值得收藏 | 深度剖析 TensorCore 卷积算子实现原理
作者:章晓 | 旷视 MegEngine 架构师
一、前言
2020 年 5 月 Nvidia 发布了新一代的 GPU 架构安培(Ampere)。其中和深度学习关系最密切的莫过于性能强劲的第三代的 TensorCore ,新一代的 TensorCore 支持了更为丰富的 DL(Deep Learning)数据类型,包括了新的 TesorFloat-32(TF32),Bfloat16(BF16)计算单元以及 INT8, INT4 和 INT1 的计算单元,这些计算单元为 DL 推理提供了全面的支持。为了发挥这些计算单元的能力,以往会由资深的 HPC 工程师手写 GPU 汇编实现的卷积、矩阵乘算子来挖掘硬件的能力。然而凭借人力手工优化算子的方式已经没有办法应对如此多的数据类型,因此对于 DL 应用的优化渐渐地越来越依赖一些自动化的工具,例如面向深度学习领域的编译器。在这样的趋势下, Nvidia 开发了线性代数模板库 CUTLASS ,抽象了一系列高性能的基本组件,可以用于生成各种数据类型,各种计算单元的卷积、矩阵乘算子。 MegEngine 在 CUTLASS 的基础上进行了二次开发,可以高效地开发新的高性能的算子,快速地迁移到新的 GPU 架构。在上一篇 文章 中,我们已经简单介绍了 MegEngine 的底层卷积算子实现的使用方法,而本文将会深入介绍 MegEngine CUDA 平台的底层卷积算子的实现原理,并将会对 Nvidia CUTLASS 的 Implicit GEMM 卷积 文档 进行解读和补充。
因此,读者在阅读本文之前必须要了解的 CUDA 知识有:
- 访问全局存储(Global Memory)时,同一 Warp 中的相邻线程访问连续的地址,访存请求会被合并,合并的访存能够最大化 Global Memory 的吞吐。
- 访问 Global Memory 时,尽可能使用最宽的数据类型(float4)进行访问,这样可以最大化访存指令的利用率。
- CUDA 的共享存储(Shared Memory)按照每 4Bytes 划分为一个 bank,共分为 32 个 bank。当同一 Warp 中的线程访问同一 bank 的不同地址时会发生冲突(bank conflict)。无 bank conflict 的访存模式才能最大化 Shared Memory 的吞吐。
- GPU 有显存(Global Memory)、L2、L1(Shared Memory)、寄存器 4 个层次的存储,直接访问显存的延迟很高,在优化 GEMM、Convolution 这样的计算密集型算子时,需要
- 通过 L1 和寄存器的缓存来减少 Global Memory 的访存请求。
- 通过大量的计算来隐藏不可避免的 Global Memory 访存延迟。
首先,我们需要了解 CUTLASS 引入的一些抽象概念
TileIterator: 用于访问存储中的一个Tile的数据。TileIterator实现了advance()方法,支持在Matrix,Tensor等数据类型上进行遍历。Fragment: 数组类型,用于存放TileIterator读取进来的数据。Fragment的数据通常存放在寄存器中。
然后我们简单回顾一下 CUTLASS 设计的高性能的 GEMM 算子的 Pipeline,按照 Pipeline 实现的算子能够在 CUDA 平台上达到 cublas 的 90% 以上的性能。下图演示了 CUTLASS 设计的 Pipeline 化的 GEMM 算子:
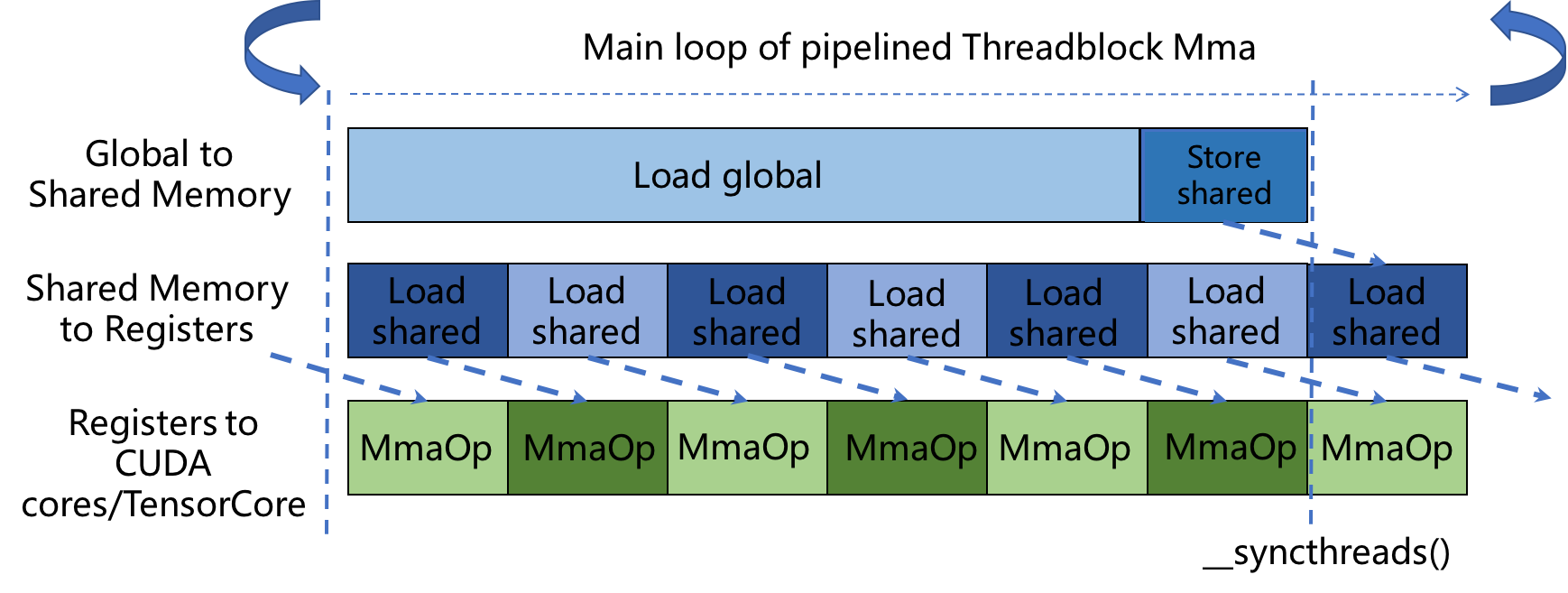
- 图中第一行演示了由
PredicatedTileIterator和SmemTileIterator配合完成从 Global Memory 到 Shared Memory 的数据搬运。 - 第二行演示了
WarpTileIterator负责从 Shared Memory 搬运数据到Fragment寄存器中。 - 第三行展示了
WarpMmaOperator用Fragment寄存器中的矩阵数据执行矩阵乘加 (Matrix-Multiply-Add) 操作。
二、Implicit GEMM 算法
卷积映射为矩阵乘法
我们首先来看一下前向卷积算子的定义,假设输入的 feature map 是 x,卷积层的 weight 是 w,输出是 y,其中 x,y,w 都是 4 维的 Tensor,x 的四个维度分别是 NxICxIHxIW,w 的四个维度分别是 OCxICxFHxFW,y 的四个维度分别是 NxOCxOHxOW。那么输出 y 和输入 x, w 的数学关系式可以写成
\]
公式里的小写字母代表了 Tensor 在每一维的坐标,其中 ih,iw 和 oh,ow,fh,fw 的关系式可以写为
ih = oh * stride_h - pad_h + fh
iw = ow * stride_w - pad_w + fw
这里的stride_h, stride_w, pad_h, pad_w是卷积层的参数。
根据 im2col 算法的原理,公式里定义的卷积运算可以转化为一个矩阵乘法,也即
C = Matmul(A, B)
其中
- 矩阵 A 由 weight 转化而来,是一个\(\text{OC}\times\text{IC}\cdot\text{FH}\cdot\text{FW}\)的矩阵。
- 矩阵 B 由 feature map 转化而来,是一个\(\text{IC}\cdot\text{FH}\cdot\text{FW}\times\text{N}\cdot\text{OH}\cdot\text{OW}\)的矩阵
- 矩阵 C 代表了输出的 Tensor y,是一个\(\text{OC}\times\text{N}\cdot\text{OH}\cdot\text{OW}\)的矩阵。
矩阵和 Tensor 在各个位置上的元素的对应关系为
\begin{aligned}
A_{ik} &= \text{w}\left(\text{oc}, \text{ic}, \text{fh}, \text{fw}\right) \\
\end{aligned}
\end{equation}
\]
\begin{aligned}
B_{kj} &= \text{x}\left(\text{n}, \text{ic}, \text{ih}, \text{iw}\right) \\
\end{aligned}
\end{equation}
\]
\begin{aligned}
C_{ij} &= \text{y}\left(\text{n}, \text{oc}, \text{oh}, \text{ow}\right)
\end{aligned}
\end{equation}
\]
其中矩阵的下标\(i, j, k\)和 Tensor 的坐标之间的关系为
i = oc
j = n * OH * OW + oh * OW + ow
k = ic * FH * FW + fh * FW + fw
当 \(j\) 已知时,可以用下面的关系式推算出 feature map 的坐标
n = j / (OH * OW)
j_res = j % (OH * OW)
oh = j_res / OW
ow = j_res % OW
当 \(k\) 已知时,可以推算出 weight 的坐标
ic = k / (FH * FW)
k_res = k % (FH * FW)
fh = k_res / FW
fw = k_res % FW
同时结合 oh, ow, fh, fw,就可以计算出 ih 和 iw。
