大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)
什么是Hive? 我来一个短而精悍的总结(面试常问)
1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark)。
2:hive可以使用类sql方言,对存储在hdfs上的数据进行分析和管理。
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
Hive相当于hadoop的客户端工具,部署时不一定放在集群管理节点中,可以放在某个节点上。
Hive与传统数据库比较
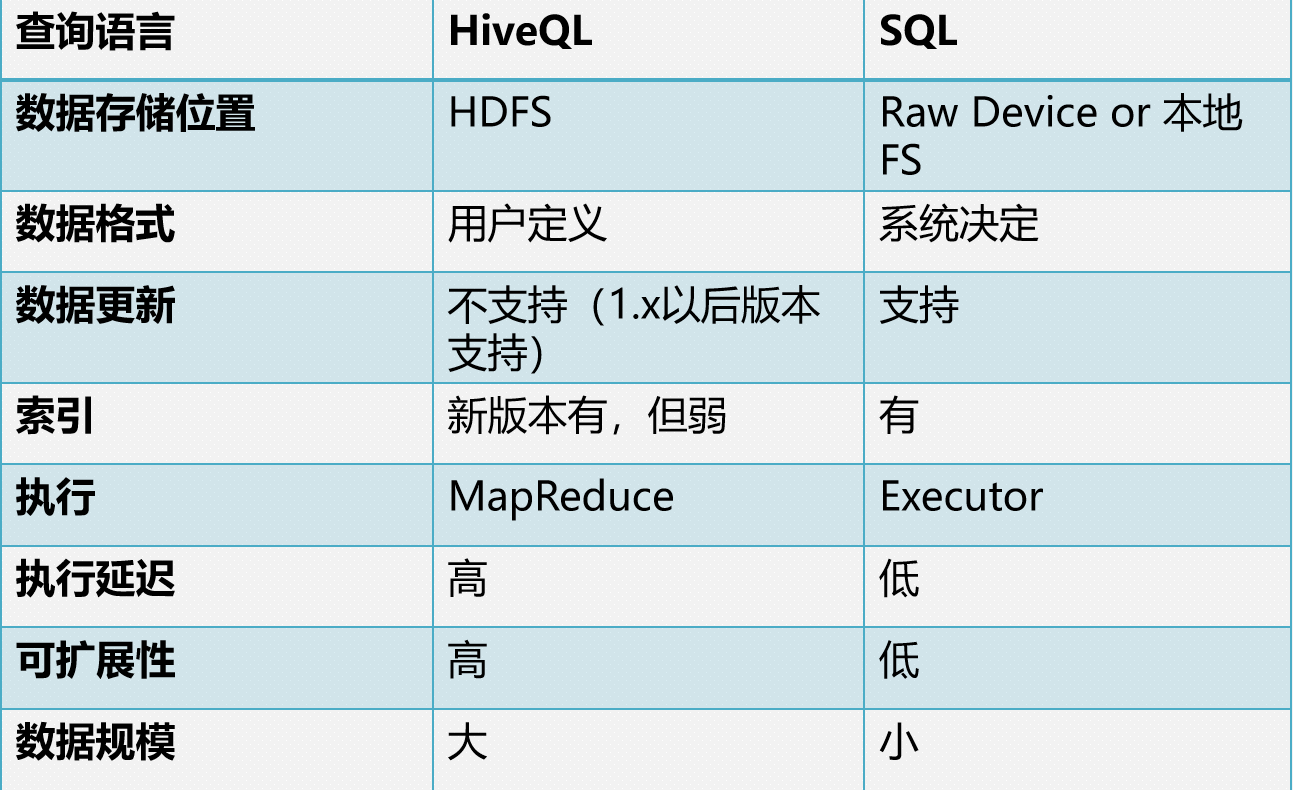
Hive与传统数据库比较
1. 查询语言。类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
2. 数据存储位置。所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3. 数据格式。Hive 中没有定义专门的数据格式。而在数据库中,所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
4. 数据更新。Hive 对数据的改写和添加比较弱化,0.1.4版本之后支持,需要启动配置项。而数据库中的数据通常是需要经常进行修改的。
5. 索引。Hive 在加载数据的过程中不会对数据进行任何处理。因此访问延迟较高。数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
6. 执行计算。Hive 中执行是通过 MapReduce 来实现的而数据库通常有自己的执行引擎。
7. 数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive的存储格式
Hive的数据存储基于Hadoop HDFS。
Hive没有专门的数据文件格式,目前主流使用有三种:
TextFile
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。 可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分。从而无法对数据进行并行操作。
RCFile
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取
SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
Hive操作客户端
常用的2个:CLI,JDBC/ODBC
CLI,即Shell命令行 JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似。
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。
Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
Hive的metastore
metastore是hive元数据的集中存放地。
metastore默认使用内嵌的derby数据库作为存储引擎
Derby引擎的缺点:一次只能打开一个会话
使用MySQL作为外置存储引擎,多用户同时访问
元数据库详解见:查看mysql SDS表和TBLS表
可参考 https://blog.csdn.net/haozhugogo/article/details/73274832
大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)的更多相关文章
- Hive -- 基于Hadoop的数据仓库分析工具
Hive是一个基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库 ...
