requests模块 高级应用
requests模块 高级应用
HttpConnectinPool 问题解决
- HttpConnectinPool:
- 原因:
- 1.短时间内发起了高频的请求导致ip被禁
- 2.http连接池中的连接资源被耗尽
- 解决:
- 1.使用代理
- 2.headers中加入Conection:“close”
IP代理
- 代理:代理服务器,可以接受请求然后将其转发。
- 匿名度
- 高匿:接收方,啥也不知道
- 匿名:接收方知道你使用了代理,但是不知道你的真实ip
- 透明:接收方知道你使用了代理并且知道你的真实ip
- 类型:
- http
- https
- 免费代理:
- 全网代理IP www.goubanjia.com
- 快代理 https://www.kuaidaili.com/
- 西祠代理 https://www.xicidaili.com/nn/
- 代理精灵 http://http.zhiliandaili.cn/
简单使用代理
- 代理服务器
- 进行请求转发
- 代理ip:port作用到get、post方法的proxies = {'http':'ip:port'}中
- 代理池(列表)
爬虫代码使用代理
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
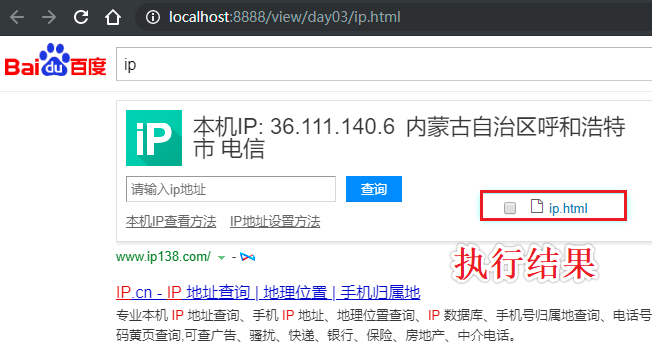
url = 'https://www.baidu.com/s?wd=ip'
page_text = requests.get(url,headers=headers,proxies={'https':'36.111.140.6:8080'}).text
with open('ip.html','w',encoding='utf-8') as fp:
fp.write(page_text)
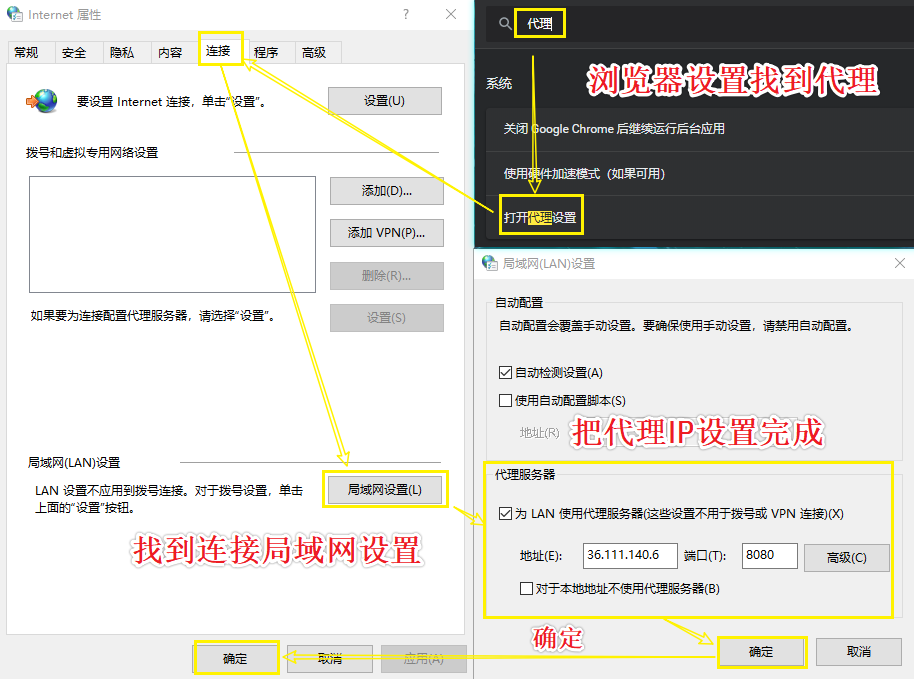
浏览器设置代理

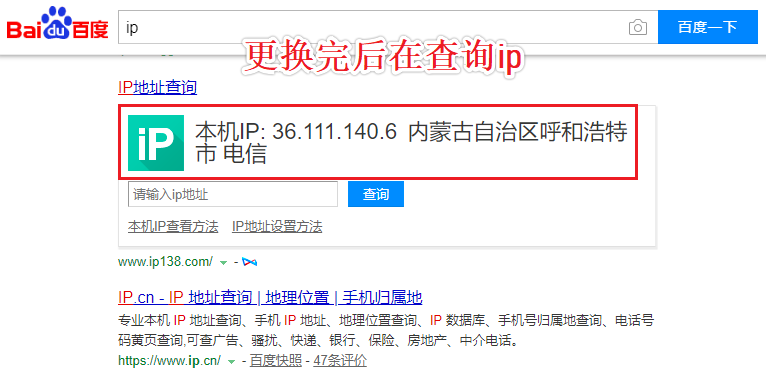
代理池
代理池的作用
解决短时间内频繁爬取统一网站导致IP封锁的情况,具体工作机制:从各大代理网站抓取免费IP,
去重后以有序集合的方式保存到Redis中,定时检测IP有效性、根据自己设定的分数规则进行优先级更改并删除分数为零
(无效)的IP 提供代理接口供爬虫工具使用.
简单实现一个代理池
#代理池:列表
import random
#字典都是网上找的代理ip
proxy_list = [
{'https':'121.231.94.44:8888'},
{'https':'131.231.94.44:8888'},
{'https':'141.231.94.44:8888'}
]
#指定url
url = 'https://www.baidu.com/s?wd=ip'
#proxies=random.choice(proxy_list) 使用代理池
page_text = requests.get(url,headers=headers,proxies=random.choice(proxy_list)).text
with open('ip.html','w',encoding='utf-8') as fp:
fp.write(page_text)
构建一个代理池
import random
import requests
from lxml import etree
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'Connection':"close"
}
#从代理精灵中提取代理ip
ip_url = 'http://t.11jsq.com/index.php/api/entry?method=proxyServer.generate_api_url&packid=1&fa=0&fetch_key=&groupid=0&qty=4&time=1&pro=&city=&port=1&format=html&ss=5&css=&dt=1&specialTxt=3&specialJson=&usertype=2'
page_text = requests.get(ip_url,headers=headers).text
tree = etree.HTML(page_text)
ip_list = tree.xpath('//body//text()')
#爬取西祠代理
url = 'https://www.xicidaili.com/nn/%d'
proxy_list_http = []
proxy_list_https = []
for page in range(1,20):
