read(byte[] b, int off, int len):将输入流中最多 len 个数据字节读入字节数组 b 中,以整数形式返回实际读取的字节数,off 指数组 b 中将写入数据的初始偏移量。
void close():关闭此输入流,并释放与该流关联的所有系统资源。
int available():返回可以不受阻塞地从此输入流读取(或跳过)的估计字节数。
void mark(int readlimit):在此输入流中标记当前的位置。
void reset():将此输入流重新定位到上次 mark 的位置。
boolean markSupported():判断此输入流是否支持 mark() 和 reset() 方法。
long skip(long n):跳过并丢弃此输入流中数据的 n 字节。
字符的输入输出流:
抽象字符输入流:Reader 抽象字符输出流:Writer
- FileReader :与 FileInputStream 对应,从文件系统中读取字符序列。
- CharArrayReader :与 ByteArrayInputStream 对应,从字符数组中读取数据。
- PipedReader :与 PipedInputStream 对应,从线程管道中读取字符序列。
- StringReader :从字符串中读取字符序列。
字符输出流的常用方法:
Writer append(char c):将指定字符 c 追加到此 Writer,此处是追加,不是覆盖。
Writer append(CharSequence csq):将指定字符序列 csq 添加到此 Writer。
Writer append(CharSequence csq, int start, int end):将指定字符序列 csq 的子序列,追加到此 Writer。
void write(char[] cbuf):写入字符数组 cbuf。
void write (char[] cbuf, int off, int len):写入字符数组 cbuf 的某一部分。
void write(int c):写入单个字符 c。
void write(String str):写入字符串 str。
void write(String str, int off, int len):写入字符串 str 的某一部分。
void close():关闭当前流。
字节流、字符流都是无缓冲的输入、输出流,每次的读、写操作都会交给操作系统来处理。对系统的性能造成很大的影响,因为每次操作都可能引发磁盘硬件的读、写或网络的访问,这些磁盘硬件读、写和网络访问会占用大量系统资源,影响效率。
3.装饰器模式
通过方法,将对象进行包装。
比如FileOutputStream放在缓冲字节流BufferedOutputStream的构造方法中时,就变成了BufferedOutputStream。
再把BufferedOutputStream放在DataOutputStream的构造方法中,就变成了DataOutputStream。
虽然外观都是OutputStream,但是功能得到了增强,提供了更加丰富的API。
4.Buffered流
缓冲流的目的是让原字节流、字符流新增缓冲的功能。
- BufferedInputStream
- BufferedOutputStream
- BufferedReader
- BufferedWriter
5.字节流转换为字符流:
使用InputStreamReader将字节流转换成InputStreamReader对象,再通过字符流的构造函数转换成字符流。
Java没有提供字节流转换成字符流的方式,因为字节流是一个通用的流,而字符流只能传输文本类型的资源,但是传输效率较快。
6.Data流
DataStream允许流直接操作基本数据类型和字符串。常用的方法有
dos.writeUTF();
dos.writeInt();
dis.readUTF();
dis.readInt();
注意读取顺序要和写入顺序一致。
public static void main(String[] args) {
try {
DataOutputStream dos = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(new File("D:\\ideaproject\\Java02\\data.txt"))));
dos.writeUTF("this");
dos.writeUTF("is");
dos.writeInt(4);
dos.writeUTF("leellamarz");
dos.close();
DataInputStream dis = new DataInputStream(new BufferedInputStream(new FileInputStream(new File("D:\\ideaproject\\Java02\\data.txt"))));
String a = dis.readUTF();
String b = dis.readUTF();
int d = dis.readInt();
String c = dis.readUTF();
System.out.println(a+" "+b+" "+d+" "+c);
dis.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
7.XML
XML是可拓展标记语言,可以用来存储数据、系统配置、数据交换。
XML的标签可以自定义。
XML 文档总是以 XML 声明开始,即告知处理程序,本文档是一个 XML 文档。在 XML 声明中,通常包括版本、编码等信息,以 <? 开始,以 ?> 结尾。
