Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】
练习1-爬取歌曲列表
任务:通过两个案例,练习使用Selenium操作网页、爬取数据。
使用无头模式,爬取网易云的内容。

'''
任务:通过两个案例,练习使用Selenium操作网页、爬取数据。
使用无头模式,爬取网易云的内容。
'''
from selenium import webdriver
# 无头模式:隐身地启动浏览器,但是并没有窗口展现
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.add_argument('--headless')
opts.add_argument('--disable-gpu')
bw = webdriver.Chrome(options=opts);
# bw = webdriver.Chrome();
url = 'https://music.163.com/#/discover/toplist?id=3779629'
bw.get(url);
bw.switch_to.frame('g_iframe')
# 如果页面中有iframe,说明有内嵌页面
# 要爬取元素时,先切换到对应的内嵌页面中,然后再爬
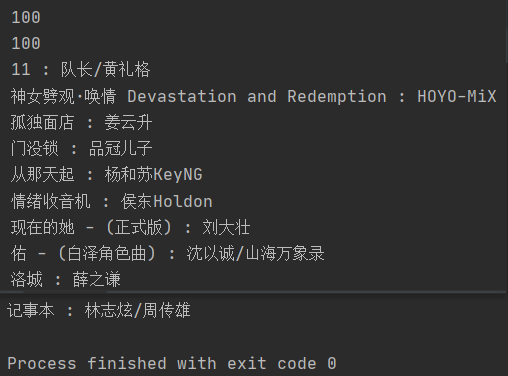
ss = bw.find_elements_by_css_selector('.m-table-rank tbody tr .txt a b');
print(len(ss)) # 100
