kafka时间轮的原理(一)
概述
早就想写关于kafka时间轮的随笔了,奈何时间不够,技术感觉理解不到位,现在把我之前学习到的进行整理一下,以便于以后并不会忘却。kafka时间轮是一个时间延时调度的工具,学习它可以掌握更加灵活先进的定时器技术,补益多多。本文由浅到深进行讲解,先讲解定时器基础以及常用定时器,接着就是主要的kafka时间轮实现。大部分都是原理。后期作者写第二部分的时候专门讲解时间轮的实践和使用。
定时器概念
使用场景,例如:
1,使用tcp连接的时候,客户端需要向服务端发送心跳请求。
2,财务系统每月生成的定时账单。
3,双十一定时开启秒杀开关。
总而言之就是定时器的作用就是指定特定时刻执行任务,一般定时任务的形式表现为:经过固定时间后触发、按照固定频率周期性触发、在某个时刻触发。定时器是什么?可以理解为这样一个数据结构:
存储一系列任务的集合,并且deadline越接近的任务,拥有越高的执行优先级。
NewTask:将新任务加入任务集合
Cancel:取消某个任务 在任务调度的视角还要支持:
Run:执行一个到底的定时任务
判断一个任务是否到期,基本会采用轮询的方式,每隔一个时间片去检查最近的任务是否到期,并且,在 NewTask 和 Cancel 的行为发生之后,任务调度策略也会出现调整。这么说来定时器就是依靠线程轮询来实现的。
定时器几种数据结构
我们主要衡量 NewTask(新增任务),Cancel(取消任务),Run(执行到期的定时任务)这三个指标,分析他们使用不同数据结构的时间/空间复杂度。
双向有序链表
在 Java 中, LinkedList 是一个天然的双向链表。
NewTask:O(N)
Cancel:O(1)
Run:O(1)
N:任务数
NewTask O(N) 很容易理解,按照 expireTime 查找合适的位置即可;Cancel O(1) ,任务在 Cancel 时,会持有自己节点的引用,所以不需要查找其在链表中所在的位置,即可实现当前节点的删除,这也是为什么我们使用双向链表而不是普通链表的原因是 ;Run O(1),由于整个双向链表是基于 expireTime 有序的,所以调度器只需要轮询第一个任务即可。
堆
在 Java 中, PriorityQueue 是一个天然的堆,可以利用传入的 Comparator 来决定其中元素的优先级。
NewTask:O(logN)
Cancel:O(logN)
Run:O(1)
N:任务数
expireTime 是 Comparator 的对比参数。NewTask O(logN) 和 Cancel O(logN) 分别对应堆插入和删除元素的时间复杂度 ;Run O(1),由 expireTime 形成的小根堆,我们总能在堆顶找到最快的即将过期的任务。堆与双向有序链表相比,NewTask 和 Cancel 形成了 trade off,但考虑到现实中,定时任务取消的场景并不是很多,所以堆实现的定时器要比双向有序链表优秀。
时间轮
Netty 针对 I/O 超时调度的场景进行了优化,实现了 HashedWheelTimer 时间轮算法。
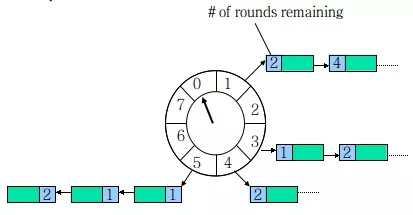
HashedWheelTimer 是一个环形结构,可以用时钟来类比,钟面上有很多 bucket ,每一个 bucket 上可以存放多个任务,使用一个 List 保存该时刻到期的所有任务,同时一个指针随着时间流逝一格一格转动,并执行对应 bucket 上所有到期的任务。任务通过 取模决定应该放入哪个 bucket 。和 HashMap 的原理类似,newTask 对应 put,使用 List 来解决 Hash 冲突。
