Keras实现Self-Attention
本文转载自:https://blog.csdn.net/xiaosongshine/article/details/90600028
一、Self-Attention概念详解
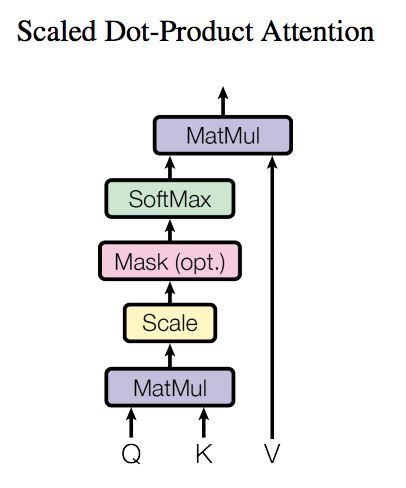
对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度 其中
其中 为一个query和key向量的维度。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。该操作可以表示为

如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示

其中 是我们模型训练过程学习到的合适的参数。上述操作即可简化为矩阵形式
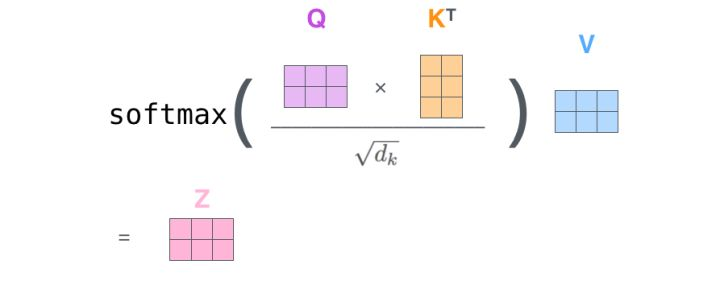
二、Self_Attention模型搭建
笔者使用Keras来实现对于Self_Attention模型的搭建,由于网络中间参数量比较多,这里采用自定义网络层的方法构建Self_Attention,关于如何自定义Keras可以参看这里:编写你自己的 Keras 层
Keras实现自定义网络层。需要实现以下三个方法:(注意input_shape是包含batch_size项的)
- build(input_shape): 这是你定义权重的地方。这个方法必须设 self.built = True,可以通过调用 super([Layer], self).build() 完成。
- call(x): 这里是编写层的功能逻辑的地方。你只需要关注传入 call 的第一个参数:输入张量,除非你希望你的层支持masking。
- compute_output_shape(input_shape): 如果你的层更改了输入张量的形状,你应该在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状
from keras.preprocessing import sequence
from keras.datasets import imdb
from matplotlib import pyplot as plt
import pandas as pd from keras import backend as K
from keras.engine.topology import Layer class Self_Attention(Layer): def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(Self_Attention, self).__init__(**kwargs) def build(self, input_shape):
# 为该层创建一个可训练的权重
#inputs.shape = (batch_size, time_steps, seq_len)
self.kernel = self.add_weight(name='kernel',
shape=(3,input_shape[2], self.output_dim),
initializer='uniform',
trainable=True) super(Self_Attention, self).build(input_shape) # 一定要在最后调用它 def call(self, x):
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2]) print("WQ.shape",WQ.shape) print("K.permute_dimensions(WK, [0, 2, 1]).shape",K.permute_dimensions(WK, [0, 2, 1]).shape) QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1])) QK = QK / (64**0.5) QK = K.softmax(QK) print("QK.shape",QK.shape) V = K.batch_dot(QK,WV) return V def compute_output_shape(self, input_shape): return (input_shape[0],input_shape[1],self.output_dim)
Keras实现Self-Attention的更多相关文章
- Keras实现Hierarchical Attention Network时的一些坑
Reshape 对于的张量x,x.shape=(a, b, c, d)的情况 若调用keras.layer.Reshape(target_shape=(-1, c, d)), 处理后的张量形状为(?, ...
- LSTM/RNN中的Attention机制
一.解决的问题 采用传统编码器-解码器结构的LSTM/RNN模型存在一个问题,不论输入长短都将其编码成一个固定长度的向量表示,这使模型对于长输入序列的学习效果很差(解码效果很差). 注意下图中,ax ...
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
- Sequence Models
Sequence Models This is the fifth and final course of the deep learning specialization at Coursera w ...
- keras系列︱seq2seq系列相关实现与案例(feedback、peek、attention类型)
之前在看<Semi-supervised Sequence Learning>这篇文章的时候对seq2seq半监督的方式做文本分类的方式产生了一定兴趣,于是开始简单研究了seq2seq.先 ...
- [深度应用]·Keras极简实现Attention结构
[深度应用]·Keras极简实现Attention结构 在上篇博客中笔者讲解来Attention结构的基本概念,在这篇博客使用Keras搭建一个基于Attention结构网络加深理解.. 1.生成数据 ...
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- [深度应用]·首届中国心电智能大赛初赛开源Baseline(基于Keras val_acc: 0.88)
[深度应用]·首届中国心电智能大赛初赛开源Baseline(基于Keras val_acc: 0.88) 个人主页--> https://xiaosongshine.github.io/ 项目g ...
- [深度应用]·DC竞赛轴承故障检测开源Baseline(基于Keras 1D卷积 val_acc:0.99780)
[深度应用]·DC竞赛轴承故障检测开源Baseline(基于Keras1D卷积 val_acc:0.99780) 个人网站--> http://www.yansongsong.cn/ Githu ...
- Attention Model(注意力模型)思想初探
1. Attention model简介 0x1:AM是什么 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但 ...
随机推荐
- mybatis自动生成后无法获取主键id问题
使用mybatis的自动生成工具生成的主键id: <selectKey resultType="java.lang.Integer" keyProperty="id ...
- prettier
prettier,是一个自以为是 Opinionated 的代码格式化工具,用来批量处理旧代码的统一. 涉及引号,分号,换行,缩进. prettier 支持我们大前端目前大部分语言处理,包括 Jav ...
- rConfig v3.9.2 授权认证与未授权RCE (CVE-2019-16663) 、(CVE-2019-16662)
rConfig v3.9.2 authenticated and unauthenticated RCE (CVE-2019-16663) and (CVE-2019-16662) 原文:https: ...
- JavaScript有用的代码片段和trick
浮点数取整 const x = 123.4545; x >> 0; ~~x; x | 0; Math.floor(x); 注意:前三种方法只适用于32个位整数,对于负数的处理上和Math. ...
- 协议——SPI
SPI(Serial Peripheral interface)是由摩托罗拉公司定义的一种串行外围设备接口,是一种高速.全双工.同步的通信总线,只需要四根信号线即可,节约引脚,同时有利于PCB的布局. ...
- Socket简单Demo
Socket协议网上介绍的有很多了,就不在画蛇添足了,本文主要编写一个小Demo,介绍下它具体实现 一:Socket服务器端 package com.founderit; import java.io ...
- JXOI2018
发现自己不会T3可以退群了 排序问题(组合.模拟) 可以发现Gobo Sort相当于在所有排列中随机选择一个,所以当第\(i\)个数出现次数为\(a_i\)时,期望的Sort次数就是\(\frac{( ...
- tomcat线程池调优
之前项目一直在tomcat下开发,后来在上线之前,需要进行性能安全测试,可是测试的同事反应,登陆口线程并发一多的时候,系统立马就没法登陆了. 中间件是tomcat6. tomcat的日志总是简洁的很 ...
- Java泛型 - 返回父类的子类
一.栗子 public class GenericityInher { //error: Type mismatch: cannot convert from ArrayList<Child&g ...
- Spark 系列(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...