HTTP流量神器Goreplay核心源码详解
摘要:Goreplay 前称是 Gor,一个简单的 TCP/HTTP 流量录制及重放的工具,主要用 Go 语言编写。
本文分享自华为云社区《流量回放工具之 goreplay 核心源码分析》,作者:zuozewei。
一、前言
Goreplay 前称是 Gor,一个简单的 TCP/HTTP 流量录制及重放的工具,主要用 Go 语言编写。
Github地址:https://github.com/buger/goreplay
二、工程结构
这里以最新的 v1.3 版本为例,与 v1.0 的代码存在较大差异。
~/GoProjects/gor_org/goreplay release-1.3 ±✚ tree -L 1 .
├── COMM-LICENSE
├── Dockerfile
├── Dockerfile.dev
├── ELASTICSEARCH.md
├── LICENSE.txt
├── Makefile
├── Procfile
├── README.md
├── byteutils
├── capture
├── circle.yml
├── docs
├── elasticsearch.go
├── emitter.go
├── emitter_test.go
├── examples
├── go.mod
├── go.sum
├── gor.go
├── gor_stat.go
├── homebrew
├── http_modifier.go
├── http_modifier_settings.go
├── http_modifier_settings_test.go
├── http_modifier_test.go
├── http_prettifier.go
├── http_prettifier_test.go
├── input_dummy.go
├── input_file.go
├── input_file_test.go
├── input_http.go
├── input_http_test.go
├── input_kafka.go
├── input_kafka_test.go
├── input_raw.go
├── input_raw_test.go
├── input_tcp.go
├── input_tcp_test.go
├── kafka.go
├── limiter.go
├── limiter_test.go
├── middleware
├── middleware.go
├── middleware_test.go
├── mkdocs.yml
├── output_binary.go
├── output_dummy.go
├── output_file.go
├── output_file_test.go
├── output_http.go
├── output_http_test.go
├── output_kafka.go
├── output_kafka_test.go
├── output_null.go
├── output_s3.go
├── output_tcp.go
├── output_tcp_test.go
├── plugins.go
├── plugins_test.go
├── pro.go
├── proto
├── protocol.go
├── ring
├── s3
├── s3_reader.go
├── s3_test.go
├── settings.go
├── settings_test.go
├── sidenav.css
├── simpletime
├── site
├── size
├── snapcraft.yaml
├── tcp
├── tcp_client.go
├── test_input.go
├── test_output.go
├── vendor
└── version.go
工程目录比较扁平,主要看 plugin.go,settings.go,emitter.go 几个主要文件,其它分 input_xxx ,output_xxx 都是适配具体协议的输入输出插件,程序入口是 gor.go 的 main 函数。
主要文件说明:
- settings.go:实现对于启动命令参数的解析,决定其注册那些插件到 Plugin.Inputs,Plugin.Outputs两个列表里。
- plugin.go:主要是所有输入输出插件的管理。
- emitter.go:程序核心事件处理,实现对于 Plugin.Inputs 输入流的读取、判断是否需要进行 middlewear 的处理、http修改等,然后异步复制流量到所有 Plugin.outputs,同时将所有 Plugin.outputs 中有 response 的数据,复制到所有 outputs 中。
- input_xxx.go:主要是输入的插件,实现 tcp/http/raw/kafka等协议, 实现 io.Reader 接口,最后根据配置注册到 Plugin.inputs队列里。
- output_xxx.go:主要是输出的插件,实现 tcp/http/raw/kafka 等协议, 实现 io.Writer 接口,最后根据配置注册到 Plugin.outputs 队列里。
三、主要核心流程
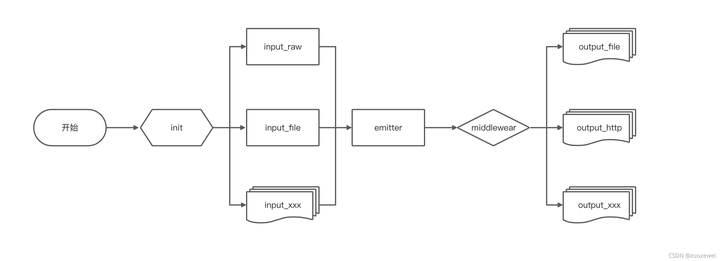
goreplay 只有 input 和 output 两个概念,是 goreplay 对数据流的抽象,统称为 plugin。
gor.go 中 main 函数,它主要做了以下事情:
1、解析命令行参数:
// Parse parses the command-line flags from os.Args[1:]. Must be called
// after all flags are defined and before flags are accessed by the program.
func Parse() {
// Ignore errors; CommandLine is set for ExitOnError.
