python 面试真题
0、Python是什么?

- Python是一种解释型语言。但是跟C和C的衍生语言不同,Python代码在运行之前不需要编译。其他解释型语言还包括PHP和Ruby。
- Python是动态类型语言,指的是在声明变量时,不需要说明变量的类型。可以直接编写类似
x=111和x="Hello World"这样的代码,程序不会报错。 - Python是一门强类型语言,是指不容忍隐式的类型转换,比如字符串类型的数字和整型的数字进行比较不会成立。
- Python非常适合面向对象的编程(OOP),因为它支持通过组合(composition)与继承(inheritance)的方式定义类(class)。
- 在Python语言中,函数是第一类对象(first-class objects)。这指的是它们可以被指定给变量,函数既能返回函数类型,也可以接受函数作为输入。类(class)也是第一类对象。
- Python代码编写快,而运行速度比编译语言通常要慢。但是Python允许加入基于C语言编写的扩展,也常被用作“胶水语言”。因此我们能够优化代码,消除瓶颈。比如说
numpy就是一个很好地例子,它的运行速度非常快。 - Python用途非常广泛——爬虫、Web 程序开发、桌面程序开发、自动化、科学计算、科学建模、大数据应用、图像处理、人工智能等等。
- Python包含八种数据类型:字符串、元组、字典、列表、集合、布尔类型、整型、浮点型。拥有三大特性:封装、继承、多态。最显著特点是采用缩进/4个空格(不能混用)表示语句块的开始和结束。
- Python的标识符命名规则有:可以由字母下划线数字组成,不能以数字开头,不能与关键字重名,不能含有特殊字符和空格,使用大驼峰、小驼峰式命名。Python区分大小写
_单下划线开头:声明为私有变量,通过from M import * 方式将不导入所有以下划线开头的对象,包括包、模块、成员。
单下划线结尾_:为了避免与python关键字的命名冲突。
__双下划线开头:模块内的成员,表示私有成员,外部无法直接调用
__双下划线开头双下划线结尾__:指那些包含在用户无法控制的名字空间中的“魔术”对象或属性,如类成员的name 、doc、init、import、file、等。
表达式:算术运算符 + - * / // % ; 比较运算符 > < >= <= != ; 逻辑运算符 and or not ;判断是否为同一对象:is、is not ; 判断是否属于另一个对象: in 、not in。
函数支持递归、默认参数值、可变参数、闭包,实参与形参之间的结合是传递对象的引用。另外还支持字典、集合、列表的推导式。
Python3中的print函数代替Python2的print语句
Python3中的Str类型代表Unicode字符串,Python2中的Str类型代表bytes字节序列
Python3中的 / 返回浮点数,Python2中根据结果而定,能被整除返回整数,否则返回浮点数
Python3中的捕获语法 except exc as var 代替Python2中的 except exc, var
1、Python新式类&旧式类的区别
Python2中默认都是旧式类,除非显式继承object才是新式类; Python3中默认都是新式类,无需显式继承object。
新式类对象可以直接通过__class__属性获取自身类型:实例对象a1.__class__ 、type(实例对象a1)结果为:<class '__main__.A1'>; 旧式类为 __main__.A、<type 'instance'>
多继承时,经典类搜索父类的顺序: 先深入继承树左侧,再返回开始找右侧,菱形搜索,深度优先搜索(MRO算法); 新式类搜索父类的顺序: 先水平搜索,然后再向上移动,广度优先搜索(C3算法)。
新式类增加了__slots__内置属性, 可以把实例属性的种类锁定到__slots__规定的范围之中。
新式类增加了__getattribute__方法
2、如何在一个函数内部修改全局变量
a = 10 def info():
print(a) def foo():
global a
a = 22
print(a) print(a)
info()
foo() # 经过foo函数的修改,a的值已变为22
print(a)
info()
3、列出5个python标准库
标准库:sys、os、re、urllib、logging、datetime、random、threading、multiprocessing、base64
第三方库:requests、Scrapy、gevent、pygame、pymysql、pymongo、redis-py、Django、Flask、Werkzeug、celery、IPython、pillow
4、字典如何删除键和合并两个字典
di = {"name": "power"}
ci = {"age": 18}
# 删除键
del di["name"]
# 合并字典
di.update(ci)
5、python实现列表去重的方法
li = [2, 2, 1, 0, 0, 1, 2] # 方法一:使用set方法
sl = list(set(li)) # 方法二:额外使用一个列表
li2 = list()
for i in li:
if i not in li2:
li2.append(i) # 方法三:使用列表的sort方法
l1 = ['b','c','d','c','a','a']
l2 = list(set(l1))
l2.sort(key=l1.index)
print(l2) l1 = ['b','c','d','c','a','a']
l2 = sorted(set(l1),key=l1.index)
print(l2)
6、一句话解释什么样的语言能够用装饰器?
装饰器本质上是一个Python函数,他可以让其他函数在不需要做任何代码改动的前提下额外增加功能,装饰器接收一个函数作为参数,返回值也是一个函数。
谁可以用:函数可以作为参数传递的语言,就可以使用装饰器。
作用:在不改变源代码的情况下添加新的功能。
使用场景:插入日志、性能测试(计算函数运行时间)、事务处理(让函数实现事务的一致性)、缓存、权限校验等场景 问题:函数A接收整数参数n,返回一个函数B,函数B是将函数A的参数与n相乘后的结果返回 def info(func):
def foo(n):
res = func(n)
return res * n
return foo @info
def func(n):
return n func(2)
[Out]: 4
7、python内建数据类型有哪些
# 不可变类型
int 整形
str 字符串
float 浮点型
tuple 元组 bool 布尔型 # 可变类型
list 列表
dict 字典
8、简述面向对象中__new__和__init__区别
1、__new__必须接收一个名为 cls 的参数,代表的是当前类对象。
2、__new__必须有返回值,返回的是由当前类对象创建的实例对象,而__init__什么都不返回。
3、__init__必须接收一个名为 self 的参数,代表的是由__new__方法所创建的实例对象。
4、只有在__new__方法返回一个 cls 的实例时,后面的__init__才能被调用。
5、当创建一个新实例对象是,自动调用__new__方法, 当初始化一个实例时调用__init__方法。ps:__metaclass__是创建类时起作用.所以我们可以分别使用__metaclass__,__new__和__init__来分别在类创建,实例创建和实例初始化的时候做一些小手脚.
9、进程&线程&协程?
1、进程多与线程进行比较
- 线程是CPU真正调度的单位,也是进程内的一个执行单元,进程是系统资源分配的基本单位;
- 一个进程内至少有一个线程,同一个进程内的线程共享进程的资源,而进程有自己独立的地址空间,每个进程各自有独立的资源互不干扰。
- 每个独立的线程必须有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在进程当中。
- 不仅进程之间可以并发执行,同一个进程的多个线程之间也可以并发执行。
- 多线程的意义在与一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
2、协程与线程进行比较
- 一个线程内可以有多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
- 线程进程都是同步机制,而协程可以选择同步或异步。
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态。
10、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
li = [1, 2, 3, 4, 5] def info(x):
return x**2 li2 = [i for i in map(info, li) if i > 10]
11、python中生成随机整数、随机小数、0--1之间小数方法
import random
import numpy as np # 随机整数
print(random.randint(0, 99999)) # 随机小数
print(np.random.randn()) # 随机 0-1 小数
print(random.random())
12、避免转义给字符串加哪个字母表示原始字符串?
import re a = 'power.top*one' res = re.match(r'.*', a) print(res) # 注:r 只针对于Python代码生效,与re正则并无关系
13、<div class="nam">中国</div>,用正则匹配出标签里面的内容(“中国”),其中class的类名是不确定的
import re a = '<div class="nam">中国</div>' res = re.match(r'<div class=".*">(.*)</div>', a)
res.group(1) res = re.findall(r'<div class=".*">(.*)</div>', a)
print(res[0])
14、python中断言方法举例

15、数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
select distinct name from student
16、10个Linux常用命令
cd、ls、cp、mv、mkdir、touch、cat、grep、echo、pwd、more、tar、tree
17、python2和python3区别?
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
2、python3的range 返回可迭代对象,python2的range返回列表,xrange返回迭代器
for ... in 和 list() 都是迭代器
3、python2中使用ascii编码,python中使用utf-8编码 4、python2中unicode表示字符串序列,str表示字节序 python3中str表示字符串序列,byte表示字节序列 5、python2中为正常显示中文,引入coding声明,python3中不需要 6、python2中是raw_input()函数,python3中是input()函数
18、列出python中可变数据类型和不可变数据类型,并简述原理
可变类型: 列表、字典 不可变类型:字符串、整型、浮点型、元组
19、s = "ajldjlajfdljfddd",去重并从小到大排序输出"adfjl"
s = "ajldjlajfdljfddd" # set方法
li = list(set(s))
li.sort() # 注:sort 没有返回值 # 循环遍历
li2 = []
for i in s:
if i not in li2:
li2.append(i)
li2.sort()
20、用lambda函数实现两个数相乘
nu = lambda x, y: x*y nu(2, 3) lambda 函数是一个可以接收任意多个参数(包括可选参数)并且返回单个表达式值的函数。 1、lambda函数比较轻便,即用即扔,很适合的场景是,需要完成一项功能,但此功能只在此一处使用,连名字都很随意的情况下。
2、匿名函数,一般用来给 filter、map 这样的函数式编程服务。
3、作为回调函数,传递给某些应用,比如消息处理。
21、字典根据键从小到大排序
dict(sorted(di.items(), key=lambda x: x))
22、利用collections库的Counter方法统计字符串每个单词出现的次数"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
from collections import Counter s = "kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
Counter(s) # 输出结果
Counter({'l': 9, 'h': 6, ';': 6, 'f': 5, 'a': 4, 'd': 3, 'j': 3, 's': 2, 'b': 1, 'g': 1, 'k': 1})
23、字符串a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳
import re a = "not 404 found 张三 99 深圳" # 第一种方式
res = re.sub('[^\u4e00-\u9fa5]', '', a).split()
print(res) # 第二种方式
value = re.findall(r'[^a-zA-Z\d\s]+', a)
print(''.join(value))
24、filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# filter(function, iterable) function -- 判断函数。 iterable -- 可迭代对象。
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def info(x):
if x % 2 == 1:
return x
print(list(filter(info, a)))
25、列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
li = [i for i in a if i % 2 == 1]
26、正则re.complie作用
re.compile是将正则表达式编译成一个对象,加快速度,并重复使用
27、a=(1,)b=(1),c=("1") 分别是什么类型的数据?
元组 : a=(1,)
整型 :b=(1)
字符串 : c=("1")
28、两个列表合并为一个列表
#[1,2,5,6,7,8,9] li1 = [1,5,7,9]
li2 = [2,2,6,8] # 第一种方法
li3 = list(set(li1 + li2))
print(li3.sort()) # 第二种方法
li1.extent(li2)
li5 = list(set(li1))
li5.sort()
print(li5)
# 第三种方法
li6 = li1 + li2
print(li6)
29、用python删除文件和用linux命令删除文件方法
python: os.remove(文件名)
linux: rm 文件名
30、log日志中,我们需要用时间戳记录error,warning等的发生时间,请用datetime模块打印当前时间戳 “2018-04-01 11:38:54”
from datetime import datetime
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
print(datetime.strftime(datetime.now(), "%Y-%m-%d %H:%M:%S"))
# Out[12]: '2019-03-30 18:57:55'
logging模块的日志等级:
DEBUG 最详细的日志信息,典型应用场景是:问题诊断
INFO 信息细程度仅次于DEBUG,通常只记录关键节点信息,用于确认一切都是按照我们预期的那样进行工作
WARNING 当某些不期望的事情发生时记录的信息(如,磁盘可用空间较低),但是此时应用程序还是正常运行的
ERROR 由于一个更严重的问题导致某些功能不能正常运行时记录的信息
CRITICAL 当发生验证错误,导致应用程序不能继续运行时记录的信息
logging.debug('debug message')
logging.info('info message')
logging.warn('warn message')
logging.error('error message')
logging.critical('critical message') 31、写一段自定义异常代码
li = [1, 2, 3, 0] for i in li:
try:
if i == 0:
raise Exception("遍历得到0")
except Exception as e:
print(e)
32、正则表达式匹配中,(.*)和(.*?)匹配区别?