authors = bw.find_elements_by_css_selector('.m-table-rank tbody tr .text');
print(len(authors)) # 100
for i, s in enumerate(ss):
print(s.get_attribute('title'), ':', authors[i].get_attribute('title'));
bw.close();练习2-爬取歌曲文件mp3
网易云:能不能爬取音乐???可以!能不能爬歌词???可以!
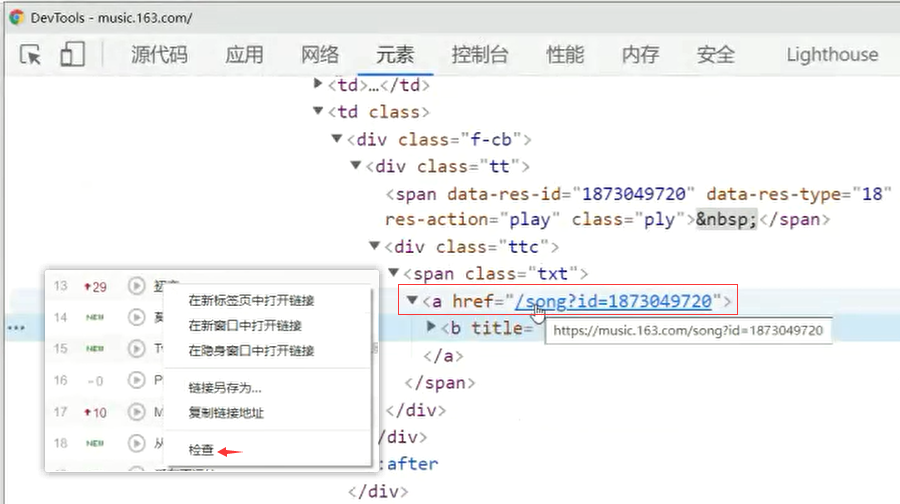
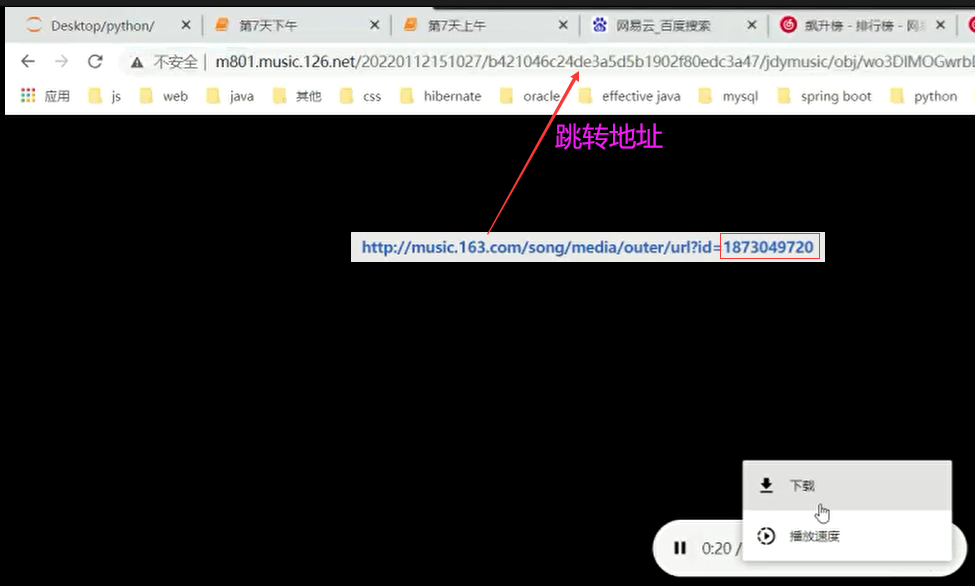
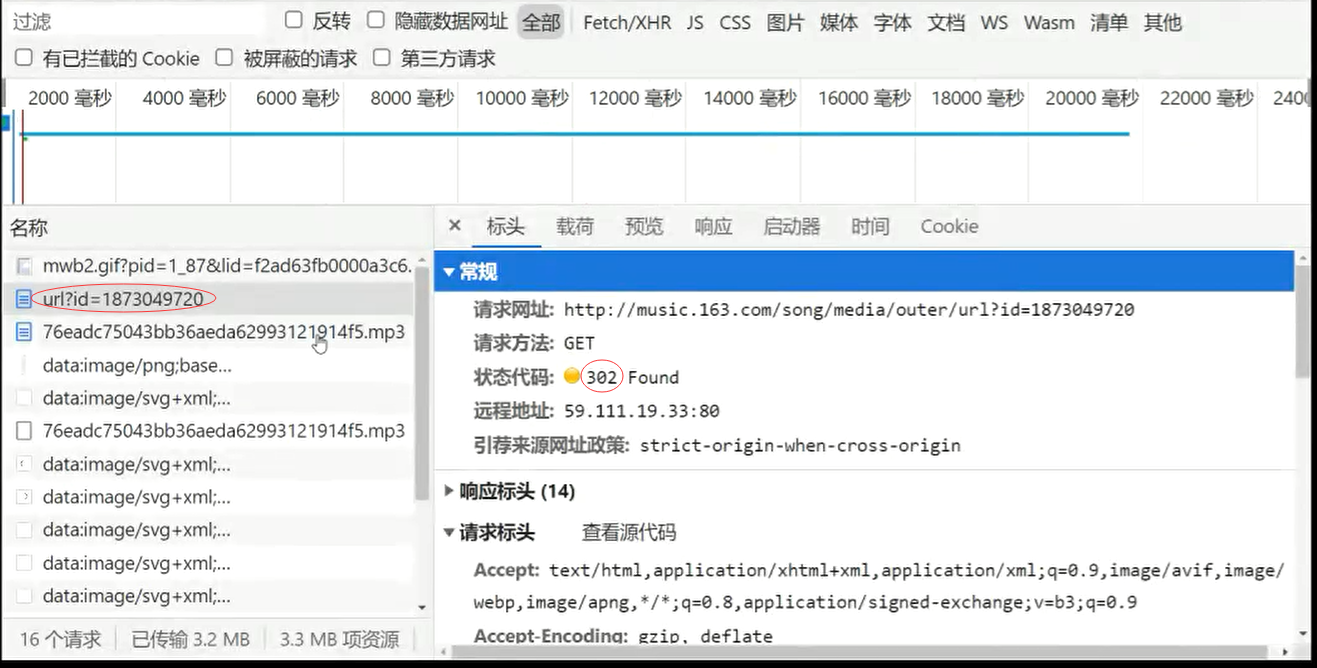
网易云音乐,歌曲通用下载地址:http://music.163.com/song/media/outer/url?id= [ id后面拼接歌曲编号 ]


'''
尝试下载,requests访问,得到二进制数据,保存到本地即可
爬取网易云音乐的歌曲mp3文件(单个歌曲下载)
《初恋》歌曲id: 1873049720
《清醒》歌曲id:1909660296
《星辰大海》歌曲id:1811921555
'''
import requests as req
# hds:伪装成浏览器
hds = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
common_url = 'http://music.163.com/song/media/outer/url?id={}'; # 通用下载路径
