Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS、YARN等组件。
为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压开箱即可使用,给我们提供了很大的方便。
如果我们只是本地学习的spark,又不想搭建复杂的hadoop集群,就可以使用该安装包。
spark-3.2.0-bin-hadoop3.2-scala2.13.tgz
但是,如果是生产环境,想要搭建集群,或者后面想要自定义一些hadoop配置,就可以单独搭建Hadoop集群,后面再与spark进行整合。(推荐)
下面讲一下Hadoop集群环境的搭建。
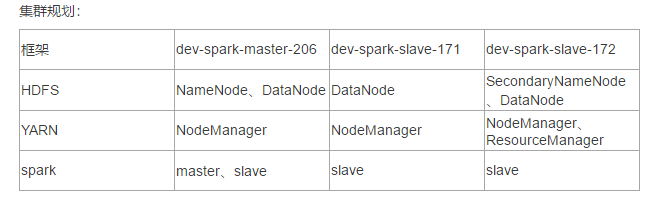
三台服务器,需要提前做好初始化,配置好主机名、免密登录与JDK配置等等。
参考前面一篇文章:Spark集群环境搭建——服务器环境初始化
https://www.cnblogs.com/doublexi/p/15623436.html
搭建Hadoop集群
1、下载:
Hadoop官网地址:http://hadoop.apache.org/
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.2.2/
cd /data/apps/shell/software
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
2、解压安装Hadoop
解压:
tar xf hadoop-3.2.2.tar.gz
mv hadoop-3.2.2 /data/apps/
编辑环境变量:
vim /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/data/apps/hadoop-3.2.2/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source生效:
source /etc/profile
测试:
# hadoop version
Hadoop 3.2.2
Source code repository Unknown -r 7a3bc90b05f257c8ace2f76d74264906f0f7a932
Compiled by hexiaoqiao on 2021-01-03T09:26Z
Compiled with protoc 2.5.0
From source with checksum 5a8f564f46624254b27f6a33126ff4
This command was run using /data/apps/hadoop-3.2.2/share/hadoop/common/hadoop-common-3.2.2.jar
3、集群配置:
3.1、HDFS集群配置:
配置:hadoop-env.sh
将JDK路径明确配置给HDFS
cd /data/apps/hadoop-3.2.2/etc/hadoop/
vim hadoop-env.sh
...
export JAVA_HOME=/usr/java/jdk1.8.0_162 export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
指定NameNode节点以及数据存储目录(修改core-site.xml)
vim core-site.xml <configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://dev-spark-master-206:8020</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/apps/hadoop-3.2.2/data/tmp</value>
</property>
</configuration>
core-site.xml的默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/coredefault.xml
指定secondarynamenode节点(修改hdfs-site.xml)
vim hdfs-site.xml <configuration>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>dev-spark-slave-172:50090</value>
</property>
<!--副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
官方默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfsdefault.xml
指定datanode从节点(修改workers文件,每个节点配置信息占一行)
注意:这里hadoop2.x是用slaves文件,3.x是用workers文件
vim workers
dev-spark-master-206
dev-spark-slave-171
dev-spark-slave-172
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
3.2、MapReduce集群配置
指定MapReduce使用的jdk路径(修改mapred-env.sh)
vim mapred-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_162
指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)
vim mapred-site.xml <configuration>
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定MR环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
mapred-site.xml默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-mapreduce-client/hadoop-mapreduceclient-core/mapred-default.xml
3.3、Yarn集群配置
编辑yarn-env.sh,指定JDK路径
vim yarn-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_162
指定ResourceMnager的master节点信息(修改yarn-site.xml)
vim yarn-site.xml <configuration> <!-- Site specific YARN configuration properties -->
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>dev-spark-slave-172</value>
</property>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
yarn-site.xml的默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-common/yarndefault.xml
指定NodeManager节点(slaves文件已修改)
注意:
Hadoop安装目录所属用户和所属用户组信息,默认是501 dialout,而我们操作Hadoop集群的用户使用的是虚拟机的root用户,
所以为了避免出现信息混乱,修改Hadoop安装目录所属用户和用户组!!