CommandLine.Parse(os.Args[1:])
}
2、初始化全局的 Settings 变量。
func checkSettings() {
if Settings.OutputFileConfig.SizeLimit < 1 {
Settings.OutputFileConfig.SizeLimit.Set("32mb")
}
if Settings.OutputFileConfig.OutputFileMaxSize < 1 {
Settings.OutputFileConfig.OutputFileMaxSize.Set("1tb")
}
if Settings.CopyBufferSize < 1 {
Settings.CopyBufferSize.Set("5mb")
}
}
3、命令行参数的定义在 settings.go 的 init 函数中,会先于 main 函数执行。
func init() {
flag.Usage = usage
flag.StringVar(&Settings.Pprof, "http-pprof", "", "Enable profiling. Starts http server on specified port, exposing special /debug/pprof endpoint. Example: `:8181`")
flag.IntVar(&Settings.Verbose, "verbose", 0, "set the level of verbosity, if greater than zero then it will turn on debug output")
flag.BoolVar(&Settings.Stats, "stats", false, "Turn on queue stats output")
if DEMO == "" {
flag.DurationVar(&Settings.ExitAfter, "exit-after", 0, "exit after specified duration")
} else {
Settings.ExitAfter = 5 * time.Minute
}
flag.BoolVar(&Settings.SplitOutput, "split-output", false, "By default each output gets same traffic. If set to `true` it splits traffic equally among all outputs.")
flag.BoolVar(&Settings.RecognizeTCPSessions, "recognize-tcp-sessions", false, "[PRO] If turned on http output will create separate worker for each TCP session. Splitting output will session based as well.")
......
// default values, using for tests
Settings.OutputFileConfig.SizeLimit = 33554432
Settings.OutputFileConfig.OutputFileMaxSize = 1099511627776
Settings.CopyBufferSize = 5242880
}
4、根据命令行传参初始化插件,在 main 函数中调用 InitPlugins 函数。
// NewPlugins specify and initialize all available plugins
func NewPlugins() *InOutPlugins {
plugins := new(InOutPlugins) for _, options := range Settings.InputDummy {
plugins.registerPlugin(NewDummyInput, options)
} ...... return plugins
}
5、调用 Start 函数,启动 emitter,每个 input 插件,都启动一个协程,读取 input,写 output。
/ Start initialize loop for sending data from inputs to outputs
func (e *Emitter) Start(plugins *InOutPlugins, middlewareCmd string) {
if Settings.CopyBufferSize < 1 {
Settings.CopyBufferSize = 5 << 20
}
e.plugins = plugins if middlewareCmd != "" {
middleware := NewMiddleware(middlewareCmd) for _, in := range plugins.Inputs {
middleware.ReadFrom(in)
} e.plugins.Inputs = append(e.plugins.Inputs, middleware)
e.plugins.All = append(e.plugins.All, middleware)
e.Add(1)
go func() {
defer e.Done()
if err := CopyMulty(middleware, plugins.Outputs...); err != nil {
Debug(2, fmt.Sprintf("[EMITTER] error during copy: %q", err))
}
}()
} else {
for _, in := range plugins.Inputs {
e.Add(1)
go func(in PluginReader) {
defer e.Done()
if err := CopyMulty(in, plugins.Outputs...); err != nil {
