InfluxDB 开源分布式时序、事件和指标数据库
InfluxDB 是一个开源分布式时序、事件和指标数据库。使用 Go 语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展。
特点
- schemaless(无结构),可以是任意数量的列
- Scalable
- min, max, sum, count, mean, median 一系列函数,方便统计
- Native HTTP API, 内置http支持,使用http读写
- Powerful Query Language 类似sql
- Built-in Explorer 自带管理工具
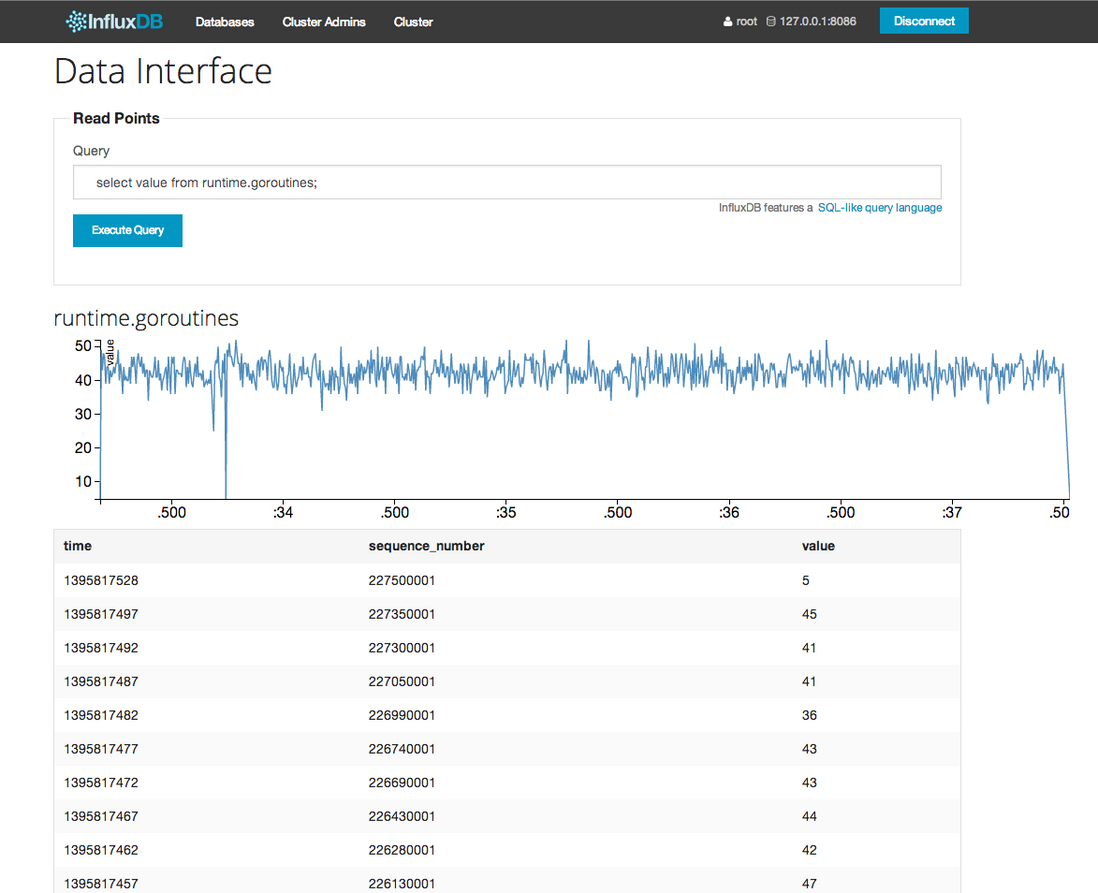
管理界面:
API
InfluxDB 支持两种api方式
- HTTP API
- Protobuf API
Protobuf 还未开发完成, 官网文档都没有
如何使用 http api 进行操作?