chown -R root:root /data/apps/hadoop-3.2.2
3.4、将Hadoop安装包发送到其他节点
[root@dev-spark-master-206 ~]# cd /data/apps/
# 将hadoop安装包发送到其他两台服务器相同的目录
[root@dev-spark-master-206 apps]# rsync-script hadoop-3.2.2/
在其他两台服务器上,也需要重新编辑一下环境变量,并source加载
# 检查三台服务器上是否有这个hadoop包,以及环境变量配置
# vim /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/data/apps/hadoop-3.2.2/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
三台机器上都要source一下
source /etc/profile
三台机器上运行hadoop命令测试:
# hadoop version
Hadoop 3.2.2
Source code repository Unknown -r 7a3bc90b05f257c8ace2f76d74264906f0f7a932
Compiled by hexiaoqiao on 2021-01-03T09:26Z
Compiled with protoc 2.5.0
From source with checksum 5a8f564f46624254b27f6a33126ff4
This command was run using /data/apps/hadoop-3.2.2/share/hadoop/common/hadoop-common-3.2.2.jar
3.5、集群初始化:
注意:如果集群是第一次启动,需要在Namenode所在节点格式化NameNode,非第一次不用执行格式化Namenode操作!!
新版都用hdfs namenode命令,旧版用hadoop namenode
# 注意,只能执行一次,后面再执行会破坏之前的集群环境
hdfs namenode -format
初始化成功后,输出日志里会显示”successfully formatted”
3.6、启动集群:
方式一:手动一个个服务启动:
启动HDFS:
在master上启动NameNode
[root@dev-spark-master-206 hadoop-3.2.2]# hadoop-daemon.sh start namenode
在master和slave节点,启动DataNode
在dev-spark-master-206上启动datanode
[root@dev-spark-master-206 hadoop-3.2.2]# hadoop-daemon.sh start datanode
# jps查看是否有namenode和datanode的进程
[root@dev-spark-master-206 hadoop-3.2.2]# jps
在dev-spark-slave-171上,启动datanode
[root@dev-spark-slave-171 ~]# hadoop-daemon.sh start datanode
# 查看是否有datanode的进程
[root@dev-spark-slave-171 ~]# jps
在dev-spark-slave-172上,启动datanode
[root@dev-spark-slave-172 ~]# hadoop-daemon.sh start datanode
# 查看是否有datanode进程
[root@dev-spark-slave-172 ~]# jps
Yarn集群单节点启动:
注意:NameNode和ResourceManger不是在同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
