Redis持久化 aof和rdb的原理配置
一.介绍
由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据。
redis提供两种方式进行持久化,一种是RDB持久化(原理是将Reids在内存中的数据库记录定时 dump到磁盘上的RDB持久化),另外一种是AOF(append only file)持久化(原理是将Reids的操作日志以追加的方式写入文件)
本篇为综合整理的文档,若要深入了解可查阅Redis官网文档
二.RDB持久化(全量写入)
rdb原理
RDB持久化是把当前进程数据生成快照保存到硬盘的过程,触发RDB持久化过程分为手动触发和自动触发
过程:
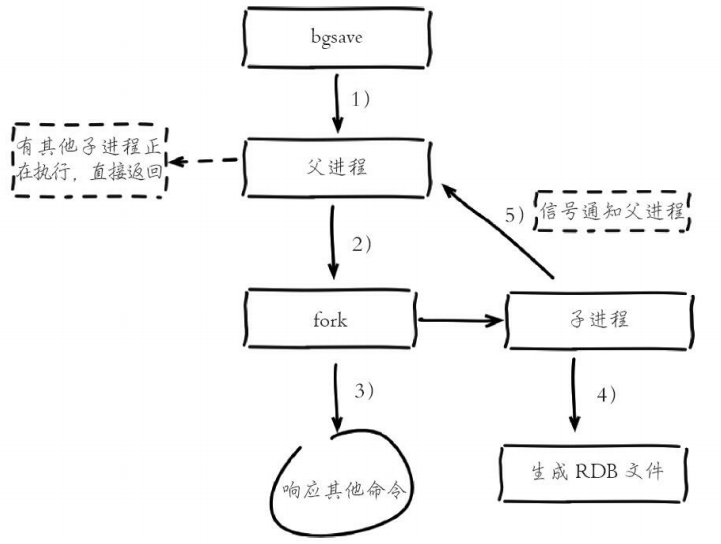
1)执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
2)父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通过info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒。
3)父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
4)子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换 执行lastsave命令可以获取最后一次生成RDB的时间,对应info统计的rdb_last_save_time选项。
5)进程发送信号给父进程表示完成,父进程更新统计信息,具体见info Persistence下的rdb_*相关选项。
rdb模式
SAVE 阻塞式的RDB持久化,当执行这个命令时间时rdis的主进程把内存里的数据库状态写入到rdb文件中,直到该文件创建完毕的这段时间内redis讲不能处理任何命令请求
BGSAVE 非阻塞式的持久化,它会创建一个子进程,专门去把内存中的数据库状态写入RDB文件,同时主进程还可以处理来自客户端的请求命令,但子进程基本是复制父进程,这等于两个相同大小的redis进程在系统上运行,会造成内存使用率的大幅增加。
rdb触发情况
1.手动执行bgsave或save命令
2.根据配置文件的save选项自动触发
3.主从结构时,从节点执行全量复制操作,主节点自动执行,将生成的RDB文件发送给从
4.执行debug reload命令重新加载Redis时
5.默认情况下执行shutdown命令关闭redis时,如果没有开启AOF持久化功能则自动执行
rdb优势和劣势
优势:
- 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对可以定时每天可以备份出一个整个的数据文件。
- 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。
- 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
劣势:
- 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
- RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。
rdb文件配置
redis.conf文件
#注释所有save行则停止rdb持久化
#900秒(15分钟)内至少1个key值改变(则进行数据库保存--持久化)
save 900 1
#300秒(5分钟)内至少10个key值改变(则进行数据库保存--持久化)
save 300 10
#60秒(1分钟)内至少10000个key值改变(则进行数据库保存--持久化)
save 60 10000
#当RDB持久化出现错误后,再写入数据会报错,用于提示用户出问题了。
#yes是开启,no是关闭,默认开启
stop-writes-on-bgsave-error yes
#是否压缩rdb文件,rdb文件压缩使用LZF压缩算法,压缩会消耗一些cpu,不压缩文件会很大
#yes开启,no关闭,默认开启
rdbcompression yes
#使用CRC64算法来进行数据校验,防止RDB是错误的,但是这样做会增加大约10%的性能消耗
#yes开启,no关闭,默认开启
rdbchecksum yes
rdb命令配置
阻塞当前Redis服务器 直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
save
Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
bgsave
查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒。
info stats
rdb数据恢复
1.将RDB备份放到配置文件指定的数据目录下,启动redis将会自动恢复。加载期间将会阻塞,无法进行其它操作。
