硬盘分区形式(MBR、GPT)、系统引导、文件系统、Inode和Block
目录
文件系统(FAT16、32、NTFS和EXT2、3、4、Xfs、Tmpfs)
MBR和GPT
新买一块硬盘,设置分区时,系统会询问你是想要使用MBR分区形式还是GPT分区形式(有些硬盘出厂的时候就默认给你设定了分区形式)。MBR是以前的分区形式,GPT是一种新的分区形式,现在逐渐取代MBR分区形式。
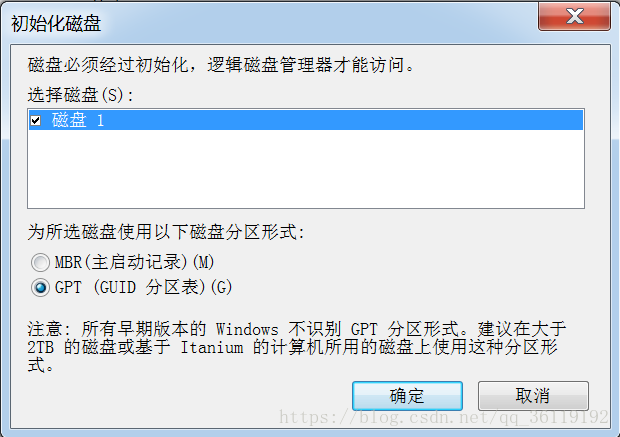
GPT带来了很多新特性,但MBR仍然拥有最好的兼容性。GPT并不是Windows专用的新标准—— Mac OS X,Linux,及其他操作系统同样使用GPT。在使用新磁盘之前,你必须对其进行分区。MBR(Master Boot Record)和GPT(GUID Partition Table)是在磁盘上存储分区信息的两种不同方式。这些分区信息包含了分区从哪里开始,这样操作系统才知道哪个扇区是属于哪个分区的,以及哪个分区是可以启动的。在磁盘上创建分区时,你必须在MBR和GPT之间做出选择。目前有且只有这两种分区形式。
MBR的局限性
MBR的意思是“主引导记录”,最早在1983年在IBM PC DOS 2.0中提出。之所以叫“主引导记录”,是因为它是存在于驱动器开始部分的一个特殊的启动扇区。这个扇区包含了驱动器的分区信息(64个字节,大小固定,一个分区用16个字节记录)和已安装的操作系统的启动加载器(446字节)和2个字节的结束标志,所以这个扇区的大小是512个字节。。所谓启动加载器,是一小段代码,用于加载驱动器上其他分区上更大的加载器。如果你安装了Windows,Windows启动加载器的初始信息就放在这个区域里——如果MBR的信息被覆盖导致Windows不能启动,你就需要使用Windows的MBR修复功能来使其恢复正常。如果你安装了Linux,则位于MBR里的通常会是GRUB加载器。MBR支持最大2TB磁盘,它无法处理大于2TB容量的磁盘。MBR还只支持最多4个主分区——如果你想要更多分区,你需要创建所谓“扩展分区”,并在其中创建逻辑分区。MBR已经成为磁盘分区和启动的工业标准。
GPT的优势
GPT意为GUID分区表。(GUID意为全局唯一标识符)。这是一个正逐渐取代MBR的新标准。它和UEFI相辅相成——UEFI用于取代老旧的BIOS,而GPT则取代老旧的MBR。之所以叫作“GUID分区表”,是因为你的驱动器上的每个分区都有一个全局唯一的标识符(globally unique identifier,GUID)——这是一个随机生成的字符串,可以保证为地球上的每一个GPT分区都分配完全唯一的标识符。这个标准没有MBR的那些限制。磁盘驱动器容量可以大得多,大到操作系统和文件系统都没法支持。