比如对于foo_production这个数据库,插入一系列数据,可以发现POST 请求到 /db/foo_production/series?u=some_user&p=some_password, 数据放到body里。
数据看起来是这样的:
下面的"name": "events", 其中"events"就是一个series,类似关系型数据库的表table
[
{
"name": "events",
"columns": ["state", "email", "type"],
"points": [
["ny", "paul@influxdb.org", "follow"],
["ny", "todd@influxdb.org", "open"]
]
},
{
"name": "errors",
"columns": ["class", "file", "user", "severity"],
"points": [
["DivideByZero", "example.py", "someguy@influxdb.org", "fatal"]
]
}
]
格式是json,可以在一个POST请求发送多个 series, 每个 series 里的 points 可以是多个,但索引要和columns对应。
上面的数据里没有包含time 列,InfluxDB会自己加上,不过也可以指定time,比如:
[
{
"name": "response_times",
"columns": ["time", "value"],
"points": [
[1382819388, 234.3],
[1382819389, 120.1],
[1382819380, 340.9]
]
}
]
time 在InfluxDB里是很重要的,毕竟InfluxDB是time series database
在InfluxDB里还有个sequence_number字段是数据库维护的,类似于mysql的 主键概念
InfluxDB 增删更查都是用http api来完成,甚至支持使用正则表达式删除数据,还有计划任务。
比如:
发送POST请求到 /db/:name/scheduled_deletes, body如下,
{
"regex": "stats\..*",
"olderThan": "14d",
"runAt": 3
}
这个查询会删除大于14天的数据,并且任何以stats开头的数据,并且每天3:00 AM运行。
更加详细查看官方文档: http://influxdb.org/docs/api/http.html
查询语言
InfluxDB 提供了类似sql的查询语言
看起来是这样的:
select * from events where state == 'NY';
select * from log_lines where line =~ /error/i;
select * from events where customer_id == 23 and type == 'click';
select * from response_times where value > 500;
select * from events where email !~ /.*gmail.*/;
select * from nagios_checks where status != 0;