(.*)是贪婪匹配,会把满足正则的尽可能多的往后匹配
(.*?)是非贪婪匹配,会把满足正则的尽可能少匹配
33、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
li = [[1, 2], [3, 4], [5, 6]] lis = [j for i in li for j in i]
34、x="abc",y="def",z=["d","e","f"],分别求出x.join(y)和x.join(z)返回的结果
x="abc" z=["d","e","f"] y="def" x.join(y)
# Out[202]:'dabceabcf' x.join(z)
# Out[202]: 'dabceabcf'
35、举例说明异常模块中 try except else finally 的相关意义
li = [1, 2, 3, 0] for i in li:
try:
if i == 0:
raise Exception("遍历得到0")
except Exception as e:
print(e)
else:
print(i)
finally:
print("顺利跑完") # Out[28]:
1
顺利跑完
2
顺利跑完
3
顺利跑完
遍历得到0
顺利跑完 try: 放置可能出现异常的代码
except: 当出现异常时,执行此处代码
else: 当程序没有没有出现异常时,执行此处代码
finally: 不管程序是否出现异常,此处代码都会执行
36、举例说明zip()函数用法
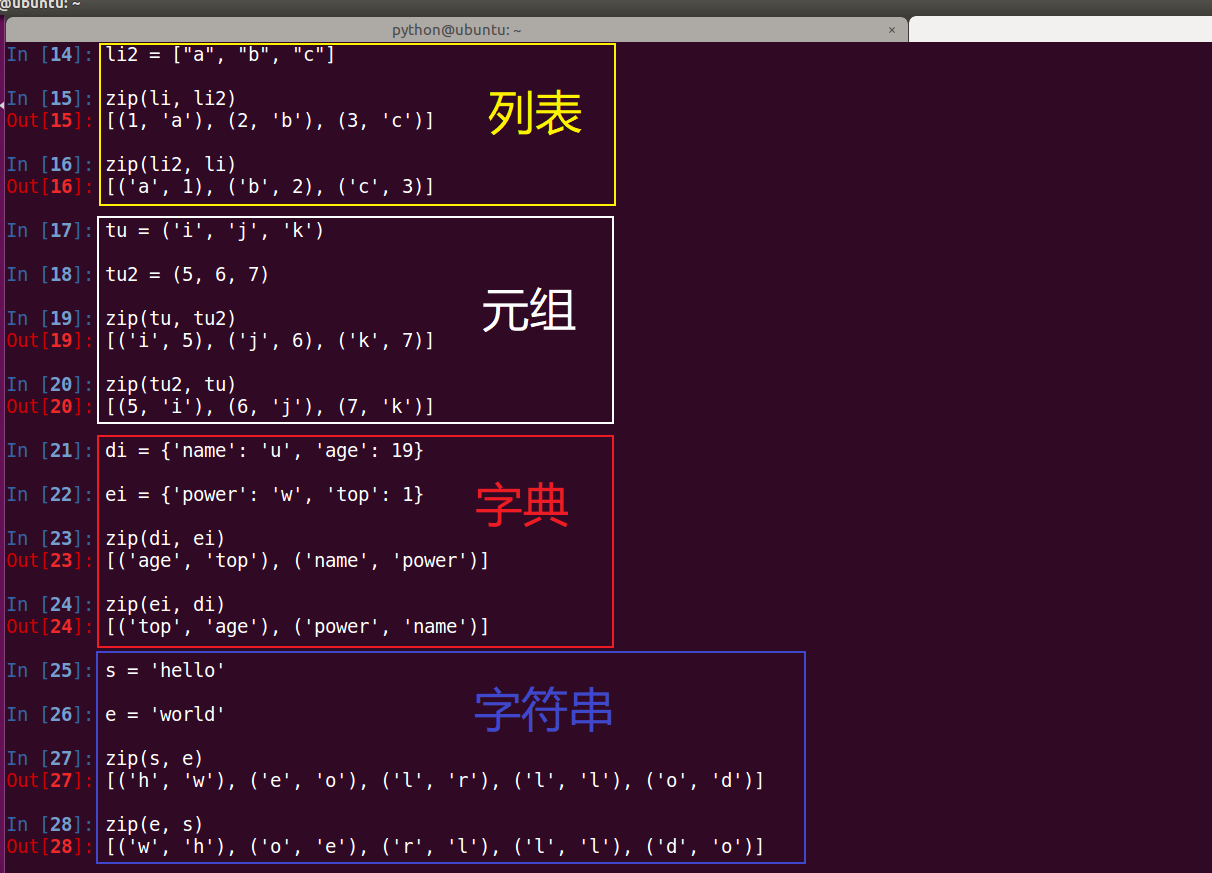
37、a="张明 98分",用re.sub,将98替换为100
res = re.sub(r'\d+', '100', a)
print(res)
38、写5条常用sql语句
# 增
insert into student (name, age) values ("power", 22); # 删
delete from student where name="power"; # 改
update student set age=12 where name="power"; # 查
select name from student where id=2;
39、简述ORM
O 模型类对象 R 关系 M 映射 : 模型类对象和数据库的表的映射关系 ORM拥有转换语法的能力,没有执行SQL 语句的能力,执行SQL语句需要安装数据库驱动(python3解释器需安装PyMySQL, python2解释器需安装mysql)django只能识别mysqldb驱动,需要给pymysql起别名骗过django ORM作用:
1. 将面向对象的操作数据库的语法转换为相对应SQL语句
2. 解决数据库之间的语法差异性(根据数据库的配置不同,生成不同的SQL语句)
40、a="hello"和b="你好"编码成bytes类型
a="hello"
print(b'a') b="你好"
print(b.encode())
41、提高python运行效率的方法
1、使用生成器,因为可以节约大量内存。 2、循环代码的优化,避免重复执行循环代码。 3、核心模块用Cython PyPy等,提高效率。 4、对于不同场景使用多进程、多线程、协程,充分利用CPU资源。 5、多个if elif条件判断,将最有可能先发生的条件放到前面写,可减少程序判断的次数。
42、遇到bug如何处理
0、查看报错信息(错误日志信息),分析bug出现原因。 1、在接口的开头打断点,单步执行往下走,逐渐缩小造成bug的代码范围。 2、【可选】在程序中通过 print() 打印,能执行到print() 说明一般上面的代码没有问题,分段检测程序是否有问题,如果是js的话可以alert或console.log 2、若自己无法解决,利用搜索引擎将报错信息进行搜索。 3、查看官方文档,或者一些技术博客。 4、查看框架的源码。 5、对于bug进行管理与归类总结,一般测试将测试出的bug用teambin等bug管理工具进行记录。
43、正则匹配,匹配日期2018-03-20
a= 'aa20kk18-power03-30oo' res = re.findall(r'[-\d]+', a)
data = ''.join(res)
print(data) Out[82]: '2018-03-30'
44、list=[2,3,5,4,9,6],从小到大排序,不许用sort,输出[2,3,4,5,6,9]
li = [2, 3, 5, 4, 9, 6]
lis = []
# 冒泡排序
for i in range(len(l)-1):
for j in range(len(l)-1):
if l[j] > l[j+1]:
l[j],l[j+1] = l[j+1], l[j] Out[51]: [2, 3, 4, 5, 6, 9] # 递归删除
def info():
nu = min(li)
li.remove(nu)
lis.append(nu)
# 如果原列表中仍有数据,再次调用自身进行删除&追加
if len(li)> 0:
info()
print(lis) info()
Out[77]: [2, 3, 4, 5, 6, 9]
45、写一个单例模式
# 第一种方法: 基类 __new__ 方法是真正创建实例对象的方法
class Info(object):
def __new__(cls, *args, **kwargs):
if not hasattr(cls, '_instance'):
cls._instance = super(Info, cls).__new__(cls, *args, **kwargs)
return cls._instance info = Info()
info2 = Info()
print(id(foo), id(foo2))
#Out[106]: 140395100343696, 140395100343696 # 第二种方法 type元类是python创建类对象的类,类对象创建实例对象时必须调用 __call__方法
class Info(type):
def __call__(cls, *args, **kwargs):
if not hasattr(cls, '_instance'):
#cls._instance = super().__call__(*args, **kwargs)
cls._instance = super(Info, cls).__call__(*args, **kwargs)
return cls._instance class Foo(object):
__metaclass__ = Info f = Foo()
f1 = Foo()
print(id(f), id(f1))
#Out[122]: 139622152568912, 139622152568912 # 第三种方法:使用装饰器
def singleton(cls):
instances = {}
def wrapper(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return wrapper
@singleton
class Foo(object):
pass
foo1 = Foo()
foo2 = Foo()
print foo1 is foo2 # True
单例模式应用场景:
资源共享的情况下,避免由于资源操作时导致的性能或损耗等,如日志文件,应用配置。
控制资源的情况下,方便资源之间的互相通信。如线程池等,1,网站的计数器 2,应用配置 3.多线程池 4数据库配置 数据库连接池 5.应用程序的日志应用...