根据上面的讨论,我们可以把卷积的运算过程,写成一个隐式矩阵乘法 (Implicit GEMM) 的形式:
GEMM_M = OC
GEMM_N = N * OH * OW
GEMM_K = IC * FH * FW
for i in range(GEMM_M):
oc = i
for j in range(GEMM_N):
accumulator = 0
n = j / (OH * OW)
j_res = j % (OH * OW)
oh = j_res / OW
ow = j_res % OW
for k in range(GEMM_K):
ic = k / (FH * FW)
k_res = k % (FH * FW)
fh = k_res / FW
fw = k_res % FW
ih = oh * stride_h - pad_h + fh
iw = ow * stride_w - pad_w + fw
accumulator = accumulator + x(n, ic, ih, iw) * w(oc, ic, fh, fw)
y(n, oc, oh, ow) = accumulator
上面的 Implicit GEMM 算法仍然是串行的形式,接下来我们要把它改造成 CUDA 上的并行算法。首先我们对整个计算任务进行分块,让每个线程块负责计算并输出大小为TILE_MxTILE_N的矩阵。于是算法变成了下面的形式:
for i_out in range(GEMM_M / TILE_M):
for j_out in range(GEMM_N / TILE_N):
ThreadblockConvolution(x, w, y)
def ThreadblockConvolution(x, w, y):
accumulate[TILE_M, TILE_N] = 0
for i_in in range(TILE_M):
oc = i_out * TILE_M + i_in
for j_in in range(TILE_N):
j = j_out * TILE_N + j_in
n = j / (OH * OW)
j_res = j % (OH * OW)
oh = j_res / OW
ow = j_res % OW
for k in range(GEMM_K):
ic = k / (FH * FW)
k_res = k % (FH * FW)
fh = k_res / FW
fw = k_res % FW
ih = oh * stride_h - pad_h + fh
iw = ow * stride_w - pad_w + fw
accumulator(i_in, j_in) = accumulator(i_in, j_in)
+ x(n, ic, ih, iw) * w(oc, ic, fh, fw)
y(n, oc, oh, ow) = accumulator(i_in, j_in)
为了提高访存的效率,我们可以在GEMM_K这一维上也进行分块,每次将TILE_MxTILE_K的矩阵 A 和TILE_KxTILE_N的矩阵 B 缓存到 Shared Memory 里,避免重复的 Global Memory 访存。于是,算法就变成了如下形式:
for i_out in range(GEMM_M / TILE_M):
for j_out in range(GEMM_N / TILE_N):
ThreadblockConvolution(x, w, y)
def ThreadblockConvolution(x, w, y):
accumulator[TILE_M, TILE_N] = 0
smem_A[TILE_M, TILE_K] = 0
smem_B[TILE_K, TILE_N] = 0
for i_in in range(TILE_M):
oc = i_out * TILE_M + i_in
for j_in in range(TILE_N):
j = j_out * TILE_N + j_in
n = j / (OH * OW)
j_res = j % (OH * OW)
oh = j_res / OW
ow = j_res % OW
for k_out in range(GEMM_K / TILE_K):
load_tile_to_smem(x, A_smem)
load_tile_to_smem(w, B_smem)
WarpGemm(A_smem, B_smem, accumulator)
y(n, oc, oh, ow) = accumulator(i_in, j_in)
def WarpGemm(A_smem, B_smem, accumulator):
for k_in in range(TILE_K):
accumulator(i_in, j_in) = accumulator(i_in, j_in)
+ A_smem(i_in, k_in) * B_smem(k_in, j_in)
因为我们可以直接复用 CUTLASS 里已经实现好了高性能的WarpMmaOperator,所以实现基于 Implicit GEMM 的卷积算子只需要
- 适配
DeviceConvolution、KernelConvolution和ThreadblockConvolution,支持传入 Tensor 类型和 Convolution Layer 的参数。 - 添加
PredicateTileIterator支持读取 Tensor 的一个 Tile 的数据到 Shared Memory 中,并隐式地将读入的数据组织成矩阵的形式。 - 算法的 main loop 中直接调用
WarpTileIterator从 Shared Memory 读取数据,然后由WarpGemmOperator完成 Warp-level 的 GEMM 运算。 EpilogueOperator适配卷积算子,将 Accumulator 的数据写回 Global Memory 的 Tensor 中。
接下来我们会以 INT8 数据类型的 TensorCore 卷积算子来介绍 MegEngine 底层的卷积实现,本文会重点介绍 2、3、4 是如何实现的,关于如何使用已经写好的卷积算子,可以参考之前的 文章。
Global Memory 数据布局(Layout)
为了最大化 TensorCore 类型的卷积算子的吞吐,MegEngine 使用了 128 位的 Global
Memory 访存指令,因此在访问 Tensor 的数据的时候要求地址满足 128 位对齐。MegEngine 使用了 NCHW32 的格式来存储 Tensor,NCHW32 格式的特点为:
- Tensor 的通道维度按照 32 个 channel 进行分组,每 32 个 channel 连续的存放在存储中。
- Tensor 的其余维度按照 W、H、C、N 的顺序地址变化由快到慢的存放在存储中。
由于采用了 32 个通道对齐的存储格式,因此卷积 layer 要求输入和输出 feature map 的通道数都是 32 的倍数。
预处理访存偏移量
MegEngine 的卷积实现在GEMM_K的维度上是按照\((\text{IC}/32)\cdot \text{FH}\cdot \text{FW}\cdot32\)的顺序累加,写成伪代码的形式如下:
kInterleaved = 32
for ic_out in range(IC//kInterleaved):
for fh in range(FH):
for fw in range(FW):
for ic_in in range(kInterleaved):
# do mma
......