以上图为例,假设一个 bucket 是 1 秒,则指针转动一轮表示的时间段为 8s,假设当前指针指向 0,此时需要调度一个 3s 后执行的任务,显然应该加入到 (0+3=3) 的方格中,指针再走 3 次就可以执行了;如果任务要在 10s 后执行,应该等指针走完一轮零 2 格再执行,因此应放入 2,同时将 round(1)保存到任务中。检查到期任务时只执行 round 为 0 的, bucket 上其他任务的 round 减 1。
再看图中的 bucket5,我们可以知道在 $18+5=13s$ 后,有两个任务需要执行,在 $28+5=21s$ 后有一个任务需要执行。
NewTask:O(1)
Cancel:O(1)
Run:O(M)
Tick:O(1)
M:bucket ,M ~ N/C ,其中 C 为单轮 bucket 数,Netty 中默认为 512
时间轮算法的复杂度可能表达有误,我个人觉得比较难算,仅供参考。另外,其复杂度还受到多个任务分配到同一个 bucket 的影响。并且多了一个转动指针的开销。传统定时器是面向任务的,时间轮定时器是面向 bucket 的。
构造 Netty 的 HashedWheelTimer 时有两个重要的参数: tickDuration 和 ticksPerWheel。
1,tickDuration:即一个 bucket 代表的时间,默认为 100ms,Netty 认为大多数场景下不需要修改这个参数;
2,ticksPerWheel:一轮含有多少个 bucket ,默认为 512 个,如果任务较多可以增大这个参数,降低任务分配到同一个 bucket 的概率。
层级时间轮
说道今天的重点了,Kafka 针对时间轮算法进行了优化,实现了层级时间轮 TimingWheel。先简单介绍一下,层级时间轮就是相当于时针分针秒针,秒针转动一圈,分针就走了一个bucket。层级适合时间跨度较大时存在明显优势。
如果任务的时间跨度很大,数量也多,传统的 HashedWheelTimer 会造成任务的 round 很大,单个 bucket 的任务 List 很长,并会维持很长一段时间。这时可将轮盘按时间粒度分级。下面会详细讲解kafka层级时间轮的原理。
KAFKA时间轮模式
“时间轮”的概念稍微有点抽象,我用一个生活中的例子,来帮助你建立一些初始印象。想想我们生活中的手表。手表由时针、分针和秒针组成,它们各自有独立的刻度,但又彼此相关:秒针转动一圈,分针会向前推进一格;分针转动一圈,时针会向前推进一格。这就是典型的分层时间轮。和手表不太一样的是,Kafka 自己有专门的术语。在 Kafka 中,手表中的“一格”叫“一个桶(Bucket)”,而“推进”对应于 Kafka 中的“滴答”,也就是 tick。后面你在阅读源码的时候,会频繁地看到 Bucket、tick 字眼,你可以把它们理解成手表刻度盘面上的“一格”和“向前推进”的意思。除此之外,每个 Bucket 下也不是白板一块,它实际上是一个双向循环链表(Doubly Linked Cyclic List),里面保存了一组延时请求。我先用一张图帮你理解下双向循环链表。
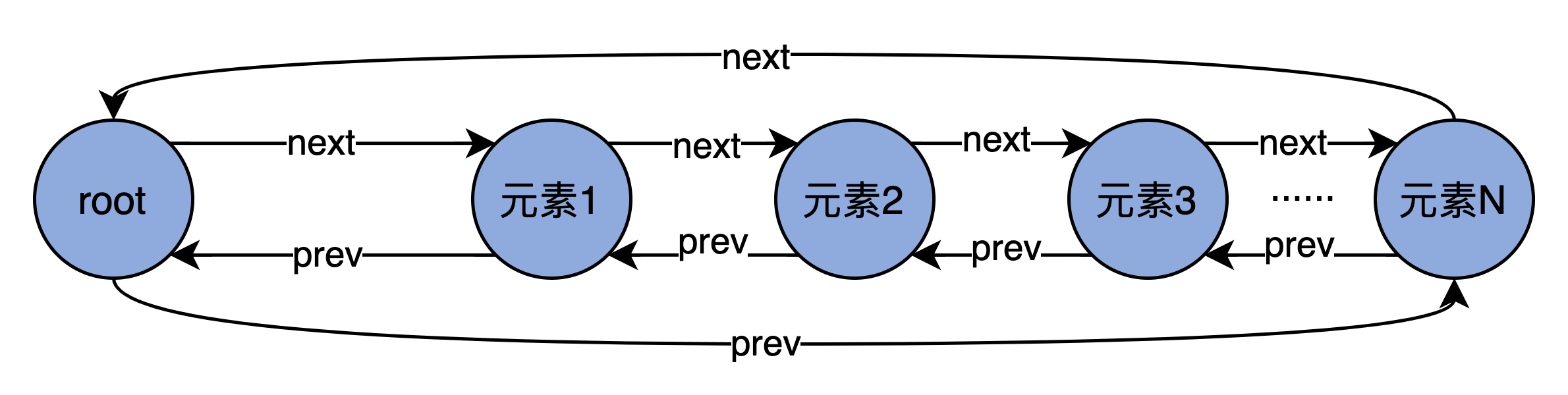
图中的每个节点都有一个 next 和 prev 指针,分别指向下一个元素和上一个元素。Root 是链表的头部节点,不包含任何实际数据。它的 next 指针指向链表的第一个元素,而 prev 指针指向最后一个元素。由于是双向链表结构,因此,代码能够利用 next 和 prev 两个指针快速地定位元素,因此,在 Bucket 下插入和删除一个元素的时间复杂度是 O(1)。当然,双向链表要求同时保存两个指针数据,在节省时间的同时消耗了更多的空间。在算法领域,这是典型的用空间去换时间的优化思想。
