Hive On Spark保姆级攻略
声明:
此博客参考了官网的配置方式,并结合笔者在实践网上部分帖子时的踩坑经历整理而成
这里贴上官方配置说明:
[官方]: https://cwiki.apache.org//confluence/display/Hive/Hive+on+Spark:+Getting+Started
大前提:
从Hive1.1开始支持使用Spark作为执行引擎,我们配置使用Spark On Yarn时,一定要注意
Hive版本与Spark版本的适配,不适配的需要自己重新编译使其适配
这里贴上官方推荐的对应版本Hive Version Spark Version master 2.3.0 3.0.x 2.3.0 2.3.x 2.0.0 2.2.x 1.6.0 2.1.x 1.6.0 2.0.x 1.5.0 1.2.x 1.3.1 1.1.x 1.2.0 笔者这里使用的是hive-3.1.2,按理说应该使用spark-2.3.0作为对应,但出于业务要求需使用spark-3.1.2,故重新编译hive-3.1.2源码使其适配spark-3.1.2
Spark使用的jar包必须是没有集成Hive的
因spark包自带hive,其支持的版本与我们使用的版本冲突(如spark-3.1.2默认支持的hive版本为2.3.7),故我们只需spark自身即可,不需其自带的hive模块
两种方式去获得去hive的jar包- 从官网下载完整版的jar包,解压后将其jars目录下的hive相关jar包全部删掉(本文即使用此种方法)
- 重新编译spark,但不指定-Phive
注:网上部分帖子中所说使用“纯净版”,其实指的就是去hive版,而不是官方提供的without-hadoop版
下面进入正题
部署环境:CentOS 7.4 x86_64
Hive版本:3.1.2(重新编译过,修改了Spark版本和Scala版本,替换修改了部分源码,如有需要后续会出编译指导)
Spark版本:3.1.2(spark-3.1.2-bin-hadoop3.2.tgz,官网直接下载)
Hadoop版本:3.1.3(与Spark3.1.2自带hadoop版本3.2只差一个小版本,可直接使用,不用重新编译)
JDK版本:1.8.0_172
myql版本:5.7.32
步骤:
- 在机器上部署spark
解压
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz
设置环境变量
echo '#SPARK_HOME' >> /etc/profile
echo 'export SPARK_HOME=/data/apps/spark-3.1.2-bin-hadoop3.2' >> /etc/profile
echo 'export PATH=$PATH:$SPARK_HOME/bin' >> /etc/profile
准备去hive版本的spark-jars(!!!除了hive-storage-api-2.7.2.jar这个包!!!,如果用的spark是重新编译的且没有指定-Phive,这步可以省略)
cd $SPARK_HOME //进目录
mv jars/hive-storage-api-2.7.2.jar . //把这包先移出去
rm -rf jars/*hive* //删
mv hive-storage-api-2.7.2.jar jars/ //再移回去
将刚做好的spark-jars上传到hdfs
hdfs dfs -mkdir -p /spark-jars
hdfs dfs -put jars/* /spark-jars/
hdfs上创建spark-history存日志
hdfs dfs -mkdir -p /spark-history
- 在机器上部署hive
解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz
注:解压后的hive还需要一些额外的包放在lib下,比如因元数据库换为mysql需要一个mysql-connector-java-5.1.48.jar,比如为了处理hive-3.1.2和hadoop-3.1.3中guava包版本冲突的问题需要把原lib下的guava19删了放一个guava27,再比如为了处理slf4j包冲突问题将lib下面log4j-slf4j-impl-2.10.0.jar删喽,这里都不做详细说明(已经够详细了吧/doge);且这些问题都可以通过重新编译hive解决,不过要费一番功夫
改名(非必要)
mv apache-hive-3.1.2-bin hive-3.1.2
设置环境变量
echo '#HIVE_HOME' >> /etc/profile
echo 'export HIVE_HOME=/data/apps/hive-3.1.2' >> /etc/profile
echo 'export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile
修改配置文件
- hive-site.xml
注:该文件首先需要从hive-default.xml.template复制一份出来,里面参数根据自己需要调整,这里只讲hive-on-spark需要修改或新增的参数
<!--Spark依赖位置,上面上传jar包的hdfs路径-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://bdp3install:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎,使用spark-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive连接spark-client超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>30000ms</value>
</property>
- hive-env.sh
注:该文件首先需要从hive-env.sh.template复制一份出来,里面参数根据自己需要调整,这里只讲hive-on-spark需要修改或新增的参数
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=${HADOOP_HOME:-/data/apps/hadoop-3.1.3}
export HIVE_HOME=${HIVE_HOME:-/data/apps/hive-3.1.2}
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=${HIVE_CONF_DIR:-/data/apps/hive-3.1.2/conf}
export METASTORE_PORT=9083
export HIVESERVER2_PORT=10000
- spark-default.conf
注:直接vim生成吧,不用从spark目录再拷过来,更多的参数可以参考最上面的官方地址
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bdp3install:8020/spark-history
spark.executor.memory 4g
spark.driver.memory 4g
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.cores 2
spark.yarn.driver.memoryOverhead 400m
- 启动hive
cd $HIVE_HOME
nohup bin/hive --service metastore &
等metastore启完(9083端口被监听了)
nohup bin/hive --service hiveserver2 &
等hiveserver2启完(10000端口被监听了)
4. 客户端连接测试
beeline
!connect jdbc:hive2://localhost:10000 hive ""
执行一些insert,同时观察下yarn,如果任务成功了,yarn上也有相应的application成功了,那就妥了


注:hive on spark任务是以每个spark session为单位提交到yarn的,每个yarn任务都有一次从hdfs加载spark-jars到容器中的过程,所以每次通过客户端执行命令时,第一次执行的速度会比较慢(因为加载jars,大约有200M),后续就很快了。
常见问题:
- java.lang.NoClassDefFoundError: org/apache/hadoop/hive/ql/exec/vector/ColumnVector