<?xml version = "1.0" encoding="UTF-8"?>
XML 文档由元素组成,一个元素由一对标签来定义,包括开始和结束标签,以及其中的内容。元素之间可以嵌套(但不能交叉),也就是说元素的内容里还可以包含元素。
标签可以有属性(属性值要加引号)。属性是对标签的进一步描述和说明,一个标签可以有多个属性,每个属性都有自己的名字和值,属性是标签的一部分。
8.解析XML
解析XML的技术主要有:
- DOM 即org.w3c.dom,W3C 推荐的用于使用 DOM 解析 XML 文档的接口
- SAX 即org.xml.sax,用 SAX 解析 XML 文档的接口
DOM 把一个 XML 文档映射成一个分层对象模型,而这个层次的结构,是一棵根据 XML 文档生成的节点树。DOM 在对 XML 文档进行分析之后,不管这个文档有多简单或多复杂,其中的信息都会被转化成一棵对象节点树。在这棵节点树中,有一个根节点,其他所有的节点都是根节点的子节点。节点树生成之后,就可以通过 DOM 接口访问、修改、添加、删除树中的节点或内容了。
DOM解析过程:
- 通过getInstance()创建DocumentBuilderFactory,即解析器工厂
- 通过build()创建DocumentBuilder
- 解析文件得到Document对象
- 通过NodeList,开始解析结点(标签)
9.Node常用方法
NodeList getChildNodes():返回此节点的所有子节点的 NodeList。
Node getFirstChild():返回此节点的第一个子节点。
Node getLastChild():返回此节点的最后一个子节点。
Node getNextSibling():返回此节点之后的节点。
Node getPreviousSibling():返回此节点之前的节点。
Document getOwnerDocument():返回与此节点相关的 Document 对象。
Node getParentNode():返回此节点的父节点。
short getNodeType():返回此节点的类型。
String getNodeName():根据此节点类型,返回节点名称。
String getNodeValue():根据此节点类型,返回节点值。
String getTextContent():返回此节点的文本内容。
void setNodeValue(String nodeValue):根据此节点类型,设置节点值。
void setTextContent(String textContent):设置此节点的文本内容。
Node appendChild(Node newChild):将节点 newChild 添加到此节点的子节点列表的末尾。
Node insertBefore(Node newChild,Node refChild):在现有子节点 refChild 之前插入节点 newChild。
Node removeChild(Node oldChild):从子节点列表中移除 oldChild 所指示的子节点,并将其返回。
Node replaceChild(Node newChild, oldChild):将子节点列表中的子节点 oldChild 替换为 newChild,并返回 oldChild 节点。
10.Document常用方法
Element getDocumentElement():返回代表这个 DOM 树根节点的 Element 对象。
NodeList getElementsByTagName(String tagname):按文档顺序返回包含在文档中且具有给定标记名称的所有 Element 的 NodeList。
NodeList常用方法:
int getLength():返回有序集合中的节点数。
Node item(int index):返回有序集合中的第 index 个项。
11.SAX解析
SAX是事件驱动的。通过继承DefaultHandler类,重写五个关键方法实现解析。
startDocument():开始文档的标志
endDocument():结束文档的标志
startElement(String uri, String localName, String qName, Attributes attributes):通过比较localName,找到指定的元素,打开元素
endElement(String uri, String localName, String qName):通过比较localName,找到指定的元素,结束元素
characters(char[] ch, int start, int length):解析每个元素时调用的方法
@Override
public void startDocument() throws SAXException {
System.out.println("books2文档开始解析");
} @Override
public void endDocument() throws SAXException {
System.out.println("books2文档结束解析");
} @Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if (qName.equals("book")) {
for(int i=0;i<attributes.getLength();i++){
System.out.println("编号:"+attributes.getValue(i));
} }
this.tagName = qName;
} @Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if("book".equals(localName)){}