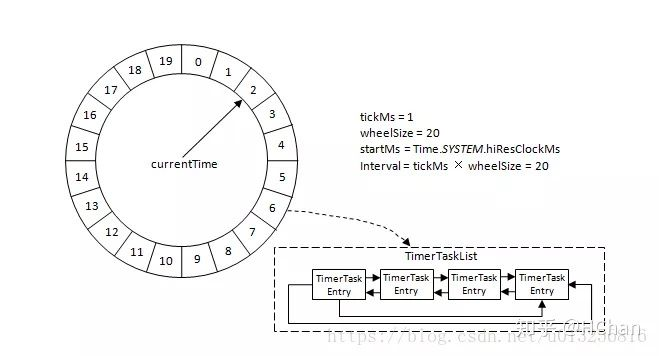
下图是比较容易理解的时间轮:Kafka中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务TimerTask。
在 Kafka 中,具体是怎么应用分层时间轮实现请求队列的呢?
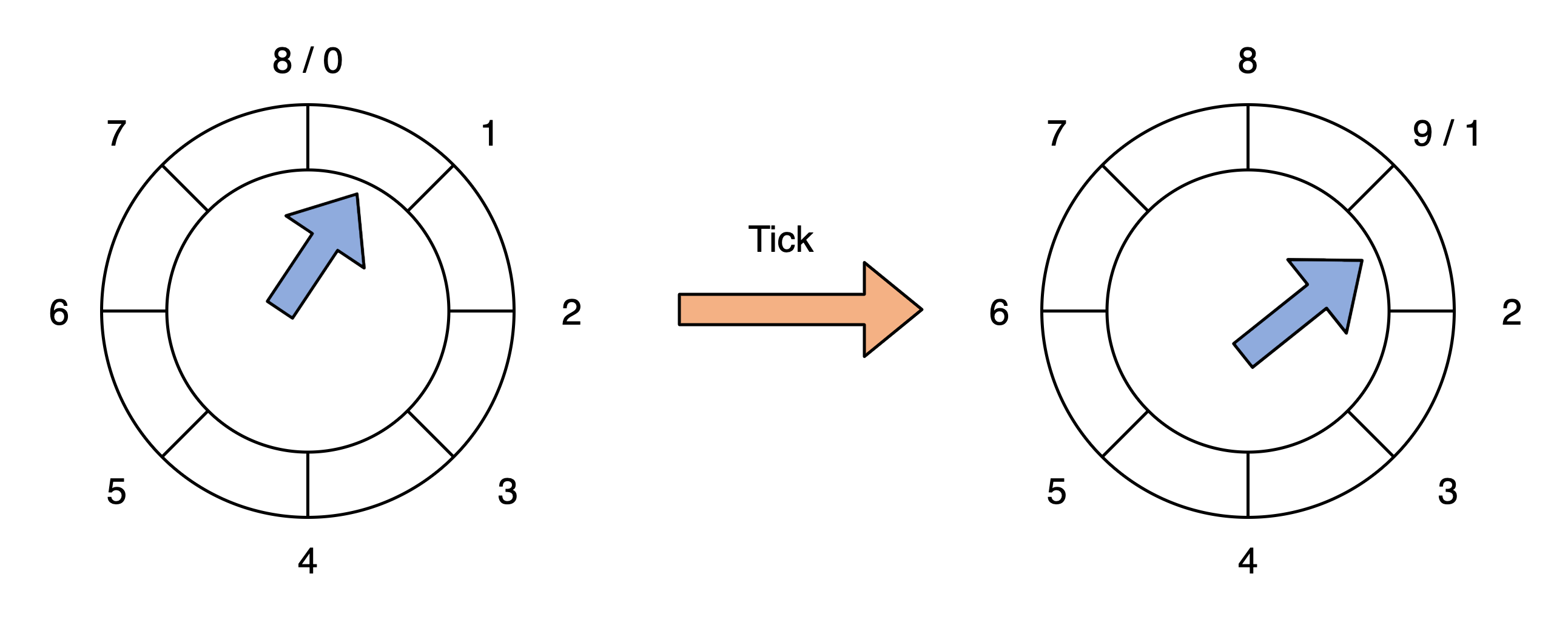
图中的时间轮共有两个层级,分别是 Level 0 和 Level 1。每个时间轮有 8 个 Bucket,每个 Bucket 下是一个双向循环链表,用来保存延迟请求。在 Kafka 源码中,时间轮对应 utils.timer 包下的 TimingWheel 类,每个 Bucket 下的链表对应 TimerTaskList 类,链表元素对应 TimerTaskEntry 类,而每个链表元素里面保存的延时任务对应 TimerTask。在这些类中,TimerTaskEntry 与 TimerTask 是 1 对 1 的关系,TimerTaskList 下包含多个 TimerTaskEntry,TimingWheel 包含多个 TimerTaskList。我画了一张 UML 图,帮助你理解这些类之间的对应关系。

KAFKA时间轮源码
TimerTask
所在文件:core/src/main/scala/kafka/utils/timer/TimerTask.scala
这个trait, 继承于 Runnable,需要放在时间轮里执行的任务都要继承这个TimerTask
每个TimerTask必须和一个TimerTaskEntry绑定,实现上放到时间轮里的是TimerTaskEntry
def cancel(): 取消当前的Task, 实际是解除在当前TaskEntry上的绑定
1 def cancel(): Unit = {
2 synchronized {
3 if (timerTaskEntry != null) timerTaskEntry.remove()
4 timerTaskEntry = null
5 }
6 }
TimerTaskEntry
所在文件:core/src/main/scala/kafka/utils/timer/TimerTaskList.scala
作用:绑定一个TimerTask对象,然后被加入到一个TimerTaskLIst中;
它是TimerTaskList这个双向列表 中的元素,因此有如下三个成员
1 var list: TimerTaskList = null //属于哪一个TimerTaskList
2 var next: TimerTaskEntry = null //指向其后一个元素
3 var prev: TimerTaskEntry = null //指向其前一个元素
TimerTaskEntry对象在构造成需要一个TimerTask对象,并且调用
1 timerTask.setTimerTaskEntry(this)
将TimerTask对象绑定到 TimerTaskEntry上 如果这个TimerTask对象之前已经绑定到了一个TimerTaskEntry上, 先调用timerTaskEntry.remove()解除绑定。 * def remove()
实际上就是把自己从当前所在TimerTaskList上摘掉, 为什么要使用一个while(...)来作,简单说就是相当于用个自旋锁代替读写锁来尽量保证这个remove的操作的彻底。