Debug(2, fmt.Sprintf("[EMITTER] error during copy: %q", err))
}
}(in)
}
}
}
如果只有一个协程,存在性能瓶颈。默认是一个 input 复制多份,写多个 output,如果传了 --split-output 参数,并且有多个 output ,则使用简单的 Round Robin 算法来选 output,不会写多份。多个 input 之间是并行的,但单个 input 到多个 output,是串行的。所有 input 都实现了 io.Reader 接口,output 都实现了 io.Writer 接口。所以阅读代码时,input 的入口是 Read() 方法,output 的入口是 Write() 方法。
// CopyMulty copies from 1 reader to multiple writers
func CopyMulty(src PluginReader, writers ...PluginWriter) error {
wIndex := 0
modifier := NewHTTPModifier(&Settings.ModifierConfig)
filteredRequests := make(map[string]int64)
filteredRequestsLastCleanTime := time.Now().UnixNano()
filteredCount := 0 for {
msg, err := src.PluginRead()
if err != nil {
if err == ErrorStopped || err == io.EOF {
return nil
}
return err
}
if msg != nil && len(msg.Data) > 0 {
if len(msg.Data) > int(Settings.CopyBufferSize) {
msg.Data = msg.Data[:Settings.CopyBufferSize]
}
meta := payloadMeta(msg.Meta)
if len(meta) < 3 {
Debug(2, fmt.Sprintf("[EMITTER] Found malformed record %q from %q", msg.Meta, src))
continue
}
requestID := byteutils.SliceToString(meta[1])
// start a subroutine only when necessary
if Settings.Verbose >= 3 {
Debug(3, "[EMITTER] input: ", byteutils.SliceToString(msg.Meta[:len(msg.Meta)-1]), " from: ", src)
}
if modifier != nil {
Debug(3, "[EMITTER] modifier:", requestID, "from:", src)
if isRequestPayload(msg.Meta) {
msg.Data = modifier.Rewrite(msg.Data)
// If modifier tells to skip request
if len(msg.Data) == 0 {
filteredRequests[requestID] = time.Now().UnixNano()
filteredCount++
continue
}
Debug(3, "[EMITTER] Rewritten input:", requestID, "from:", src) } else {
if _, ok := filteredRequests[requestID]; ok {
delete(filteredRequests, requestID)
filteredCount--
continue
}
}
} if Settings.PrettifyHTTP {
msg.Data = prettifyHTTP(msg.Data)
if len(msg.Data) == 0 {
continue
}
} if Settings.SplitOutput {
if Settings.RecognizeTCPSessions {
if !PRO {
log.Fatal("Detailed TCP sessions work only with PRO license")
}
hasher := fnv.New32a()
hasher.Write(meta[1]) wIndex = int(hasher.Sum32()) % len(writers)
if _, err := writers[wIndex].PluginWrite(msg); err != nil {
return err
}
} else {
// Simple round robin
if _, err := writers[wIndex].PluginWrite(msg); err != nil {
return err
} wIndex = (wIndex + 1) % len(writers)
}
} else {
for _, dst := range writers {
if _, err := dst.PluginWrite(msg); err != nil && err != io.ErrClosedPipe {
return err
}
}
}
} // Run GC on each 1000 request
if filteredCount > 0 && filteredCount%1000 == 0 {
// Clean up filtered requests for which we didn't get a response to filter
now := time.Now().UnixNano()
if now-filteredRequestsLastCleanTime > int64(60*time.Second) {
for k, v := range filteredRequests {
