MPP大规模并行处理架构详解
面试官:说下你知道的MPP架构的计算引擎?
这个问题不少小伙伴在面试时都遇到过,因为对MPP这个概念了解较少,不少人都卡壳了,但是我们常用的大数据计算引擎有很多都是MPP架构的,像我们熟悉的Impala、ClickHouse、Druid、Doris等都是MPP架构。
采用MPP架构的很多OLAP引擎号称:亿级秒开。
本文分为三部分讲解,第一部分详解MPP架构,第二部分剖析MPP架构与批处理架构的异同点,第三部分是采用MPP架构的OLAP引擎介绍。
一、MPP架构
MPP是系统架构角度的一种服务器分类方法。
目前商用的服务器分类大体有三种:
- SMP(对称多处理器结构)
- NUMA(非一致存储访问结构)
- MPP(大规模并行处理结构)
我们今天的主角是 MPP,因为随着分布式、并行化技术成熟应用,MPP引擎逐渐表现出强大的高吞吐、低时延计算能力,有很多采用MPP架构的引擎都能达到“亿级秒开”。
先了解下这三种结构:
1. SMP
即对称多处理器结构,就是指服务器的多个CPU对称工作,无主次或从属关系。SMP服务器的主要特征是共享,系统中的所有资源(如CPU、内存、I/O等)都是共享的。也正是由于这种特征,导致了SMP服务器的主要问题,即扩展能力非常有限。
2. NUMA
即非一致存储访问结构。这种结构就是为了解决SMP扩展能力不足的问题,利用NUMA技术,可以把几十个CPU组合在一台服务器内。NUMA的基本特征是拥有多个CPU模块,节点之间可以通过互联模块进行连接和信息交互,所以,每个CPU可以访问整个系统的内存(这是与MPP系统的重要区别)。但是访问的速度是不一样的,因为CPU访问本地内存的速度远远高于系统内其他节点的内存速度,这也是非一致存储访问NUMA的由来。
这种结构也有一定的缺陷,由于访问异地内存的时延远远超过访问本地内存,因此,当CPU数量增加时,系统性能无法线性增加。
3. MPP
即大规模并行处理结构。MPP的系统扩展和NUMA不同,MPP是由多台SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。每个节点只访问自己的资源,所以是一种完全无共享(Share Nothing)结构。
MPP结构扩展能力最强,理论可以无限扩展。由于MPP是多台SPM服务器连接的,每个节点的CPU不能访问另一个节点内存,所以也不存在异地访问的问题。
MPP架构图:
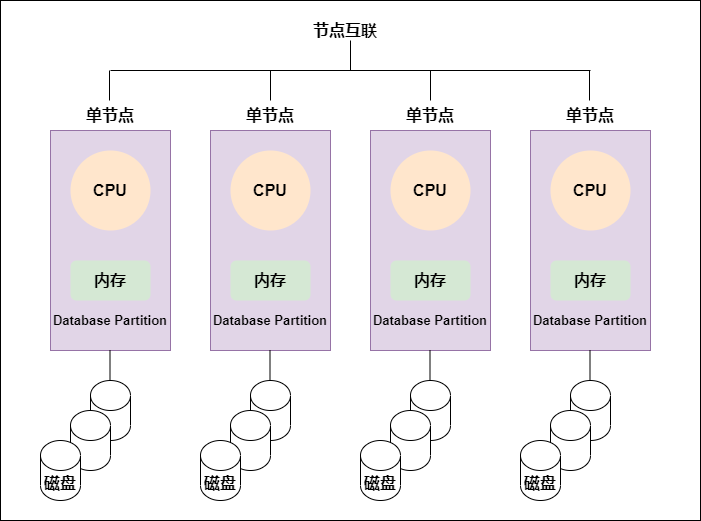
每个节点内的CPU不能访问另一个节点的内存,节点之间的信息交互是通过节点互联网络实现的,这个过程称为数据重分配。
但是MPP服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。目前,一些基于MPP技术的服务器往往通过系统级软件(如数据库)来屏蔽这种复杂性。举个例子,Teradata就是基于MPP技术的一个关系数据库软件(这是最早采用MPP架构的数据库),基于此数据库来开发应用时,不管后台服务器由多少节点组成,开发人员面对的都是同一个数据库系统,而无需考虑如何调度其中某几个节点的负载。
MPP架构特征:
- 任务并行执行;
- 数据分布式存储(本地化);
- 分布式计算;
- 高并发,单个节点并发能力大于300用户;
- 横向扩展,支持集群节点的扩容;
- Shared Nothing(完全无共享)架构。
NUMA和MPP区别:
二者有许多相似之处,首先NUMA和MPP都是由多个节点组成的;其次每个节点都有自己的CPU,内存,I/O等;都可以都过节点互联机制进行信息交互。
那它们的区别是什么呢,首先是节点互联机制不同,NUMA的节点互联是在同一台物理服务器内部实现的,MPP的节点互联是在不同的SMP服务器外部通过I/O实现的。
其次是内存访问机制不同,在NUMA服务器内部,任何一个CPU都可以访问整个系统的内存,但异地内存访问的性能远远低于本地内存访问,因此,在开发应用程序时应该尽量避免异地内存访问。而在MPP服务器中,每个节点只访问本地内存,不存在异地内存访问问题。
二、批处理架构和MPP架构
批处理架构(如 MapReduce)与MPP架构的异同点,以及它们各自的优缺点是什么呢?