如果写成一层循环,那么应该写成:
kInterleaved = 32
for k in range(GEMM_K):
chw = k // kInterleaved
ic_in = k % kInterleaved
ic_out = chw // (FH * FW)
chw_res = chw % (FH * FW)
fh = chw_res // FW
fw = chw_res % FW
pointer += ic_out * C_STRIDE + fh * H_STRIDE + fw * W_STRIDE
# do mma
......
可以看到在迭代过程中,如果直接计算指针的偏移量的话,会引入很多除法和求余运算。而在 CUDA 平台上,整数的除法和求余的开销是非常大的,因此我们将一些地址的偏移量在 host 端预先计算好,存到 kernel param 的 buffer 中,需要时从 constant memory 中直接读取地址,避免除法和求余运算。
对于每个线程来说,在主循环中指针移动的 offset 如下图所示:

如果地址的增量可以用delta来表示的话,那么delta是以FH*FW为周期的,即:
delta(step, TILE_K) = delta(step + (FH * FW), TILE_K)
因此我们只需要大约\(\text{O}\left(\text{FH}\cdot\text{FW}\right)\)的存储空间。其中地址偏移量的计算逻辑可以参考代码 conv2d_tile_iterator_nt_src_fprop_precomp.h。由于 kernel param buffer 的大小为 4KB,我们用了大约 3KB 来存储地址的增量,所以 MegEngine 的卷积实现要求 Convolution Layer 的FH*FW的大小不能太大,但是一般情况下,3x3, 5x5, 7x7 的卷积都可以处理。Nvidia 官方实现的迭代顺序与本文介绍的略有不同:
- 官方实现需要将
IC补齐为TILE_K的倍数,这样在通道数较小时会浪费一些计算量。 - 官方实现的线程块在访问输入 feature map 的时候地址的跨度比较大,降低了访存的局部性,对 cache 不够友好。
因此在性能方面,MegEngine 的实现会更有优势,而官方实现的优点是对 Convolution Layer 的参数没有太多限制,通用性更好。
Warp-level Mma(Matrix-multiply-add) 指令
cuda10.2 引入了新的 Warp-level 的mma和ldmatrix指令,用户可以通过mma指令使用 TensorCore 来进行高速的矩阵乘加运算,通过ldmatrix精细地控制 Warp 给 TensorCore 喂数据。其中mma指令的用法如下:
unsigned A, B; // input matrix fragment data
int C[2], D[2]; // accumulators
asm volatile(
"mma.sync.aligned.m8n8k16.rol.col.satfinite.s32.s8.s8.s32 {%0,$1}, {%2}, {%3}, {%4,%5};\n"
: "=r"(D[0]), "=r"(D[1])
: "r"(A), "r"(B), "r"(C[0]), "r"(C[1]));
这条指令的语义是由一个 Warp 的 32 个线程同步地完成 8x8x16 的矩阵乘加运算,它有三个输入操作数,其中参与矩阵乘法运算的分别是一个 8x16 的矩阵 A 和一个 16x8 的矩阵 B,这两个输入矩阵的数据分布在同一 Warp 的 32 个线程中。
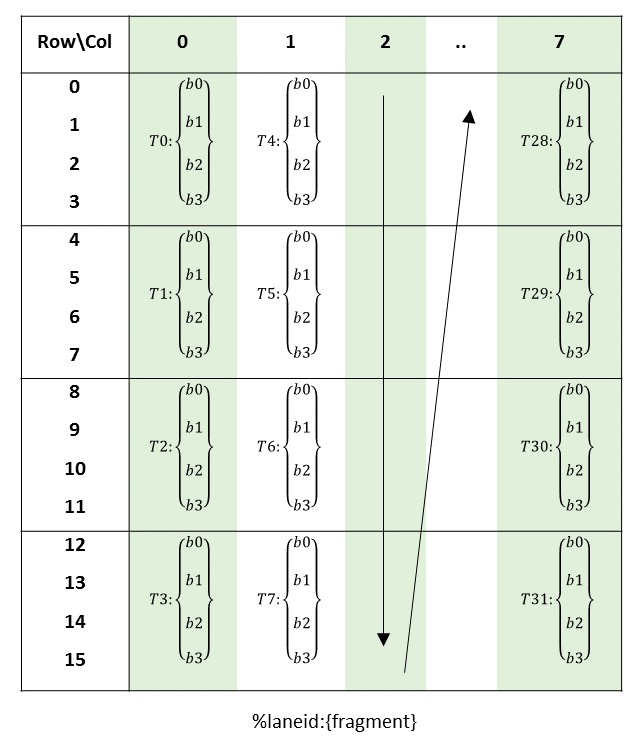
矩阵 A 的布局如下图所示:

- 同一 Warp 中的 32 个线程分为 8 组,每组四个线程,负责读取 8x16 的矩阵中的一行。
- 每一组中的一个线程读取每一行中相邻的 4 个 int8 的数据,恰好填满一个 32 位的寄存器。
类似的矩阵 B 的布局如下图所示:
- 每 4 个线程一组,共分为 8 组,每组负责读取 16x8 的矩阵中的一列。
- 每一组中的一个线程负责读取一列中相邻的 4 个数据。
参与累加运算的矩阵 C 和输出矩阵 D 的数据也同样分布在 32 个线程中,它们的布局如下图所示:
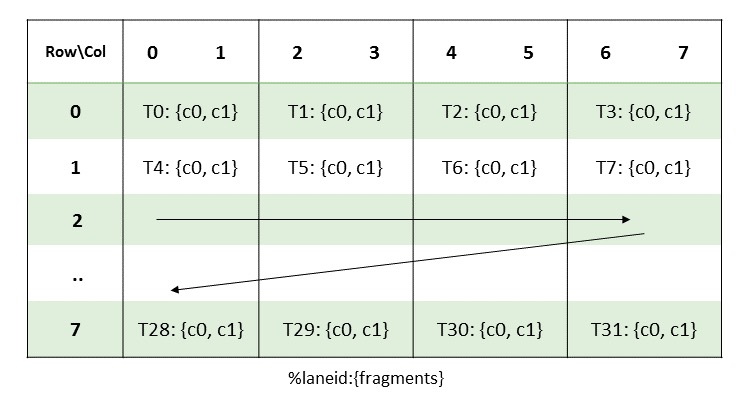
- 同样每 4 个线程一组,每组负责读入/输出一行的数据。
- 每个线程负责输出一行中的相邻两个 int32 类型的数据,恰好构成一个 64 位的寄存器。
通过对mma指令的分析,如果 Global Memory/Shared Memory 中的数据是以行优先 (RowMajor) 或者列优先 (ColumnMajor) 的格式存储的,那么当同一 Warp 执行空间上连续的两个 8x8x16 的矩阵乘加运算时,每个线程读取的数据将会是跳跃的,执行每次乘法都只能读取 32 位宽的数据到寄存器中,而低位宽的 Load 指令通常没有办法最大化利用存储的带宽。因此 Nvidia 提供了ldmatrix的指令,可以让同一 Warp 一次性读取 4 个 8x16 的矩阵到寄存器中,这样恰好可以让 Warp 中的每个线程一次读取 128 位的数据,最大化带宽的利用率。
ldmarix的用法如下所示:
unsigned addr; // shared memory pointer
int x, y, z, w; // loaded data
int4 data; // loaded fragment
asm volatile("ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];"
: "=r"(x), "=r"(y), "=r"(z), "=r"(w)
: "r"(addr));
data = make_int4(x, y, z, w);
上述这条指令恰好读取了 4 个 8x16 的矩阵,每个线程恰好负责读取矩阵的一行数据,读取完成后,线程之间会进行数据交换,将矩阵的数据重新分布到各个线程,读取的过程如下图所示:
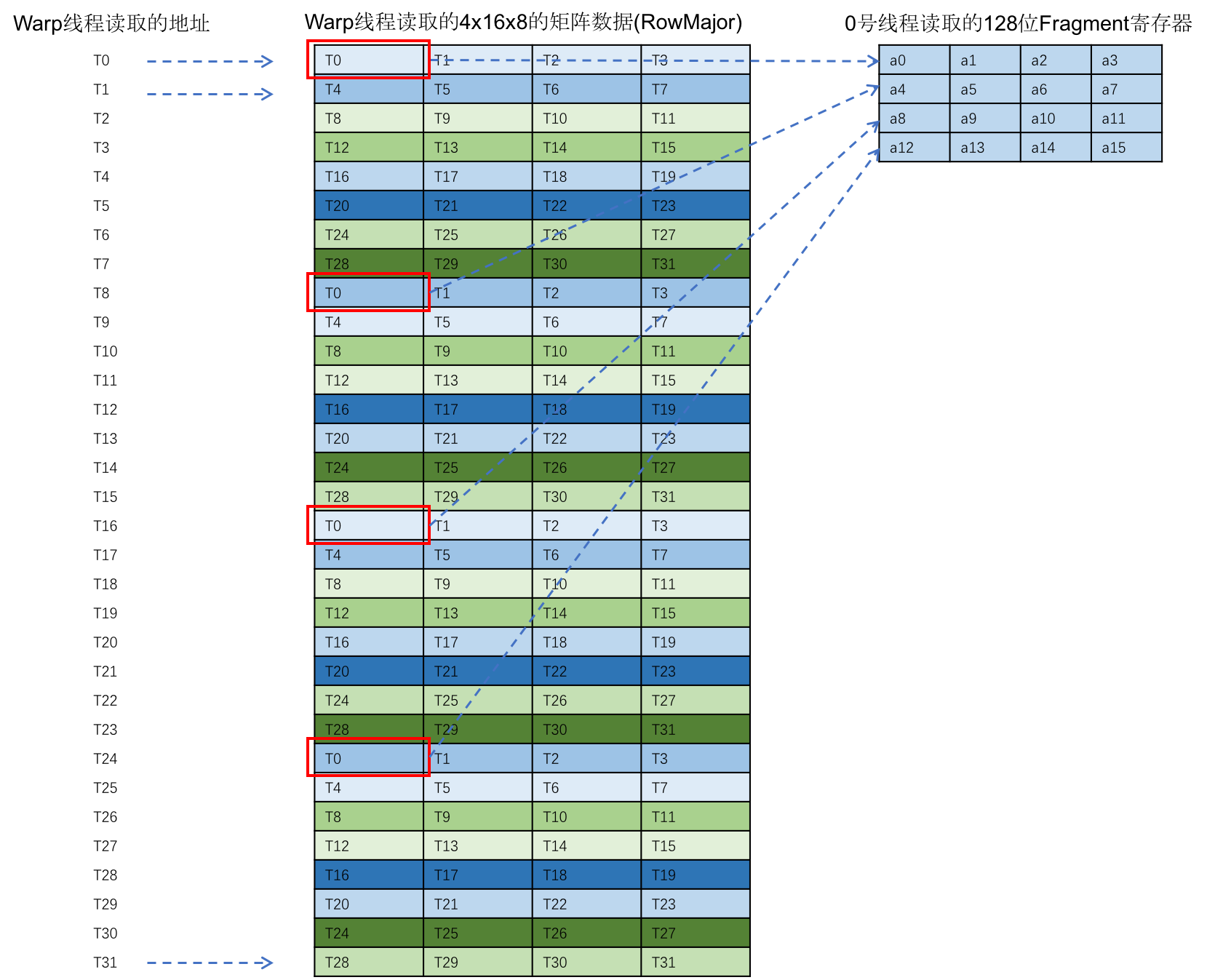
这一节介绍了 TensorCore 相关的mma和ldmatrix指令,有了这两条高性能的指令,我们还需要为数据设计巧妙的 Shared Memory 存储格式,消除从 Shared Memory 读取数据的 bank conflict,从而提升 Shared Memory 的读取效率。
Shared Memory 的数据布局
在介绍 Shared Memory 中的数据布局之前,我们需要了解 Shared Memory 的访存特点。Shared Memory 按照每 4 个字节组成一个 bank,共划分成了 32 个 bank,同一 Warp 的线程访问了相同 bank 的不同地址时会发生 conflict,导致访存的效率变慢。在同一 Warp 的线程访问不同位宽的数据时,会有不同的行为:
- 每个线程访问 Shared Memory 中 32 位的数据,访存将在一个阶段内完成。
- 每个线程访问 Shared Memory 中 64 位的数据,访存会在两个阶段内完成:
- 第一个阶段:前 16 个线程访存 128 字节的数据。
- 第二个阶段:后 16 个线程访存 128 字节的数据。
- 每个线程访问 Shared Memory 中的 128 位的数据,访存会在四个阶段内完成:
- 每个阶段由 8 个线程完成 128 字节的数据的访存。