if now-v > int64(60*time.Second) {
delete(filteredRequests, k)
filteredCount--
}
}
filteredRequestsLastCleanTime = time.Now().UnixNano()
}
}
}
}
轮询调度算法的原理是每一次把来自用户的请求轮流分配给内部中的服务器,从1开始,直到 N(内部服务器个数),然后重新开始循环。
算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。
四、其它的小知识
1、goreplay 抓包调用 google/gopacket 来实现,后者通过 cgo 来调用 libpcap。整体工具小巧而实用,既可以实现 rawsocket 的抓包,也可以实现 http 的录制、回放,也支持多实例之间的级联。RAW_SOCKET 允许监听任何端口上的流量,因为它们是在IP级别上操作的。端口是 TCP 的特性,具有流量控制、传输可靠等优点。这个包实现了自己的TCP层: 使用tcp_packet 解析TCP包。流控制由 tcp_message.go管理
参考地址:http://en.wikipedia.org/wiki/Raw_socket
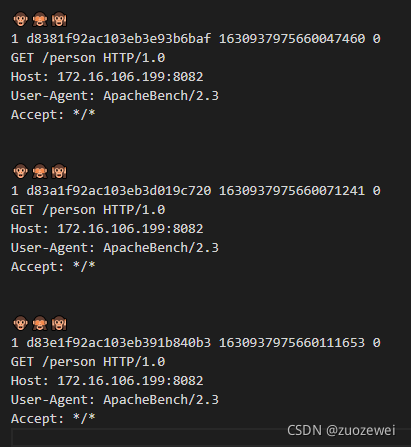
2、用三个猴头 emoji 字符作为请求分隔符,第一眼看到感觉挺搞笑的。
比如:
3、配置信息全靠启动命令参数。
比如:
/usr/local/bin/gor --input-raw :80 --input-raw-track-response --input-raw-bpf-filter "host ! 167.xxx.xxx.xx" --input-raw-override-snaplen --prettify-http --output-http http://192.168.3.110:80 --output-http-timeout 10s --output-http-workers 1000 --output-http-workers-min 100 --http-allow-header "Aww-Csid: xxxxx" --output-http-track-response --http-allow-method POST --middleware "/production/www/go_replay/client/middleware/sync --project {project_name}" --output-http-compatibility-mode --http-allow-url /article/detail
4、goreplay 支持 Java 程序配合工作的。支持开启插件模式:
gor --input-raw :80 --middleware "java -jar xxx.jar" --output-file request.gor
通过 middleware 参数可以传递一条命令给 gor ,gor 会拉起一个进程执行这个命令。在录制过程中,gory 通过获取进程的标准输入和输出与插件进程进行通信。
数据流向大致如下:
+-------------+ Original request +--------------+ Modified request +-------------+
| Gor input |----------STDIN---------->| Middleware |----------STDOUT---------->| Gor output |
+-------------+ +--------------+ +-------------+
input-raw java -jar xxx.jar output-file
5、拦截器的设置
参考地址:https://github.com/buger/goreplay/wiki/Dealing-with-missing-requests-and-responses
实际使用过程中,发现录制流量并发达到一定量级会丢失很多请求,经过阅读官方文档和测试,发现最相关的一个关键参数是 –input-raw-buffer-size。
其主要原因四由于 gor 本身需要对数据包进行读取,协议解析等,借助于 pcap 及 os 缓冲区,当缓冲区不足,到达的数据包不足以组装 Http 请求则出现丢失或失效请求,无法正确处理。
listener.go 该参数是作用在底层录制上:
inactive.SetTimeout(t.messageExpire)
inactive.SetPromisc(true)
inactive.SetImmediateMode(t.immediateMode)
if t.immediateMode {
log.Println("Setting immediate mode")
}
if t.bufferSize > 0 {
inactive.SetBufferSize(int(t.bufferSize))
} handle, herr := inactive.Activate()
if herr != nil {
log.Println("PCAP Activate error:", herr)
wg.Done()
return
}
在具体复制动作定义bufferSize: // CopyMulty copies from 1 reader to multiple writers
func CopyMulty(src io.Reader, writers ...io.Writer) (err error) {
buf := make([]byte, Settings.copyBufferSize)
wIndex := 0
modifier := NewHTTPModifier(&Settings.modifierConfig)
filteredRequests := make(map[string]time.Time)
filteredRequestsLastCleanTime := time.Now() ......