resp = req.get(common_url.format('1909660296'), headers=hds);
ct = resp.content; # 响应内容
print(len(ct)) # 响应内容长度
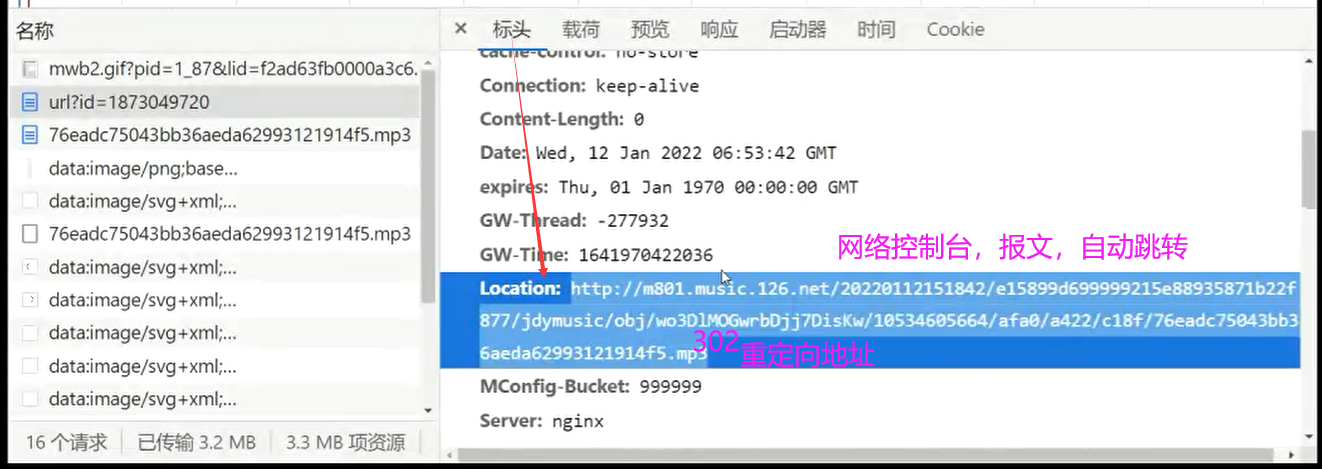
print(resp.status_code); # 200正常;302重定向,需要继续获取重定向后的路径
# print(resp.headers)
# u2 = resp.headers['Location'];
# print(u2) # 继续爬取u2路径,来下载音乐
if resp.status_code == 200:
with open(r'C:\Users\lwx\Desktop\网易云\清醒.mp3', 'wb') as f: # as f取别名,简写
f.write(ct);
# 上述两行代码(简写),在效果上等于下面三行代码。
# f = open(r'C:\Users\lwx\Desktop\网易云\清醒.mp3', 'wb')
# f.write(ct)
# f.close()
print('over!')练习3-下载飙升榜中的歌曲
结合上午的代码和刚才下载音乐的办法,请尝试:将飙升榜中的前20首歌曲下载(尝试下载)。
https://music.163.com/#/discover/toplist 15分钟时间
import requests as req
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
hds = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