如果上述过程中每个阶段都没有 bank conflict,则能够达到最大的 Shared Memory 访存效率。
通常为了避免 Shared Memory 的 bank conflict,我们会对 Shared Memory 的数据进行 padding,让线程访问的数据错开,避免落在同一 bank 中。但是这样做的问题是会使得 kernel 需要 Shared Memory 的 Size 变大,但是 SM 上的 L1 cache(Shared Memory) 又是有限的,所以 padding 会降低 kernel 的 occupancy,进而就会降低 kernel 的性能。
因此 CUTLASS 设计了一种 Shared Memory 的交错布局方式,它能够在不进行 padding 的前提下,使得线程访存的地址没有 bank conflict。接下来,我们以 64x64 的矩阵为例来详细介绍数据在 Shared Memory 中的布局。首先,线程读取数据的粒度都是 128 位,也即 16 个 INT8 类型的数据,因此我们在演示数据的布局时总是以 16 个数据为一组。如果矩阵是以行优先 (RowMajor) 的格式来组织的,那么在逻辑上的布局如下图所示:

从图中可以看到
- 每 16 个元素分为一组,被称为一个 Vector,被染上了不同的颜色。
- 每行相邻的 32 个元素被称为一个 Crosswise,恰好是 NCHW32 格式中的一组 channel 的数据。
在 Shared Memory 的物理存储中,矩阵的数据进行了重新排列,如下图所示:
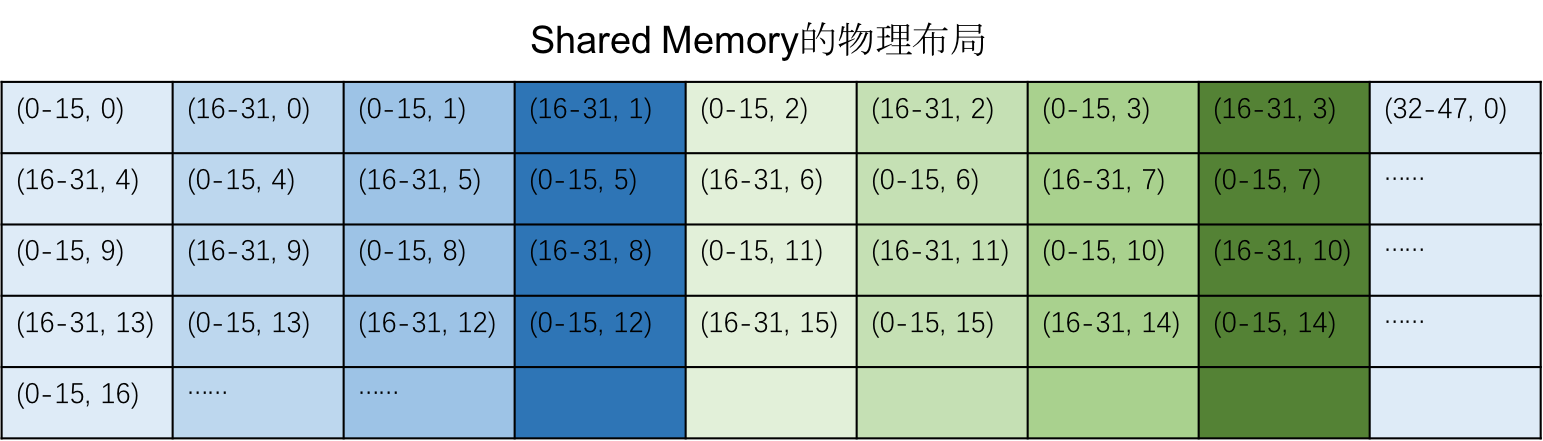
我们可以看到 Shared Memory 的物理布局有以下特点:
- 每 4 行的一个 Crosswise 的数据作为一组,连续存放在 Shared Memory 中,紧接着会存放这 4 行的下一个 Crosswise 的数据。
- 每组数据包含了 8 个 Vector,占据了 128 个字节,恰好是 Shared Memory 中的 32 个不同的 bank。
- 每组数据在排列是进行了交错,保证了
ldmatrix时不会发生 bank conflict。
显存 -> Shared Memory 的数据搬运
这一节我们会介绍从显存 (Global Memory) 到 Shared Memory 的数据搬运。显存到 Shared Memory 的数据搬运是由 Conv2dTileSrcIteratorFpropPrecomp 来完成的,本文并不会详细地解读代码的实现,而是描述线程搬运数据的过程,帮助大家建立直观的印象,更好地理解代码。
如果以上一节中 Shared Memory 的逻辑布局为例,同一 Warp 中每个线程读取的数据的逻辑布局如下图所示,每个线程读取 16 个 INT8 类型的数据,恰好构成一个 Vector。
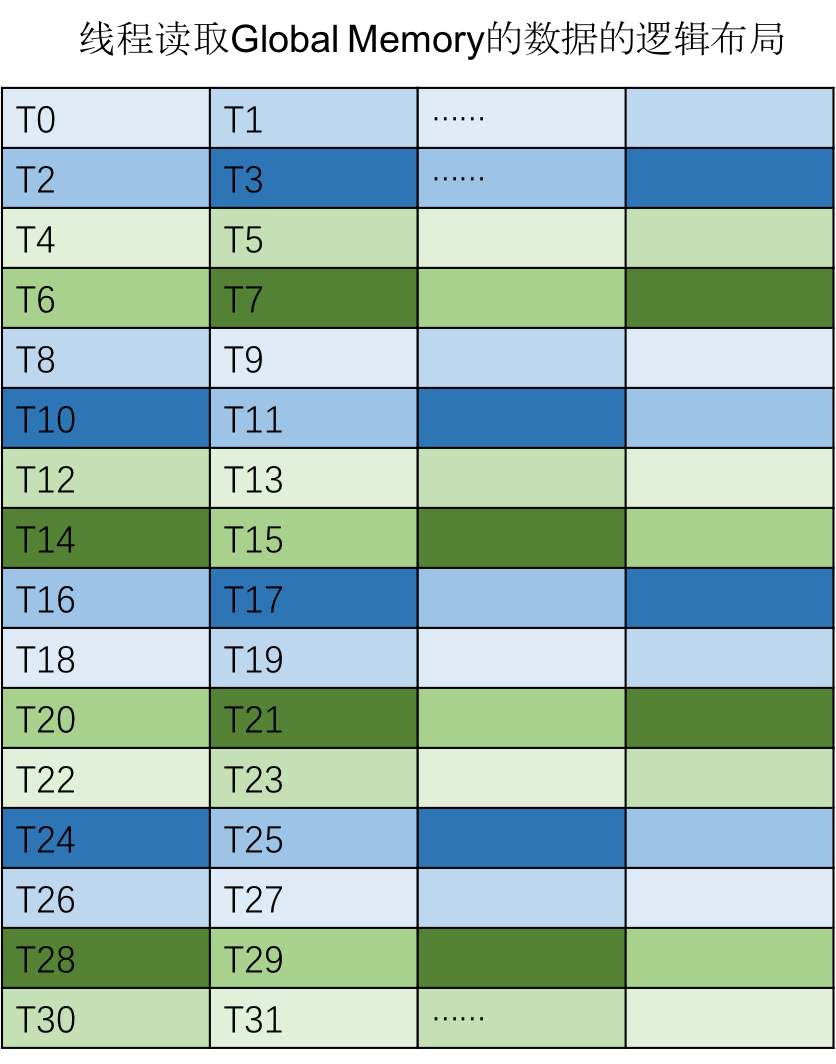
而在实际的物理显存中,线程访问的数据分布如下图所示:

- 我们可以看到每个线程读取了 128 位的数据。
- 相邻的线程读取的数据在物理上是连续的。
因此线程从 Global Memory 读取数据的 pattern 可以满足合并访存的要求,同时以最大的数据位宽进行访存,最大化了显存带宽的利用率。
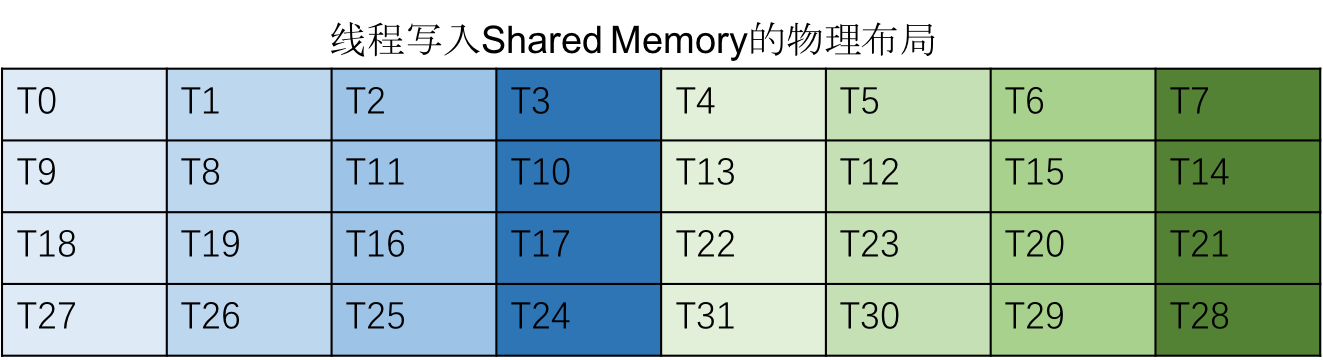
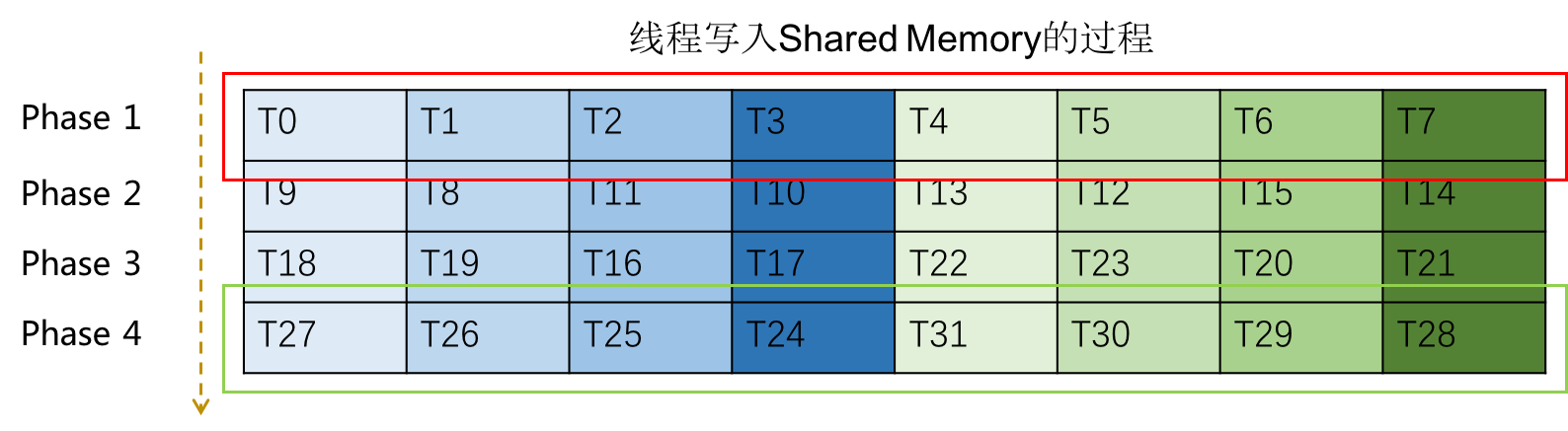
然后如果将线程读取的数据映射到 Shared Memory 的物理地址,我们可以看到
- 每 8 个线程向 Shared Memory 写入 128 字节的数据,恰好落在 Shared Memory 的 32 个不同的 bank 中。