}
五、代码调用链路图
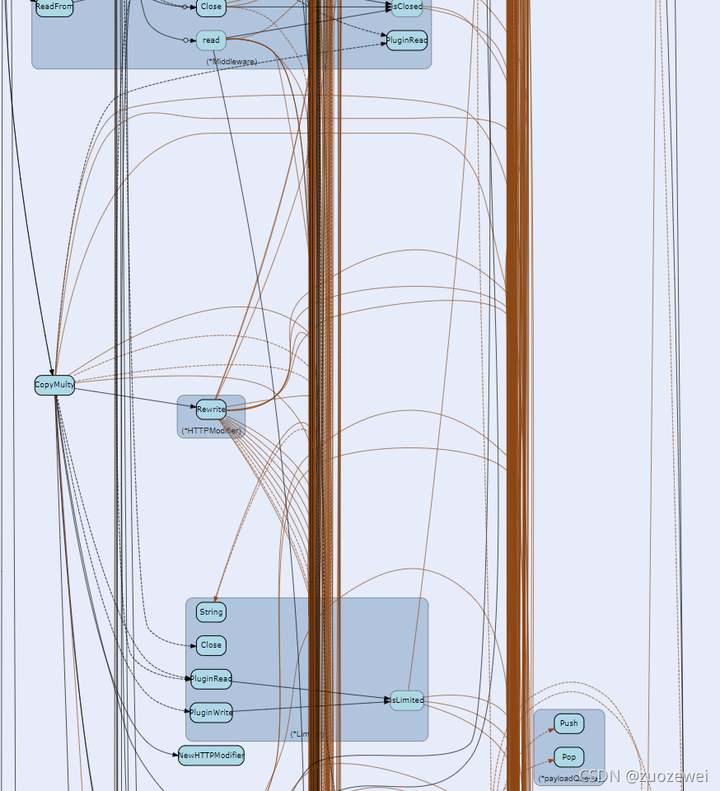
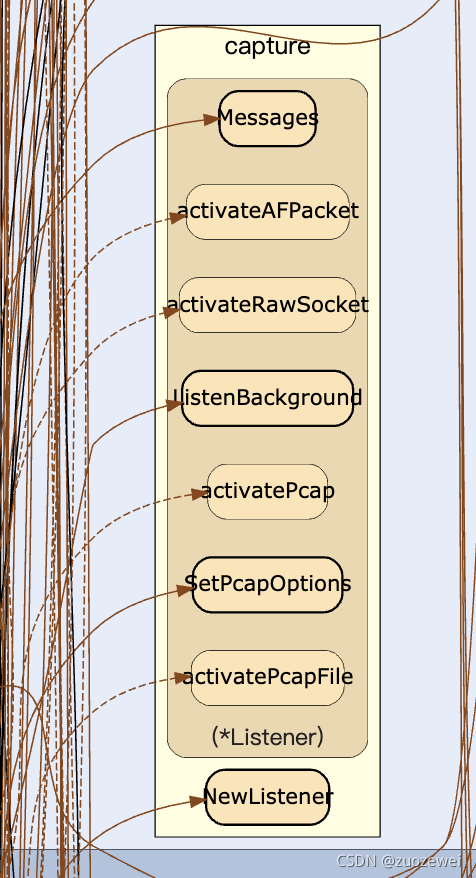
最后附送一张 gor 代码调用链路图。
原图地址:
HTTP流量神器Goreplay核心源码详解的更多相关文章
- Rank & Sort Loss for Object Detection and Instance Segmentation 论文解读(含核心源码详解)
第一印象 Rank & Sort Loss for Object Detection and Instance Segmentation 这篇文章算是我读的 detection 文章里面比较难 ...
- java中ReentrantLock核心源码详解
ReentrantLock简介 ReentrantLock是一个可重入且独占式的锁,它具有与使用synchronized监视器锁相同的基本行为和语义,但与synchronized关键字相比,它更灵活. ...
- HashMap的结构以及核心源码分析
摘要 对于Java开发人员来说,能够熟练地掌握java的集合类是必须的,本节想要跟大家共同学习一下JDK1.8中HashMap的底层实现与源码分析.HashMap是开发中使用频率最高的用于映射(键值对 ...
- Android版数据结构与算法(五):LinkedHashMap核心源码彻底分析
版权声明:本文出自汪磊的博客,未经作者允许禁止转载. 上一篇基于哈希表实现HashMap核心源码彻底分析 分析了HashMap的源码,主要分析了扩容机制,如果感兴趣的可以去看看,扩容机制那几行最难懂的 ...
- Java内存管理-掌握类加载器的核心源码和设计模式(六)
勿在流沙筑高台,出来混迟早要还的. 做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 上一篇文章介绍了类加载器分类以及类加载器的双亲委派模型,让我们能够从整体上对类加载器有 ...