TimerTaskList
所在文件:core/src/main/scala/kafka/utils/timer/TimerTaskList.scala
作为时间轮上的一个bucket, 是一个有头指针的双向链表
双向链表结构:
1 private[this] val root = new TimerTaskEntry(null)
2 root.next = root
3 root.prev = root
继承于java的Delayed,说明这个对象应该是要被放入javar的DelayQueue,自然要实现下面的两个接口。
1 def getDelay(unit: TimeUnit): Long = {
2 unit.convert(max(getExpiration - SystemTime.milliseconds, 0), TimeUnit.MILLISECONDS)
3 }
4
5 def compareTo(d: Delayed): Int = {
6
7 val other = d.asInstanceOf[TimerTaskList]
8
9 if(getExpiration < other.getExpiration) -1
10 else if(getExpiration > other.getExpiration) 1
11 else 0
12 }
每个 TimerTaskList都是时间轮上的一个bucket,自然也要关联一个过期 时间:private[this] val expiration = new AtomicLong(-1L)
add和remove方法,用来添加和删除TimerTaskEntry
foreach方法:在链表的每个元素上应用给定的函数;
flush方法:在链表的每个元素上应用给定的函数,并清空整个链表, 同时超时时间也设置为-1;
TimingWheel
所在文件:core/src/main/scala/kafka/utils/timer/TimingWheel.scala
tickMs:表示一个槽所代表的时间范围,kafka的默认值的1ms
wheelSize:表示该时间轮有多少个槽,kafka的默认值是20
startMs:表示该时间轮的开始时间
taskCounter:表示该时间轮的任务总数
queue:是一个TimerTaskList的延迟队列。每个槽都有它一个对应的TimerTaskList,TimerTaskList是一个双向链表,有一个expireTime的值,这些TimerTaskList都被加到这个延迟队列中,expireTime最小的槽会排在队列的最前面。
interval:时间轮所能表示的时间跨度,也就是tickMs*wheelSize
buckets:表示TimerTaskList的数组,即各个槽。
currentTime:表示当前时间,也就是时间轮指针指向的时间
上面说了这么多,终于到这个时间轮出场了,说简单也简单,说复杂也复杂;
简言之,就是根据每个TimerTaskEntry的过期时间和当前时间轮的时间,选择一个合适的bucket(实际上就是TimerTaskList),这个桶的超时时间相同(会去余留整), 把这个TimerTaskEntry对象放进去,如果当前的bucket因超时被DelayQueue队列poll出来的话, 以为着这个bucket里面的都过期, 会调用这个bucket的flush方法, 将里面的entry都再次add一次,在这个add里因task已过期,将被立即提交执行,同时reset这个bucket的过期时间, 这样它就可以用来装入新的task了, 感谢我的同事"阔哥"的批评指正.