46、保留两位小数
a = 0.255
b = 22 # 保留2位小数
print("%0.2f" % a) # 补足6位
print("%06d" % b)
47、分别从前端、后端、数据库阐述web项目的性能优化
前端内容优化:
(1)减少HTTP请求数:这条策略是最重要最有效的,因为一个完整的请求要经过DNS寻址,与服务器建立连接,发送数据,等待服务器响应,接收数据这样一个消耗时间成本和资源成本的复杂的过程。常见方法:合并多个CSS文件和js文件,利用CSS Sprites整合图像,Inline Images(使用 data:URL scheme在实际的页面嵌入图像数据 ),合理设置HTTP缓存等。
(2)减少DNS查找
(3)避免重定向
(4)使用Ajax缓存
(5)延迟加载组件,预加载组件
(6)减少DOM元素数量:页面中存在大量DOM元素,会导致javascript遍历DOM的效率变慢。
(7)最小化iframe的数量:iframes 提供了一个简单的方式把一个网站的内容嵌入到另一个网站中。但其创建速度比其他包括JavaScript和CSS的DOM元素的创建慢了1-2个数量级。
(8)避免404:HTTP请求时间消耗是很大的,因此使用HTTP请求来获得一个没有用处的响应(例如404没有找到页面)是完全没有必要的,它只会降低用户体验而不会有一点好处。
cookie优化:
(1)减小Cookie大小
(2)针对Web组件使用域名无关的Cookie
CSS优化:
(1)将CSS代码放在HTML页面的顶部
(2)避免使用CSS表达式
(3)使用<link>来代替@import
(4)避免使用Filters
JavaScript优化:
(1)将JavaScript脚本放在页面的底部。
(2)将JavaScript和CSS作为外部文件来引用:在实际应用中使用外部文件可以提高页面速度,因为JavaScript和CSS文件都能在浏览器中产生缓存。
(3)缩小JavaScript和CSS
(4)删除重复的脚本
(5)最小化DOM的访问:使用JavaScript访问DOM元素比较慢。
(6)开发智能的事件处理程序
(7)javascript代码注意:谨慎使用with,避免使用eval Function函数,减少作用域链查找。
HTML优化:
1、HTML标签有始终。 减少浏览器的判断时间
2、把script标签移到HTML文件末尾,因为JS会阻塞后面的页面的显示。
3、减少iframe的使用,因为iframe会增加一条http请求,阻止页面加载,即使内容为空,加载也需要时间
4、id和class,在能看明白的基础上,简化命名,在含有关键字的连接词中连接符号用'-',不要用'_'
5、保持统一大小写,统一大小写有利于浏览器缓存,虽然浏览器不区分大小写,但是w3c标准为小写
6、清除空格,虽然空格有助于我们查看代码,但是每个空格相当于一个字符,空格越多,页面体积越大,像google、baidu等搜索引擎的首页去掉了所有可以去掉的空格、回车等字符,这样可以加快web页面的传输。可以借助于DW软件进行批量删除 html内标签之间空格,sublime text中ctrl+a,然后长按shift+tab全部左对齐,清除行开头的空格
7、减少不必要的嵌套,尽量扁平化,因为当浏览器编译器遇到一个标签时就开始寻找它的结束标签,直到它匹配上才能显示它的内容,所以当嵌套很多时打开页面就会特别慢。
8、减少注释,因为过多注释不光占用空间,如果里面有大量关键词会影响搜索引擎的搜索
9、使用css+div代替table布局,去掉格式化控制标签如:strong,b,i等,使用css控制
10、代码要结构化、语义化
11、css和javascript尽量全部分离到单独的文件中
12、除去无用的标签和空标签
13、尽量少使用废弃的标签,如b、i等,尽管高版本浏览器是向后兼容的
服务器优化:
(1)CDN:把网站内容分散到多个、处于不同地域位置的服务器上可以加快下载速度。
(2)GZIP压缩
(3)设置ETag:ETags(Entity tags,实体标签)是web服务器和浏览器用于判断浏览器缓存中的内容和服务器中的原始内容是否匹配的一种机制。
(4)提前刷新缓冲区
后端优化:
1.SQL优化,最常见的方式是,优化联表查询,以及优化索引。这里面包括,尽量使用left join 替代 where联表;当碰到,频繁查询字段A和字段B,以及AB联合查询的情况时,对AB做联合索引,能够有效的降低索引存储空间,提升查询效率。在复杂联表的情况下,可以考虑使用 Memory中间表。
2.主从数据库和读写分离,主从分库是用来应对访问量增加,带来频繁读写导致数据库的访问和操作性能下降的问题。对数据库的操作,为了保证数据的完整性,通常涉及到锁的机制的问题。MySQL的InnoDB引擎支持行级锁,而MyIsAM只支持表锁定。这样的话,如果读写集中在一个表中的情况下,当访问量增加,就会造成明显的性能下降。因此,通过主从数据库的方式可以实现读写分离。一般来说,使用InnoDB来作为写库,使用MyISAM作为读库。这种方式是缺点当然是,数据库的维护难度增加,但是通常都会有专门的DBA这个职位来负责。
3.数据库分库和分表.有的时候会出现,某个表变得越来越庞大,比如存放message信息表,这样会造成读取性能的增加。这种情况下,你可以通过分表的方式来解决。将一个大表切分成若干个表。
4.使用存储过程中,将一些操作,直接通过存储过程的方式,预先设置在MySQL,客户端只需要调用存储过程就可以操作数据。
5.对动态页面进行缓存,比如网站首页,内容页等这种查询次数高,数据改动不大的页面:应用程序读取数据时,先从缓存中读取,如果读取不到或数据已失效,再访问磁盘数据库,并将数据再次写入缓存。
- 1)直接生成静态html页面,需要更新时通过后台成生成新页面进行覆盖。然后可以把静态页存放到本地硬盘或者同步到CDN上。
- 2)使用vanish服务器作为方向代理,对php生成的动态页面进行缓存,由于vanish可以使用内存作为缓存,因此访问速度更快,且对生成页面的php代码不需要做任何的修改,就可以实现静态页面缓存。所以可以很好地解决因为一直遗留下来的问题导致代码修改成本高的情况。缺点也是,提升了运维成本。
6.浏览器缓存,通过Cache-Control,以及Last-Modified等控制缓存头的设置来告诉浏览器缓存页面。这样不必每次,都从服务器端重复请求新文件,也可以防止用户频繁刷新页面。
代码优化:
- 不断通过for循环去进行查找
- 错误的选择了容器,导致不断的遍历查找
- 在循环中添加了很多可以移到循环之外只运行一次的函数调用
- 可以实现成 事件触发的逻辑 变成了轮询
- 函数中存在大量重复调用
- 避免循环和判断次数太多,如果多个if else判断,将最有可能先发生的情况优先判断
- 将耗时操作放入celery异步任务中
48、简述同源策略
协议相同: http / https
域名(主机号)相同
端口相同
49、简述cookie和session的区别
cookie数据存储在客户端的浏览器上,session数据存储在服务器端。
cookie通过request对象获取cookie,通过response对象设置cookie,并且cookie的设置和读取不能够同步进行,比如:第一次设置cookie时不能够立马获取。Session的获取&设置都通过request对象进行。
cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。session存储在服务器上,相对于cookie更安全。
单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。 session中多用于存储敏感、重要的信息,session依赖于cookie。 session会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能考虑到减轻服务器性能方面,应当使用COOKIE。
Session的存储过程: session通过request对象进行设置,假设将session数据(键值对)存储到数据库中,会生成一个session_id交由响应对象返回给浏览器,浏览器会将其保存在本地。之后每一次请求这个网站时会自动携带session_id,服务器会根据session_id取出整条session数据。注意:session是依赖于cookie的,但是在浏览器中是可以禁用掉cookie的。即:cookie被禁用,session也将失去意义,此条session记录在服务器中将不能取出。
5、建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
50、简述any()和all()方法
any():只要迭代器中有一个元素为真就为真
all():迭代器中所有的判断项返回都是真,结果才为真
Python中为假的条件:False、None、[]、()、{}、""、0
51、IOError、AttributeError、ImportError、IndentationError、IndexError、KeyError、SyntaxError、NameError分别代表什么异常
IOError:输入输出异常
AttributeError:试图访问一个对象没有的属性
ImportError:无法引入模块或包,基本是路径问题
IndentationError:语法错误,代码没有正确的对齐
IndexError:下标索引超出序列边界
KeyError:试图访问你字典里不存在的键
SyntaxError:Python代码逻辑语法出错,不能执行
NameError:使用一个还未赋予对象的变量
52、单位转换
1 bytes = 8 bit
1024 bytes = 1KB
1024 KB = 1 MB
1024 MB = 1 GB
1024 GB = 1 TB
1024 TB = 1 PB
1024 PB = 1 EB
1024 EB = 1 ZB
10进制,人类使用。
2进制, 供计算机使用,1,0代表开和关,有和无,机器只认识2进制。
16进制,内存地址空间是用16进制的数据表示, 如0x8049324。
十进制转二进制: 十进制数除2取余法,即十进制数除2,余数为权位上的数,得到的商值继续除2,依此步骤继续向下运算直到商为0为止。
二进制转十进制: 把二进制数按权展开、相加即得十进制数。
二进制转八进制: 3位二进制数按权展开相加得到1位八进制数。(注意事项,3位二进制转成八进制是从右到左开始转换,不足时补0)。
八进制转成二进制: 八进制数通过除2取余法,得到二进制数,对每个八进制为3个二进制,不足时在最左边补零。
二进制转十六进制:与二进制转八进制方法近似,八进制是取三合一,十六进制是取四合一。(注意事项,4位二进制转成十六进制是从右到左开始转换,不足时补0)。
十六进制转二进制: 十六进制数通过除2取余法,得到二进制数,对每个十六进制为4个二进制,不足时在最左边补零。
十进制转八进制&十进制转十六进制:1.间接法—把十进制转成二进制,然后再由二进制转成八进制或者十六进制。 2.直接法—把十进制转八进制或者十六进制按照除8或者16取余,直到商为0为止。
八进制转十进制&十六进制转十进制:把八进制、十六进制数按权展开、相加即得十进制数。
八进制与十六进制之间的转换:1.先转成二进制然后再相互转换。 2.他们之间的转换可以先转成十进制然后再相互转换。
53、列出几种魔法方法并简要介绍用途
__new__(cls[, ...]) 1.实例化对象时第一个被调用的方法 2.其参数直接传递给__init__方法处理 __init__(self[, ...]) 构造方法,初始化类的时候被调用
__del__(self) 析构方法,当实例化对象被彻底销毁时被调用(实例化对象的所有指针都被销毁时被调用)
__call__(self[, args...]) 允许一个类的实例像函数一样被调用:x(a, b) 调用 x.__call__(a, b)
__len__(self) 定义当被 len() 调用时的行为
__repr__(self) 定义当被 repr() 调用时的行为
__str__(self) 定义当被 str() 调用时的行为
__bytes__(self) 定义当被 bytes() 调用时的行为
__hash__(self) 定义当被 hash() 调用时的行为
__bool__(self) 定义当被 bool() 调用时的行为,应该返回 True 或 False
__format__(self, format_spec) 定义当被 format() 调用时的行为
54、a = " hehheh ",去除首尾空格
a.strip()
Out[95]: 'hehheh'
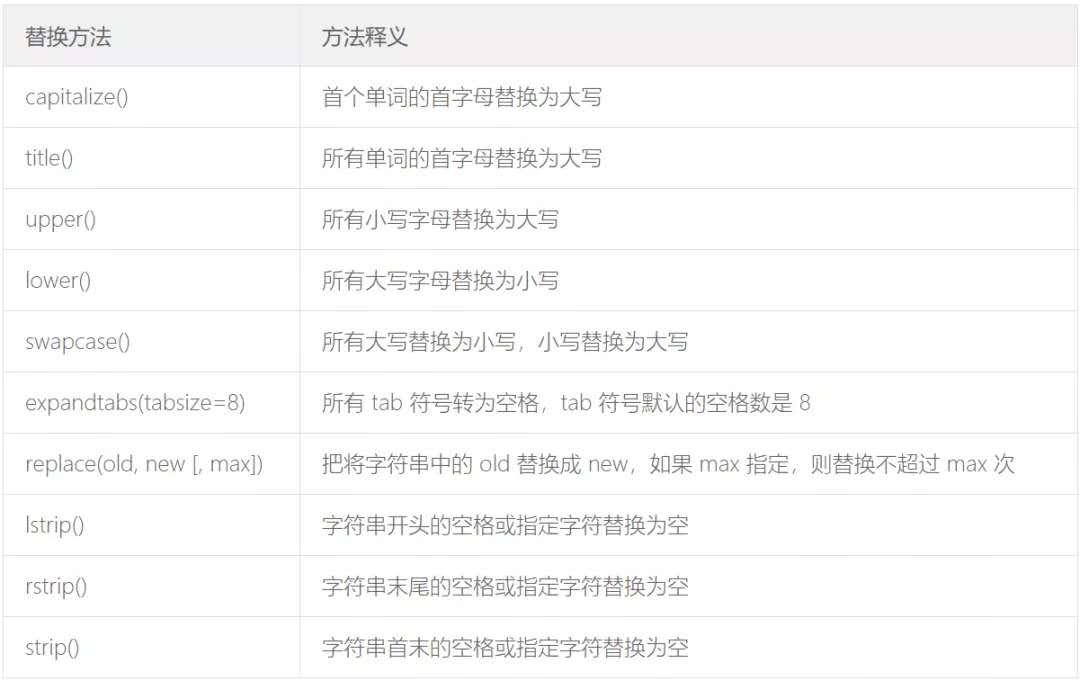
55、用两种方法去除空格
# 第一种方法:使用split方法分割
a = ' hello world '
b = a.split()
c = ''.join(b)
print(c)
#Out[22]: ''helloworld'' # 第二种方法:使用re正则
a = ' hello world '
b = re.sub(' ', '', a)
print(b)
#Out[23]: ''helloworld'' # 第三种方法:使用strip方法去除首尾空格
a = ' helloworld '
b = a.strip()
print(b)
#Out[24]: 'helloworld'
# rstrip():去除尾部空格; lstrip():去除首部空格

56、举例sort和sorted对列表排序,list=[0,-1,3,-10,5,9]
li=[0,-1,3,-10,5,9] li.sort()
print(li)
Out[90]: [-10, -1, 0, 3, 5, 9] lis = sorted(li)
print(lis)
Out[90]: [-10, -1, 0, 3, 5, 9]
57、对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],使用lambda函数从小到大排序
foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4] # 第一种方式
g = lambda x: x.sort()
g(foo)
print(foo)
# Out[102]: [-20, -5, -4, -4, -2, 0, 2, 4, 8, 8, 9] # 第二种方式
a = sorted(foo, key=lambda x: x)
print(a)
58、使用lambda函数对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],输出结果为[0,2,4,8,8,9,-2,-4,-4,-5,-20],正数从小到大,负数从大到小
foo = [-5, 8, 0, 4, 9, -4, -20, -2, 8, 2, -4] g = sorted(foo, key=lambda x:(x<0, abs(x))) print(g) Out[113]: [0, 2, 4, 8, 8, 9, -2, -4, -4, -5, -20]
58、字典分别按照key、value排序
a = {'y': 2, 'x':1, 'z': 3}
# 按照key排序 - 升序
g = sorted(a.items(), key=lambda x: x[0])
dict(g)
[Out]:{'x': 1, 'y': 2, 'z': 3}
# 按照key排序 - 降序
g = sorted(a.items(), key=lambda x: x[0], reverse=True)
dict(g)
[Out]: {'z': 3, 'y': 2, 'x': 1}
# 按照value排序 - 升序
g = sorted(a.otems(), key=lambda x: x[1])
dict(g)
[Out]: {'x': 1, 'y': 2, 'z': 3}
# 按照value排序 - 降序
g = sorted(a.items(), key=lambda x: x[1], reverse=True)
dict(g)
[Out]: {'z': 3, 'y': 2, 'x': 1}
59、列表嵌套字典,根据年龄排序
alist = [{'name':'a','age':20},{'name':'b','age':30},{'name':'c','age':25}]
def sort_by_age(list1):
return sorted(alist, key=lambda x:x['age'], reverse=True)
60、以下代码的输出结果,为什么?