new_url = format(url%page)
ip_port = random.choice(ip_list)
page_text = requests.get(new_url,headers=headers,proxies={'https':ip_port}).text
tree = etree.HTML(page_text)
#tbody不可以出现在xpath表达式中
tr_list = tree.xpath('//*[@id="ip_list"]//tr')[1:]
for tr in tr_list:
ip = tr.xpath('./td[2]/text()')[0]
port = tr.xpath('./td[3]/text()')[0]
t_type = tr.xpath('./td[6]/text()')[0]
ips = ip+':'+port
if t_type == 'HTTP':
dic = {
t_type: ips
}
proxy_list_http.append(dic)
else:
dic = {
t_type:ips
}
proxy_list_https.append(dic)
print(len(proxy_list_http),len(proxy_list_https))
#检测 (这里可以进行持久化储存)
for ip in proxy_list_http:
response = requests.get('https://www/sogou.com',headers=headers,proxies={'https':ip})
if response.status_code == '200':
print('检测到了可用ip')
cookie的处理
手动处理:将cookie封装到headers中
自动处理:session对象。可以创建一个session对象,改对象可以像requests一样进行请求发送。
不同之处在于如果在使用session进行请求发送的过程中产生了cookie,则cookie会被自动存储在session对象中。
爬取雪球网首页新闻信息 https://xueqiu.com/
爬取过程中遇到问题
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
}
url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id=20349203&count=15&category=-1'
page_text = requests.get(url=url,headers=headers).json()
print(page_text)
#执行结果
{'error_description': '遇到错误,请刷新页面或者重新登录帐号后再试', 'error_uri': '/v4/statuses/public_timeline_by_category.json', 'error_data': None, 'error_code': '400016'}
#分析发现,正常的浏览器请求携带有cookie数据
解决办法手动添加cookie信息 (不推荐,因为有的网站cookie可能是变动的,这样就写死了)
#对雪球网中的新闻数据进行爬取https://xueqiu.com/
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'Cookie':'aliyungf_tc=AQAAAAl2aA+kKgkAtxdwe3JmsY226Y+n; acw_tc=2760822915681668126047128e605abf3a5518432dc7f074b2c9cb26d0aa94; xq_a_token=75661393f1556aa7f900df4dc91059df49b83145; xq_r_token=29fe5e93ec0b24974bdd382ffb61d026d8350d7d; u=121568166816578; device_id=24700f9f1986800ab4fcc880530dd0ed',
}
url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id=20349203&count=15&category=-1'
page_text = requests.get(url=url,headers=headers).json()
print(page_text)
#执行结果
{'list': [{'id': 20349202, 'category': 0, 'data': '{"id":132614531,"title":"狼来了!今天,中囯电信行业打响第一枪!