这个时间轮是支持层级的,就是如果当前放入的TimerTaskEntry的过期时间如果超出了当前层级时间轮的覆盖范围,那么就创始一个overflowWheel: TimingWheel,放进去,只不过这个新的时间轮的降低了很多,那的tick是老时间轮的interval(相当于老时间轮的tick * wheelSize), 基本可以类比成钟表的分针和时针;
def add(timerTaskEntry: TimerTaskEntry): Boolean: 将TimerTaskEntry加入适当的TimerTaskList;
def advanceClock(timeMs: Long)::推动时间轮向前走,更新CurrentTime
值得注意的是,这个类不是线程安全的,也就是说add方法和advanceClock的调用方式使用者要来保证;
关于这个层级时间轮的原理,源码里有详细的说明。
Timer
所在文件:core/src/main/scala/kafka/utils/timer/Timer.scala
上面讲了这么多,现在是时候把这些组装起来了,这就是个用TimingWheel实现的定时器,可以添加任务,任务可以取消,可以到期被执行;
构造一个TimingWheel。
1 private[this] val delayQueue = new DelayQueue[TimerTaskList]()
2 private[this] val taskCounter = new AtomicInteger(0)
3 private[this] val timingWheel = new TimingWheel(
4 tickMs = tickMs,
5 wheelSize = wheelSize,
6 startMs = startMs,
7 taskCounter = taskCounter,
8 delayQueue
9 )
taskExecutor: ExecutorService: 用于执行具体的task;
这个类为线程安全类,因为TimingWhell本身不是线程安全,所以对其操作需要加锁。
1 // Locks used to protect data structures while ticking
2 private[this] val readWriteLock = new ReentrantReadWriteLock()
3 private[this] val readLock = readWriteLock.readLock()
4 private[this] val writeLock = readWriteLock.writeLock()
def add(timerTask: TimerTask)::添加任务到定时器,通过调用def addTimerTaskEntry(timerTaskEntry: TimerTaskEntry):实现
1 if (!timingWheel.add(timerTaskEntry)) {
2 // Already expired or cancelled
3 if (!timerTaskEntry.cancelled)
4 taskExecutor.submit(timerTaskEntry.timerTask)
5 }
timingWheel.add(timerTaskEntry):如果任务已经过期或被取消,则return false; 过期的任务被提交到taskExcutor执行;
1 var bucket = delayQueue.poll(timeoutMs, TimeUnit.MILLISECONDS)