- 并发编程之 SynchronousQueue 核心源码分析
前言 SynchronousQueue 是一个普通用户不怎么常用的队列,通常在创建无界线程池(Executors.newCachedThreadPool())的时候使用,也就是那个非常危险的线程池 ^ ...
- iOS 开源库系列 Aspects核心源码分析---面向切面编程之疯狂的 Aspects
Aspects的源码学习,我学到的有几下几点 Objective-C Runtime 理解OC的消息分发机制 KVO中的指针交换技术 Block 在内存中的数据结构 const 的修饰区别 block ...
- Backbone事件机制核心源码(仅包含Events、Model模块)
一.应用场景 为了改善酷版139邮箱的代码结构,引入backbone的事件机制,按照MVC的分层思想搭建酷版云邮局的代码框架.力求在保持酷版轻量级的基础上提高代码的可维护性. 二.遗留问题 1.b ...
- 6 手写Java LinkedHashMap 核心源码
概述 LinkedHashMap是Java中常用的数据结构之一,安卓中的LruCache缓存,底层使用的就是LinkedHashMap,LRU(Least Recently Used)算法,即最近最少 ...
随机推荐
- spring boot 使用 AOP 的正确姿势 --- 心得
1.前言 向spring boot转型,所有的配置基本上是用注解完成 ,以前使用spring MVC 需要写一大堆xml文件来配置. 基本上没什么变化,但是有些地方需要注意: 环绕通知不要使用异常捕获 ...
- 解决MySQL服务器禁止远程连接的问题
1. 改表法. 可能是你的帐号不允许从远程登陆,只能在localhost.这个时候只要在localhost的那台电脑,登入mysql后,更改 "mysql" 数据库里的 " ...
- 虚拟机上CentOS7网络配置
如果图片损坏:点击链接:https://www.toutiao.com/i6493449418249863693/ 设置网络 首先打开虚拟网络编辑器 权限打开 选择NAT模式,设置IP 应用确定之后, ...
- SYCOJ2205超级百钱百鸡
题目-超级百钱百鸡 (shiyancang.cn) 百钱百鸡的加强版 百钱百鸡的话,因为是有范围,所以挨个挨个尝试即可,确定两个,即可确定第三个. 超级百钱百鸡,通过题目的描述,最后可以得到一个二元的 ...
- kafka学习笔记(五)kafka的请求处理模块
概述 现在介绍学习一下kafka的请求处理模块,请求处理模块就是网络请求处理和api处理,这是kafka无论是对客户端还是集群内部都是非常重要的模块.现在我们对他进行源码深入探讨.当我们说到 Kafk ...
- 【记录一个问题】android opencl c++: 使用event.SetCallBack()方法后,在回调函数中要再使用event.wait()才能得到profile信息
如题:希望执行完成后得到各个阶段的执行时间,但是通过回调发现start, end, submit, queued等时间都是0 因此要在回调函数中再使用一次event.wait(),然后才能获得prof ...
- 带你十天轻松搞定 Go 微服务系列(二)
上篇文章开始,我们通过一个系列文章跟大家详细展示一个 go-zero 微服务示例,整个系列分十篇文章,目录结构如下: 环境搭建 服务拆分(本文) 用户服务 产品服务 订单服务 支付服务 RPC 服务 ...
- Mac系统U盘制作教程
您可以将外置驱动器或备用宗卷用作安装 Mac 操作系统的启动磁盘. 以下高级步骤主要适用于系统管理员以及熟悉命令行的其他人员.升级 macOS 或重新安装 macOS 不需要可引导安装器,但如果您要在 ...
- mysqldump 逻辑备份和物理备份
逻辑备份 逻辑备份是备份sql语句,在恢复的时候执行备份的sql语句实现数据库数据的重现. 工具:mysqldump 特点: 1.可移植性比较强 2.备份和恢复的花费时间长,不适用于大型业务系统 物理 ...
- Python中的魔术方法
什么是魔术方法? 在Python中,所有用"__"包起来的方法,都称为[魔术方法]. 魔术方法一般是为了让显示器调用的,你自己并不需要调用它们. __init__:初始化函数 这个 ...