相同点:
首先相同点,批处理架构与MPP架构都是分布式并行处理,将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
不同点:
批处理架构和MPP架构的不同点可以举例来说:我们执行一个任务,首先这个任务会被分成多个task执行,对于MapReduce来说,这些tasks被随机的分配在空闲的Executor上;而对于MPP架构的引擎来说,每个处理数据的task被绑定到持有该数据切片的指定Executor上。
正是由于以上的不同,使得两种架构有各自优势也有各自缺陷:
- 批处理的优势:
对于批处理架构来说,如果某个Executor执行过慢,那么这个Executor会慢慢分配到更少的task执行,批处理架构有个推测执行策略,推测出某个Executor执行过慢或者有故障,则在接下来分配task时就会较少的分配给它或者直接不分配。
- MPP的缺陷:
对于MPP架构来说,因为task和Executor是绑定的,如果某个Executor执行过慢或故障,将会导致整个集群的性能就会受限于这个故障节点的执行速度(所谓木桶的短板效应),所以MPP架构的最大缺陷就是——短板效应。另一点,集群中的节点越多,则某个节点出现问题的概率越大,而一旦有节点出现问题,对于MPP架构来说,将导致整个集群性能受限,所以一般实际生产中MPP架构的集群节点不易过多。
- 批处理的缺陷:
任何事情都是有代价的,对于批处理而言,会将中间结果写入到磁盘中,这严重限制了处理数据的性能。
- MPP的优势:
MPP架构不需要将中间数据写入磁盘,因为一个单一的Executor只处理一个单一的task,因此可以简单直接将数据stream到下一个执行阶段。这个过程称为pipelining,它提供了很大的性能提升。
举个例子:要实现两个大表的join操作,对于批处理而言,如Spark将会写磁盘3次(第一次写入:表1根据join key进行shuffle;第二次写入:表2根据join key进行shuffle;第三次写入:Hash表写入磁盘), 而MPP只需要一次写入(Hash表写入)。这是因为MPP将mapper和reducer同时运行,而MapReduce将它们分成有依赖关系的tasks(DAG),这些task是异步执行的,因此必须通过写入中间数据共享内存来解决数据的依赖。
批处理架构和MPP架构融合:
两个架构的优势和缺陷都很明显,并且它们有互补关系,如果我们能将二者结合起来使用,是不是就能发挥各自最大的优势。目前批处理和MPP也确实正在逐渐走向融合,也已经有了一些设计方案,一旦技术成熟,可能会风靡大数据领域,我们拭目以待!