this.tagName = null;
} @Override
public void characters(char[] ch, int start, int length) throws SAXException {
if (this.tagName != null) {
String data = new String(ch, start, length);
if (this.tagName.equals("bookname")) {
System.out.println("书名:"+data);
}
if (this.tagName.equals("bookauthor")) {
System.out.println("作者:"+data);
} if (this.tagName.equals("bookprice")) {
System.out.println("价格:"+data);
} }
}
12.练习

如果子类异常块放在父类异常块后面,就会报编译错误。
try {
int[] a = {1,2,3};
System.out.print(a[3]);
System.out.print(1);
} catch(Exception e) {
System.out.print(2);
System.exit(0);//2
} finally {
System.out.print(3);
}
不同于return,System.exit(0)的优先级高于finally,在前面遇到会直接退出程序。
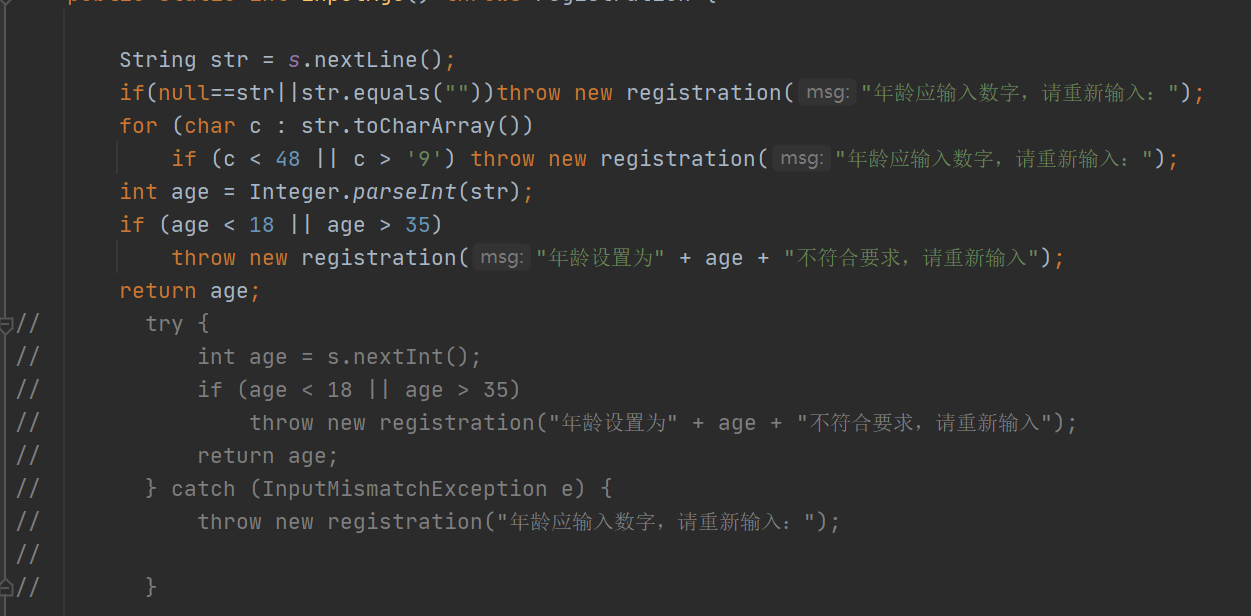
异常向外抛出,再被外部trycatch接受,会造成死循环
ArrayList<String> a = new ArrayList<String>();
a.add(true);
a.add(123);
a.add("abc");
System.out.print(a);
//执行后,控制台输出为?编译错误
//集合定义时加了泛型后,就不能添加不匹配泛型的元素。
List a = new ArrayList();
a.add(1);
a.add(2);
a.add(3);
a.remove(1);
System.out.print(a);
//执行后,控制台输出为? 1 3
//ArrayList 有 2 个删除方法:a.remove(Object o); 和 a.remove(int index); 那么这里的 1 到底是匹配 Object 还是 int 类型呢?我们考虑一下这两个方法的来历就行了。
//a.remove(Object o); 是父接口的方法,a.remove(int index); 是子类重写的方法,所以这里应该是调用子类重写的方法。
Set ts = new TreeSet();
ts.add("zs");
ts.add("ls");
ts.add("ww");
System.out.print(ts);
//执行后,控制台输出为?
//TreeSet 对于字符串来说默认按照字典升序进行排序,所以答案为:[ls, ww, zs]
//假设文件 c:/a.txt 的内容为 abc
//以下代码
try {
File f = new File("c:/a.txt");
System.out.print(f.length());
OutputStream out = new FileOutputStream(f);
System.out.print(f.length());
out.write(97);
System.out.print(f.length());
out.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//执行后,控制台输出为?301
File 对象 new 出来后,f.length() 返回值为 3。
FileOutputStream 对象 new 出来后,由于默认方法是覆盖已经存在的文件,所以f.length() 返回值为 0,如果想不覆盖,应该使用new FileOutputStream(f,false);。
out.write(97) 写入字母 a 后,f.lenght() 返回值为 1。
if(node2 instanceof Element){
String string = node2.getNodeName();
String ste = node2.getTextContent();
System.out.println(string+" "+ste);
}
出现这种问题的原因主要是使用org.w3c.dom.Node的进行解析的,它会将你的回车也作为一个节点。在你的代码中你打印str.getLenth();得到的数值肯定比你写的节点要多。
如果:node2 instanceof Text,则输出:#text
如果:node2 instanceof Element,则输出:标签名
或者将文件中多余的空格和回车都去掉。
12Java进阶-IO与XML的更多相关文章
- Java进阶 | IO流核心模块与基本原理
一.IO流与系统 IO技术在JDK中算是极其复杂的模块,其复杂的一个关键原因就是IO操作和系统内核的关联性,另外网络编程,文件管理都依赖IO技术,而且都是编程的难点,想要整体理解IO流,先从Linux ...
- Spring3.0 入门进阶(三):基于XML方式的AOP使用
AOP是一个比较通用的概念,主要关注的内容用一句话来说就是"如何使用一个对象代理另外一个对象",不同的框架会有不同的实现,Aspectj 是在编译期就绑定了代理对象与被代理对象的关 ...