2.上述方法不行,或者恢复的集群,可以使用redis-migrate-tool工具进行恢复。
三.AOF持久化(增量写入)
aof原理
以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
写入的数据具有可读性,同步时先写入缓冲区,再放入硬盘。如果直接写入硬盘,性能将取决于磁盘负载,并且放到缓冲区,可以提供各种同步策略。
过程:
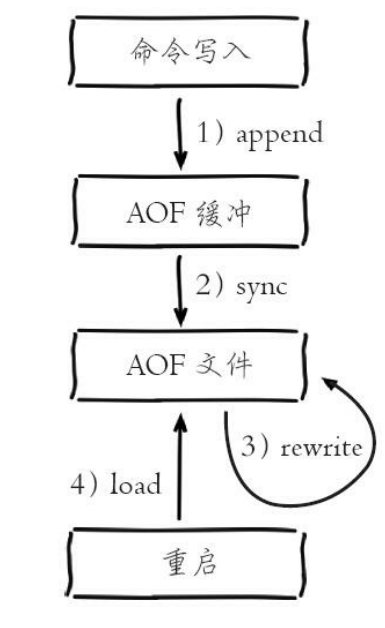
1)所有的写入命令会追加到aof_buf(缓冲区)中。
2)AOF缓冲区根据对应的策略向硬盘做同步操作。
3)随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
4)当Redis服务器重启时,可以加载AOF文件进行数据恢复。
aof触发情况
1.根据配置文件自动触发
aof优势和劣势
优势:
- 该机制可以带来更高的数据安全性,即数据持久性。根据策略不同,从而对数据安全性不同,可以在性能和安全区选择一个。
- 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。
- 如果日志过大,将自动启用rewrite机制。以append模式不断的将修改数据写入到老的磁盘文件中,同时还会创建一个新的文件用于记录此期间有哪些修改命令被执行,保证安全性。
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
劣势:
- 对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
aof文件配置
在Redis的配置文件中存在三种同步方式,它们分别是:
#是否开启aof持久化。默认no,要打开
appendonly yes
#位置
appendfilename "appendonly.aof"
#每次有数据修改发生时都会写入AOF文件
#命令写入aof_buf后调用系统fsync操作同步AOF文件,fsync完成后线程返回
appendfsync always
#每秒钟同步一次,该策略为AOF的缺省策略
#命令写入aof_buf后调用系统write操作,write完成后线程返回。fsync同步文件操作由专门线程每秒调用一次
#这个模式兼顾了效率的同时也保证了数据的完整性,即使在服务器宕机也只会丢失一秒内对redis数据库做的修改
appendfsync everysec
#不加入缓冲区,直接写到硬盘,速度最快,不安全
#命令写入aof_buf后调用系统write操作,不对aof文件做fsync同步,同步硬盘操作由操作系统负责,通常同步周期最长30秒
#这种模式下效率是最快的,但对数据来说也是最不安全的,如果redis里的数据都是从后台数据库如mysql中取出来的,属于随时可以找回或者不重要的数据,那么可以考虑设置成这种模式。
appendfsync no
aof命令配置
aof文件重写手动触发
bgrewriteaof
aof文件重写自动触发,配置文件
#新的aof文件大小是上次的aof文件的大小2倍(100)时,进行重写
auto-aof-rewrite-percentage 100
#表示运行AOF重写时文件最小体积, 默认为64MB
auto-aof-rewrite-min-size 64mb
aof数据恢复
- 将AOF备份放到配置文件指定的数据目录下,启动redis将会自动恢复。加载期间将会阻塞,无法进行其它操作。
- 上述方法不行,或者恢复的集群,可以使用redis-migrate-tool工具进行恢复。
- 可以使用pipline方式批量硬写入,但效率会低
四.总结
二者选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。
启动加载流程:
- AOF持久化开启且存在AOF文件时, 优先加载AOF文件
- AOF关闭或者AOF文件不存在时, 加载RDB文件
- 加载AOF/RDB文件成功后, Redis启动成功
- AOF/RDB文件存在错误时, Redis启动失败并打印错误信息
Redis持久化 aof和rdb的原理配置的更多相关文章
- Redis - 持久化 AOF 和 RDB
Redis - 持久化 AOF 和 RDB AOF AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集. AOF 文件中的命令全部以 Redis 协议的格 ...
- redis持久化AOF与RDB
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot). AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原 ...
- redis 持久化 AOF和 RDB 引起的生产故障
概要 最近听开发的同事说,应用程序连接 redis 时总是抛出连接失败或超时之类的错误.通过观察在 redis 日志,发现日志中出现 "Asynchronous AOF fsyn ...