三、 MPP架构的OLAP引擎
采用MPP架构的OLAP引擎有很多,下面只选择常见的几个引擎对比下,可为公司的技术选型提供参考。
采用MPP架构的OLAP引擎分为两类,一类是自身不存储数据,只负责计算的引擎;一类是自身既存储数据,也负责计算的引擎。
1)只负责计算,不负责存储的引擎
1. Impala
Apache Impala是采用MPP架构的查询引擎,本身不存储任何数据,直接使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。
提供了类SQL(类Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。它是由Java和C++实现的,Java提供的查询交互的接口和实现,C++实现了查询引擎部分。
Impala支持共享Hive Metastore,但没有再使用缓慢的 Hive+MapReduce 批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。
Impala经常搭配存储引擎Kudu一起提供服务,这么做最大的优势是查询比较快,并且支持数据的Update和Delete。
2. Presto
Presto是一个分布式的采用MPP架构的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto是一个OLAP的工具,擅长对海量数据进行复杂的分析;但是对于OLTP场景,并不是Presto所擅长,所以不要把Presto当做数据库来使用。
Presto是一个低延迟高并发的内存计算引擎。需要从其他数据源获取数据来进行运算分析,它可以连接多种数据源,包括Hive、RDBMS(Mysql、Oracle、Tidb等)、Kafka、MongoDB、Redis等。
2)既负责计算,又负责存储的引擎
1. ClickHouse
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。
它自包含了存储和计算能力,完全自主实现了高可用,而且支持完整的SQL语法包括JOIN等,技术上有着明显优势。相比于hadoop体系,以数据库的方式来做大数据处理更加简单易用,学习成本低且灵活度高。当前社区仍旧在迅猛发展中,并且在国内社区也非常火热,各个大厂纷纷跟进大规模使用。
ClickHouse在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与SIMD指令、代码生成等多种重要技术。
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
2. Doris
Doris是百度主导的,根据Google Mesa论文和Impala项目改写的一个大数据分析引擎,是一个海量分布式 KV 存储系统,其设计目标是支持中等规模高可用可伸缩的 KV 存储集群。
Doris可以实现海量存储,线性伸缩、平滑扩容,自动容错、故障转移,高并发,且运维成本低。部署规模,建议部署4-100+台服务器。
Doris3 的主要架构: DT(Data Transfer)负责数据导入、DS(Data Seacher)模块负责数据查询、DM(Data Master)模块负责集群元数据管理,数据则存储在 Armor 分布式 Key-Value 引擎中。Doris3 依赖 ZooKeeper 存储元数据,从而其他模块依赖 ZooKeeper 做到了无状态,进而整个系统能够做到无故障单点。
3. Druid
Druid是一个开源、分布式、面向列式存储的实时分析数据存储系统。
Druid的关键特性如下:
- 亚秒级的OLAP查询分析:采用了列式存储、倒排索引、位图索引等关键技术;
- 在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作;
- 实时流数据分析:Druid提供了实时流数据分析,以及高效实时写入;
- 实时数据在亚秒级内的可视化;
- 丰富的数据分析功能:Druid提供了友好的可视化界面;
- SQL查询语言;
- 高可用性与高可拓展性:
- Druid工作节点功能单一,不相互依赖;
- Druid集群在管理、容错、灾备、扩容都很容易;
4. TiDB
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持OLTP与OLAP的融合型分布式数据库产品。
TiDB 兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP 、OLAP 、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
5. Greenplum
Greenplum 是在开源的 PostgreSQL 的基础上采用了MPP架构的性能非常强大的关系型分布式数据库。为了兼容Hadoop生态,又推出了HAWQ,分析引擎保留了Greenplum的高性能引擎,下层存储不再采用本地硬盘而改用HDFS,规避本地硬盘可靠性差的问题,同时融入Hadoop生态。
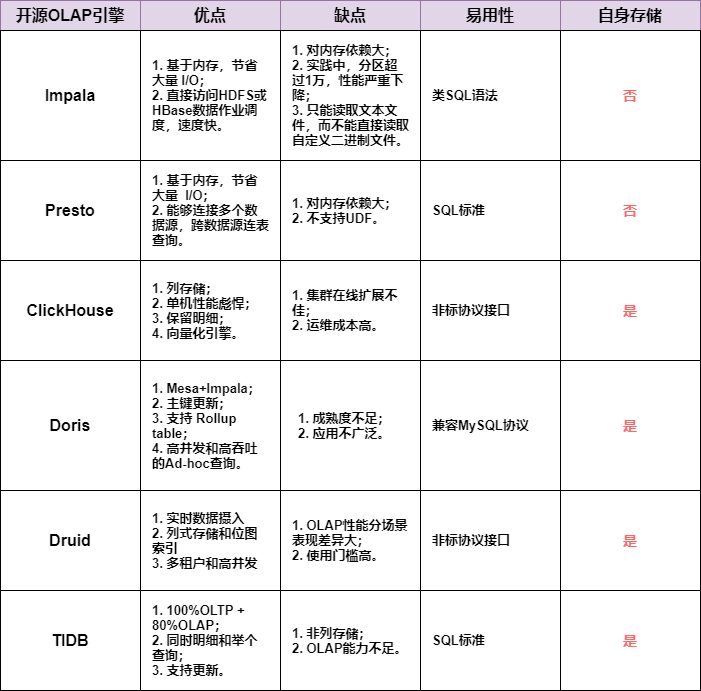
3)常用的引擎对比
一张图总结下常用的OLAP引擎对比:
MPP大规模并行处理架构详解的更多相关文章
- MPP(大规模并行处理)
1. 什么是MPP? MPP (Massively Parallel Processing),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和 ...
