【RS】:论文《Neural Collaborative Filtering》的思路及模型框架
【论文的思路】
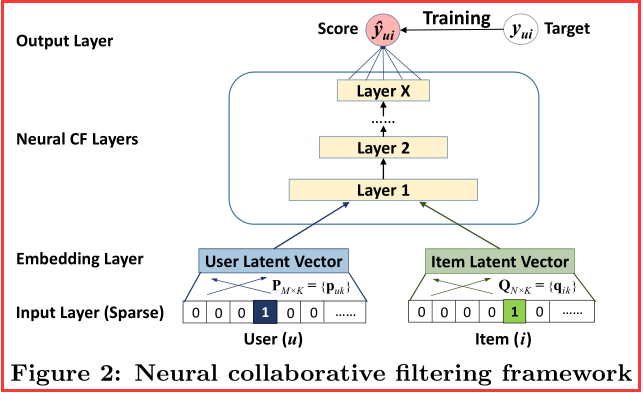
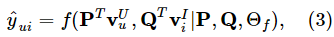


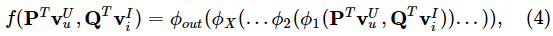
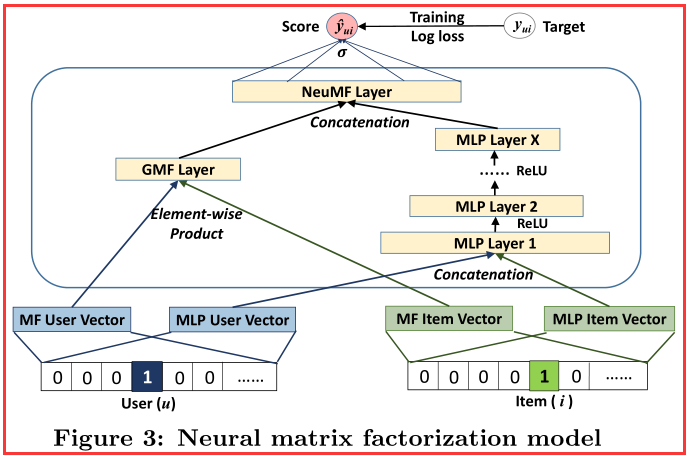
.png)


.png)


【广义矩阵分解】
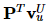 表示用户的潜在向量
表示用户的潜在向量 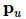 ,
,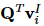 表示项目的潜在向量
表示项目的潜在向量 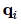
- 定义第一层神经CF层的映射函数为:
.png)

- 将向量映射到输出层:
.png)

.png)

.png)

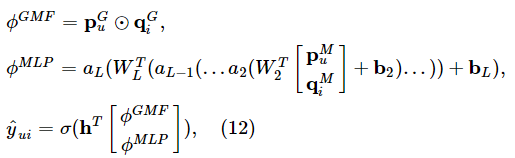
.png)


.png)


.png)


【RS】:论文《Neural Collaborative Filtering》的思路及模型框架的更多相关文章
- 论文笔记 : NCF( Neural Collaborative Filtering)
ABSTRACT 主要点为用MLP来替换传统CF算法中的内积操作来表示用户和物品之间的交互关系. INTRODUCTION NeuCF设计了一个基于神经网络结构的CF模型.文章使用的数据为隐式数据,想 ...
- 【翻译】Neural Collaborative Filtering--神经协同过滤
[说明] 本文翻译自新加坡国立大学何向南博士 et al.发布在<World Wide Web>(2017)上的一篇论文<Neural Collaborative Filtering ...
- 协同滤波 Collaborative filtering 《推荐系统实践》 第二章
利用用户行为数据 简介: 用户在网站上最简单存在形式就是日志. 原始日志(raw log)------>会话日志(session log)-->展示日志或点击日志 用户行一般分为两种: 1 ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
- 【RS】Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model - 当因式分解遇上邻域:多层面协同过滤模型
[论文标题]Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model (35th-ICM ...
- 【RS】List-wise learning to rank with matrix factorization for collaborative filtering - 结合列表启发排序和矩阵分解的协同过滤
[论文标题]List-wise learning to rank with matrix factorization for collaborative filtering (RecSys '10 ...
- 【RS】Amazon.com recommendations: item-to-item collaborative filtering - 亚马逊推荐:基于物品的协同过滤
[论文标题]Amazon.com recommendations: item-to-item collaborative filtering (2003,Published by the IEEE C ...
- 【RS】AutoRec: Autoencoders Meet Collaborative Filtering - AutoRec:当自编码器遇上协同过滤
[论文标题]AutoRec: Autoencoders Meet Collaborative Filtering (WWW'15) [论文作者]Suvash Sedhain †∗ , Aditya K ...
- mahout算法源码分析之Collaborative Filtering with ALS-WR 并行思路
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit. mahout算法源码分析之Collaborative Filtering with ALS-WR 这个算 ...
随机推荐
- 单词大学CET六四级英语
2012年大学英语六级词汇 baseball n.棒球:棒球运动 basement n.地下室:地窖:底层 basin n.内海:盆地,流域 battery n.炮兵连:兵器群 battle vi.战 ...
- 使用linq对ado.net查询出来dataset集合转换成对象(查询出来的数据结构为一对多)
public async Task<IEnumerable<QuestionAllInfo>> GetAllQuestionByTypeIdAsync(int id) { st ...
- 深入解析 Go 中 Slice 底层实现
原文: https://halfrost.com/go_slice/ 切片是 Go 中的一种基本的数据结构,使用这种结构可以用来管理数据集合.切片的设计想法是由动态数组概念而来,为了开发者可以更加 ...
- 【Visio】亲测Visio2013激活,破解工具下载
破解方法地址: https://blog.csdn.net/qq_38276669/article/details/85046615
- 7.vertical-align属性
本节学习目标: 图片.表单和旁边的文字对齐 解决图片底部默认空白缝隙问题 1.图片.表单和旁边的文字对齐 默认的图片.表单等行内元素或行内快元素是和文字的基线对齐的,但在实际情况下,我们想让他们中间对 ...
- vue-cli随机生成port源码
const portfinder = require('portfinder'): const port = await portfinder.getPortPromise(): 两行代码 端口搜索范 ...
- QML官方文档:Qt Quick Controls 1和2对比
Qt Quick Controls有1和2两个版本,在程序中会看到好多1和2版本混合使用的情况. 原文:https://doc.qt.io/qt-5/qtquickcontrols2-differen ...
- 浅谈华为验厂对MES系统的要求
众所周知,华为对供应商在管理.防错.品控.追溯等方面的要求都非常严格.在华为验厂时,对供应商的信息系统,尤其是MES系统的评估也是有非常具体的要求.那么我们今天就来谈谈华为验厂时,对MES系统有哪些具 ...
- 电信NBIOT 1 - 数据上行(中国电信开发者平台对接流程)
电信NBIOT 1 - 数据上行(中国电信开发者平台对接流程) 电信NBIOT 2 - 数据上行(中间件获取电信消息通知) 电信NBIOT 3 - 数据下行 电信NBIOT 4 - NB73模块上行测 ...
- JVM Code Cache空间不足,导致服务性能变慢
本文阅读时间大约5分钟. 有业务反馈,线上一个应用运行了一段时间之后,在高峰期之后,突然发现处理能力下降,接口的响应时间变长,但是看Cat上的GC数据,一切都很正常. 通过跳板机上机器查看日志,发现一 ...