select * from events
where (email =~ /.*gmail.* or email =~ /.*yahoo.*/) and state == 'ny';
delete from response_times where time > now() - 1h
非常容易上手, 还支持Group By, Merging Series, Joining Series, 并内置常用统计函数,比如max, min, mean 等
文档: http://influxdb.org/docs/query_language/
库
常用语言的库都有,因为api简单,也很容易自己封装。
InfluxdDB作为很多监控软件的后端,这样监控数据就可以直接存储在InfluxDBStatsD, CollectD, FluentD
还有其它的可视化工具支持InfluxDB, 这样就可以基于InfluxDB很方便的搭建监控平台
InfluxDB 数据可视化工具
InfluxDB 用于存储基于时间的数据,比如监控数据,因为InfluxDB本身提供了Http API,所以可以使用InfluxDB很方便的搭建了个监控数据存储中心。
对于InfluxDB中的数据展示,官方admin有非常简单的图表, 看起来是这样的
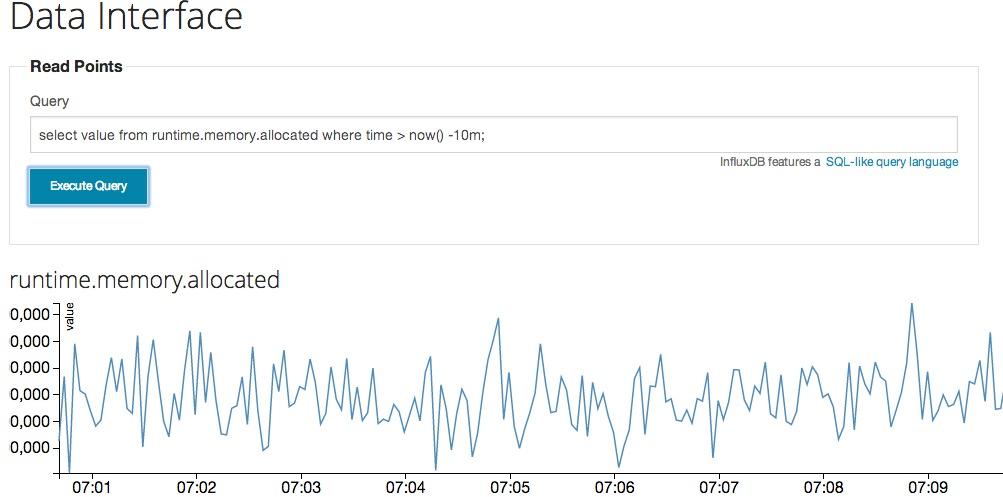
除了自己写程序展示数据还可以选择:
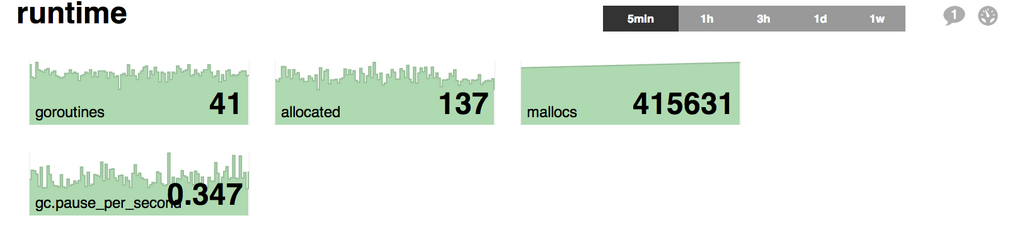
tasseo
tasseo,为Graphite写的Live dashboard,现在也支持InfluxDB,tasseo 比较简单, 可以配置的选项很少。
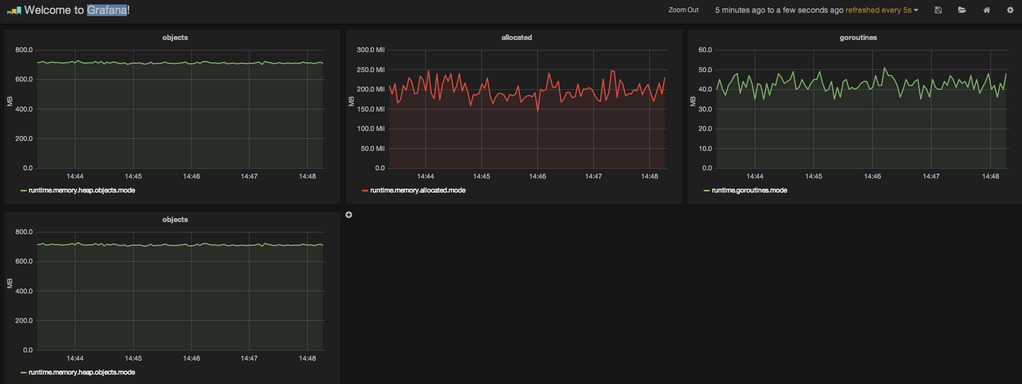
Grafana
Grafana是一个纯粹的html/js应用,访问InfluxDB时不会有跨域访问的限制。只要配置好数据源为InfluxDB之后就可以,剩下的工作就是配置图表。Grafana 功能非常强大。使用ElasticsSearch保存DashBoard的定义文件,也可以Export出JSON文件(Save ->Advanced->Export Schema),然后上传回它的/app/dashboards目录。
配置数据源:
datasources: {
influx: {
default: true,
type: 'influxdb',
url: 'http://<your_influx_db_server>:8086/db/<db_name>',
username: 'test',
password: 'test',
}
},
InfluxDB 开源分布式时序、事件和指标数据库的更多相关文章
- 分布式时序数据库InfluxDB
我们内部的监控系统用到分布式时序数据库InfluxDB http://www.ttlsa.com/monitor-safe/monitor/distributed-time-series-databa ...
- 开源分布式数据库SequoiaDB在去哪儿网的实践
编者注: 中国的数据库行业也迎来了一波新的热点事件.分布式数据库这块新消息不断,也让大家开始关注中国的分布式数据库.首先是短短一周内,Pingcap和SequoiaDB巨杉数据库陆续宣布了C轮的数千万 ...