流量费用要降价了!","description":"狼,终究来了! 刚刚传来大消息,中国工信部正式宣布:英国电信(BT)
获得了在中国全国性经营通信的牌照。 随后,英国电信也在第一时间证实这一消息!他们兴高采烈地表示:
取得牌照,意味着英国电信在中国迈出重要的一步! 是的,你没有看错:英国电信!这是英国最大的电信公司,
也是一家有着超过...","target":"/3583653389/132614531","reply_count":75,"retweet_count":7,"topic_title":"狼来了!
今天,中囯电信行业打响第一枪!流量费用要降价了!","topic_desc":"狼,终究来了! 刚刚传来大消息, 中国工信部正式宣布:英...}.....省略

自动获取cookie(推荐,cookie是变化的也没问题)
import requests
#创建session对象
session = requests.Session()
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
}
session.get('https://xueqiu.com',headers=headers)#会自动把请求中的cookie信息携带上
url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id=20349203&count=15&category=-1'
page_text = session.get(url=url,headers=headers).json()
print(page_text)
#执行结果
{'list': [{'id': 20349202, 'category': 0, 'data': '{"id":132614531,"title":"狼来了!今天,中囯电信行业打响第一枪!
流量费用要降价了!","description":"狼,终究来了! 刚刚传来大消息,中国工信部正式宣布:英国电信(BT)
获得了在中国全国性经营通信的牌照。 随后,英国电信也在第一时间证实这一消息!他们兴高采烈地表示:
取得牌照,意味着英国电信在中国迈出重要的一步! 是的,你没有看错:英国电信!这是英国最大的电信公司,
也是一家有着超过...","target":"/3583653389/132614531","reply_count":75,"retweet_count":7,"topic_title":"狼来了!
今天,中囯电信行业打响第一枪!流量费用要降价了!","topic_desc":"狼,终究来了! 刚刚传来大消息, 中国工信部正式宣布:英...}......省略
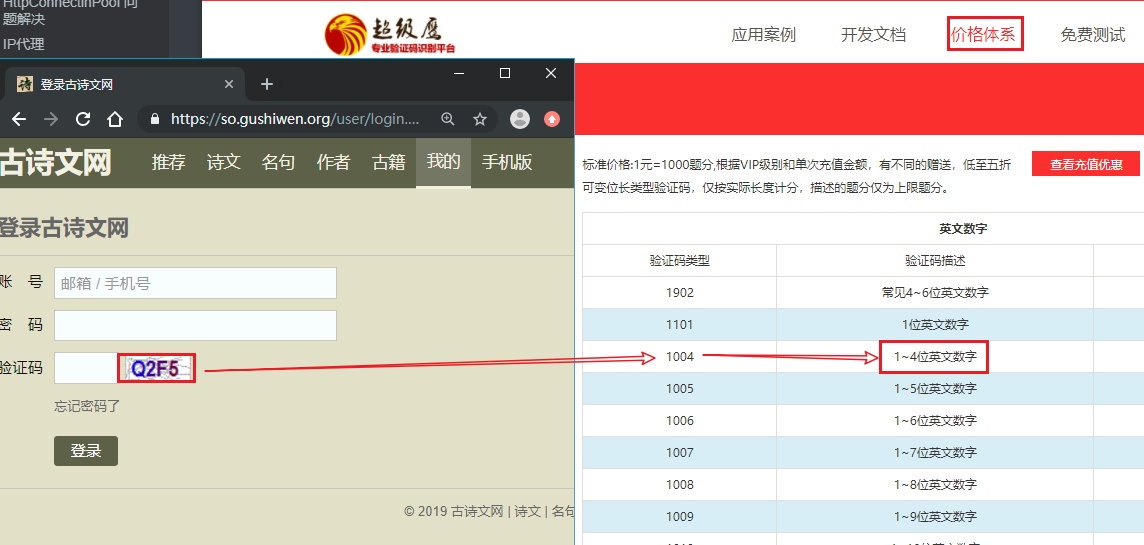
页面中验证码识别
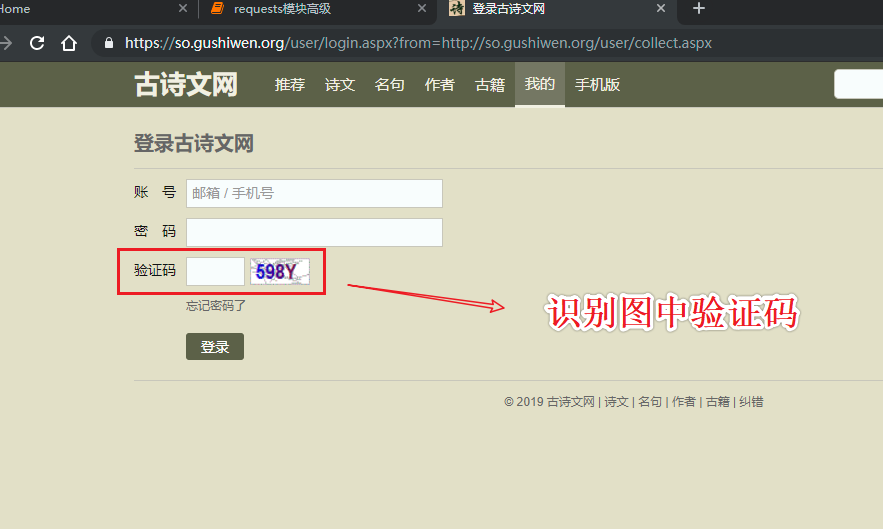
解决办法
验证码的识别推荐平台
- 超级鹰:http://www.chaojiying.com/about.html (这里我们使用超级鹰)
- 注册:(用户中心身份)
- 登陆:
- 创建一个软件:899370
- 下载示例代码
- 云打码:http://www.yundama.com/
实现过程

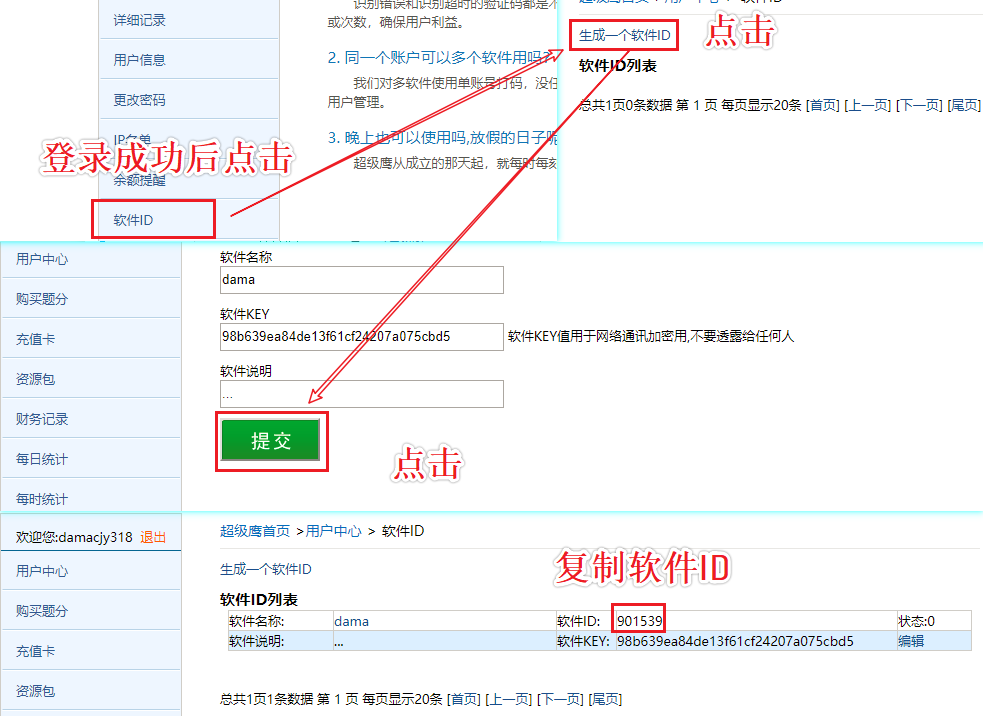
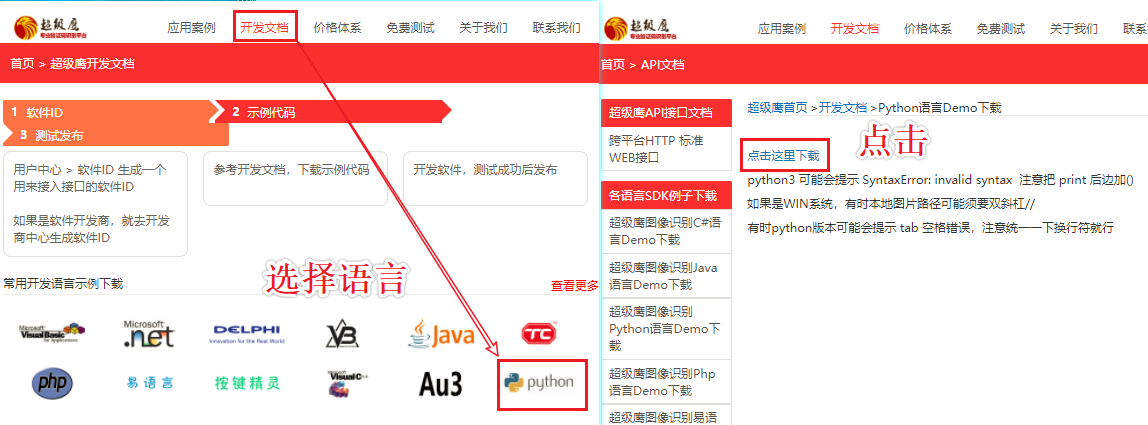
识别网页验证码
#超级鹰代码
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
#爬虫代码
#识别古诗文网中的验证码
from lxml import etree
#识别古诗文网中的验证码
def tranformImgData(imgPath,t_type):#调用超级鹰
chaojiying = Chaojiying_Client('bobo3280948', 'bobo3284148', '899370')#超级鹰账户 密码 软件id
im = open(imgPath, 'rb').read()
return chaojiying.PostPic(im, t_type)['pic_str']
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
}
url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx'