def wydown(songname, songid):
common_url = 'http://music.163.com/song/media/outer/url?id={}';
resp = req.get(common_url.format(songid), headers=hds);
ct = resp.content;
# print(len(ct))
# print(resp.status_code); #200正常 302重定向,需要继续获取重定向后的路径
if resp.status_code == 200:
f = open(r'C:\Users\qx\Desktop\网易云\{}.mp3'.format(songname), 'wb')
f.write(ct);
f.close();
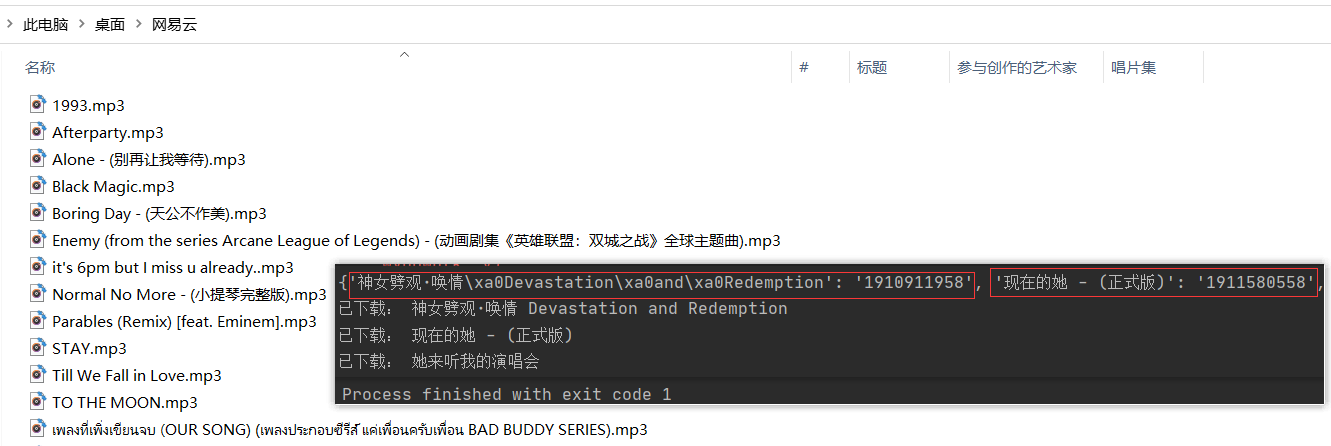
print('已下载:', songname);
# 无头模式 : 隐身的启动浏览器,但是并没有窗口展现
opts = Options()
opts.add_argument('--headless')
opts.add_argument('--disable-gpu')
bw = webdriver.Chrome(options=opts);
url = 'https://music.163.com/#/discover/toplist'
bw.get(url);
bw.switch_to.frame('g_iframe');
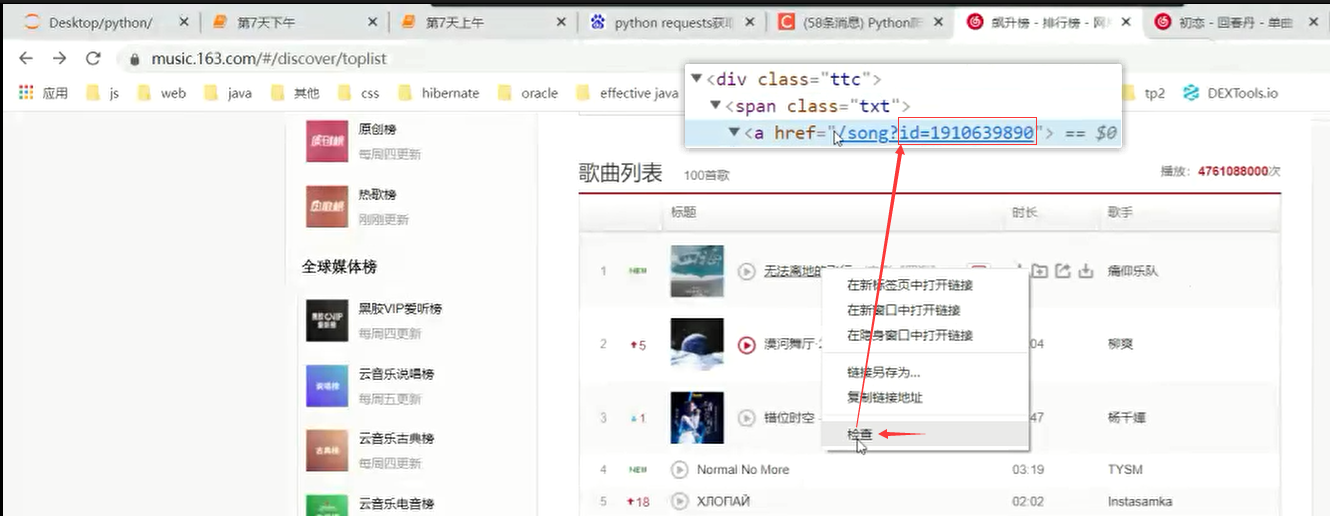