按照我们集群的规划,我们在dev-spark-slave-172上启动resourcemanager和nodemanager
[root@dev-spark-slave-172 ~]# yarn-daemon.sh start resourcemanager
[root@dev-spark-slave-172 ~]# yarn-daemon.sh start nodemanager
# 查看是否有 ResourceManager和 NodeManager进程
[root@dev-spark-slave-172 ~]# jps
在dev-spark-slave-171上启动nodemanager
[root@dev-spark-slave-171 ~]# yarn-daemon.sh start nodemanager
# 查看是否有 NodeManager的进程
[root@dev-spark-slave-171 ~]# jps
在dev-spark-master-206上,启动nodemanager
[root@dev-spark-master-206 hadoop-3.2.2]# yarn-daemon.sh start nodemanager
# jps查看是否有 NodeManager的进程
[root@dev-spark-master-206 hadoop-3.2.2]# jps
方式二:集群群起
在master节点执行start-dfs.sh命令,它会启动namenode,以及去workers文件中指定的节点中,启动datanode
在dev-spark-master-206上启动hdfs
# 不单个启动,集群启动
start-dfs.sh
在dev-spark-slave-172上启动yarn
[root@dev-spark-slave-172 ~]# start-yarn.sh
注意:NameNode和ResourceManger不是在同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
注意:如果启动报错
# start-dfs.sh
Starting namenodes on [dev-spark-master-206]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [dev-spark-slave-172]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
# vim sbin/start-dfs.sh
# 顶部加上下面的配置
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root # vim sbin/stop-dfs.sh
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
# vim sbin/start-yarn.sh
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root # vim sbin/stop-yarn.sh
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
发送到其他节点:
rsync-script sbin/start-dfs.sh
rsync-script sbin/stop-dfs.sh
rsync-script sbin/start-yarn.sh
rsync-script sbin/stop-yarn.sh
再启动:(再启动之前,需要使用jps查看之前残存的进程,用kill杀掉)
# start-dfs.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [dev-spark-master-206]
Last login: Wed Sep 8 15:05:01 CST 2021 from 192.168.90.188 on pts/6