它同时还支持几乎无限个分区数量,限制只在于操作系统——Windows支持最多128个GPT分区,GPT硬盘上没有主分区、扩展分区的概念,所有的分区都是叫分区。在MBR磁盘上,分区和启动信息是保存在一起的。如果这部分数据被覆盖或破坏,事情就麻烦了。相对的,GPT在整个磁盘上保存多个这部分信息的副本,因此它更为健壮,并可以恢复被破坏的这部分信息。GPT还为这些信息保存了循环冗余校验码(CRC)以保证其完整和正确——如果数据被破坏,GPT会发觉这些破坏,并从磁盘上的其他地方进行恢复。而MBR则对这些问题无能为力——只有在问题出现后,你才会发现计算机无法启动,或者磁盘分区都不翼而飞了。
GPT的兼容性
可以看到,在GTP磁盘的第一个数据块中同样有一个与MBR(主引导记录)类似的标记,叫做PMBR(保护下MBR)。PMBR的作用是,当使用不支持GPT的分区工具时,整个硬盘将显示为一个受保护的分区,以防止分区表及硬盘数据遭到破坏。UEFI并不从PMBR中获取GPT磁盘的分区信息,它有自己的分区表,即GPT分区表。
主分区、扩展分区和逻辑分区
这几个名词是在MBR中才有的,因为GPT支持无限多个主分区。倘若你使用的是MBR的分区形式,那么你将最少拥有一个、最多只能有四个主分区;如果你想要有更多的分区,那么你将要建立扩展分区,然后在扩展分区里面在新建多个逻辑分区。且主分区+扩展分区的数量不超过四个;扩展分区可以没有,最多只能有一个;逻辑分区可以没有,也可以有多个。扩展分区不能包围在主分区之间。
激活的主分区是硬盘的启动分区,他是独立的,也是硬盘的第一个分区,正常分的话就是C驱。 分出主分区后,其余的部分可以分成扩展分区,一般是剩下的部分全部分成扩展分区,也可以不全分,那剩下的部分就浪费了。但扩展是不能直接用的,他是以逻辑分区的方式来使用的,所以说扩展分区可分成若干个逻辑分区。他们的关系是包含的关系,所有的逻辑分区都是扩展分区的一部分。 在linux中相当于hda分区。
硬盘的容量=主分区的容量+扩展分区的容量
扩展分区的容量=各个逻辑分区的容量之和
在MBR分区表中最多4个主分区或者3个主分区+1个扩展分区,也就是说扩展分区只能有一个,然后可以再细分为多个逻辑分区。
在Linux系统中,硬盘分区命名为 sda1~sda4 或者 hda1~hda4(sd表示SCSI硬盘,hd表示IDE硬盘,其中a表示硬盘编号,如果有多块硬盘,那就是b、c、d;1代表第一块分区,2代表第二块分区,以此类推)。在MBR硬盘中,分区号1-4是主分区(或者扩展分区),逻辑分区号只能从5开始
如图,磁盘1中F、G、H盘是主分区,I+K+J是扩展分区,I、K、J 是逻辑分区 。
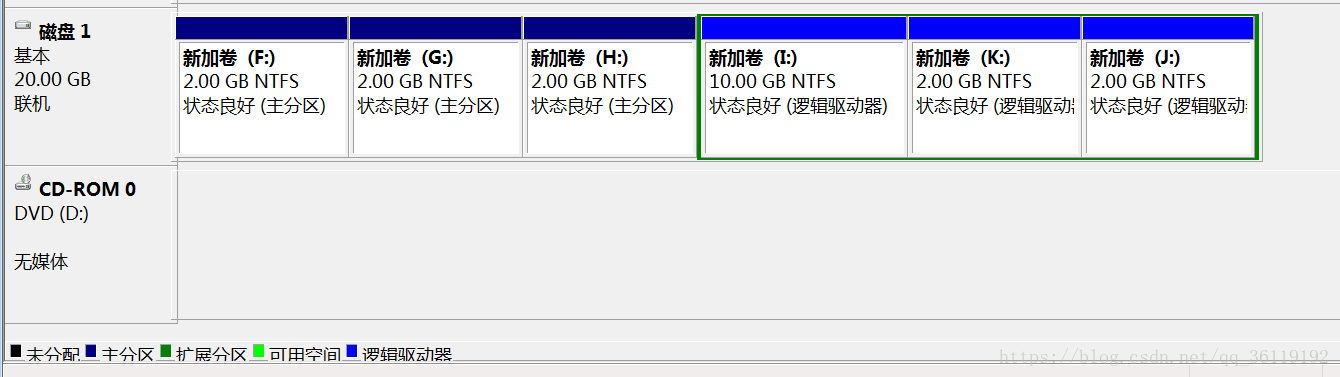