- TestNG入门教程-12-Java代码执行testng.xml和失败后重跑
前面我们都在IDEA上右键testng.xml文件来运行testng用例,这个在编写测试用例过程是 可以这么做,但是,如果测试用例写完了,也是这么做吗?有没有什么方法,例如自动化去实现.测试脚本维护后 ...
- 09java进阶——IO
1.File类 1.1目录及路径分隔符 package cn.jxufe.java.chapter09.demo01; import java.io.File; public class Test01 ...
- 13Java进阶——IO、线程
1 字节缓冲流 BufferInputStream 将创建一个内部的缓冲区数组,内部缓冲区数组将根据需要从包含的输入流中重新填充,一次可以读取多个字节 BufferOutputStream 该类实现缓 ...
- IO redirect
在OS中,每启动一个进程,就自动的分配了三个流到进程中. [0:标准输入流,即键盘输入].[1:标准输出流,输出到显示器].[2:错误输出流,输出到显示器],其余的还未指定. 基本IO操作 cmd & ...
- Java对象转xml报文和xml报文转Java对象帮助类
import javax.xml.bind.JAXBContext; import javax.xml.bind.JAXBException; import javax.xml.bind.Marsha ...
- c# xml操作类
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Xm ...
- java学习之xml
xml的处理有两种方式dom和Sax 其中dom有3套api ,分别是dom和jdom和dom4j package com.gh.xml; import java.io.File; import ja ...
随机推荐
- NVIDIA Nsight Systems CUDA 跟踪
NVIDIA Nsight Systems CUDA 跟踪 CUDA跟踪 NVIDIA Nsight Systems能够捕获有关在概要过程中执行CUDA的信息. 可以在报告的时间轴上收集和呈现以下信息 ...
- 采用MVC模式创建一个简单的javascript App
初次翻译,翻译的不好,还请见谅 JavaScript中最好的一部分之一,也可能是最糟糕的. 在HTML文档的头部添加一个开始和结束脚本标记,并在其中引入一些意大利面条式的代码,毫无疑问这是一种过分简单 ...
- 性能监控工具之Grafana+Prometheus+Exporters
在本模块中,我将把几个常用的监控部分给梳理一下.前面我们提到过,在性能监控图谱中,有操作系统.应用服务器.中间件.队列.缓存.数据库.网络.前端.负载均衡.Web 服务器.存储.代码等很多需要监控的点 ...
- 已经安装好了tensorboardX,任然报错 No module named ‘tensorboardX‘ ??
问题: 1.在jupyter notebook网页版中已经使用命令pip install tensorboardX来安装tensorboardX包,但是运行程序时仍旧出现错误:No module na ...
- 一篇文章带你搞懂 etcd 3.5 的核心特性
作者 唐聪,腾讯云资深工程师,极客时间专栏<etcd实战课>作者,etcd活跃贡献者,主要负责腾讯云大规模k8s/etcd平台.有状态服务容器化.在离线混部等产品研发设计工作. etcd ...
- 液晶显示系列(2)之黑色背景的PPT更省电环保吗?常黑与常白型LCD
原文地址点击这里: 数年前听过一个培训师讲课,他的电脑课件PPT背景颜色是黑色的?美其名曰:黑色省电环保!当时讲台下听课的那些菜鸟们(也包括区区在下)深以为然,不由得心中竖起大拇指:这老师有水平,境界 ...
- unity 通过JsonUtility实现json数据的本地保存和读取
本文主要讲解json数据在本地的保存和读取,使用的是unity5之后提供的JsonUtility工具. 一.关于json数据的保存 在实际开发中,有时候可能涉及到大量数据保存到本地,以便于下次客户端的 ...
- 富文本编辑器之游戏角色升级ing
一.前言 想必大家看到这个标题,心中不禁会浮现几个问题: 什么是富文本编辑器? 富文本编辑器和游戏角色有什么关系? 为什么是升级ing? 什么是富文本编辑器--富文本编辑器集成了格式设置.媒体嵌入.社 ...
- 腾讯云TKE-基于 Cilium 统一混合云容器网络(下)
前言 在 腾讯云TKE - 基于 Cilium 统一混合云容器网络(上) 中,我们介绍 TKE 混合云的跨平面网络互通方案和 TKE 混合云 Overlay 网络方案.公有云 TKE 集群添加第三方 ...
- 企业该选择什么样的CRM系统
不论您是需要CRM系统来优化业务流程,还是准备更换一款新的CRM系统,在这之前都应该先明确企业的需求,并了解CRM的哪些功能能够对企业有所帮助.例如,企业的管理者想了解每个销售人员的业绩情况,那么就应 ...