list = ['a','b','c','d','e']
print(list[10:]) 代码将输出[],不会产生IndexError错误,就像所期望的那样,尝试用超出成员的个数的index来获取某个列表的成员。例如,尝试获取list[10]和之后的成员,会导致IndexError。
然而,尝试获取列表的切片,开始的index超过了成员个数不会产生IndexError。
61、给定两个列表,怎么找出他们相同的元素和不同的元素?
A = [1,2,3]
B = [3,4,5] A,B 中相同元素: print(set(A) & set(B)) A,B 中不同元素: print(set(A) ^ set(B))
62、列表推导式、字典推导式、生成器
# 列表推导式
li = [i for i in range(1,101) if i % 2 ==0] # 字典推导式
a = [0, 1, 2]
b = ['a', 'b', 'c']
c = {a[i]:b[i] for i in range(len(a))} # 生成器
def info(num):
offset = 0
a = 0
b = 1 while offset < num:
result = a
a, b = b, a+b
offset += 1
yield result print(list(info(10)))
63、正则匹配IPV4地址
IPV4由四组数字组成,中间由.隔开: a = "169.254.0.112"
re.search(r'(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9]?[0-9])\.(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9]?[0-9])\.(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9]?[0-9])\.(25[0-5]|2[0-4][0-9]|1[0-9][0-9]|[1-9]?[0-9])$', a).group()
64、举例说明SQL注入和解决办法
产生原因:程序开发过程中不注意规范书写 sql 语句和对特殊字符进行过滤,导致客户端可以通过全局变量POST 和 GET 提交一些 sql 语句正常执行。产生 Sql 注入。 防止办法:
a. 过滤掉一些常见的数据库操作关键字,或者通过系统函数来进行过滤。
b. 对传入的参数进行编码转义。
c. SQL 语句书写的时候尽量不要省略小引号(tab 键上面那个)和单引号
d. 提高数据库命名技巧,对于一些重要的字段根据程序的特点命名,取不易被猜到的
e. 使用Python的pymysql模块自带的方法,给execute传递两个参数,第一个是SQL语句,第二个是列表格式的SQL语句所需参数
65、s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong']
s = 'info:xiaoZhang 33 shandong'
# 正则方式
g = re.findall(r'[^:\s]+', s)
Out[162]: ['info', 'xiaoZhang', '33', 'shandong']
# spilt分隔方式
li = []
li.extend(s.split(":")[0].split() + s.split()) Out[156]: ['info', 'xiaoZhang', '33', 'shandong']
66、正则匹配以163.com结尾的邮箱
re.match(r'[0-9a-zA-Z_]{0,19}@163.com', text).group()
67、递归求和
def info(num):
if num > 0:
res = num + info(num - 1)
else:
res = 0
return res
res = info(10)
print(res)
68、python字典和json字符串相互转化方法
json.dumps() 字典转json字符串
json.loads() json转字典
69、快排
def info(li):
midpivot = lil[0]
lesspivot = [i for i in li[1:] if i <= midpivot]
biggpivot = [i for i in li[1:] if i > midpivot]
lesspivot.sort()
biggpivot.sort()
result = lesspivot + [midpivot] + biggpivot
print(result)
70、RESTFul风格
# 1、后端API定义规范
请求方法 请求地址 后端操作
GET /goods 获取所有商品
POST /goods 增加商品
GET /goods/1 获取编号为1的商品
PUT /goods/1 修改编号为1的商品
DELETE /goods/1 删除编号为1的商品 # 2、尽量将API部署在专用域名之下。
https://api.example.com # 将API的版本号放入URL。
http://www.example.com/app/2.0/foo # 3、路径
资源作为网址,只能有名词,不能有动词,而且所用的名词往往与数据库的表名对应。
API中的名词应该使用复数。无论子资源或者所有资源。 # 4、错误处理
服务器向用户返回出错信息时,返回的信息以error作为键名,出错信息作为value值即可。 # 5、返回结果规范
GET /collection:返回资源对象的列表(数组)
GET /collection/resource:返回单个资源对象
POST /collection:返回新生成的资源对象
PUT /collection/resource:返回完整的资源对象
PATCH /collection/resource:返回完整的资源对象
DELETE /collection/resource:返回一个空文档 # 6、超媒体
访问api.github.com会得到一个所有可用API的网址列表。 # 7、服务器返回的数据格式应尽量为json格式,避免使用xml
71、列举3条以上PEP8编码规范
分号:不要在行尾加分号, 也不要用分号将两条命令放在同一行. 行长度:每行不超过80个字符 缩进:用4个空格来缩进代码,绝对不要用tab, 也不要tab和空格混用 空行:顶级定义之间空两行, 方法定义之间空一行 空格:按照标准的排版规范来使用标点两边的空格,括号内不要有空格,不要在逗号、分号、 冒号前面加空格, 但应该在它们后面加(除了在行尾),参数列表, 索引或切片的左括号前不应加空格.
导入格式:每个导入应该独占一行
类:类应该在其定义下有一个用于描述该类的文档字符串. 如果你的类有公共属性(Attributes), 那么文档中应该有一个属性(Attributes)段. 并且应该遵守和函数参数相同的格式 继承:如果一个类不继承自其它类, 就显式的从object继承. 嵌套类也一样.
72、正则匹配中文
import re title = "Hello World, 你好 世界" pattern = re.compile(r'[\u4e00-\u9fa5]+')
res = pattern.findall(title) print(res)
73、Linux命令重定向 > 和 >>
Linux 允许将命令执行结果 重定向到一个 文件 将本应显示在终端上的内容 输出/追加 到指定文件中 > 表示输出,会覆盖文件原有的内容 >> 表示追加,会将内容追加到已有文件的末尾
74、正则表达式匹配出<html><h1>www.baidu.com</h1></html>
g = re.match(r'<(\w+)><(\w+)>(.*)</\2></\1>', a)
g.group()
75、遍历列表的同时删除元素
# 1.新表用于遍历,旧表用于删除元素
a = [1, 2, 3, 4, 5, 6, 7, 8]
print(id(a))
print(id(a[:]))
for i in a[:]:
if i>5:
pass
else:
a.remove(i)
print(a)
print('-----------')
print(id(a)) # 2.filter
a = [1, 2, 3, 4, 5, 6, 7, 8]
b = filter(lambda x: x>5, a)
print(list(b)) # 3.列表推导式
a = [1, 2, 3, 4, 5, 6, 7, 8]
b = [i for i in a if i > 5]
print(b) # 4.倒序删除
a = [1, 2, 3, 4, 5, 6, 7, 8]
print(id(a))
for i in range(len(a)-1,-1,-1):
if a[i]>5:
pass
else:
a.remove(a[i]) print(id(a))
print('-----------')
print(a)
76、常见的网络传输协议
HTTP(80) 浏览器的网络请求 协议
HTTPS(443) 浏览器的网络请求 协议
TCP 数据传输协议
UDP 数据传输协议
SMTP(25) 发邮件协议
TEL 电话协议
SMS 短信协议
POP3 收邮件协议 (需经过邮件服务器,从服务器拉去最新邮件时,服务器不做缓存)
IMAP 收邮件协议(即使本地邮件删除,服务器上还有备份的邮件)
HHT 文件传输协议
77、8个老师随机分配3个办公室, 每个办公室人数在2~3人
import random room_nums = 0 # 办公室数量默认是0
teacher_nums = 0 # 教师数量默认是0
while True:
r_nums = input("请输入办公室的个数:")
t_nums = input("请输入老师的个数:") # 如果教师数目大于等于办公室数目,才退出循环,并赋值给room_nums、teacher_nums
# 否则重新输入
if int(r_nums) <= int(t_nums):
room_nums = int(r_nums)
teacher_nums = int(t_nums)
break
else:
print("老师数低于办公室数,请重新输入") # 创建办公室列表,即创建一个嵌套列表 大列表:办公室 小列表:老师
rooms = []
while room_nums >= 1:
rooms.append([])
room_nums -= 1 # 创建老师列表,并添加老师
teachers = []
while teacher_nums>= 1:
teacher_nums -= 1
teachers.append("teacher%d"%(teacher_nums+1)) # 开始安排办公室
# 1.先随机选出三位老师,依次放到办公室中
for room in rooms:
# 随机选出一名老师,注意teachers长度会变
index = random.randint(0, len(teachers)-1)
# pop方法弹出一个元素,并列表中删除
teac = teachers.pop(index)
room.append(teac) # 2.将剩下的老师,再随机分配
for teacher in teachers:
room_index = random.randint(0, len(rooms)-1)
rooms[room_index].append(teacher)
print("分配结束后:", rooms)
78、静态函数、类函数、成员函数的区别
类方法: 是类对象的方法,在定义时需要在上方使用 @classmethod 进行装饰,形参为cls,表示类对象,类对象和实例对象都可调用 类实例方法: 是类实例化对象的方法,只有实例对象可以调用,形参为self,指代对象本身; 静态方法: 是一个任意函数,在其上方使用 @staticmethod 进行装饰,可以用对象直接调用,静态方法实际上跟该类没有太大关系
| \ | 实例方法 | 类方法 | 静态方法 |
|---|---|---|---|
| a = A() | a.foo(x) | a.class_foo(x) | a.static_foo(x) |
| A | 不可用 | A.class_foo(x) | A.static_foo(x) |
79、变量查找顺序
L: local 函数内部作用域(本地作用域) E: enclosing 函数内部与内嵌函数之间 G: global 全局/模块作用域 B: build-in 内置作用域
79.字符串 "123" 转换成 123,不使用内置api,例如 int()
# 方法一:利用 str方法
def atoi(s):
num = 0
for v in s:
for j in range(10):
if v == str(j):
num = num * 10 + j
return num # 方法二:利用 ord方法
def atoi(s):
num = 0
for v in s:
num = num * 10 + ord(v) - ord('0')
return num # 方法三:利用 eval方法
def atoi(s):
num = 0
for v in s:
t = "%s * 1" % v
n = eval(t)
num = num * 10 + n
return num # 方法四:使用 reduce 并结合方法二
from functools import reduce
def atoi(s):
return reduce(lambda num, v: num * 10 + ord(v) - ord('0'), s, 0)
80、MySQL的事务隔离级别
未提交读(Read Uncommitted):允许脏读,其他事务只要修改了数据,即使未提交,本事务也能看到修改后的数据值。也就是可能读取到其他会话中未提交事务修改的数据
提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)。
可重复读(Repeated Read):可重复读。无论其他事务是否修改并提交了数据,在这个事务中看到的数据值始终不受其他事务影响。
串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞 MySQL数据库(InnoDB引擎)默认使用可重复读( Repeatable read) 命令行修改数据库事务隔离级别:transaction-isolation = {READ-UNCOMMITTED | READ-COMMITTED | REPEATABLE-READ | SERIALIZABLE}
配置文件中修改数据库事务隔离级别(最后一行进行添加):transaction-isolation={READ-UNCOMMITTED | READ-COMMITTED | REPEATABLE-READ | SERIALIZABLE}
===============================================================================================================
隔离级别 脏读(Dirty Read) 不可重复读(NonRepeatable Read) 幻读(Phantom Read)
===============================================================================================================
未提交读(Read uncommitted) 可能 可能 可能
已提交读(Read committed) 不可能 可能 可能
可重复读(Repeatable read) 不可能 不可能 可能
可串行化(Serializable ) 不可能 不可能 不可能
===============================================================================================================
脏读: 是指事务T1将某一值修改,然后事务T2读取该值,此后T1因为某种原因撤销对该值的修改,这就导致了T2所读取到的数据是无效的。
当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个修改了还未提交的数据。
栗子: 1.Mary的原工资为1000, 财务人员将Mary的工资改为了8000(但未提交事务)
2.Mary读取自己的工资 ,发现自己的工资变为了8000,欢天喜地!