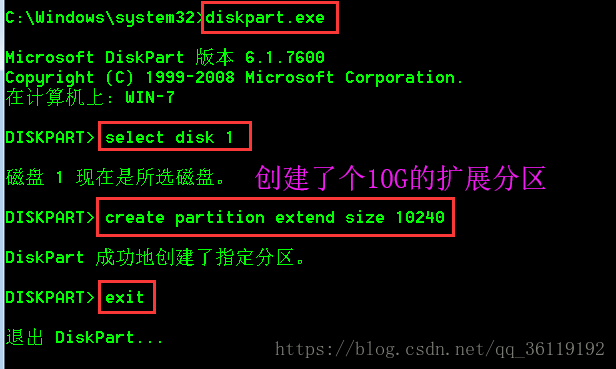
在windows中,默认只有你建立了3个主分区后,才会建立扩展分区。如果我们想直接建立扩展分区的话,可以使用命令
挂接卷
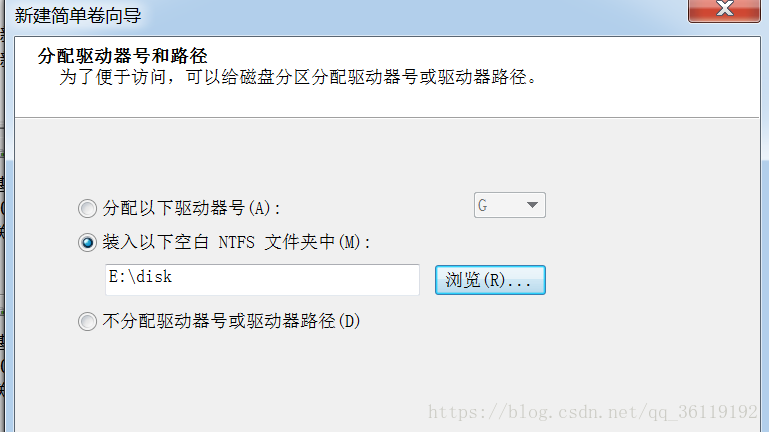
在windows中,虽然GPT分区可以建立高达128个主分区,但是驱动器号只有26个(A-Z)。如果驱动器号满了该怎么办?我们可以使用挂接卷,将新的分区挂载在现有的文件夹下,通过访问该文件夹即可访问新分区。这和Linux中的挂载类似。挂接卷只需要在分区初始化的时候选择即可。
Legacy、UEFI引导和GRUB引导
Legacy 和 UEFI 均是windows的引导方式。Legacy是老式的Legacy BIOS引导,引导文件为 winload.exe,通常是和MBR分区形式结合使用。也就是 MBR分区形式+Legacy引导。
而UEFI是windows新式的引导方式,引导文件为 winload.efi,通常是和GPT分区形式结合使用,也就是 GPT分区形式+UEFI引导。
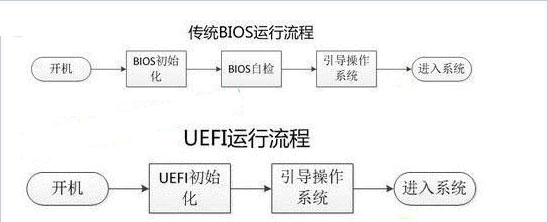
由此可见,UEFI在开机方面相比BIOS少了自检这一步,它把硬件信息存在了硬盘里,直接读取,因此它的启动速度更快;UEFI是BIOS的一种升级替代方案,UEFI之所以比Legacy BIOS强大,是因为UEFI本身已经相当于一个微型操作系统,其带来的便利之处在于:UEFI已具备文件系统的支持,它能够直接读取FAT分区中的文件;
如果电脑是在UEFI模式下安装的系统只能选择UEFI模式引导,要是在Legacy模式下安装的系统就要在Legacy模式下进系统。
GRUB(GRand Unified Bootloader)是一个来自GNU项目的多操作系统启动程序。GRUB是多启动规范的实现,它允许用户可以在计算机内同时拥有多个操作系统,并在计算机启动时选择希望运行的操作系统。GRUB可用于选择操作系统分区上的不同内核,也可用于向这些内核传递启动参数。Linux、BSD或其他的类unix基本都是用GRUB引导系统。目前,GRUB分为GRUB Legacy和GRUB 2。
文件系统(FAT16、32、NTFS和EXT2、3、4、Xfs、Tmpfs)
文件系统是操作系统用于明确磁盘或分区上的文件的方法和数据结构;即在磁盘上组织文件的方法。一块分区必须要有文件系统才可以使用。
举个通俗的比喻,一块硬盘就像一个块空地,文件就像不同的材料,我们首先得在空地上建起仓库(分区),并且指定好(格式化)仓库对材料的管理规范(文件系统),这样才能将材料运进仓库保管。
文件系统是对应硬盘的分区的,而不是整个硬盘,不管是硬盘只有一个分区,还是几个分区,不同的分区可以有着不同的文件系统!