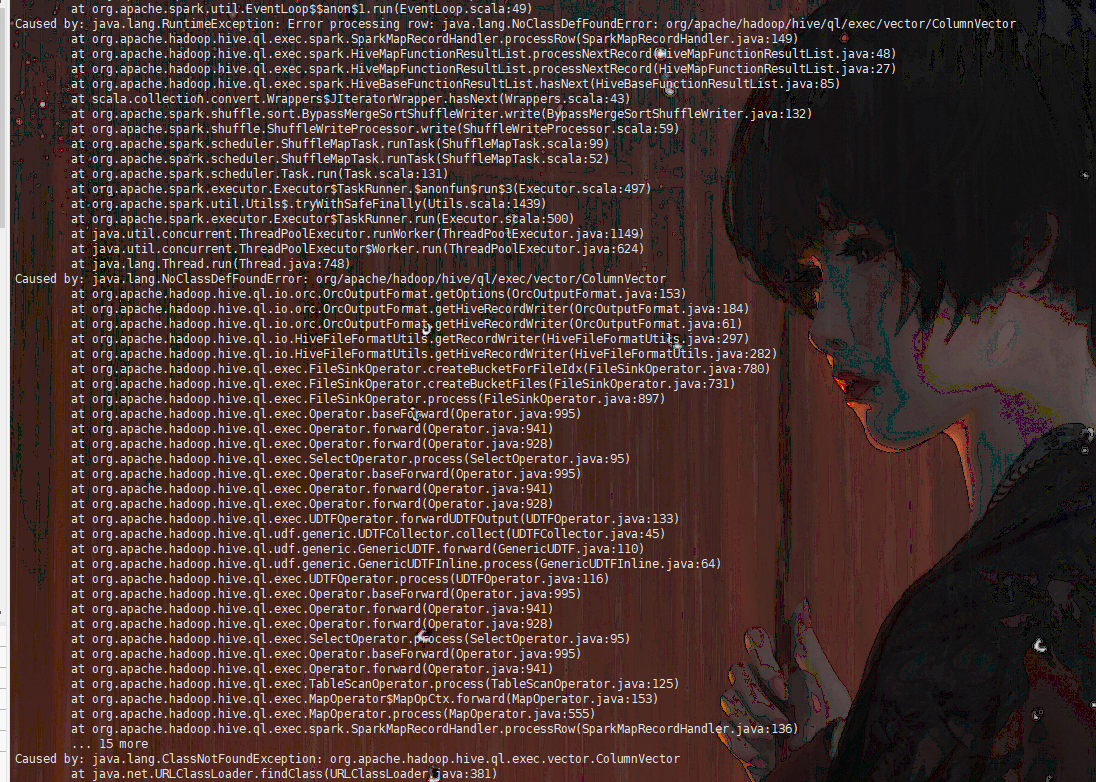
原因:spark-jars里少hive-storage-api-2.7.2.jar这个包
2. Could not load YARN classes. This copy of Spark may not have been compiled with YARN support.
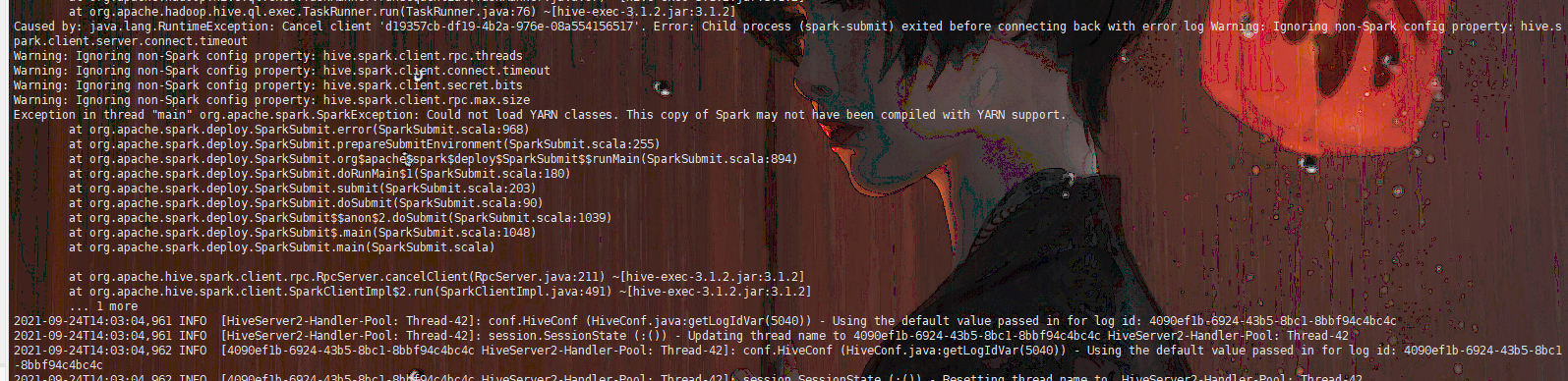
原因:hiveserver2所在机器没有部署spark或spark非完整版,或spark版本与hive版本不对应
3. 各种各样的ClassNotFound,NoClassDefFoundError
原因:spark-jars不完整,一定要是去hive的完整版jar包(一般都是少hadoop的包)
此文章首发于博客园,希望能对大家有所帮助,如有遗漏或问题欢迎补充指正。
Hive On Spark保姆级攻略的更多相关文章
- 废弃fastjson!大型项目迁移Gson保姆级攻略
前言 大家好,又双叒叕见面了,我是天天放大家鸽子的蛮三刀. 在被大家取关之前,我立下一个"远大的理想",一定要在这周更新文章.现在看来,flag有用了... 本篇文章是我这一个多月 ...
- Pyspark spark-submit 集群提交任务以及引入虚拟环境依赖包攻略
网上提交 scala spark 任务的攻略非常多,官方文档其实也非常详细仔细的介绍了 spark-submit 的用法.但是对于 python 的提交提及得非常少,能查阅到的资料非常少导致是有非常多 ...
- 【转】Hive安装及使用攻略
Posted: Jul 16, 2013 Tags: HadoophiveHiveQLsql分区表 Comments: 18 Comments Hive安装及使用攻略 让Hadoop跑在云端系列文章, ...