page_text = requests.get(url,headers=headers).text
tree = etree.HTML(page_text)
img_src = 'https://so.gushiwen.org'+tree.xpath('//*[@id="imgCode"]/@src')[0]
img_data = requests.get(img_src,headers=headers).content
with open('./code.jpg','wb') as fp:
fp.write(img_data)
yzm = tranformImgData('./code.jpg',1004)#保存的验证码图片地址 验证码对应超级鹰的验证码类型对应号
print(yzm)
#执行结果 成功解析验证码
d145
模拟登录
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
from lxml import etree
#识别古诗文网中的验证码
def tranformImgData(imgPath,t_type):#调用超级鹰
chaojiying = Chaojiying_Client('bobo328410948', 'bobo328410948', '899370')
im = open(imgPath, 'rb').read()
return chaojiying.PostPic(im, t_type)['pic_str']
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
}
#模拟登陆
s = requests.Session()
url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx'
page_text = s.get(url,headers=headers).text
tree = etree.HTML(page_text)
img_src = 'https://so.gushiwen.org'+tree.xpath('//*[@id="imgCode"]/@src')[0]
img_data = s.get(img_src,headers=headers).content
with open('./code.jpg','wb') as fp:
fp.write(img_data)
#动态获取变化的请求参数
__VIEWSTATE = tree.xpath('//*[@id="__VIEWSTATE"]/@value')[0]
__VIEWSTATEGENERATOR = tree.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')[0]
code_text = tranformImgData('./code.jpg',1004)
login_url = 'https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx'
data = {
'__VIEWSTATE': __VIEWSTATE,
'__VIEWSTATEGENERATOR': __VIEWSTATEGENERATOR,
'from':'http://so.gushiwen.org/user/collect.aspx',
'email': 'www.zhangbowudi@qq.com',
'pwd': 'bobo328410948',
'code': code_text,
'denglu': '登录',
}
page_text = s.post(url=login_url,headers=headers,data=data).text
with open('login.html','w',encoding='utf-8') as fp:
fp.write(page_text)
#动态变化的请求参数 通常情况下动态变化的请求参数都会被隐藏在前台页面源码中
使用 multiprocessing.dummy Pool 线程池
模拟请求
#未使用线程池(模拟请求)
import time
from time import sleep
start = time.time()
urls = [
'www.1.com',
'www.2.com',
'www.3.com',
]
def get_request(url):