3.而财务发现操作有误,回滚了事务,Mary的工资又变为了1000
像这样,Mary记取的工资数8000是一个脏数据。
不可重复读 :是指在数据库访问时,一个事务范围内的两次相同查询却返回了不同数据。在一个事务内多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么在第一个事务中的两次读数据之间,由于第二个事务的修改,第一个事务两次读到的的数据可能是不一样的。这样在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
栗子:1.在事务1中,Mary 读取了自己的工资为1000,操作并没有完成。
2.在事务2中,这时财务人员修改了Mary的工资为2000,并提交了事务。
3.在事务1中,Mary 再次读取自己的工资时,工资变为了2000。
解决办法:如果只有在修改事务完全提交之后才可以读取数据,则可以避免该问题。
幻读: 是指当事务不是独立执行时发生的一种现象,比如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么就会发生,操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
栗子:目前工资为1000的员工有10人。
1.事务1,读取所有工资为1000的员工。
2.这时事务2向employee表插入了一条员工记录,工资也为1000
3.事务1再次读取所有工资为1000的员工 共读取到了11条记录,
解决办法:一般解决幻读的方法是增加范围锁RangeS,锁定检索范围为只读,这样就避免了幻读。如果在操作事务完成数据处理之前,任何其他事务都不可以添加新数据,则可避免该问题
丢失更新:两个事务同时更新一行数据,最后一个事务的更新会覆盖掉第一个事务的更新,从而导致第一个事务更新的数据丢失,这是由于没有加锁造成的;
81、TCP协议的 TIME WAITE 状态
# 1.TIME WAITE状态:
是指主动关闭方在发送四次挥手的最后一个ACK后会进入TIME_WAIT状态,也就是这个发起关闭的一方会保持2MSL时间之后才会回到初始状态。(linux里一个MSL为30s,是不可配置的) # 2.MSL值是数据包在网络中的最大生存时间。当主动关闭方进入TIME WAITE状态后,会使得这个TCP连接在2MSL连接等待期间,定义这个连接的四元数组(local_ip, local_port, remote_ip,remote_port)不能被使用。 # 3.TIME_WAIT状态产生的原因:
虽然双方都同意关闭连接了,而且握手的4个报文也都协调和发送完毕,按理可以直接回到CLOSED状态(就好比从SYN_SEND状态到ESTABLISH状态那样);但因为我们必须要假想网络是不可靠的,你无法保证你最后发送的ACK报文会一定被对方收到
假设发起主动关闭的一方(client)四次挥手时最后发送的ACK在网络中丢失,但由于TCP协议的重传机制,执行被动关闭的一方(server)将会重发上一个数据包FIN,所以这个TIME_WAIT状态的作用就是用来重发可能丢失的ACK报文。(TCP属于全双工连接) # 4.TIME_WAIT两个MSL的作用:
可靠安全的关闭TCP连接。比如网络拥塞,主动方最后一个ACK被动方没收到,这时被动方会对FIN开启TCP重传,发送多个FIN包,在这时尚未关闭的TIME_WAIT就会把这些尾巴问题处理掉,不至于对新连接及其它服务产生影响。 # 5.TIME_WAIT状态如何避免(端口复用):
如果服务器程序停止后想立即重启,而新的套接字依旧希望使用同一端口,可以通过(SO_REUSEADDR, True)选项避免TIME_WAIT状态。
82、网络的七层协议
OSI的7层从上到下分别是:
7 应用层 6 表示层 5 会话层 4 传输层 3 网络层 2 数据链路层 1 物理层
其中高层(即7、6、5、4层)定义了应用程序的功能,下面3层(即3、2、1层)主要面向通过网络的端到端的数据流。 应用层:与其它计算机进行通讯的一个应用,它是对应应用程序的通信服务的。TELNET,HTTP,FTP,NFS,SMTP 表示层:定义数据格式及加密。加密,ASCII等。 会话层:定义了如何开始、控制和结束一个会话,包括对多个双向消息的控制和管理,以便在只完成连续消息的一部分时可通知应用,表示层看到的数据是连续的,本质用于区分不同进程的。RPC,SQL等。 传输层:负责将数据进行可靠或者不可靠传递,负责终端之间的传送。即:选择差错恢复协议还是无差错恢复协议,以及在同一主机上对不同应用的数据流输入进行复用,还包括对收到顺序不对的数据包的重新排序功能。TCP,UDP,SPX。 网络层:负责选择最佳路径,并保证数据始终沿着最佳路径传输,以数据包为单位。IP,IPX等。 数据链路层:在单个链路上如何传输数据,比如对数据进行处理封装成数据帧,进行传递和错误检测的就是数据链路层,数据以帧为单位。ATM,FDDI等。 物理层:为网络设备之间的数据通信提供传输媒体及互连设备,为数据传输提供可靠的环境,数据是以比特的形式传递的。Rj45,802.3等。 栗子:从西班牙去罗马的贸易商人
1、 要想贸易获得成功,首先要有至少一条路,能够从西班牙通向罗马。此层为【物理层】
2、有了路是不是就能去贸易了?还要保证路上不会把商人的货物给磕坏了,要有一层保护的包装。引出第二层,【数据链路层】
3、所谓条条道路通罗马。并不只有一条路能够到达罗马,那么在那么多的选择中选一条最短的,或者路费的成本最少的,这才符合商人的利益。引出第三层,【网络层】以上三层为网络中的下三层,叫媒体层,让我们来看看另外4层。
4、贸易出门前要先检查一下自己的货,有没有拿错了,事先要检查过,如果错了要重新取货,引出第四层,【传输层】。
5、是不是可以上路了?还不行。我们要和罗马联系好, 如果我们这边的货物到了那边卖不出去怎么办?我们首先要交流、协商一下,看看罗马的市场情况,能和那边的另外一个商人合作的话就更好了,这就需要一些外交的关系。叫做【会话层】。
6、好象所有的事情都准备好了,但是商人到了罗马以后突然发现,他的商队里没有人能听懂罗马人的话,罗马人也没有人能听懂西班牙语,这个时候,还需要一个翻译,要么把两种语言都转换成一种国际通用语言,比如说英语,要么至少能让双方能交流。这里就是【表示层】。
7、到了罗马了,最终需要在交易所中把商品卖掉,这个交易所就是一个交易平台,相当于各个软件平台,引出最后一层,【应用层】。
83、HTTP和TCP的keep-alive区别
1、keep-alive(持久连接/长连接):Http是一个”请求-响应”协议,它的keep-alive主要是为了使用同一个TCP连接来发送和接收多个HTTP请求/应答,而不是为每一个新的请求/应答打开新的连接的方法。可以减少tcp连接建立次数,也意味着可以减少TIME_WAIT状态连接,以此提高性能(更少的tcp连接意味着更少的系统内核调用,socket的accept()和close()调用)。
2、HTTP的keep-alive:
HTTP 1.0版本中默认没有keep-alive操作,是根据浏览器是否支持keep-alive而决定的,如果浏览器支持的话,它会在请求报头中添加 'Connection: Keep-Alive' 字段,而服务器做出响应时也会在响应报头中添加 'Connection: Keep-Alive',这样就会保持当前的连接而不会中断。HTTP 1.1版本中默认所有都是持久连接。
需要特别注意的是:长时间的tcp连接容易导致系统资源无效占用。配置不当的keep-alive,有时比重复利用连接带来的损失还更大。所以,正确地设置keep-alive timeout时间非常重要。keep alive_timout时间值意味着:一个http产生的tcp连接在传送完最后一个响应后,还需要hold住keep alive_timeout秒后,才开始关闭这个连接。 3、TCP的keep-alive:
Tcp的keep-alive是Tcp协议的一种保鲜装置,当链接建立之后,如果应用程序或者上层协议一直不发送数据,或者隔很长时间才发送一次数据的情况下,TCP协议需要考虑当链接很久没有数据报文传输时确定对方是否还在线,到底是掉线了还是确实没有数据传输,链接还需不需要保持。在此情况下,当超过一段时间之后,服务器自动发送一个监测包(数据为空的报文)
如果对方回应了这个报文,说明对方还在线,链接可以继续保持,如果对方没有报文返回,并且重试了多次之后则认为链接丢失,没有必要保持链接。 4、http keep-alive与tcp keep-alive: http keep-alive是为了让tcp活得更久一点,以便在同一个连接上传送多个http,提高socket的效率。而tcp keep-alive是TCP的一种检测TCP连接状况的机制。
tcp keepalive原理,当网络两端建立了TCP连接,但双方没有任何数据流发送往来,服务器内核就会尝试向客户端发送侦测包,来判断TCP连接状况(有可能客户端崩溃、强制关闭了应用、主机不可达等等)。如果没有收到对方的回答(ack包),则会在指定x时间后再次尝试发送侦测包,直到收到对方的ack包,如果一直没有收到对方的ack,一共会尝试y次数。如果重试y次数后,依然没有收到对方的ack包,则会丢弃该TCP连接。
长连接概念:所谓长连接,指在一个TCP连接上可以连续发送多个数据包,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接。连接->传输数据->保持连接 -> 传输数据 -> 直到一方关闭连接
短链接概念:短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接,即每次TCP连接只完成一对 CMPP消息的发送。连接->传输数据->关闭连接
- HTTP 协议的 KeepAlive 意图在于连接复用,同一个连接上串行方式传递请求-响应数据
- TCP 的 KeepAlive 机制意图在于保活、心跳,检测连接错误。
Redis设置长连接:修改redis.conf配置文件的tcp-keepalive=1(启用长连接), 默认为0(表示禁止长连接)
84、当保持长连接时,如何判断一次请求已经完成?