Windows中的文件系统
在windows下,主要有FAT16 、FAT32 、NTFS文件系统。
各个文件系统的区别如下:
| NTFS文件格式 | FAT32文件格式 | FAT16文件格式 |
|---|---|---|
| 支持单个分区最大2TB | 支持单个分区最大128GB | 支持单个分区最大2GB |
| 支持单个文件最大2TB | 支持单个最大文件4GB | 支持单个最大文件2GB |
| 支持磁盘配额 | 不支持磁盘配额 | 不支持磁盘配额 |
| 支持文件压缩(系统 ) | 不支持文件压缩(系统) | 不支持文件压缩(系统 ) |
| 支持EFS文件加密系统 | 不支持EFS | 不支持EFS |
| 产生的磁盘碎片较少 | 产生的磁盘碎片适中 | 产生的磁盘碎片较多 |
| 适合于大磁盘分区 | 适合于中小磁盘分区 | 适合于小与2G的磁盘分区 |
| 支持WindowsNT | 支持9x,不支持NT4.0 | 不支持Win2000,支持NT,9x |
NTFS相比FAT32与FAT16优点:
- 最大优点在于文件加密;
- 另外一个优点就是能够很好的支持大硬盘,且硬盘分配单元非常小,从而减少了磁盘碎片的产生。NTFS更适合现今硬件配置(大硬盘)和操作系统(windows10)
- NTFS文件系统相比FAT32具有更好的安全性,表现在对不同用户对不同文件/文件夹设置的访问权限上
- 而且CIH病毒在NTFS文件系统下是没有办法传播的!
FAT32文件系统转换为NTFS文件系统
如果转化的分区是系统分区或虚拟内存使用的磁盘分区,需要重启才能转化。
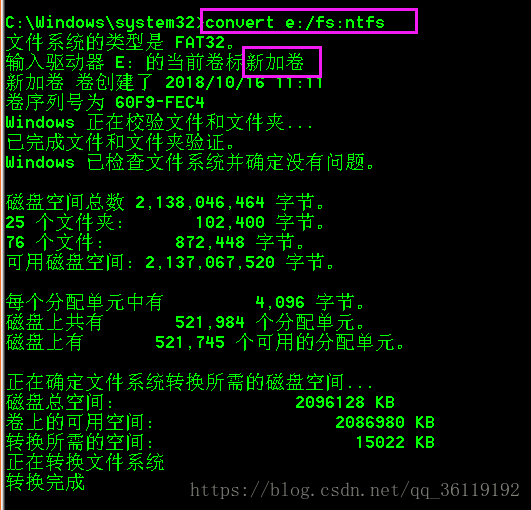
转换命令:convert e:/fs:ntfs 按回车键,会叫你输入当前的卷标,也就是盘符的名字,我的E盘卷标是: 新加卷 。回车,完成转换。 这种方法转换 FAT32 分区上的数据不丢失,该命令不能从 NTFS 转化为 FAT32,除非把数据拷贝到其他分区,重新格式化该分区为 FAT32。
比如我现在的E盘是FAT32的文件系统,我现在需要把它转换为 NTFS的文件系统,我的E盘上还有数据,转换后E盘上的数据依旧还在
Linux中的文件系统
在Linux下,主要有EXT2、3、4和swap、Tmpfs文件系统,称为扩展文件系统。
Linux ext2/ext3文件系统使用索引节点来记录文件信息,作用像windows的文件分配表。索引节点是一个结构,它包含了一个文件的长度、创建及修改时间、权限、所属关系、磁盘中的位置等信息。一个文件系统维护了一个索引节点的数组,每个文件或目录都与索引节点数组中的唯一一个元素对应。系统给每个索引节点分配了一个号码,也就是该节点在数组中的索引号,称为索引节点号。 linux文件系统将文件索引节点号和文件名同时保存在目录中。所以,目录只是将文件的名称和它的索引节点号结合在一起的一张表,目录中每一对文件名称和索引节点号称为一个连接。 对于一个文件来说有唯一的索引节点号与之对应,对于一个索引节点号,却可以有多个文件名与之对应。因此,在磁盘上的同一个文件可以通过不同的路径去访问它。Linux之前缺省情况下使用的文件系统为Ext2,ext2文件系统的确高效稳定。但是,随着Linux系统在关键业务中的应用,Linux文件系统的弱点也渐渐显露出来了:其中系统缺省使用的ext2文件系统是非日志文件系统。这在关键行业的应用是一个致命的弱点。
于是EXT3文件系统应运而生,Ext3文件系统是直接从Ext2文件系统发展而来,目前ext3文件系统已经非常稳定可靠。它完全兼容ext2文件系统。用户可以平滑地过渡到一个日志功能健全的文件系统中来。这实际上了也是ext3日志文件系统初始设计的初衷。
Ext3日志文件系统的特点
1、高可用性
系统使用了ext3文件系统后,即使在非正常关机后,系统也不需要检查文件系统。宕机发生后,恢复ext3文件系统的时间只要数十秒钟。
2、数据的完整性:
ext3文件系统能够极大地提高文件系统的完整性,避免了意外宕机对文件系统的破坏。在保证数据完整性方面,ext3文件系统有2种模式可供选择。其中之一就是“同时保持文件系统及数据的一致性”模式。采用这种方式,你永远不再会看到由于非正常关机而存储在磁盘上的垃圾文件。