print('正在访问:%s'%url)
sleep(2)
print('访问结束:%s'%url)
for url in urls:
get_request(url)
print('总耗时:',time.time()-start)
#执行结果
正在访问:www.1.com
访问结束:www.1.com
正在访问:www.2.com
访问结束:www.2.com
正在访问:www.3.com
访问结束:www.3.com
总耗时: 6.000494718551636
#使用线程池 (模拟请求)
import time
from time import sleep
from multiprocessing.dummy import Pool
start = time.time()
urls = [
'www.1.com',
'www.2.com',
'www.3.com',
]
def get_request(url):
print('正在访问:%s' % url)
sleep(2)
print('访问结束:%s' % url)
pool = Pool(3)
pool.map(get_request, urls)
print('总耗时:', time.time() - start)
#执行结果
正在访问:www.1.com
正在访问:www.2.com
正在访问:www.3.com
访问结束:www.2.com
访问结束:www.3.com
访问结束:www.1.com
总耗时: 2.037109613418579
简单使用Flask模拟server端 进行测试
#server
from flask import Flask
from time import sleep
app = Flask(__name__)
@app.route('/index')
def index():
sleep(2)
return 'hello'
if __name__ == '__main__':
app.run()
#爬虫请求代码
import time
import requests
from multiprocessing.dummy import Pool
start = time.time()
urls = [
'http://localhost:5000/index',
'http://localhost:5000/index',
'http://localhost:5000/index',
]
def get_request(url):
page_text = requests.get(url).text
print(page_text)
pool = Pool(3)
pool.map(get_request, urls)
print('总耗时:', time.time() - start)
#执行结果
hello
hello
hello
总耗时: 3.0322463512420654
单线程+多任务异步协程
- 协程
- 在函数(特殊的函数)定义的时候,如果使用了async修饰的话,则改函数调用后会返回一个协程对象,并且函数内部的实现语句不会被立即执行
- 任务对象
- 任务对象就是对协程对象的进一步封装。任务对象==高级的协程对象==特殊的函数
- 任务对象时必须要注册到事件循环对象中
- 给任务对象绑定回调:爬虫的数据解析中
- 事件循环
- 当做是一个容器,容器中必须存放任务对象。
- 当启动事件循环对象后,则事件循环对象会对其内部存储任务对象进行异步的执行。
- aiohttp:支持异步网络请求的模块
简单了解 asyncio异步协程函数
import asyncio
def callback(task):#作为任务对象的回调函数
print('i am callback and ',task.result())#task.result()接受特殊函数的返回值
async def test(): #特殊函数
print('i am test()')
return 'bobo'
c = test()#c为协程对象
#封装了一个任务对象
task = asyncio.ensure_future(c)
#绑定回调函数
task.add_done_callback(callback)
#创建一个事件循环的对象
loop = asyncio.get_event_loop()
#将任务对象注册到事件循环中
loop.run_until_complete(task)
#执行结果
i am test()