Content-Length
Content-Length表示实体内容的长度。浏览器通过这个字段来判断当前请求的数据是否已经全部接收。 所以,当浏览器请求的是一个静态资源时,即服务器能明确知道返回内容的长度时,可以设置Content-Length来控制请求的结束。
但当服务器并不知道请求结果的长度时,如一个动态的页面或者数据,Content-Length就无法解决上面的问题,这个时候就需要用到Transfer-Encoding字段。 Transfer-Encoding
Transfer-Encoding是指传输编码,在上面的问题中,当服务端无法知道实体内容的长度时,就可以通过指定Transfer-Encoding: chunked来告知浏览器当前的编码是将数据分成一块一块传递的。
当然, 还可以指定Transfer-Encoding: gzip, chunked表明实体内容不仅是gzip压缩的,还是分块传递的。最后,当浏览器接收到一个长度为0的chunked时, 知道当前请求内容已全部接收。
85、TCP&UDP的区别
TCP :
是一种面向连接的、可靠的字节流服务,一个客户端和一个服务器在发送数据之前必须先三次握手建立连接。
在一个 TCP 连接中,仅有两方进行彼此通信。广播和多播不能用于 TCP。
TCP 采用发送应答机制,所发送的每个报文段都必须得到接收方的应答才认为这个TCP报文段传输成功。
TCP 协议的超时重传机制,发送一个报文段后就启动定时器,若在一定时间内未收到对方应答就会重新发送这个报文段。
TCP 为了保证不发生丢包,会给每一个包标上序号,也保证了消息的有序性。该消息从服务器端发出顺序会以同样的顺序发送到客户端。
因为TCP必须创建连接,以保证消息的可靠交付和有序性,所以相对于UDP而言TCP速度比较慢。
TCP 数据包报头的大小是20字节,UDP数据报报头是8个字节。TCP报头中包含序列号,ACK号,数据偏移量,保留,控制位,窗口,紧急指针,可选项,填充项,校验位,源端口和目的端口。而UDP报头只包含长度,源端口号,目的端口,和校验和。
TCP 使用滑动窗口机制来实现流量控制,通过动态改变窗口的大小进行拥塞控制,以此避免主机发送得过快而使接收方来不及完全收下。
TCP 用⼀个校验和函数来检验数据是否有错误;在发送和接收时都要计算校验和。
TCP 使用发送应答机制、超时重传、错误校验、流控和阻塞管理来保证可靠传输。
注意:TCP 并不能保证数据一定会被对方接收到,因为这是不可能的。TCP 能够做到的是,如果有可能,就把数据递送到接收方;否则就(通过放弃重传并且中断连接这一手段)通知用户。因此准确说 TCP 也不是 100% 可靠的协议,它所能提供的是数据的可靠递送或故障的可靠通知。
UDP :
是无连接的,不可靠的,没有序列保证,但是一个快速传输的数据报协议。
UDP 缺乏可靠性。UDP 本身不提供确认,序列号,超时重传等机制。UDP 数据报可能在网络中被复制,被重新排序。即 UDP 不保证数据报会到达其最终目的地,也不保证各个数据报的先后顺序,也不保证每个数据报只到达一次
UDP 数据报是有长度的。每个UDP数据报都有长度,如果一个数据报正确地到达目的地,那么该数据报的长度将随数据一起传递给接收方。而 TCP 是一个字节流协议,没有任何(协议上的)记录边界。
UDP 是无连接的。UDP 客户和服务器之前不必存在长期的关系。UDP 发送数据报之前也不需要经过握手创建连接的过程。
UDP 支持多播和广播。
86、闭包是什么?
闭包必须满足的三个条件:
1、一个外函数中定义了一个内函数。
2、内嵌函数中引用了外部函数的变量。
3、外部函数的返回值是内嵌函数的引用。
87、中间件是什么?
中间件是一种独立的系统软件或服务程序,处在操作系统软件与用户的应用软件的中间,分布式应用软件借助这种软件在不同的技术之间共享资源(网络通信功能),管理计算机资源和网络通讯,相连接的系统,即使它们具有不同的接口,但通过中间件相互之间仍然能交换信息,以便于运行在一台或多台机器上的多个软件通过网络进行交互。
中间件的六大分类:终端仿真/屏幕转换中间件、数据访问中间件、远程过程调用中间件、消息中间件、交易中间件、对象中间件。
RPC远程过程调用中间件:主要用于client/server分布式计算
MOM面向消息中间件:指的是利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成,提供消息传递和消息排队模型,可在分布环境下扩展进程间的通信。
比如:IBM的MQSeries、BEA的MessageQ等;消息传递和排队技术特点:通讯程序可在不同的时间运行、对应用程序的结构没有约束、程序与网络复杂性相隔离
ORB对象请求代理中间件:提供一个通信框架,透明地在异构的分布计算环境中传递对象请求 django中,中间件其实就是一个类,监听请求进入视图之前 响应对象真正到达浏览器之前的中间执行过程,django会根据自己的规则在合适的时机执行中间件中相应的方法。在django项目的settings模块中,有一个 MIDDLEWARE_CLASSES 变量,其中每一个元素就是一个中间件
中间件中一共有四个方法:
__init__ # 初始化:无需任何参数,服务器响应第一个请求的时候调用一次,用于确定是否启用当前中间件 process_request(request) # 处理请求前:在每个请求上调用,返回None或HttpResponse对象。 process_view(request,view_func,view_args,view_kwargs) # 处理视图前:在每个请求上调用,返回None或HttpResponse对象。
process_template_response(request,response) # 处理模板响应前:在每个请求上调用,返回实现了render方法的响应对象。
process_exception(request,exception) # 当视图抛出异常时调用,在每个请求上调用,返回一个HttpResponse对象。 process_response(request,response) # 处理响应后:所有响应返回浏览器之前被调用,在每个请求上调用,返回HttpResponse对象。 Django自定义中间件类时,必须继承自MiddlewareMixin父类:from django.utils.deprecation import MiddlewareMixin
Flask中的请求钩子也类似于中间件,通过装饰器实现的,支持以下四种: before_first_request:第一次请求之前,可以在此方法内部做一些初始化操作。 before_request:每次请求之前,可以对不同请求的url处理不同的业务逻辑。 after_request:每次请求之后,可以使用response对象统一设置cookie。 teardown_request:每次请求之后是否有错误,会接受一个参数,参数是服务器出现的错误信息。
88、深浅拷贝
浅拷贝:copy.copy(变量);如果浅拷贝的是不可变对象,并没有产生开辟新的内存空间;如果浅拷贝的是简单的可变对象,会产生一块新的内存空间,修改原来值不影响拷贝值;如果浅拷贝的是复杂的可变对象,浅拷贝只拷贝父对象,不会拷贝对象内部的子对象,如果原来值的内部子对象发生改变,会影响到拷贝值,内部子对象仅仅是引用拷贝。浅拷贝有三种形式:切片操作、工厂函数(list(a))、copy模块中的copy函数
深拷贝:copy.deepcopy(变量);如果深拷贝的是不可变对象,仍然没有开辟新的内存空间;如果深拷贝的是可变对象,则会产生一块新的内存空间,修改原来值也不会影响拷贝值;如果深拷贝的是复杂的可变对象,深拷贝会拷贝父对象及其对象内部的所有子对象,如果原来值的内部子对象发生改变,不会影响到拷贝值,二者是独立存在,互不影响。 只要是拷贝不可变对象,无论浅拷贝还是深拷贝都是引用拷贝,都指向同一个内存空间;
89、Redis缓存击穿、缓存穿透、缓存雪崩
缓存穿透
概念:缓存穿透是指查询一个一定不存在的数据,由于缓存是请求数据不命中时被动写入的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,在流量大时数据库可能就挂掉了,通俗说就是恶意用户模拟请求很多缓存中不存在的数据,由于缓存中都没有,导致这些请求短时间内直接落在了数据库上,导致数据库异常。从系统层面来看像是穿透了缓存层直接达到db。
解决:
布隆过滤器(bloom filter):类似于哈希表的一种算法,将所有可能存在的数据哈希到一个足够大的bitmap中,在进行数据库查询之前会使用这个bitmap进行过滤,如果一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
空值缓存:一种比较简单的解决办法,在第一次查询完不存在的数据后,将该key与对应的空值也放入缓存中,只不过设定为较短的失效时间,最长不超过五分钟。,这样则可以应对短时间的大量的该key攻击,设置为较短的失效时间是因为该值可能业务无关,存在意义不大,且该次的查询也未必是攻击者发起,无过久存储的必要,故可以早点失效。 缓存雪崩
概念:缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决:
线程互斥:只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据才可以,每个时刻只有一个线程在执行请求,减轻了db的压力,但缺点也很明显,降低了系统的qps。
交错失效时间:可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。 缓存击穿
概念:对于一些设置了过期时间的key,如果这些key在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候可能会发生缓存被“击穿”的问题,和缓存雪崩的区别在于:缓存击穿是针对某一/几个key缓存,缓存雪崩则是很多key。当缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
比如:微博有一个热门话题的功能,用户对于热门话题的搜索量往往在一些时刻会大大的高于其他话题,这种我们成为系统的“热点“,由于系统中对这些热点的数据缓存也存在失效时间,在热点的缓存到达失效时间时,此时可能依然会有大量的请求到达系统,没有了缓存层的保护,这些请求同样的会到达db从而可能引起故障。击穿与雪崩的区别即在于击穿是对于特定的热点数据来说,而雪崩是全部数据。
解决:
二级缓存:对于热点数据进行二级缓存,并对于不同级别的缓存设定不同的失效时间,则请求不会直接击穿缓存层到达数据库。
互斥锁(mutex key): 只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据即可。
LRU算法:根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。最常见的实现是使用一个链表保存缓存数据,缓存步骤:
首先将新数据放入链表的头部
在进行数据插入的过程中,如果检测到链表中有数据被再次访问也就是有请求再次访问这些数据,那么就其插入的链表的头部,因为它们相对其他数据来说可能是热点数据,具有保留时间更久的意义
最后当链表数据放满时将底部的数据淘汰,也就是不常访问的数据
90、实现WSGI协议的框架
WSGI协议:必须同时实现 web server 和 web application;WSGI不是服务器,python模块,框架,API或者任何软件,只是一种规范,描述web server如何与web application通信的规范。
WSGI协议其实是定义了一种server与application解耦的规范,即可以有多个实现WSGI server的服务器,也可以有多个实现WSGI application的框架,可以选择任意的server和application组合实现自己的web应用。例如uWSGI和Gunicorn都是实现了WSGI server协议的服务器,Django,Flask是实现了WSGI application协议的web框架,可以根据项目实际情况搭配使用。
WSGI server:负责从客户端接收http请求,将request转发给WSGI application,将application返回的response返回给客户端。
WSGI application:接收由server转发的request,并处理请求,最后将response处理结果返回给server。application中可以包括多个栈式的中间件(middlewares),这些中间件需要同时实现server与application,可以在WSGI服务器与WSGI应用之间起调节作用:对服务器来说,中间件扮演应用程序,对应用程序来说,中间件扮演服务器。
WSGI application应该实现为一个可调用对象,例如函数、方法、类(包含`call`方法)。需要接收两个参数:1、一个字典,该字典可以包含了客户端请求的信息以及其他信息,可以认为是请求上下文,一般叫做environment(编码中多简写为environ、env) 2、一个用于发送HTTP响应状态(HTTP status )、响应头(HTTP headers)的回调函数 通过回调函数将响应状态和响应头返回给server,同时返回响应正文(response body),响应正文是可迭代的、并包含了多个字符串。
uwsgi:与WSGI一样是一种通信协议,是uWSGI服务器的独占协议,用于定义传输信息的类型(type of information),每一个uwsgi packet前4byte为传输信息类型的描述。
uWSGI:是一个web服务器,实现了WSGI协议、uwsgi协议、http协议等。主要特点:超快的性能,低内存占用,多app管理,详尽的日志功能(可以用来分析app的性能和瓶颈),高度可定制(内存大小限制,服务一定次数后重启等)。uWSGI服务器自己实现了基于uwsgi协议的server部分,我们只需要在uwsgi的配置文件中指定application的地址,uWSGI就能直接和应用框架中的WSGI application通信 生产环境使用的WSGI服务器: gunicorn:接受从Nginx转发的动态请求,处理完之后返回给Nginx,由Nginx返回给用户。 uwsgi:把HTTP协议转化成语言支持的网络协议。比如把HTTP协议转化成WSGI协议,让Python可以直接使用。 注:响应时间较短的应用中,使用uWSGI+django;如果有部分阻塞请求 Gunicorn+gevent+django有非常好的效率; 如果阻塞请求比较多的话,还是用tornado重写吧。
91、简述Django的MVT模式
### MVC: 浏览器 --> Controll Model : 用于 `Controll(服务器)和数据库的交互`,对数据库中的数据进行增、删、改、查操作。 View : 用于`封装html,css,js`,生成页面展示的html内容(数据的呈现方式)。 Controll : 用于 `接收请求,业务处理,返回结果` & `C和V交互、C和M交互、C和客户端交互` C必不可缺 ### MVT:浏览器 --> 路由器 --> View(MVC中的C) M : model `View (服务器)和数据库的交互` V : View 等同于 `MVC的Controll`,接收请求,业务处理,返回结果 & C和V交互 、C和M交互 、C和客户端交互 T : template `封装html,css,js`,负责封装构造要返回的html(如何显示数据,产生html界面)。 V必不可缺
92、Redis高并发的解决方法
Redis 主从 + 哨兵(sentinel)
Redis Sentinel 集群 + 内网 DNS + 自定义脚本
Redis Sentinel 集群 + VIP + 自定义脚本
封装客户端直连 Redis Sentinel 端口
JedisSentinelPool,适合 Java
PHP 基于 phpredis 自行封装
Redis Sentinel 集群 + Keepalived/Haproxy
Redis M/S + Keepalived
Redis Cluster
Twemproxy
Codis
Django解决高并发方案:HTTP重定向实现负载均衡、DNS负载均衡、反向代理负载均衡
93、实现斐波那契数列
# 1、生成器方式
def fibonacci(num): a = 0
b = 1
offset = 0 while offset < num:
result = a
a, b = b, a+b
offset += 1 yield result result = fibonacci(10)
for i in result:
print(i) # 2、迭代器方式 class Fibonacci(object):
"""
斐波那契数列 : 第一个数为 0 , 第二个数为 1 ,其后的每一个数都由前两数相加之和
""" def __init__(self, num): self.offset = 0 # 记录当前取值的位置
self.a = 0
self.b = 1
self.num = num # 指定最终输出数列的长度 def __iter__(self): return self # 返回自身,自身就是一个迭代器 def __next__(self): if self.offset < self.num:
result = self.a
self.a, self.b = self.b, self.a + self.b
self.offset += 1
return result
else:
raise StopIteration # 抛出异常,停止迭代 list1 = list(Fibonacci(10)) # 也可使用 元组,列表..接收结果
print(list1)
94、输入某年某月某日,判断今日是当年的第几天?