3、文件系统的速度:
尽管使用ext3文件系统时,有时在存储数据时可能要多次写数据,但是,从总体上看来,ext3比ext2的性能还要好一些。这是因为ext3的日志功能对磁盘的驱动器读写头进行了优化。所以,文件系统的读写性能较之Ext2文件系统并来说,性能并没有降低。
4、数据转换
由ext2文件系统转换成ext3文件系统非常容易,只要简单地键入两条命令即可完成整个转换过程,用户不用花时间备份、恢复、格式化分区等。用一个ext3文件系统提供的小工具tune2fs,它可以将ext2文件系统轻松转换为ext3日志文件系统。另外,ext3文件系统可以不经任何更改,而直接加载成为ext2文件系统。
5、多种日志模式
Ext3有多种日志模式,一种工作模式是对所有的文件数据及metadata(定义文件系统中数据的数据,即数据的数据)进行日志记录(data=journal模式);另一种工作模式则是只对metadata记录日志,而不对数据进行日志记录,也即所谓data=ordered或者data=writeback模式。系统管理人员可以根据系统的实际工作要求,在系统的工作速度与文件数据的一致性之间作出选择。
EXT4文件系统:Linux kernel 自 2.6.28 开始正式支持新的文件系统 Ext4。 Ext4 是 Ext3 的改进版,修改了 Ext3 中部分重要的数据结构,而不仅仅像 Ext3 对 Ext2 那样,只是增加了一个日志功能而已。Ext4 可以提供更佳的性能和可靠性,还有更为丰富的功能:
1. 与 Ext3 兼容。 执行若干条命令,就能从 Ext3 在线迁移到 Ext4,而无须重新格式化磁盘或重新安装系统。原有 Ext3 数据结构照样保留,Ext4 作用于新数据,当然,整个文件系统因此也就获得了 Ext4 所支持的更大容量。
2. 更大的文件系统和更大的文件。 较之 Ext3 目前所支持的最大 16TB 文件系统和最大 2TB 文件,Ext4 分别支持 1EB(1,048,576TB, 1EB=1024PB, 1PB=1024TB)的文件系统,以及 16TB 的文件。
3. 无限数量的子目录。 Ext3 目前只支持 32,000 个子目录,而 Ext4 支持无限数量的子目录。
4. Extents。 Ext3 采用间接块映射,当操作大文件时,效率极其低下。比如一个 100MB 大小的文件,在 Ext3 中要建立 25,600 个数据块(每个数据块大小为 4KB)的映射表。而 Ext4 引入了现代文件系统中流行的 extents 概念,每个 extent 为一组连续的数据块,上述文件则表示为“该文件数据保存在接下来的 25,600 个数据块中”,提高了不少效率。
5. 多块分配。 当写入数据到 Ext3 文件系统中时,Ext3 的数据块分配器每次只能分配一个 4KB 的块,写一个 100MB 文件就要调用 25,600 次数据块分配器,而 Ext4 的多块分配器“multiblock allocator”(mballoc) 支持一次调用分配多个数据块。
6. 延迟分配。 Ext3 的数据块分配策略是尽快分配,而 Ext4 和其它现代文件操作系统的策略是尽可能地延迟分配,直到文件在 cache 中写完才开始分配数据块并写入磁盘,这样就能优化整个文件的数据块分配,与前两种特性搭配起来可以显著提升性能。
7. 快速 fsck。 以前执行 fsck 第一步就会很慢,因为它要检查所有的 inode,现在 Ext4 给每个组的 inode 表中都添加了一份未使用 inode 的列表,今后 fsck Ext4 文件系统就可以跳过它们而只去检查那些在用的 inode 了。
8. 日志校验。 日志是最常用的部分,也极易导致磁盘硬件故障,而从损坏的日志中恢复数据会导致更多的数据损坏。Ext4 的日志校验功能可以很方便地判断日志数据是否损坏,而且它将 Ext3 的两阶段日志机制合并成一个阶段,在增加安全性的同时提高了性能。
9. “无日志”(No Journaling)模式。 日志总归有一些开销,Ext4 允许关闭日志,以便某些有特殊需求的用户可以借此提升性能。