i am callback and bobo
协程+多任务(模拟请求)
import time
import asyncio
start = time.time()
# 在特殊函数内部的实现中不可以出现不支持异步的模块代码
async def get_request(url):
await asyncio.sleep(2)
print('访问成功:', url)
urls = [
'www.1.com',
'www.2.com'
]
tasks = []
for url in urls:
c = get_request(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop = asyncio.get_event_loop()
# 注意:挂起操作需要手动处理
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start)
#执行结果
访问成功: www.1.com
访问成功: www.2.com
2.002183198928833
使用requests模块,发现并不能实现异步
#server端
from flask import Flask
from time import sleep
app = Flask(__name__)
@app.route('/index')
def index():
sleep(2)
return 'hello'
@app.route('/index1')
def index1():
sleep(2)
return 'hello1'
if __name__ == '__main__':
app.run()
#爬虫代码
import requests
import time
import asyncio
s = time.time()
urls = [
'http://127.0.0.1:5000/index',
'http://127.0.0.1:5000/home'
]
async def get_request(url):
page_text = requests.get(url).text
return page_text
tasks = []
for url in urls:
c = get_request(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time()-s)
#执行结果 并未实现异步
4.021323204040527
#因为requests不支持异步,需要使用aiohttp
使用aiohttp模块,实现了异步
#server端
from flask import Flask
from time import sleep
app = Flask(__name__)
@app.route('/index')
def index():
sleep(2)
return 'index'
@app.route('/home')
def index1():
sleep(2)
return 'home'
if __name__ == '__main__':
app.run()
#爬虫代码
import aiohttp
import time
import asyncio
s = time.time()
urls = [
'http://127.0.0.1:5000/index',
'http://127.0.0.1:5000/home'
]
async def get_request(url):
#每个with前要加async
async with aiohttp.ClientSession() as s:
#在阻塞操作前加await
async with await s.get(url=url) as response:#get(url=url,headers,params,proxy)可用参数
page_text = await response.text()#要加括号,是方法
print(page_text)
return page_text
tasks = []
for url in urls:
c = get_request(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - s)
#执行结果
index
home
2.016155242919922
示例二