import datetime
y = int(input("请输入4位数字的年份:"))
m = int(input("请输入月份:"))
d = int(input("请输入是哪一天"))
targetDay = datetime.date(y,m,d)
dayCount = targetDay - datetime.date(targetDay.year -1,12,31)
print("%s是 %s年的第%s天。"%(targetDay,y,dayCount.days))
95、Django一次请求的生命周期?
1.wsgi ,请求封装后交给web框架(Flask,Django)
2.中间件,对请求进行校验或在请求对象中添加其他相关数据,例如:csrf,request.session
3.路由匹配 根据浏览器发送的不同url去匹配不同的视图函数
4.视图函数,在视图函数中进行业务逻辑的处理,可能涉及到:orm,templates
5.中间件,对响应的数据进行处理
6.wsgi,将响应的内容发送给浏览器
猴子补丁 : 在运行期间动态修改一个类或模块(在函数或对象已经定义之后,再去改变它们的行为)
1. 在运行时替换方法、属性等。 2. 在不修改第三方代码的情况下增加原来不支持的功能。 3. 在行⾏时为内存中的对象增加patc而不是在磁盘的源代码中
96、并行并发、同步异步、阻塞非阻塞
并行: 同一时刻多个任务同时在运行(实现并行:multiprocessing) CPU运算量大的程序,使用并行会更好
并发:不会在同一时刻同时运行,存在交替执行的情况。(实现并发的: threading) 需要执行较多的读写、请求和回复任务的需要大量的IO操作,IO密集型操作使用并发更好。
同步: 多个任务之间有先后顺序执行,一个执行完下个才能执行。 异步: 多个任务之间没有先后顺序,可以同时执行,有时候一个任务可能要在必要的时候获取另一个同时执行的任务的结果,这个就叫回调! 阻塞: 如果卡住了调用者,调用者不能继续往下执行,就是说调用者阻塞了。 非阻塞: 如果不会卡住,可以继续执行,就是说非阻塞的。 同步异步相对于多任务而言,阻塞非阻塞相对于代码执行而言。
97、简述Python的垃圾回收机制
主要是引用计数、垃圾回收机制、内存池机制。
使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,还有通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。最后使用内存池机制将不使用的内存放到内存当中,而不是直接返回给操作系统。
引用计数:Python在内存中存储了每个对象的引用计数(reference count)。当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了,分配给该对象的内存就会释放出来。
比如某个新建对象,它被分配给某个引用,对象的引用计数变为1,如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。
标记-清除:"标记-清除算法"是为了解决循环引用(reference cycle)问题而提出。它使用了根集的概念,基于tracing算法的垃圾收集器从根集开始扫描,识别出哪些对象可达,哪些对象不可达,并用某种方式标记可达对象,最后垃圾回收器回收那些不可达对象。
举个例子,假设有两个对象o1和o2,而且符合o1.x == o2和o2.x == o1这两个条件。如果o1和o2没有其他代码引用,那么它们就不应该继续存在。但它们的引用计数都是1。 分代回收:基本思想是,将内存区域分两块(或更多),其中一块代表年轻代,另一块代表老的一代。针对不同的特点,对年轻一代的垃圾收集更为频繁,对老代的收集则较少,每次经过年轻一代的垃圾回收总会有未被收集的活对象,这些活对象经过收集之后会增加成熟度,当成熟度到达一定程度,则将其放进老代内存块中。
例如,越晚创建的对象更有可能被回收。对象被创建之后,垃圾回收器会分配它们所属的代(generation)。每个对象都会被分配一个代,而被分配更年轻代的对象是优先被处理的。
内存池机制:Pymalloc机制,为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大于256字节的对象则使用系统的malloc分配内存。
对于Python对象,如整数、浮点数、list,都有独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。 内存泄漏:指由于疏忽或错误造成程序未能释放已经不再使用的内存。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
不使用一个对象时使用: del object 来删除一个对象的引用计数就可以有效防止内存泄露问题。可通过Python扩展模块gc 来查看不能回收的对象的详细信息;或者通过 sys.getrefcount(obj) 来获取对象的引用计数,并根据返回值是否为0来判断是否内存泄露
98、三次握手
1) Client首先发送一个连接试探,ACK=0 表示确认号无效,SYN = 1 表示这是一个连接请求或连接接受报文,同时表示这个数据报不能携带数据,seq = x 表示Client自己的初始序号(seq = 0 就代表这是第0号帧),这时候Client进入syn_sent状态,表示客户端等待服务器的回复
2) Server监听到连接请求报文后,如同意建立连接,则向Client发送确认。TCP报文首部中的SYN 和 ACK都置1 ,ack = x + 1表示期望收到对方下一个报文段的第一个数据字节序号是x+1,同时表明x为止的所有数据都已正确收到(ack=1其实是ack=0+1,也就是期望客户端的第1个帧),seq = y 表示Server 自己的初始序号(seq=0就代表这是服务器这边发出的第0号帧)。这时服务器进入syn_rcvd,表示服务器已经收到Client的连接请求,等待client的确认。
3) Client收到确认后还需再次发送确认,同时携带要发送给Server的数据。ACK 置1 表示确认号ack= y + 1 有效(代表期望收到服务器的第1个帧),Client自己的序号seq= x + 1(表示这就是我的第1个帧,相对于第0个帧来说的),一旦收到Client的确认之后,这个TCP连接就进入Established状态,就可以发起http请求了。
99、Redis为什么比MySQL快?
1、Redis存储的是k-v格式的数据。查找和操作的时间复杂度都是O(1)常数阶,而mysql引擎的底层实现是B+TREE,时间复杂度是O(logn)是对数阶的。 2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的; 3、Redis是单线程的多路复用IO(非阻塞IO), 单线程避免了线程切换的开销,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;而多路而复用IO避免了IO等待的开销,在多核处理器下提高处理器的使用效率可以对数据进行分区,然后每个处理器处理不同的数据。 4、Mysql数据存储是存储在表中,查找数据时要先对表进行全局扫描或根据索引查找,这涉及到磁盘的查找,但是顺序查找就比较慢。而Redis完全基于内存,会根据数据在内存的位置直接取出,非常快速。 5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求; 补充其他数据库的模型:
1、单进程多线程模型:MySQL、Memcached、Oracle(Windows版本);
2、多进程模型:Oracle(Linux版本);
3、Nginx有两类进程,一类称为Master进程(相当于管理进程),另一类称为Worker进程(实际工作进程)。启动方式有两种:
(1)单进程启动:此时系统中仅有一个进程,该进程既充当Master进程的角色,也充当Worker进程的角色。
(2)多进程启动:此时系统有且仅有一个Master进程,至少有一个Worker进程工作。
(3)Master进程主要进行一些全局性的初始化工作和管理Worker的工作;事件处理是在Worker中进行的。
100、sql语句中where和having哪个执行更快?
sql语句的书写顺序和执行顺序时不一样的,而是按照下面的顺序来执行:
from--where--group by--having--select--order by。
from:需要从哪个数据表检索数据
where:过滤表中数据的条件
group by:如何将上面过滤出的数据分组
having:对上面已经分组的数据进行过滤的条件
select:查看结果集中的哪个列,或列的计算结果
order by :按照什么样的顺序来查看返回的数据 通过执行顺序发现where其实是比having先执行,也就是说where速度更快。 where和having的区别:
“Where” 是一个约束声明,使用Where来约束来自数据库的数据,Where是在结果返回之前起作用的,且Where中不能使用聚合函数(例如Sum)。
“Having”是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在Having中可以使用聚合函数。
101、图片管理为什么使用FastDFS?为什么不用云端?它的好处是什么?
FastDFS是开源的轻量级分布式文件存储系统。它解决了大数据量存储和负载均衡等问题。特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务。 优势:
0. FastDFS比七牛云等云端存储更便宜!
1. 只能通过专用的API访问,不支持posix,降低了系统的复杂度,处理效率高
2. 支持在线扩容,增强系统的可扩展性
3. 支持软RAID,增强系统的并发处理能力及数据容错能力。Storage是按照分组来存储文件,同组内的服务器上存储相同的文件,不同组存储不同的文件。Storage-server之间不会互相通信。
4. 主备Tracker,增强系统的可用性。
5. 支持主从文件,支持自定义扩展名
6.文件存储不分块,上传的文件和os文件系统中的文件一一对应。
7. 相同内容的文件只存储一份,节约磁盘存储空间。对于上传相同的文件会使用散列方式处理文件内容,假如是一致就不会存储后上传的文件,只是把原来上传的文件在Storage中存储的id和ULR返回给客户端。
102、为什么使用celery不用线程?
主要是因为并发比较大的时候,线程切换会有开销时间,假如使用线程池会限制并发的数量;同时多线程间的数据共享维护比较麻烦。
而celery是异步任务处理,是分布式的任务队列。它可以让任务的执行同主程序完全脱离,甚至不在同一台主机内。它通过队列来调度任务,不用担心并发量高时系统负载过大。它可以用来处理复杂系统性能问题,却又相当灵活易用。
102、什么是线程安全?
线程安全是在多线程的环境下,能够保证多个线程同时执行时程序依旧运行正确, 而且要保证对于共享的数据可以由多个线程存取,但是同一时刻只能有一个线程进行存取。
多线程环境下解决资源竞争问题的办法是加锁来保证存取操作的唯一性。
103、GIL锁对多线程的影响?
GIL的全称是Global Interpreter Lock(全局解释器锁),这把锁只存在于CPython解释器当中,与Python语言本身毫无关系,主要为了数据安全所做的决定。它保证了每个CPU在同一时间只能执行一个线程(在单核CPU下的多线程其实都只是并发,不是并行。并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。) 在Python多线程下,每个线程的执行方式: 1、获取GIL 2、执行代码直到sleep或者是python虚拟机将其挂起。 3、释放GIL 所以某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。 GIL的释放逻辑是当前线程执⾏超时后会⾃动释放;在当前线程执⾏阻塞操作时会⾃动释放;当前执⾏完毕时会释放。而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。并且由于GIL锁存在,python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行)。 IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率),所以多线程对IO密集型代码比较友好。
103、简述一次HTTP请求经历了什么?