10. 在线碎片整理。 尽管延迟分配、多块分配和 extents 能有效减少文件系统碎片,但碎片还是不可避免会产生。Ext4 支持在线碎片整理,并将提供 e4defrag 工具进行个别文件或整个文件系统的碎片整理。
11. inode 相关特性。 Ext4 支持更大的 inode,较之 Ext3 默认的 inode 大小 128 字节,Ext4 为了在 inode 中容纳更多的扩展属性(如纳秒时间戳或 inode 版本),默认 inode 大小为 256 字节。Ext4 还支持快速扩展属性(fast extended attributes)和 inode 保留(inodes reservation)。
12. 持久预分配(Persistent preallocation)。 P2P 软件为了保证下载文件有足够的空间存放,常常会预先创建一个与所下载文件大小相同的空文件,以免未来的数小时或数天之内磁盘空间不足导致下载失败。 Ext4 在文件系统层面实现了持久预分配并提供相应的 API(libc 中的 posix_fallocate()),比应用软件自己实现更有效率。
13. 默认启用 barrier。 磁盘上配有内部缓存,以便重新调整批量数据的写操作顺序,优化写入性能,因此文件系统必须在日志数据写入磁盘之后才能写 commit 记录,若 commit 记录写入在先,而日志有可能损坏,那么就会影响数据完整性。Ext4 默认启用 barrier,只有当 barrier 之前的数据全部写入磁盘,才能写 barrier 之后的数据。(可通过 "mount -o barrier=0" 命令禁用该特性。)
xfs文件系统是扩展文件系统的一个扩展,它是SGI公司设计的。xfs被称为业界最先进的、最具可升级性的文件系统技术。Xfs就是用为大容量大空间而设计的,在数据量特别大的情况下,建议用Xfs文件系统。但是,在文件比较多,目录比较多的环境下,其实Xfs的性能还不如ext4文件系统。
xfs是一个64位文件系统,最大支持8EB减1字节的单个文件系统,实际部署时取决于宿主操作系统的最大块限制。对于一个32位Linux系统,文件和文件系统的大小会被限制在16TB。
swap分区:Linux内核为了提高读写效率与速度,会将文件在内存中进行缓存,这部分内存就是Cache Memory(缓存内存)。即使你的程序运行结束后,Cache Memory也不会自动释放。这就会导致你在Linux系统中程序频繁读写文件后,你会发现可用物理内存变少。当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到Swap分区空间中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。这样,系统总是在物理内存不够时,才进行Swap交换。
tmpfs文件系统是Linux/Unix系统上的一种基于内存的虚拟文件系统。tmpfs可以使用您的内存或swap分区来存储文件(即它的存储空间在virtual memory 中, VM由real memory和swap组成),所以 tmpfs的大小等于real memory+swap的大小。由此可见,tmpfs主要存储暂存的文件。它有如下2个优势 : 1. 动态文件系统的大小。2. tmpfs 使用VM建的文件系统,速度当然快。3.重启后数据丢失。
当删除tmpfs中的文件时,tmpfs会动态减少文件系统并释放VM资源,LINUX中可以把一些程序的临时文件放置在tmpfs中,利用tmpfs比硬盘速度快的特点提升系统性能。实际应用中,为应用的特定需求设定此文件系统,可以提升应用读写性能,如将squid 缓存目录放在/tmp, php session 文件放在/tmp, socket文件放在/tmp, 或者使用/tmp作为其它应用的缓存设备。
devtmpfs文件系统 的作用是在 Linux 核心启动早期建立一个初步的 /dev,令一般启动程序不用等待 udev,缩短 GNU/Linux 的开机时间。
inode block superblock