########################test.html文件########################
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- 上述3个meta标签*必须*放在最前面,任何其他内容都*必须*跟随其后! -->
<title>Bootstrap 101 Template</title>
<!-- Bootstrap -->
<link href="bootstrap-3.3.7-dist/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<h1>你好,世界!</h1>
<ul>
<li>i am hero!!!</li>
<li>i am superMan!!!</li>
<li>i am Spider!!!</li>
</ul>
</body>
</html>
########################server端########################
import time
from flask import Flask,render_template
app = Flask(__name__)
@app.route('/bobo')
def index_bobo():
time.sleep(2)
return render_template('test.html')
@app.route('/jay')
def index_jay():
time.sleep(2)
return render_template('test.html')
@app.route('/tom')
def index_tom():
time.sleep(2)
return render_template('test.html')
if __name__ == '__main__':
app.run(threaded=True)
########################爬虫代码########################
import time
import aiohttp
import asyncio
from lxml import etree
start = time.time()
urls = [
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom',
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom',
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom',
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom'
]
# 特殊的函数:请求发送和响应数据的捕获
# 细节:在每一个with前加上async,在每一个阻塞操作的前边加上await
async def get_request(url):
async with aiohttp.ClientSession() as s:
# s.get(url,headers,proxy="http://ip:port",params)
async with await s.get(url) as response:
page_text = await response.text() # read()返回的是byte类型的数据
return page_text
# 回调函数
def parse(task):
page_text = task.result()
tree = etree.HTML(page_text)
parse_data = tree.xpath('//li/text()')
print(parse_data)
tasks = []
for url in urls:
c = get_request(url)
task = asyncio.ensure_future(c)
task.add_done_callback(parse)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start)
#执行结果 实现了异步
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
['i am hero!!!', 'i am superMan!!!', 'i am Spider!!!']