- 同一 Warp 的访存分为四个阶段完成,每个阶段都没有 bank conflict。
下图演示了一个 Warp 写入 Shared Memory 的过程:
Shared Memory -> 寄存器的数据搬运
Shared Memory 到寄存器的数据搬运是由 MmaTensorOpMultiplicandTileIterator 完成的。同一 Warp 在每一轮迭代过程会读取 4 个 8x16 的矩阵到寄存器中,每个线程会读取一行的数据。例如第一轮迭代时,线程读取的数据在逻辑上的布局如下图所示:
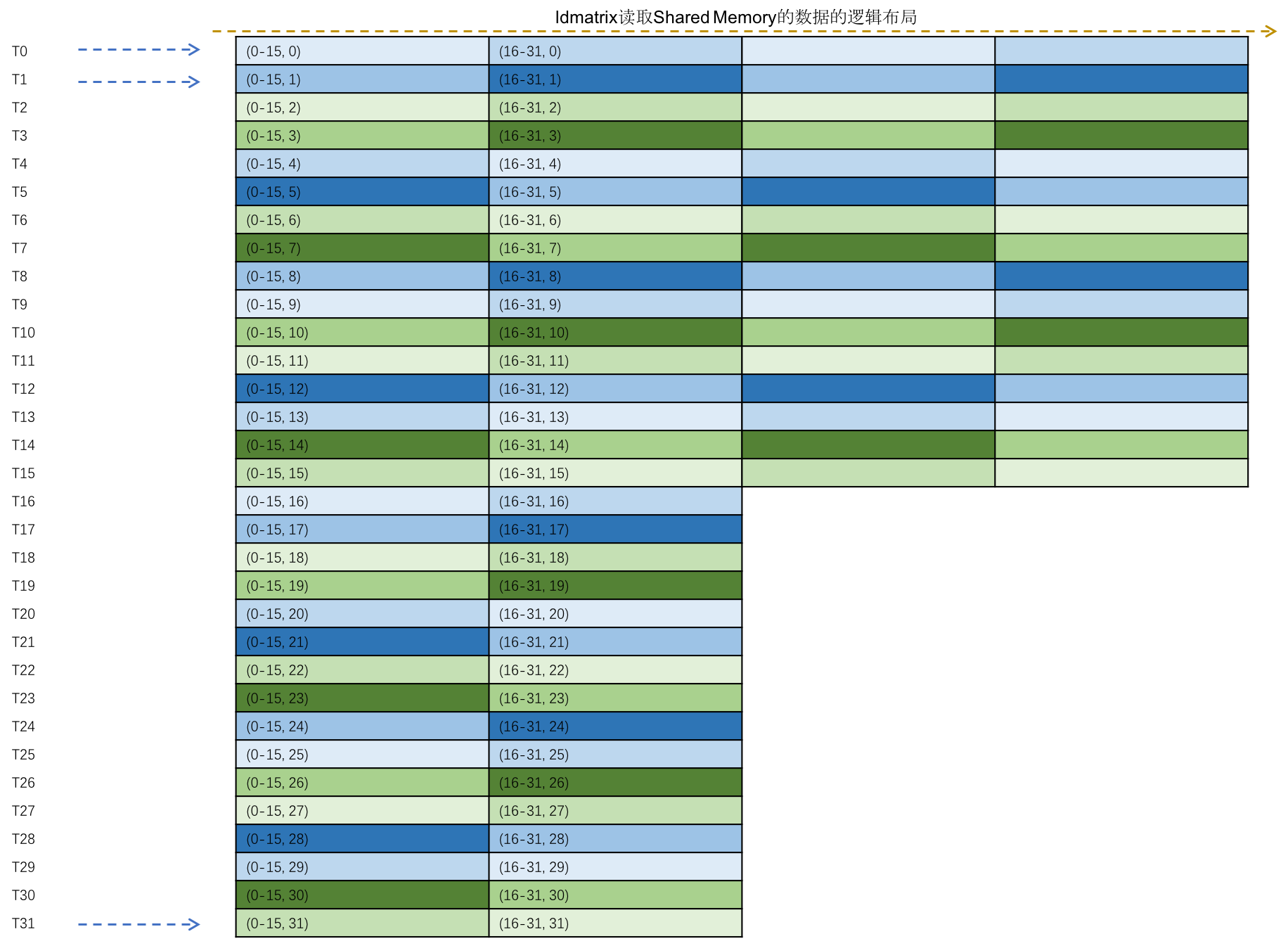
而实际上数据在 Shared Memory 里的物理布局如下图:
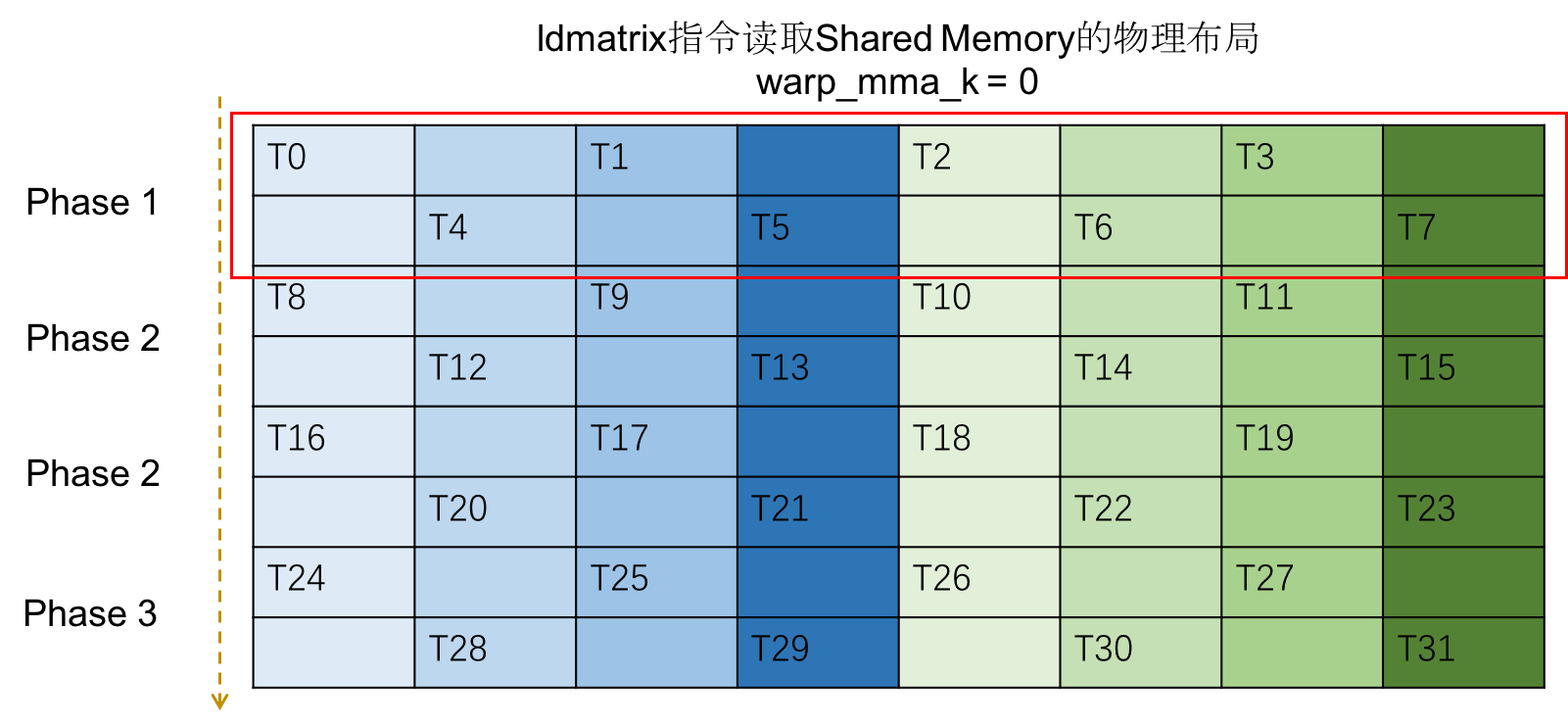
可以看到:
- 每个线程读取了 128 位的数据,因此访存分为四个阶段来进行。
- 每一阶段的 8 个线程读取的数据恰好落在了 Shared Memory 的 32 个 bank 中,并且线程访存的数据之间不存在冲突。
当进行到第二轮迭代时,每个线程访问的数据的物理布局如下图:
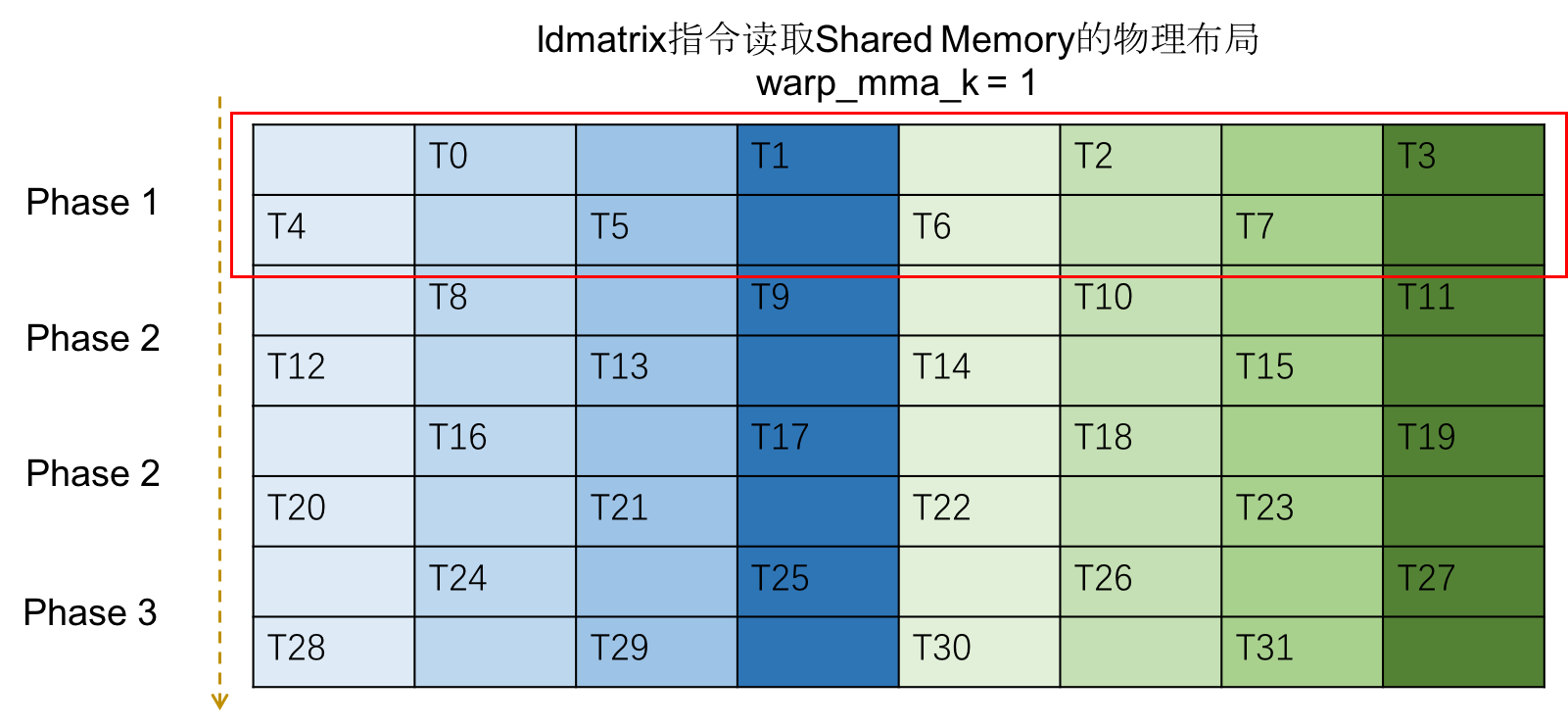
同样的访存的每一个阶段都不存在 bank conflict。
Accumulator 写回全局存储
在 int8 的情况下,同一 Warp 负责输出 64x64 的结果,kernel 会分成 8 次写回 Global Memory,每次写回 32x8 的矩阵。这样保证了每次将 Tensor 按照 NCHW32 格式写回显存时,同一 Warp 的 32 个线程恰好写了物理上连续的 256 字节的数据,而每个线程写回 8 个字节,保证了可以使用64位宽的数据类型进行显存的写操作,尽可能提高带宽的利用率。
由于mma指令的特点,输出矩阵的数据分布在各个线程上,而为了能够合并访存,即:让相邻线程写回的地址是连续的,我们利用 Shared Memory 对同一 Warp 中 32 个线程的数据进行了交换。数据交换后,每个线程拥有连续的 8 个通道的数据,且线程写的地址是连续的,保证了写回 Global Memory 满足合并访存的要求。
线程交换数据的过程如下图所示:

每一轮迭代,Warp 中的 32 个线程将 32x16 的矩阵数据写入到 Shared Memory 中。接着如下图所示,每个线程会把连续的 8 个 channel 的数据读到寄存器中。

Shared Memory 的数据交换是由以下两个Iterator完成的
- InterleavedTileIteratorTensorOp 完成了每一轮迭代将 32x8 的数据写入到 Shared Memory 中。
- InterleavedSharedLoadIteratorTensorOp 负责将连续的 8 个 channel 的数据读到
Fragment寄存器中。
当线程将交换后的数据读到Fragment寄存器之后,会由EpilogueOp,在卷积的基础上完成BiasAdd的运算。以 BiasAddLinearCombinationRelu 为例,它实际上完成了下面的运算:
accumulator = conv(x, w)
y = alpha * accumulator + beta * bias + gamma * z
其中 bias 是一个PerChannel的 Tensor,代表了每个输出通道的偏置,z 是一个和卷积输出大小一致的 Tensor,用于Convolution和ElemwiseAdd的融合。
最后EpilogueOp的输出会由 TensorPredicatedTileIteratorTensorOp 真正地写回到 Global Memory 中。每个线程写回的数据如下图所示:

可以看到线程写回的 pattern 满足合并访存的要求,因此能最大化 Global Memory 写的效率。
三、总结
本文介绍了 MegEngine 底层的卷积算子实现原理,算子性能可以达到cudnn的80%以上,测速结果可以参见文章。
MegEngine 会对卷积实现进行持续优化,进一步提升算子的性能,目前来看有以下两点可做的优化:
- 借鉴 Nvidia 官方 CUTLASS ImplicitGEMM Convolution 实现对 mask 的处理,提高
TileIterator对于 mask 判断的效率。 - 现在的卷积实现在写回显存时利用 Shared Memory 进行数据交换是存在 bank conflict 的。后续会考虑两点优化
- 对 Shared Memory 的数据布局进行探索,消除 bank conflict,优化 Shared Memory 数据交换的效率。
- 对 Global Memory 中的 Weight Tensor 的布局进行探索,提高每个 Thread 上 accumulator 的局部性,避免在 Shared Memory 中进行数据交换。
参考资料
- Warp-level Matrix Fragment Mma PTX 文档
- CUTLASS Implicit GEMM Convolution 官方文档
- Volta architecture and performance optimization
- Developing CUDA kernels to push Tensor Cores to the absolute limit on Nvidia A100
值得收藏 | 深度剖析 TensorCore 卷积算子实现原理的更多相关文章
- 深度剖析YOLO系列的原理
深度剖析YOLO系列的原理 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/12072225.html 目录 1. ...
- MegEngine TensorCore 卷积算子实现原理
作者:章晓 | 旷视 MegEngine 架构师 一.前言 2020 年 5 月 Nvidia 发布了新一代的 GPU 架构安培(Ampere).其中和深度学习关系最密切的莫过于性能强劲的第三代的 T ...
- 深度剖析Spark分布式执行原理
让代码分布式运行是所有分布式计算框架需要解决的最基本的问题. Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有很多,但是介绍Spark如 ...
- 宏旺半导体深度剖析嵌入式存储芯片eMMC原理 一篇概括大全
eMMC 一直是嵌入式存储市场最主流的选择,除了读写速度快.性价比高外,在节省空间方面也是相当优秀,今天宏旺半导体就和大家详细聊聊eMMC. eMMC 是 embedded MultiMediaCar ...
- C++11<functional>深度剖析:背景、原理、接口与实现
自C++11以来,C++标准每3年修订一次.C++14/17都可以说是更完整的C++11:即将到来的C++20也已经特性完整了. C++11已经有好几年了,它的年龄比我接触C++的时间要长10倍不止吧 ...
- 深度剖析各种BloomFilter的原理、改进、应用场景
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法.通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合. 一. 实例 为了说明B ...
- 深度剖析目标检测算法YOLOV4
深度剖析目标检测算法YOLOV4 目录 简述 yolo 的发展历程 介绍 yolov3 算法原理 介绍 yolov4 算法原理(相比于 yolov3,有哪些改进点) YOLOV4 源代码日志解读 yo ...