操作系统的文件数据除了文件实际内容外,还有非常多的属性,如文件权限(rwx)与文件属性(所有者、群组、时间参数等)。
文件系统通常将这两部分数据存放在不同的块。权限属性放到 inode 中,实际数据放到 data block 中。还有一个超级块(super block)会记录文件系统的整体信息,包括 inode 与block 的数量、使用量等。
inode:记录文件属性,一个文件占用一个inode,同时记录此文件的数据所在的block号码,硬链接的inode相等,软链接的不相等;
block:实际记录文件的内容,若文件太大时会占用多个 block ;
super block:记录文件系统的整体信息,包括inode/block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等。
每个inode与block都有编号,而每个文件系统都会占用一个inode,inode中有文件数据放置的block号码。我们可以找到文件的inode,然后找出文件所放置数据的block号码,之后读出数据。这种数据访问方式成为索引式文件系统。这种文件系统一般不太需要经常进行磁盘碎片整理。
而 U 盘等为FAT文件格式,每个block号码都记录在前一个block号码中,因此数据的读取性能较差,用久了得进行碎片整理。
linux的Ext2文件系统一开始就将 inode 与block规划好了,除非重新格式化(或者利用resize2fs等命令更改文件系统大小),否则 inode 与block 固定后就不再变动。
如果文件系统太大,将所有的inode 与 block 放在一起很难管理,因此Ext2文件系统在格式化的时候基本上是区分为多个块组(block group),每个块组都有独立的inode/block/super block系统。
data block (数据块)
Ext2 文件系统支持的block 有 1K,2K,4K三种。在格式化时 block已经固定,且每个block都有编号。但要注意,由于block大小不同,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量并不相同。使用的block太小,则一个文件要用多两个block,inode 记录也会增加,降低读写性能。
若block太大,文件小的时候则会使剩余空间不能用了,会浪费资源。
Superblock (超级块)
这里面记录文件系统的整体情况。比如文件系统的挂载时间、最近一次写入数据的时间、最近一次检验磁盘(fsck)的时间等。还有一个validbit数值,若此文件系统已经被挂载,validbit的值为 0 ,若未被挂载,则validbit值为 1 。
相关文章:Linux下磁盘分区、卸载和磁盘配额
硬盘分区形式(MBR、GPT)、系统引导、文件系统、Inode和Block的更多相关文章
- 安装grub到U盘分区,实现多系统引导
目录 1.分区工具及分区类型 1.1 显示分区表和分区信息 1.1.1 fdisk -l 1.1.2 gdisk -l 1.1.3 parted -l 1.2 常见分区类型 1.3 分区样例 1.3. ...
- 机械硬盘换到SSD后系统引导报错代码0xc000000e
由于机械硬盘IO不够用,系统使用起来非常的缓慢,特意购买了新的SSD进行了替换.机械硬盘的IO在70左右,SSD的IO在1000-4000左右指普通消费SSD. 由于不想安装系统,就直接把机械硬盘的数 ...
- Linux文件系统inode、block解释权限(三)
利用文件系统的inode和block来分析文件(目录)的权限问题. 为什么读取一个文件还要看该文件路径所有目录的权限? 为什么目录的w权限具有删除文件的能力,而文件w权限不行. inode:记录文件的 ...
- 图解MBR分区无损转换GPT分区+UEFI引导安装WIN8.1
确定你的主板支持UEFI引导.1,前期准备,WIN8.1原版系统一份(坛子里很多,自己下载个),U盘2个其中大于4G一个(最好 准备两个U盘)2,大家都知道WIN8系统只支持GPT分区,传统的MBR分 ...