- C#实现多级子目录Zip压缩解压实例 NET4.6下的UTC时间转换 [译]ASP.NET Core Web API 中使用Oracle数据库和Dapper看这篇就够了 asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程 asp.net core异步进行新增操作并且需要判断某些字段是否重复的三种解决方案 .NET Core开发日志
C#实现多级子目录Zip压缩解压实例 参考 https://blog.csdn.net/lki_suidongdong/article/details/20942977 重点: 实现多级子目录的压缩, ...
- 开源分布式数据库中间件MyCat源码分析系列
MyCat是当下很火的开源分布式数据库中间件,特意花费了一些精力研究其实现方式与内部机制,在此针对某些较为重要的源码进行粗浅的分析,希望与感兴趣的朋友交流探讨. 本源码分析系列主要针对代码实现,配置. ...
- 开源分布式数据库中间件 DBLE
DBLE 是企业级开源分布式中间件,江湖人送外号 “MyCat Plus”:以其简单稳定,持续维护,良好的社区环境和广大的群众基础得到了社区的大力支持: DBLE官方网站:https://openso ...
- 大众点评开源分布式监控平台 CAT 深度剖析
一.CAT介绍 CAT系统原型和理念来源于eBay的CAL的系统,CAT系统第一代设计者吴其敏在eBay工作长达十几年,对CAL系统有深刻的理解.CAT不仅增强了CAL系统核心模型,还添加了更丰富的报 ...
- (第8篇)实时可靠的开源分布式实时计算系统——Storm
摘要: 在Hadoop生态圈中,针对大数据进行批量计算时,通常需要一个或者多个MapReduce作业来完成,但这种批量计算方式是满足不了对实时性要求高的场景.那Storm是怎么做到的呢? 博主福利 给 ...
- 宜信开源|分布式任务调度平台SIA-TASK的架构设计与运行流程
一.分布式任务调度的背景 无论是互联网应用或者企业级应用,都充斥着大量的批处理任务.我们常常需要一些任务调度系统来帮助解决问题.随着微服务化架构的逐步演进,单体架构逐渐演变为分布式.微服务架构.在此背 ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
随机推荐
- IOS 网络判断
Reachability *connectionNetWork= [Reachability reachabilityForInternetConnection] ; int status = [co ...
- 如何把UIView转成UIImage,解决模糊失真问题
最近工作中,遇到一个需求,需要把一个UIView对象转成UIImage对象显示.经过网络搜索,找到如下答案: ? 1 2 3 4 5 6 7 8 -(UIImage*)convertViewToIma ...
- 反对网抄,没有规则可以创建目标"install" 靠谱解答
在ubuntu下遇到这个问题,原因其实很简单,你不能用WINDWOS下的方法用图形方式打开,然后点了一下按扭"解压缩",生成了一个文件夹. 的确,这个文件夹看起来和正常的没有什么区 ...
- 【分割平面,分割空间类题】【HDU1290 HDU2050】
HDU 2050 折线分割平面 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- winform最小化到托盘
1.拖取NotifyIcon控件.将该控件的visible设成false. 2.指定NotifyIcon的Icon(很重要,否则最小化后找不到窗口). 3.找到window的SizeChanged事件 ...
- Git使用过程
Git-------目前世界上最先进的分布式版本控制系统(没有之一) 什么是版本控制系统? 说简单点,就是一个文件,对其增加.删除.修改都可以被记录下来,不仅自己可以修改,其他人也可以进行修改 每次对 ...
- jdbc读取数据库图片文件
package 读取大文件.read; import java.io.BufferedReader; import java.io.FileOutputStream; import java.io.I ...
- sql一些命令
1.创建表 create table tSId ( tSid int identity(1,1) primary key, tSName varchar(10) check(len(tSName)&g ...
- SDK编程模板
#include<Windows.h> LRESULT CALLBACK WndProc(HWND,UINT,WPARAM,LPARAM); int WINAPI WinMain(HINS ...
- JSON入门之二:org.json的基本用法
java中用于解释json的主流工具有org.json.json-lib与gson,本文介绍org.json的应用. 官方文档: http://www.json.org/java/ http://de ...