2 if (bucket != null) {
3 writeLock.lock()
4 try {
5 while (bucket != null) {
6 timingWheel.advanceClock(bucket.getExpiration())
7 bucket.flush(reinsert)
8 bucket = delayQueue.poll()
9 }
10 } finally {
11 writeLock.unlock()
12 }
13 true
14 } else {
15 false
16 }
delayQueue.poll(timeoutMs, TimeUnit.MILLISECONDS) 获取到期的bucket;
调用timingWheel.advanceClock(bucket.getExpiration())
bucket.flush(reinsert):对bucket中的每一个TimerEntry调用reinsert, 实际上是调用addTimerTaskEntry(timerTaskEntry), 此时到期的Task会被执行;
总结
感谢网络大神的分享:
https://zhuanlan.zhihu.com/p/51405974
https://mp.weixin.qq.com/s?__biz=MjM5NzMyMjAwMA==&mid=2651485083&idx=1&sn=089a76c2ccef0a98831a389fd7943d23&chksm=bd251fe48a5296f22df28cd53827eac4cb153855b70266ce753cdb0ee6d145782e5a664ebd9a&mpshare=1&scene=1&srcid=1004BPAgMnZs9xgVCwrXFMog&sharer_sharetime=1591491757235&sharer_shareid=d40e8d2bb00008844e69867bcfc0d895#rd
https://www.jianshu.com/p/0f0fec47a0ad
kafka时间轮的原理(一)的更多相关文章
- kafka时间轮简易实现(二)
概述 上一篇主要介绍了kafka时间轮源码和原理,这篇主要介绍一下kafka时间轮简单实现和使用kafka时间轮.如果要实现一个时间轮,就要了解他的数据结构和运行原理,上一篇随笔介绍了不同种类的数据结 ...
- Kafka中时间轮分析与Java实现
在Kafka中应用了大量的延迟操作但在Kafka中 并没用使用JDK自带的Timer或是DelayQueue用于延迟操作,而是使用自己开发的DelayedOperationPurgatory组件用于管 ...
- [从源码学设计]蚂蚁金服SOFARegistry之时间轮的使用
[从源码学设计]蚂蚁金服SOFARegistry之时间轮的使用 目录 [从源码学设计]蚂蚁金服SOFARegistry之时间轮的使用 0x00 摘要 0x01 业务领域 1.1 应用场景 0x02 定 ...
- 时间轮机制在Redisson分布式锁中的实际应用以及时间轮源码分析
本篇文章主要基于Redisson中实现的分布式锁机制继续进行展开,分析Redisson中的时间轮机制. 在前面分析的Redisson的分布式锁实现中,有一个Watch Dog机制来对锁键进行续约,代码 ...
- Redis之时间轮机制(五)
一.什么是时间轮 时间轮这个技术其实出来很久了,在kafka.zookeeper等技术中都有时间轮使用的方式. 时间轮是一种高效利用线程资源进行批量化调度的一种调度模型.把大批量的调度任务全部绑定到同 ...