- linux基础-第十三单元 硬盘分区、格式化及文件系统的管理二
第十三单元 硬盘分区.格式化及文件系统的管理二 文件系统的挂载与卸载 什么是挂载 mount命令的功能 mount命令的用法举例 umount命令的功能 umount命令的用法举例 利用/etc/fs ...
- 装系统 ---------- 了解 UEFI与Legacy、硬盘分区MBR和GPT
UEFI:全称“统一的可扩展固件接口”(Unified Extensible Firmware Interface),一种详细描述类型接口的标准.这种接口用于操作系统自动从预启动的操作环境,加载到一种 ...
- [转]硬盘的那些事(主分区、扩展分区、逻辑分区、活动分区、系统分区、启动分区、引导扇区、MBR等)
http://xu3stones.blog.163.com/blog/static/205957136201210309424303 主分区,扩展分区,逻辑分区,活动分区,系统分区,启动分区..... ...
- Linux 入门记录:六、Linux 硬件相关概念(硬盘、磁盘、磁道、柱面、磁头、扇区、分区、MBR、GPT)
一.硬盘 硬盘的功能相当简单但很重要,它负责记录系统所需要的各种数据.硬盘记录数据有两个方面,一个是硬件方面的存储原理和结构,另外一方面则是软件方面的数据和文件系统.硬盘的主要行为就是数据的存放和取出 ...
- 解决装系统选中的磁盘采用的是GPT分区形式
今天给服务器重装系统碰到的问题,记录一下 当时是按正常的操作:到了装系统选盘的时候是找不到盘符的,加载了raid驱动,然后顺利找到盘符,然后格式化了以前的C盘, 结果无法选中格式化后的C盘,无法下一步 ...
随机推荐
- 不用typsescript也能使用类型增强功能
由于 JS 的弱类型.宽松的编写规范.以及开发工具的弱鸡支持,我们在维护前人的代码时,经常会出现不知道某一个方法或字段命名来自于哪里,一定要在全局搜索以后慢慢筛查才能找到 同样我们在使用接口返回的对象 ...
- 五十:代码审计-PHP无框架项目SQL注入挖掘技巧
代码审计教学计划: 审计项目漏洞Demo->审计思路->完整源码框架->验证并利用漏洞 代码审计教学内容: PHP,JAVA网站应用,引入框架类开发源码,相关审计工具及插件使用 代码 ...
- linux安装uwsgi,报错问题解决
uwsgi安装 uwsgi启动后出 -- unavailable modifier requested: 0 出现问题的的原因是找不到python的解释器(其他语言同理) 你使用的yum instal ...
- Python——input与raw_input的区别
区别一: raw_input():python2版本 input():python3版本 区别二: raw_input()不管是输数字还是字符串,结果都会以字符串的形式展现出来 input()则是 ...
- @MockBean 注解后 bean成员对象为 null?
笔者在写自测的时候遇到的问题: 我想模拟一个Bean,并在之后使用Mockito打桩,于是使用了 @MockBean 注解(spring集成mockito的产物),但代码编写好了后启动测试却报Null ...
- Vue ElementUI表格table中使用select下拉框组件时获取改变之前的值
目前项目中有一个场景,就是表格中显示下拉框,并且下拉框的值可以更改,更改后提交后台更新.因为这个操作比较重要,所以切换时会有一个提示框,提示用户是否修改,是则走提交逻辑,否则直接返回,什么也不做. 之 ...
- Docker上安装Redis
Docker可以很方便的进行服务部署和管理,下面我们通过docker来搭建Redis的单机模式.Redis主从复制.Redis哨兵模式.Redis-Cluster模式 一.在Docker上安装单机版R ...
- async await Task 使用方法
使用概述 C#的使用过程中,除了以前的Thread.ThreadPool等用来开一个线程用来处理异步的内容.还可以使用新特性来处理异步.比以前的Thread和AutoResetEvent.delege ...
- 手把手教你如何使用Charles抓包
一.为什么使用charles 前几天因为需要通过抓包定位问题,打开了尘封已久的fiddler,结果打开软件后什么也干不了,别说手机抓包了,打开软件什么请求也抓不到. 很多时候都是如此,如果一个方案不行 ...
- 【Makefile】2-Makefile的介绍及原理
目录 前言 概念 Chapter 2:介绍 2.1 makefile的规则 2.3 make 是如何工作的 ** 2.5 让 make 自动推导 2.8 Makefile 里面有什么 2.9 Make ...