- 胖子哥的大数据之路(10)- 基于Hive构建数据仓库实例
一.引言 基于Hive+Hadoop模式构建数据仓库,是大数据时代的一个不错的选择,本文以郑商所每日交易行情数据为案例,探讨数据Hive数据导入的操作实例. 二.源数据-每日行情数据 三.建表脚本 C ...
- 大数据之路week06--day07(完全分布式Hadoop的搭建)
前提工作: 克隆2台虚拟机完成后:新的2台虚拟机,请务必依次修改3台虚拟机的ip地址和主机名称[建议三台主机名称依次叫做:master.node1.node2 ] 上一篇博客 (三台虚拟机都要开机) ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- 胖子哥的大数据之路(11)-我看Intel&&Cloudera的合作
一.引言 5月8日,作为受邀嘉宾,参加了Intel与Cloudera在北京中国大饭店新闻发布会,两家公司宣布战略合作,该消息成为继Intel宣布放弃大数据平台之后的另外一个热点新闻.对于Intel的放 ...
- 保姆级教程,带你认识大数据,从0到1搭建 Hadoop 集群
大数据简介,概念部分 概念部分,建议之前没有任何大数据相关知识的朋友阅读 大数据概论 什么是大数据 大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需 ...
- Hive和SparkSQL: 基于 Hadoop 的数据仓库工具
Hive: 基于 Hadoop 的数据仓库工具 前言 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,将类 SQL 语句转 ...
- 基于Hadoop的数据仓库Hive
Hive是基于Hadoop的数据仓库工具,可对存储在HDFS上的文件中的数据集进行数据整理.特殊查询和分析处理,提供了类似于SQL语言的查询语言–HiveQL,可通过HQL语句实现简单的MR统计,Hi ...
- NetworkX一个图论与复杂网络建模工具
NetworkX是一个图论与复杂网络建模工具,采用Python语言开发,内置了常用的图与复杂网络分析算法,可以方便的进行复杂网络数据分析.仿真建模等工作.(1)NetworkX支持创建简单无向图.有向 ...
随机推荐
- TortoiseGit,git 未能顺利结束 (退出码 1)
其中一个原因是不能把Git下所有文件全部删除,一个都没有,就会报这个错误. 注:空文件夹git定义为空,不是文件.所以只有空文件夹也会报这个错误.
- POJ1166 The Clocks (爆搜 || 高斯消元)
总时间限制: 1000ms,内存限制: 65536kB 描述 |-------| |-------| |-------| | | | | | | | |---O | |---O | | O | | | ...
- jquery向上滚动页面的写法
jquery向上滚动页面的写法<pre> $('.arrow_top').on('click',function () { $body = (window.opera) ? (docume ...
- java日历类(calendar),可输出年月日等等,以及和Date相互转化
日历创建对象: Calendar类为抽象类,不可实例化 方式一: 父类引用指向类对象 Calendar cal = new GregorianCalendar(); 方式二: Calendar ca ...
- 用vue实现列表分页和按钮操作
为中华之崛起而读书 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> < ...
- [gRPC] 在 .NET Core 中创建 gRPC 服务端和客户端
gRPC 官网:https://grpc.io/ 1. 创建服务端 1.1 基于 ASP.NET Core Web 应用程序模板创建 gRPC Server 项目. 1.2 编译并运行 2. 创建客户 ...
- 2. RDD编程
2.1 编程模型 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换.经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,act ...
- C# vb .net实现HSL调整特效滤镜
在.net中,如何简单快捷地实现Photoshop滤镜组中的HSL调整呢?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码: 设置授权 第一 ...
- linux ubuntu-16.04-配置java1.8和Tomcat8
前言 第一次使用linux ubuntu16.04 服务器,所以做一下常用配置的记录. JDK 1.创建存放jdk的目录 一般在usr/local下创建一个java文件夹 cd /usr/local ...
- 【洛谷 P4302】 [SCOI2003]字符串折叠(DP)
题目链接 简单区间dp 令\(f[i][j]\)表示\([i,j]\)的最短长度 先枚举区间,然后在区间中枚举长度\(k\),看这个区间能不能折叠成几个长度为\(k\)的,如果能就更新答案. #inc ...