- 经典多级时间轮定时器(C语言版)
经典多级时间轮定时器(C语言版) 文章目录 经典多级时间轮定时器(C语言版) 1. 序言 2. 多级时间轮实现框架 2.1 多级时间轮对象 2.2 时间轮对象 2.3 定时任务对象 2.4 双向链表 ...
- Rust 实现Netty HashedWheelTimer时间轮
目录 一.背景 二.延迟队列-时间轮 三.Netty 时间轮源码分析 四.Rust实现HashedWheelTimer 五.总结思考 一.背景 近期在内网上看到一篇文章,文中提到的场景是 系统自动取消 ...
- 时间轮算法在Netty和Kafka中的应用,为什么不用Timer、延时线程池?
大家好,我是yes. 最近看 Kafka 看到了时间轮算法,记得以前看 Netty 也看到过这玩意,没太过关注.今天就来看看时间轮到底是什么东西. 为什么要用时间轮算法来实现延迟操作? 延时操作 Ja ...
- Kafka解惑之时间轮 (TimingWheel)
Kafka中存在大量的延迟操作,比如延迟生产.延迟拉取以及延迟删除等.Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定 ...
随机推荐
- shell脚本 微信/钉钉验证登录服务器
一.简介 登录用户需要二次验证码进行验证 可以配合 监控用户登录,发送通知给企业微信/钉钉 来使用 脚本放到/etc/profile.d/ 目录,登录的时候自动触发 二.微信脚本 1.需要修改Crop ...
- SpringCloud微服务实战——搭建企业级开发框架(三十四):SpringCloud + Docker + k8s实现微服务集群打包部署-Maven打包配置
SpringCloud微服务包含多个SpringBoot可运行的应用程序,在单应用程序下,版本发布时的打包部署还相对简单,当有多个应用程序的微服务发布部署时,原先的单应用程序部署方式就会显得复杂且 ...
- CF355B Vasya and Public Transport 题解
Content 小 \(A\) 要乘坐交通工具,其中公交车的辆数是 \(n\),第 \(i\) 辆公交车的编号为 \(i\),乘坐次数为 \(a_i\):手推车的辆数是 \(m\),每辆手推车的编号为 ...
- java 网络编程基础 InetAddress类;URLDecoder和URLEncoder;URL和URLConnection;多线程下载文件示例
什么是IPV4,什么是IPV6: IPv4使用32个二进制位在网络上创建单个唯一地址.IPv4地址由四个数字表示,用点分隔.每个数字都是十进制(以10为基底)表示的八位二进制(以2为基底)数字,例如: ...
- java IO操作和计算操作:工作内存和主内存 volatile关键字作用;原子操作对象AtomicInteger ....
应该停止但无法停止的计算线程 如下线程示例,线程实例中while循环中的条件,在主线程中通过调用实例方法更新后,while循环并没有更新判断变量是否还成立.而是陷入了while(true)死循环. i ...
- python获取命令行传参的两种种常用方法argparse解析getopt 模块解析
方法一:argparse解析 #!/usr/bin/env python3 # -*- coding:utf-8 -*- # @Time: 2020/5/20 10:38 # @Author:zhan ...
- shell脚本报错:.sh: /bin/bash^M: 坏的解释器: 没有那个文件或目录
.sh: /bin/bash^M: 坏的解释器: 没有那个文件或目录 这是因为shell脚本是Windows下编辑的 格式不一样 执行 sed -i 's/\r$//' 脚本名称.sh
- JAVAWEB使用FreeMarker利用ftl把含有图片的word模板生成word文档,然后打包成压缩包进行下载
这是写的另一个导出word方法:https://www.cnblogs.com/pxblog/p/13072711.html 引入jar包,freemarker.jar.apache-ant-zip- ...
- 关于编写c++动态库常用的定义
1. 关于 1.1 最近一段时间,写了不少动态库,慢慢的也积累了东西. 1.2 之前一直做Windows的动态库,没有做过Linux和OS X的动态库,太缺乏经验了: 代码缺乏 编译器支持的判断.缺乏 ...
- 【LeetCode】163. Missing Ranges 解题报告 (C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 遍历 日期 题目地址:https://leetcode ...