Starting datanodes
Last login: Wed Sep 8 15:37:52 CST 2021 on pts/5
Starting secondary namenodes [dev-spark-slave-172]
Last login: Wed Sep 8 15:37:54 CST 2021 on pts/5
dev-spark-slave-172: WARNING: /data/apps/hadoop-3.2.2/logs does not exist. Creating.
启动yarn:
注意:NameNode和ResourceManger不是在同一台机器,不能在NameNode上启动 YARN,应该
在ResouceManager所在的机器上启动YARN。
# 在dev-spark-slave-172上面启动yarn
start-yarn.sh
3.7、Hadoop集群启动停止命令汇总
1. 各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
2. 各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
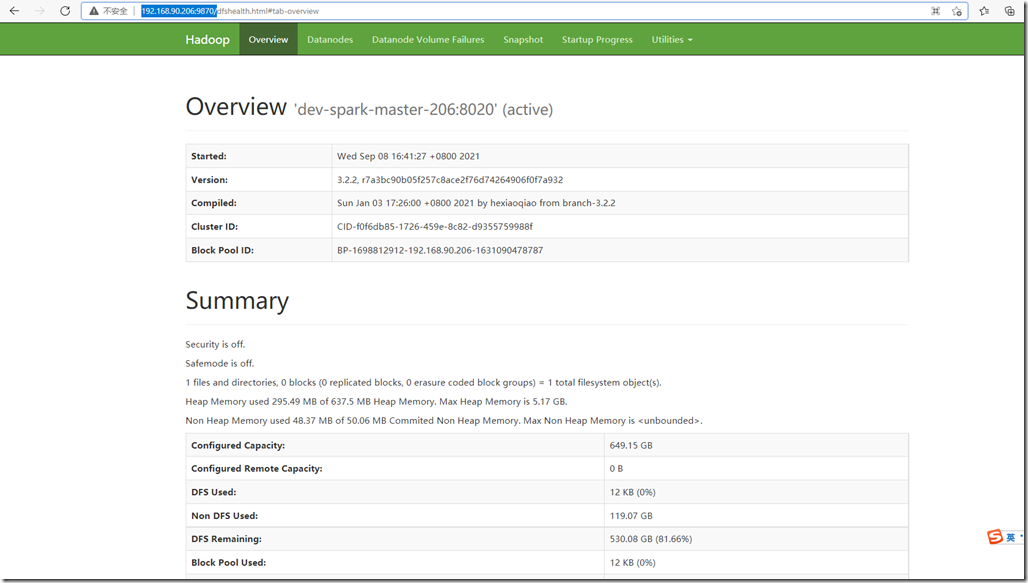
3.8、web ui界面查看
web页面查看:http://192.168.90.206:9870/
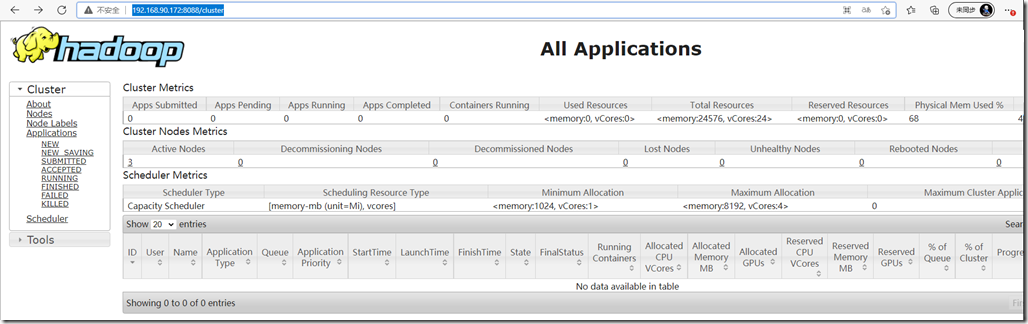
查看yarn:(注意地址是:192.168.90.172)
http://192.168.90.172:8088/
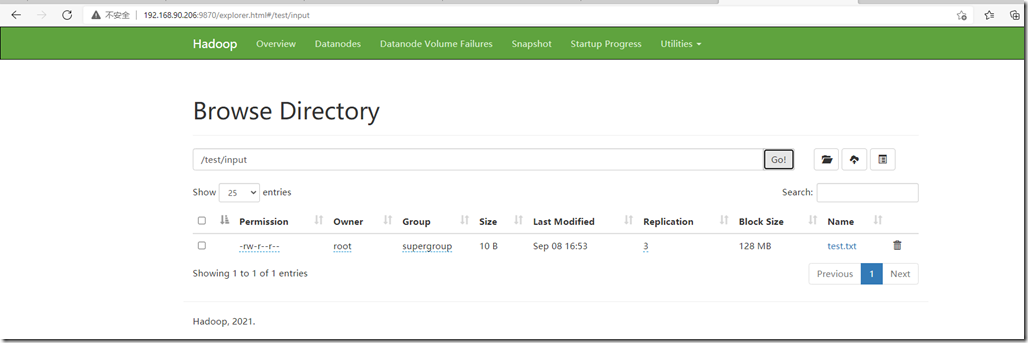
3.9、测试hdfs:
[root@dev-spark-master-206 ~]# hdfs dfs -mkdir -p /test/input
[root@dev-spark-master-206 ~]# echo "test hdfs" >> test.txt
[root@dev-spark-master-206 ~]# hdfs dfs -put test.txt /test/input
[root@dev-spark-master-206 ~]# hdfs dfs -ls /test/input
Found 1 items
-rw-r--r-- 3 root supergroup 10 2021-09-08 16:53 /test/input/test.txt
web界面上有看到相关文件:
4、配置历史服务器
在Yarn中运行的任务产生的日志数据不能查看,为了查看程序的历史运行情况,需要配置一下历史日志
服务器。具体配置步骤如下:
4.1. 配置mapred-site.xml
# cd /data/apps/hadoop-3.2.2/etc/hadoop/
# vi mapred-site.xml <!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>dev-spark-master-206:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>dev-spark-master-206:19888</value>
</property>
4.2、配置日志的聚集
日志聚集:应用(Job)运行完成以后,将应用运行日志信息从各个task汇总上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和 HistoryManager。
开启日志聚集功能具体步骤如下:
配置yarn-site.xml
vim yarn-site.xml <!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://dev-spark-master-206:19888/jobhistory/logs</value>
</property>