ss = bw.find_elements_by_css_selector('.m-table-rank tbody tr .txt a b');
ids = bw.find_elements_by_css_selector('.m-table-rank tbody tr .txt a');
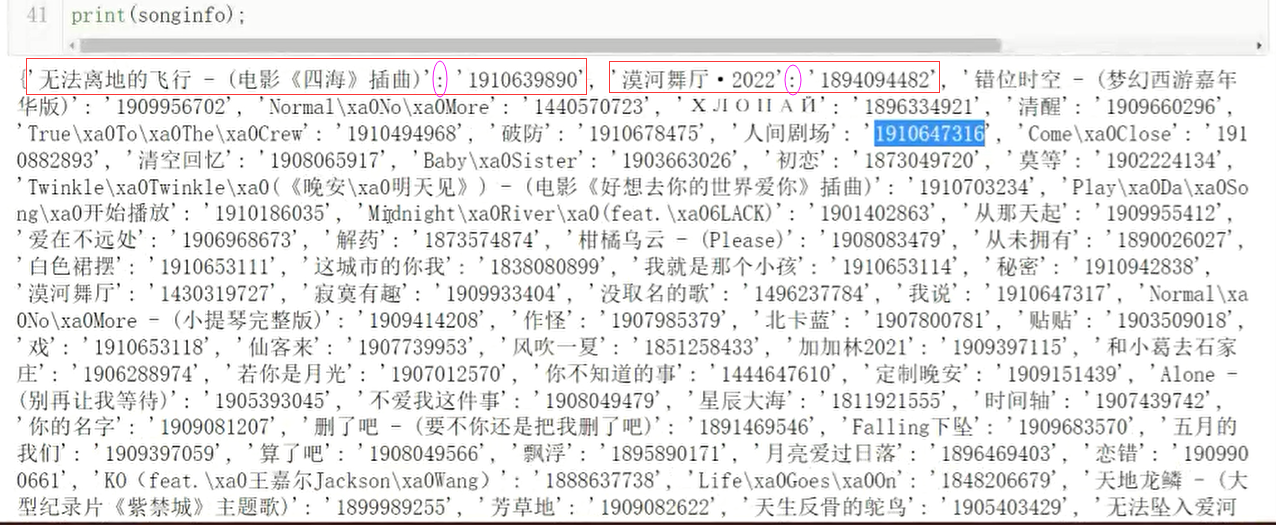
songinfo = {}; # 歌曲名:歌曲id
for i, s in enumerate(ss):
songinfo[s.get_attribute('title')] = ids[i].get_attribute('href').split("=")[1];
bw.close();
# print(songinfo);
# 遍历字典,下载所有歌曲
for k, v in songinfo.items():
wydown(k, v);Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】的更多相关文章
- Python-异常处理 使用selenium库自动爬取数据
异常处理 处理程序的报错 语法 捕捉万能异常: try: print(a) except Exception as e: print("你的代码有问题") print(" ...
- [Python爬虫] 之三:Selenium 调用IEDriverServer 抓取数据
接着上一遍,在用Selenium+phantomjs 抓取数据过程中发现,有时候抓取不到,所以又测试了用Selenium+浏览器驱动的方式:具体代码如下: #coding=utf-8import os ...