- 微信小程序——【百景游戏小攻略】
微信小程序--[百景游戏小攻略] 本次课程小项目中的图片以及文章还未获得授权!请勿商用!未经授权,请勿转载! 博客班级 https://edu.cnblogs.com/campus/zjcsxy/SE ...
- 【C#代码实战】群蚁算法理论与实践全攻略——旅行商等路径优化问题的新方法
若干年前读研的时候,学院有一个教授,专门做群蚁算法的,很厉害,偶尔了解了一点点.感觉也是生物智能的一个体现,和遗传算法.神经网络有异曲同工之妙.只不过当时没有实际需求学习,所以没去研究.最近有一个这样 ...
- Windows下LATEX排版论文攻略—CTeX、JabRef使用介绍
Windows下LATEX排版论文攻略—CTeX.JabRef使用介绍 一.工具介绍 TeX是一个很好排版工具,在学术界十分流行,特别是数学.物理学和计算机科学界. CTeX是TeX中的一个版本,指的 ...
- Python环境下NIPIR(ICTCLAS2014)中文分词系统使用攻略
一.安装 官方链接:http://pynlpir.readthedocs.org/en/latest/installation.html 官方网页中介绍了几种安装方法,大家根据个人需要,自行参考!我采 ...
- Apache Spark源码走读之12 -- Hive on Spark运行环境搭建
欢迎转载,转载请注明出处,徽沪一郎. 楔子 Hive是基于Hadoop的开源数据仓库工具,提供了类似于SQL的HiveQL语言,使得上层的数据分析人员不用知道太多MapReduce的知识就能对存储于H ...
- 30天,O2O速成攻略【8.16武汉站】
活动概况 时间:2015年08月16日13:30-16:30 地点:光谷创业咖啡(光谷广场资本大厦一楼停车场内) 主办:APICloud.爱立示.MBA移动业务助理 网址:www.apicloud.c ...
随机推荐
- .Net Core NPOI读取Excel 并转为数据实体类
创建应用程序 这里直接创建Console程序 引用NPOI的NuGet包 PM> Install-Package NPOI -Version 2.5.1 直接Nuget包管理器添加 导入Exce ...
- .net core2.1 迁移.net core 3.1
1.解决方案->属性-->目标框架 .net core3.1 2.删除旧的Nuget包添加新的NuGet包 3.修改Startup.cs 修改ConfigureServices 修改Con ...
- Spring第一课:依赖注入DI(二)
DI Dependency Injection ,依赖注入 is a :是一个,继承. has a:有一个,成员变量,依赖. class B { private A a; //B类依赖A类 } 依 ...
- jQuery中ajax请求的六种方法(三、五):$.getScript()方法
5.$.getScript()方法 <!DOCTYPE html> <html> <head> <meta charset="UTF-8" ...
- Spring Data JPA:解析CriteriaBuilder
源码 在Spring Data JPA相关的文章[地址]中提到了有哪几种方式可以构建Specification的实例,该处需要借助CriteriaBuilder,回顾一下Specification中t ...
- jwt《token》
payload与claims只能存在一个这部分是jwt源码:依赖如下:官方文档的依赖 <dependency> <groupId>io.jsonwebtoken</gro ...
- RapidSVN设置diff和edit工具
菜单栏 -> View -> Preferences -> Programs选择相应的配置页即可 需要配置的路径,默认都在 /usr/bin目录下的 editor可以用ged ...
- Python中的文件处理和数据存储json
前言:每当需要分析或修改存储在文件中的信息时,读取文件都很有用,对数据分析应用程序来说尤其如此. 例如,你可以编写一个这样的程序:读取一个文本文件的内容,重新设置这些数据的格式并将其写入文件,让浏览器 ...
- 浅析 Dapr 里的云计算设计模式
Dapr 实际上是把分布式系统 与微服务架构实践的挑战以及k8s 这三个主题的全方位的设计组合,特别是Kubernetes设计模式 一书作者Bilgin Ibryam 提出的Multi-Runtime ...
- LayoutControl控件使用
因默认外边距过大需要将外边距缩小用以下代码实现layoutControlGroup1.Padding = DevExpress.XtraLayout.Utils.Padding.Empty;是否允许只 ...