4.3、分发配置到其他节点:
rsync-script mapred-site.xml
rsync-script yarn-site.xml
4.4、启动history server
# 重启yarn
[root@dev-spark-slave-172 logs]# stop-yarn.sh
[root@dev-spark-slave-172 logs]# start-yarn.sh # 启动历史服务器:
[root@dev-spark-master-206 hadoop]# mapred --daemon start historyserver
4.5、web页面查看:
查看地址:http://192.168.90.206:19888/jobhistory
5、测试wordcount
创建wc.txt文件
# vim wc.txt
hadoop mapreduce yarn
hdfs hadoop mapreduce
mapreduce yarn hello
hello
hello
上传到hdfs:/text/input目录
# 如果目录不存在,需要先创建
hdfs dfs -mkdir -p /test/input
# 上传
hdfs dfs -put wc.txt /test/input
# 查看是否上传成功
hdfs dfs -ls /test/input
执行WordCount程序
hadoop jar /data/apps/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /test/input/wc.txt /wcoutput
运行成功,查看结果:
[root@dev-spark-master-206 hadoop]# hdfs dfs -ls /wcoutput
Found 2 items
-rw-r--r-- 3 root supergroup 0 2021-09-08 17:20 /wcoutput/_SUCCESS
-rw-r--r-- 3 root supergroup 43 2021-09-08 17:20 /wcoutput/part-r-00000
[root@dev-spark-master-206 hadoop]# hdfs dfs -ls /wcoutput/part-r-00000
-rw-r--r-- 3 root supergroup 43 2021-09-08 17:20 /wcoutput/part-r-00000
[root@dev-spark-master-206 hadoop]# hdfs dfs -cat /wcoutput/part-r-00000
hadoop 2
hdfs 1
hello 3
mapreduce 3
yarn 2
web页面查看历史服务器:http://192.168.90.206:19888/jobhistory
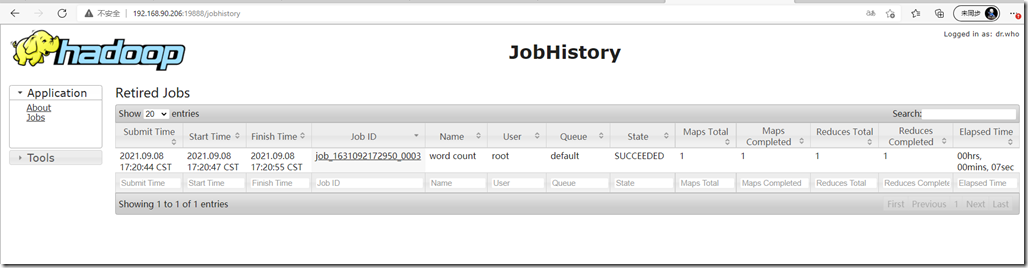
点击logs可以查看详情:
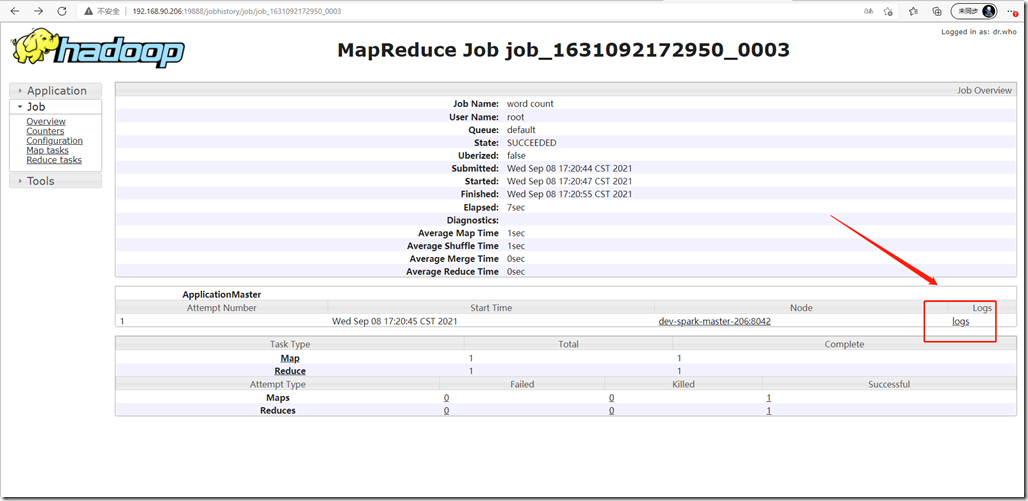
日志详情如下:
Spark集群环境搭建——Hadoop集群环境搭建的更多相关文章
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- 在搭建Hadoop集群环境时遇到的一些问题
最近在学习搭建hadoop集群环境,在搭建的过程中遇到很多问题,在这里做一些记录.1. SSH相关的问题 问题一: ssh: connect to host localhost port 22: Co ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
- 搭建Hadoop集群 (三)
通过 搭建Hadoop集群 (二), 我们已经可以顺利运行自带的wordcount程序. 下面学习如何创建自己的Java应用, 放到Hadoop集群上运行, 并且可以通过debug来调试. 有多少种D ...