- Redis持久化————AOF与RDB模式
1. 官方说明: By default Redis asynchronously dumps the dataset on disk. This mode is good enou ...
- Redis持久化AOF和RDB对比
RDB持久化 AOF持久化 全量备份,一次保存整个数据库 增量备份,一次保存一个修改数据库的命令 保存的间隔较长 保存的间隔默认一秒 数据还原速度快 数据还原速度一般 save会阻塞,但bgsave或 ...
- redis持久化AOF与RDB配置
AOF保存的数据方案时最完整的,如果同时开启了rdb和aof下,会采用aof方式. (1)设置数据保存到数据文件中的save规则 save 900 1 #900秒时间,至少有一条数据更新,则保 ...
- redis持久化的方式RDB 和 AOF
redis持久化的方式RDB 和 AOF 一.对Redis持久化的探讨与理解 目前Redis持久化的方式有两种: RDB 和 AOF 首先,我们应该明确持久化的数据有什么用,答案是用于重启后的数据恢复 ...
- Redis持久化——内存快照(RDB)
最新:Redis持久化--如何选择合适的持久化方式 最新:Redis持久化--AOF日志 最新:Redis持久化--内存快照(RDB) 一文回顾Redis五大对象(数据类型) Redis对象--有序集 ...
- Redis持久化——AOF日志
最新:Redis内存--内存消耗(内存都去哪了?) 最新:Redis持久化--如何选择合适的持久化方式 最新:Redis持久化--AOF日志 更多文章... 上一篇文章Redis持久化--内存快照(R ...
随机推荐
- 体验用yarp连接websocket
前段时间一看yarp的仓库,wow,终于发布1.0版本了..net也升级到6版本了,之前一直只是用yarp做HTTP转发,今天刚好试试websocket 话不多说,直接开搞 配置集群 首先先配置集群信 ...
- [at4631]Jewels
如果要选某颜色,必然会选该颜色最大的两个,那么不妨将这两个宝石权值修改为两者的平均数,显然不影响两者的和,也即不影响答案 接下来,将所有宝石按权值从大到小排序,并在权值相同时按颜色编号从小到大(使颜色 ...
- [loj2586]选圆圈
下面先给出比较简单的KD树的做法-- 根据圆心建一棵KD树,然后模拟题目的过程,考虑搜索一个圆 剪枝:如果当前圆[与包含该子树内所有圆的最小矩形]都不相交就退出 然而这样的理论复杂度是$o(n^2)$ ...
- rocketmq 精华
(ps:)通过本人语雀文档阅读体验更好哦--有目录 介绍 rocket mq 翻译成中文就是火箭消息队列,从名字就可以看出来,它是一个很快的消息队列... rocket mq 是 阿里巴巴研制的后面贡 ...
- MySQL联合索引的排列组合应用实战
我们都知道,当数据表中的数据日益增长后,查询会变得越来越慢,当初在表设计之初,尚未考虑创建索引的话,那么现在正是必要的时候.可是,如果对于MySQL使用索引的策略不了解,或是脱离了具体业务场景,那么, ...
- 洛谷 P6030 - [SDOI2012]走迷宫(高斯消元+SCC 缩点)
题面传送门 之所以写个题解是因为题解区大部分题解的做法都有 bug(u1s1 周六上午在讨论区里连发两个 hack 的是我,由于我被禁言才让 ycx 代发的) 首先碰到这种期望题,我们套路地设 \(d ...
- Debugging and Running MPI in Xcode
1.安装 mpich2 与 Xcode mpich2安装地址:/usr/local/Cellar/mpich2/3.1.4/ Xcode 版本:Version 6.2 (6C131e) 2.新建工程 ...
- 【Linux】非root安装Python3及其包管理
1. Python 3.8.1安装 源码安装常规操作: wget -c https://www.python.org/ftp/python/3.8.1/Python-3.8.1.tgz tar -xv ...
- Notepad++—设置背景颜色
之前,编程一直用的都是黑色背景色,最近发现,黑色背景色+高光字体,时间久了对眼睛特别不好.感觉自己编程到现在几年时间,眼睛就很不舒服,甚至有青光眼的趋势.所以,改用白底黑字,即"日间模式&q ...
- 网络爬虫-python-爬取天涯求职贴
使用urllib请求页面,使用BeautifulSoup解析页面,使用xlwt3写入Excel import urllib.request from bs4 import BeautifulSoup ...