- MPP(大规模并行处理)简介
1. 什么是MPP? MPP (Massively Parallel Processing),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和 ...
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
- 领域驱动设计(Domain Driven Design)参考架构详解
摘要 本文将介绍领域驱动设计(Domain Driven Design)的官方参考架构,该架构分成了Interfaces.Applications和Domain三层以及包含各类基础设施的Infrast ...
- WeChatAPI 开源系统架构详解
WeChatAPI 开源系统架构详解 如果使用WeChatAPI,它扮演着什么样的角色? 从图中我们可以看到主要分为3个部分: 1.业务系统 2.WeChatAPI: WeChatWebAPI,主要是 ...
- hdfs文件系统架构详解
hdfs文件系统架构详解 官方hdfs分布式介绍 NameNode *Namenode负责文件系统的namespace以及客户端文件访问 *NameNode负责文件元数据操作,DataNode负责文件 ...
- NopCommerce源码架构详解
NopCommerce源码架构详解--初识高性能的开源商城系统cms 很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从 ...
- RESTful 架构详解
RESTful 架构详解 分类 编程技术 1. 什么是REST REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移. 它首次 ...
- Nop--NopCommerce源码架构详解专题目录
最近在研究外国优秀的ASP.NET mvc电子商务网站系统NopCommerce源码架构.这个系统无论是代码组织结构.思想及分层都值得我们学习.对于没有一定开发经验的人要完全搞懂这个源码还是有一定的难 ...
随机推荐
- bond0 配置ip不生效排查方法
今天巡检的时候,发现无法连接到服务器上面了,于是到机房连接到显示器查看: 1.先检查网卡,协议有没有问题. 2.远程链接的网卡名称是bond0,用ifconfig看看网卡配置,然后发现配置的 ...
- 大数据 什么是 ETL
ETL 概念 ETL 这个术语来源于数据仓库,ETL 指的是将业务系统的数据经过抽取.清洗转换之后加载到数据仓库的过程.ETL 的目的是将企业中的分散.零乱.标准不统一的数据整合到一起,为企业的决策提 ...
- STM32 keil中编译遇到的问题
发现 移植的SPI程序 说里面的 SPI_InitTypeDef 所有有关 SPI库函数的都找不到 这是因为 用的是 原子的程序 在 config函数中 把这个注释了
- SystemVerilog MCDF验证结构
MCDF的设计和验证花费的时间:(工作中假设的时间) design cycle time ==10days how about 验证?verify? 模块越往上(大')验证花费的时间越来越大,但是 ...
- [LeetCode] 1744. 你能在你最喜欢的那天吃到你最喜欢的糖果吗?
都儿童节了,为什么要折磨一个几百个月大的孩子? 把题意读懂挺难的.不过读懂后基本也就知道怎么做了.恶心的是int类型可能会越界,要用long类型(很难想到).这题不好 [1744. 你能在你最喜欢的那 ...
- Lua时间互转
1. 时间戳转成格式化字符串 直接利用函数os.date()将时间戳转化成格式化字符串. local timestamp = 1561636137; local strDate = os.date(& ...
- redis中AOF和RDB的关闭方法
redis中AOF和RDB的关闭方法 问题:当往redis中导入数据时,有时会出现redis server went away的情况: 原因: 导入的数据量太大,而内存不够(即内存1G,但数据有2 ...
- checkbox,select,radio 选取值,设定值,回显值
获取一组radio被选中项的值var item = $('input[@name=items][@checked]').val();获取select被选中项的文本var item = $(" ...
- 特斯拉Tesla Model 3整体架构解析(下)
特斯拉Tesla Model 3整体架构解析(中) Tesla Computer Unit 特斯拉已经开发了一个由自动驾驶仪和信息计算机组成的定制"液冷双计算平台"."他 ...
- H265与ffmpeg改进开发
H265与ffmpeg改进开发 1. Introduction KSC265是集编码.解码于一体的H.265编解码软件,完全遵循H.265协议标准.符合H.265编码规范的视频都可以通过KSC265进 ...