- 搭建Hadoop集群 (一)
上面讲了如何搭建Hadoop的Standalone和Pseudo-Distributed Mode(搭建单节点Hadoop应用环境), 现在我们来搭建一个Fully-Distributed Mode的 ...
- 搭建Hadoop集群 (二)
前面的步骤请看 搭建Hadoop集群 (一) 安装Hadoop 解压安装 登录master, 下载解压hadoop 2.6.2压缩包到/home/hm/文件夹. (也可以从主机拖拽或者psftp压缩 ...
- Linux下搭建Hadoop集群
本文地址: 1.前言 本文描述的是如何使用3台Hadoop节点搭建一个集群.本文中,使用的是三个Ubuntu虚拟机,并没有使用三台物理机.在使用物理机搭建Hadoop集群的时候,也可以参考本文.首先这 ...
随机推荐
- Typora简介
Typora是什么 Typora是一款支持实时预览的Markdown文本编辑器,拥有macOS.Windows.Linux三个平台的版本,并且完全免费. 下载地址:https://www.typora ...
- AC-DCN ESXi
传统IT架构中的网络,根据业务需求部署上线以后,如果业务需求发生变动,重新修改相应网络设备(路由器.交换机.防火墙)上的配置是一件非常繁琐的事情.在互联网/移动互联网瞬息万变的业务环境下,网络的高稳定 ...
- zabbix 监控redis 挂掉自动重启 并发送企业微信
1.创建redis监控项[配置]-[主机]-[监控项]-创建监控项,监控6379端口(注意关闭防火墙或者开启防火墙端口6379) redis配置文件设置允许任何地址监听: 添加监控项 2.创建redi ...
- es6实现继承详解
ES6中通过class关键字,定义类 class Parent { constructor(name,age){ this.name = name; this.age = age; } speakSo ...
- JMeter学习笔记--JDBC测试计划-连接Mysql
1.首先要下载jar包,mysql-connector-java-5.1.7-bin.jar 放到Jmeter的lib文件下ext下 2.添加JDBC Connection Configuration ...
- map2bean & bean2map
1,自己实现: /** * @author xx * @since 2020/7/8 */ @Slf4j public class JavaBeanUtils { /** * 实体类转map * 效率 ...
- (五)MySQL函数
5.1 常用函数 5.2 聚合函数(常用) 函数名称 描述 COUNT() 计数 SUM() 求和 AVG() 平均值 MAX() 最大值 MIN() 最小值 .... .... 想查询一 ...
- 菜鸡的Java笔记 第二十 - java 方法的覆写
1.方法的覆写 当子类定义了与父类中的完全一样的方法时(方法名称,参数类型以及个数,返回值类型)这样的操作就称为方法的覆写 范例:观察方法的覆写 class A{ public void ...
- 分布式配置系统Apollo如何实时更新配置的?
引言 记得我们那时候刚开始学习Java的时候都只是一个单体项目,项目里面的配置基本都是写在项目里面的properties文件中,比如数据库配置啥的,各种逻辑开关,一旦这些配置修改了,还需要重启项目这修 ...
- [noi39]子图
小w喜欢的图可以发现就是一棵森林(是不是很神奇,其实易证:如果有环那么环本身就不合法,如果没有环那么显然合法).继续研究发现删边最小<=>选边最大<=>最大生成森林,krusk ...