- Java反射机制剖析(四)-深度剖析动态代理原理及总结
动态代理类原理(示例代码参见java反射机制剖析(三)) a) 理解上面的动态代理示例流程 a) 理解上面的动态代理示例流程 b) 代理接口实现类源代码剖析 咱们一起来剖析一下代理实现类($Pr ...
- 深度剖析HashMap的数据存储实现原理(看完必懂篇)
深度剖析HashMap的数据存储实现原理(看完必懂篇) 具体的原理分析可以参考一下两篇文章,有透彻的分析! 参考资料: 1. https://www.jianshu.com/p/17177c12f84 ...
随机推荐
- Leetcode 递归题
24. 两两交换链表中的节点 题目描述: 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表. 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换. 示例: 给定 1->2-&g ...
- python使用笔记13--清理日志小练习
1 ''' 2 写一个删除日志的程序,删除5天前或为空的日志,不包括当天的 3 1.删除5天前的日志文件 4 2.删除为空的日志文件 5 ''' 6 import os 7 import time 8 ...
- CTF-safer-than-rot13-writeup
safer-than-rot13 题目信息 附件: cry100 XMVZGC RGC AMG RVMG HGFGMQYCD VT VWM BYNO, NSVWDS NSGO RAO XG UWFN ...
- android体温登记APP开发过程+问题汇总+源码
源码上传至https://github.com/durtime/myproject下的temperature 实际效果: 开发过程 1.首先进行布局文件的编写,布局前台页面 2.布置两个按钮,一个 ...
- GDB常用命令整理
(gdb) break xxx (gdb) b xxx 在源代码指定的某一行设置断点,其中 xxx 用于指定具体打断点的位置. (gdb) run (gdb) r 执行被调试的程序,其会自动在第一个断 ...
- python基础之面向对象OOP
#类(面向对象) PageObject设计模式 unittest 知识体系#函数式编程import datetimebook_info = { "title":"Pyth ...
- 「干货」面试官问我如何快速搜索10万个矩形?——我说RBush
「干货」面试官问我如何快速搜索10万个矩形?--我说RBUSH 前言 亲爱的coder们,我又来了,一个喜欢图形的程序员,前几篇文章一直都在教大家怎么画地图.画折线图.画烟花,难道图形就是这样嘛,当 ...
- Linux虚拟机扩展磁盘
Linux虚拟机扩展磁盘 1.虚拟机关机,Vmware中扩展磁盘 2.虚拟机开机,查看磁盘大小 [root@hadoop6 ~]# df -h 文件系统 容量 已用 可用 已用% 挂载点 devtmp ...
- 【Azure 应用服务】App Service服务无法启动,打开Kudu站点,App Service Editor 页面均抛出:The service is unavailable
问题描述 App Service 服务URL无法访问,进入门户中的Advanced Tools(Kudu).App Service Editor (Preview)等页面无法打开, 打开就出现 The ...
- String类型转成int类型
在将String类型转换成int类型时: int n = Interger.parseInt(Stringnum); 如果报错,可以改成 int n = Interger.parseInt(Strin ...