2.094982147216797
总结
- 单线程+多任务异步协程
- 协程
- 如果一个函数的定义被asyic修饰后,则改函数调用后会返回一个协程对象。
- 任务对象:
- 就是对协程对象的进一步封装
- 绑定回调
- task.add_done_callback(func):func(task):task.result()
- 事件循环对象
- 事件循环对象是用来装载任务对象。该对象被启动后,则会异步的处理调用其内部装载的每一个任务对象。(将任务对象手动进行挂起操作)
- aynic,await
- 注意事项:在特殊函数内部不可以出现不支持异步模块的代码,否则会中断整个异步的效果!!!
- aiohttp支持异步请求的模块
requests模块 高级应用的更多相关文章
- requests模块高级
requests模块高级 cookie cookie: 基于用户的用户数据 -需求:爬取用户的豆瓣网的个人页面数据 cookie作用:服务器端使用cookie来记录客户端的状态信息 实现流程: 1.执 ...
- 爬虫 requests模块高级用法
一 介绍 #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3) #注意:requests库发送请求将网页内 ...
- 爬虫--requests模块高级(代理和cookie操作)
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- requests模块高级操作之cookie
一.cookie 存储在客户端的键值对,可以让服务端记录客户端相关状态. 如何处理cookie? 手动处理: 将抓包工具中的请求头信息中的cookie键值拷贝到header中 自动处理:session ...
- requests模块高级操作之proxies
一.代理proxy 概念:代理服务器 作用:请求和响应的转发 免费代理 www.goubanjia.com 快代理 西祠代理 代理精灵(付费) 匿名度: 透明:对方服务器知道你使用代理也知道你真实ip ...
- requests模块的使用
requests模块 什么是request模块:requests是python原生一个基于网络请求的模块,模拟浏览器发起请求. requests-get请求 # get请求 import reques ...
- 爬虫requests模块 1
让我们从一些简单的示例开始吧. 发送请求¶ 使用 Requests 发送网络请求非常简单. 一开始要导入 Requests 模块: >>> import requests 然后,尝试 ...
- Python requests模块
import requests 下面就可以使用神奇的requests模块了! 1.向网页发送数据 >>> payload = {'key1': 'value1', 'key2': [ ...
- python爬虫之requests模块介绍
介绍 #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3) #注意:requests库发送请求将网页内容下 ...
随机推荐
- 【JavaScript】frame跨域访问元素
什么是跨frame访问元素呢?比如main.html中有如下代码: <frameset cols="50%,*"> <frame src="frame1 ...
- t5_sumdoc.txt
C:\Users\Administrator\Documents\sumdoc 2019\sumdoc t5 final\sumdoc t511C:\Users\Administrator\Docum ...
- FilelistCreator --- 导出文件列表神器 及其他好用工具
https://www.sttmedia.com/ Standard Software WordCreator: Creates readable words, sentences or texts ...
- rabbitMQ消息队列 – Message方法解析
消息的创建由AMQPMessage对象来创建$message = new AMQPMessage("消息内容");是不是很简单. 后边是一个数组.可以对消息进行一些特殊配置$mes ...
- Java学习-054-Mybatis IN查询,通过 foreach 获取列表数据
通过如下语句查询商品订单信息: ,,,) 在 Mapper.java 中定义如下接口: List<GoodsOrder> findGoodsOrderByIds(String ids); ...
- 解决 No IDEA annotations attached to the JDK 1.8和xml文件没有代码提示
Android studio3.3 用着用着突然xml里没有代码联想了,忙着做其他的就没管,写xml的时候就硬写... 然后今天用着突然在class文件上方提示No IDEA annotations ...
- SVM – 回归
SVM的算法是很versatile的,在回归领域SVM同样十分出色的.而且和SVC类似,SVR的原理也是基于支持向量(来绘制辅助线),只不过在分类领域,支持向量是最靠近超平面的点,在回归领域,支持向量 ...
- 基于term vector深入探查数据
1.term vector介绍 获取document中的某个field内的各个term的统计信息 term information: term frequency in the field, term ...
- shell基础知识4--别名、采集终端信息
别名就是一种便捷方式,可以为用户省去输入一长串命令序列的麻烦.下面我们会看到如何 使用 alias 命令创建别名. 直接使用alias就是显示当前有哪些别名,否则就是创建别名 [root@dns-no ...
- CentOS7 ping: unknown host www.baidu.com
原文链接:https://blog.csdn.net/zz657114506/article/details/53871470