- Python爬虫学习——使用selenium和phantomjs爬取js动态加载的网页
1.安装selenium pip install selenium Collecting selenium Downloading selenium-3.4.1-py2.py3-none-any.wh ...
- python 网页爬取数据生成文字云图
1. 需要的三个包: from wordcloud import WordCloud #词云库 import matplotlib.pyplot as plt #数学绘图库 import jieba; ...
- 动态网页爬取例子(WebCollector+selenium+phantomjs)
目标:动态网页爬取 说明:这里的动态网页指几种可能:1)需要用户交互,如常见的登录操作:2)网页通过JS / AJAX动态生成,如一个html里有<div id="test" ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- Python和BeautifulSoup进行网页爬取
在大数据.人工智能时代,我们通常需要从网站中收集我们所需的数据,网络信息的爬取技术已经成为多个行业所需的技能之一.而Python则是目前数据科学项目中最常用的编程语言之一.使用Python与Beaut ...
- [Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息 2018-07-21 23:53:02 larger5 阅读数 4123更多 分类专栏: 网络爬虫 版权声明: ...
- 利用selenium和ffmpeg爬取m3u8 ts视频《进击的巨人》
需求 想看下动漫<进击的巨人>,发现到处被和谐,找不到资源,但是在一个视频网站找到了在线播放,https://www.55cc.cc/dongman/17890/player-2-1.ht ...
随机推荐
- presto官网阅读记录: Functions and Operators 部分
官网Functions and Operators部分 版本:0.266 目录 官网Functions and Operators部分 1 Comparison Functions and Opera ...
- 摘要任务工期计算(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 先说一个好消息:摘要工期是可以自动计算的. 比如A1.A2.A3.A4四个任务,工期如下图安排: 而他们的摘要任务,就不再 ...
- 用 shell 脚本做自动化测试
前言 项目中有一个功能,需要监控本地文件系统的变更,例如文件的增.删.改名.文件数据变动等等.之前只在 windows 上有实现,采用的是 iocp + ReadDirectoryChanges 方案 ...
- CF132A Turing Tape 题解
Content 读入一个字符串 \(s\),让你用以下规则将字符串中的所有字符转换成数字: 先将这个字符的 \(\texttt{ASCII}\) 码的 \(8\) 位 \(2\) 进制数反转,再将这个 ...
- 一、Uniapp+vue+腾讯IM+腾讯音视频开发仿微信的IM聊天APP,支持各类消息收发,音视频通话,附vue实现源码(已开源)-项目引言
项目文章索引 1.项目引言 2.腾讯云后台配置TXIM 3.配置项目并实现IM登录 4.会话好友列表的实现 5.聊天输入框的实现 6.聊天界面容器的实现 7.聊天消息项的实现 8.聊天输入框扩展面板的 ...
- 『学了就忘』Linux日志管理 — 92、日志轮替
目录 1.日志文件的命名规则 2.logrotate配置文件说明 3.logrotate配置文件的主要参数 1.日志文件的命名规则 日志轮替最主要的作用就是把旧的日志文件移动并改名,同时建立新的空日志 ...
- vim操作(复制,粘贴)
整行操作 单行复制 在"命令"模式下,将光标移动到将要复制的行处,按"yy"进行复制 多行复制 在"命令"模式下,将光标移动到将要复制的首行 ...
- 使用WebUploader进行文件图片上传
官方文档:http://fex.baidu.com/webuploader/getting-started.html 引入Webuploader的css和js文件,下载地址:http://fex.ba ...
- WEB文档在线预览解决方案
web页面无法支持预览office文档,但是却可以预览PDF.flash文档,所以大多数解决方案都是在服务端将office文档转换为pdf,然后再通过js的pdf预览插件(谷歌浏览器等已经原生支持嵌入 ...
- 如何跳出springboot的service层中某一个方法?
有一个需求,就是中断某个方法中的for循环 目前的做法是:for循环中,增加if判断,如果满足条件就return,会中断这个方法 for (int i = 0; i < totalIndex; ...