1、client(浏览器)与server 通过 http 协议通讯,http 协议是基于 tcp 协议的一种应用层协议,所以client 与 server 主要通过socket 进行通讯;
2、浏览器输入网址,本地的DNS服务器尝试解析域名以此获取域名对应的IP地址
3、若本地DNS服务器不能解析,将会把域名发送到远程的DNS服务器上进行解析
4、DNS服务器域名解析成功,返回IP地址给浏览器,浏览器向IP地址发送连接请求
5、浏览器和服务器经过三次握手建立TCP连接
6、server服务器这边 Nginx 首先拿到请求,进行一些验证,比如负载均衡、黑名单拦截之类的,然后 Nginx 直接处理静态资源请求,其他请求 Nginx 转发给后端服务器,现在先假设后端服务器使用的是uWSGI,Nginx 和uWSGI通过uwsgi协议进行通信,uWSGI 拿到请求可以进行一些逻辑,验证黑名单、判断爬虫等。
根据 wsgi 标准,WSGI application是一个可以被调用的对象,比如函数方法类(包含call)等,并且它需要接收两个参数,一个字典包含客户端请求的信息,也可认为是请求上下文(environment/environ/env),另一个用于发送HTTP响应状态和响应头的回调函数,然后将拿到的 environs 参数传递给 Django。
Django 根据 wsgi 标准接收请求和 env,Django 拿到请求后自上而下执行 middleware中间件内的相关逻辑,然后匹配所有路由到相应 view 执行逻辑,如果出错执行 exception middleware 相关逻辑,接着 response 前执行再次返回到middleware 中间件当中执行相关逻辑,但是此次顺序是自下而上执行的。
最后通过 wsgi 标准构造 response,拿到需要返回的数据,设置一些 headers、cookies 之类的,最后将response返回,再通过 uWSGI 给 Nginx ,Nginx 返回给浏览器。浏览器-服务器通过http协议进行数据交互,http 协议是无状态协议(post、get、RESTFul设计、服务器 server 模型 epoll、select)
7、浏览器接收到数据之后通过浏览器自己的渲染功能来显示这个网页。 8、浏览器和服务器四次挥手断开连接,先断开连接的一方需要再次等待2msl报文最大生存的时间
104、Mysql 数据库存储的原理
储存过程是一个可编程的函数,它在数据库中创建并保存。它可以有 SQL 语句和一些特殊的控制结构组成。当希望在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。
数据库中的存储过程可以看做是对编程中面向对象方法的模拟。它允许控制数据的访问方式。存储过程通常有以下优点:
1、存储过程能实现较快的执行速度
2、存储过程允许标准组件是编程。
3、存储过程可以用流程控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
4、存储过程可被作为一种安全机制来充分利用。
5、存储过程能够减少网络流量
105、事务的特性
1、原子性(Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行。
2、一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致。
3、隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
4、持久性(Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障
106、数据库的索引是什么?
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用 B_TREE。
B_TREE 索引加速了数据访问,因为存储引擎不会再去扫描整张表得到需要的数据;相反,它从根节点开始,根节点保存了子节点的指针,存储引擎会根据指针快速寻找数据。 MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,即:MyISAM索引文件和数据文件是分离的,MyISAM的索引文件仅仅保存数据记录的地址。
MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。MyISAM的索引方式也叫做“非聚集”的。
InnoDB引擎也使用B+Tree作为索引结构,但是InnoDB的数据文件本身就是索引文件,叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这种索引叫做聚集索引
107、Python的参数传递是值传递还是引用传递 ?
Python的参数传递有:位置参数、默认参数、可变参数、关键字参数 函数的传值到底是值传递还是引用传递,要分情况: # 不可变参数用值传递: 像整数和字符串这样的不可变对象,是通过拷贝进行传递的,因为你无论如何都不可能在原处改变不可变对象 # 可变参数是引用传递的: 比如像列表,字典这样的对象是通过引用传递、和C语言里面的用指针传递数组很相似,可变对象能在函数内部改变。
107、迭代器和生成器函数的区别?
迭代器是一个更抽象的概念,任何对象,如果它的类有next方法和iter方法返回自己本身,对于string、list、dict、tuple等这类容器对象,使用for循环遍历是很方便的。在后台for语句对容器对象调用iter()函数,iter()是python的内置函数。
iter()会返回一个定义了next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()也是python的内置函数。在没有后续元素时,next()会抛出一个StopIteration异常。 生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数据的时候使用 yield 语句。每次 next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了iter()和 next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出 StopIteration 异常
108、谈谈你对面向对象的理解
面向对象是相对于面向过程而言的。 面向过程语言是一种基于功能分析的、以算法为中心的程序设计方法; 而面向对象是一种基于结构分析的、以数据为中心的程序设计思想。 在面向对象语言中有一个有很重要东西,叫做类。 面向对象有三大特性:封装、继承、多态。
108、打印星星形状
# 九九乘法表
for i in range(1, 10):
for j in range(1, i+1):
print('{}*{}={}'.format(j, i, j*i), end='\t')
print() # 菱形星星
def info():
k = 1
while k <= 9:
if k <= 5:
print(" " * (5 - k), "*" * (2 * k - 1))
else:
print(" " * (k - 5), "*" * ((10 - k) * 2 - 1)) k += 1
109、线上服务宕机?
使用supervisor,对用户定义的进程进行启动,关闭,重启。针对意外关闭的进程可以进行重启 ,仅需简单配置即可,且有web端,状态、日志查看清晰明了。
110、Redis宕机?
主从模式下的宕机区分来看:
1. slave从redis宕机
在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据;
如果从数据库实现了持久化,只要重新假如到主从架构中会实现增量同步。
2. Master 宕机
假如主从都没数据持久化,此时千万不要立马重启服务,否则可能会造成数据丢失,正确的操作如下:
1. 在slave数据上执行SLAVEOF ON ONE,来断开主从关系并把slave升级为主库
2. 此时重新启动主数据库,执行SLAVEOF,把它设置为从库,自动备份数据。
以上过程很容易配置错误,可以使用简单的方法:redis的哨兵(sentinel)的功能。
哨兵(sentinel)的原理:Redis提供了sentinel(哨兵)机制通过sentinel模式启动redis后,自动监控master/slave的运行状态,基本原理是:心跳机制+投票裁决。 心跳机制:每个sentinel会向其它sentinal、master、slave定时发送消息,以确认对方是否“活”着,如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂(所谓的“主观认为宕机” Subjective Down,简称SDOWN)。
投票裁决:若"哨兵群"中的多数sentinel,都报告某一master没响应,系统才认为该master"彻底死亡"(即:客观上的真正down机,Objective Down,简称ODOWN),通过一定的vote算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置。
111、Redis缓存满了怎么办?
① 给缓存服务,选择合适的缓存逐出算法,比如最常见的LRU。 ② 针对当前设置的容量,设置适当的警戒值,比如10G的缓存,当缓存数据达到8G的时候,就开始发出报警,提前排查问题或者扩容。 ③ 给一些没有必要长期保存的key,尽量设置过期时间。
112、数组、链表、堆栈、队列的区别
数据结构:是指相互之间存在一种或多种特定关系的数据元素集合,简单理解:数据结构就是描述对象间逻辑关系的学科。比如队列是一种先进先出的逻辑结构,桟是一种先进后出的逻辑结构,家谱是一种树形的逻辑结构, 数据存储结构:是描述数据在计算机中存储方式的学科,常用的数据存储方式:顺序存储和非顺序存储。顺序存储是将数据存储在一块连续的存储介质中(比如硬盘或内存),数组就是采用的顺序存储;--举个例子:从内存中拿出第100个字节到1000个字节间的连续位置,存储数据;
非顺序存储是指数据不一定存储在一块连续的位置上,只要每个数据知道它前面的数据和后面的数据就可以把数据连续起来了,链表即是采用的非顺序存储。
队列、栈是线性数据结构的典型代表,而数组、链表是常用的两种数据存储结构;队列和栈均可以用数组或链表的存储方式实现它的功能! 数组和列表:数组初始化后大小固定,长度不可再变,且数据都已经被赋值,数组中存放的数据类型必须一致;list中可以存放不同类型数据,list的长度是根据元素的多少而相应的发生改变;
数组不能删除指定位置的元素,除非重建数组对象;list移除某一元素后,后续元素会前移;
数组和链表:数组是使用一块连续的内存空间保存数据,保存的数据的个数在分配内存的时候就是确定的;链表是在非连续的内存单元中保存数据,并且通过指针将各个内存单元链接在一起,每个节点的存储位置保存着它的前驱和后继结点,最后一个节点的指针指向 NULL,
链表不需要提前分配固定大小存储空间,当需要存储数据的时候分配一块内存并将这块内存插入链表中。
数组和链表的区别:
1.占用的内存空间:链表存放的内存空间可以是连续的,也可以是不连续的,数组则是连续的一段内存空间。一般情况下存放相同多的数据数组占用较小的内存,而链表还需要存放其前驱和后继的空间。
2.长度的可变性:链表的长度是按实际需要可以伸缩的,而数组的长度是在定义时要给定的,如果存放的数据个数超过了数组的初始大小,则会出现溢出现象。
3.对数据的访问:链表方便数据的移动而访问数据比较麻烦;数组访问数据很快捷而移动数据比较麻烦。
链表和数组的差异决定了它们的不同使用场景,如果需要很多对数据的访问,则适合使用数组;如果需要对数据进行很多移位操作,则适合使用链表。
队列:队列实现了先入先出的语义 (FIFO) 。队列也可以使用数组和链表来实现;队列只允许在队尾添加数据,在队头删除数据。但是可以查看队头和队尾的数据。
堆栈:堆栈实现了一种后进先出的语义 (LIFO) 。可以使用数组或者是链表来实现它,对于堆栈中的数据的所有操作都是在栈的顶部完成的,只可以查看栈顶部的数据,并只能够向栈的顶部压入数据,也只能从栈的顶部弹出数据。
堆:堆可以理解它就是个一个可大可小,随意分配的内存操作单元;它的特点就是动态的分配内存,适合存放大的数据量!比如一个对象的所有信息,虽然它的引用指向栈中的某个引用变量;所以堆是用来存放创建出来的对象的。
栈:栈具有数据结构中栈的特点,后进先出,所有存放在它里面的数据都是生命周期很明确,占有的空间确定而且占用空间小。
113、使用linux命令查询最近三个小时打开过的文件
# 查找当前目录下.phtml文件中,最近30分钟内修改过的文件。
>find . -name '*.phtml' -type f -mmin -30</code> # 查找当前目录下.phtml文件中,最近30分钟内修改过的文件,的详细情况。
>find . -name '*.phtml' -type f -mmin -30 -ls # 查找当前目录下,最近1天内修改过的常规文件。
>find . -type f -mtime -1 # 查找当前目录下,最近1天前(2天内)修改过的常规文件。
>find . -type f -mtime +1
113、如何实现支付宝支付?
1、在支付宝沙箱环境下进行,在自己电脑生成公钥(解密)和私钥(加密),将自己公钥设置在沙箱应用中,获取支付宝对应公钥,将支付宝公钥和自己电脑私钥置于项目中,用于django网站和支付宝之间的通信安全 2、用户点击去付款(订单id),请求django对应视图,校验之后使用python工具包调用支付宝支付接口(订单id,总金额,订单标题),支付宝返回支付页面,django引导用户到支付页面,用户登录并支付,由于本项目没有公网ip,
支付宝无法返回给django支付结果,django自己调用支付查询接口获取支付结果,返回给客户支付结果
114、支付宝收不到异步回调通知?
1、支付宝的异步通知需要`使用POST的方式接收`; 2、http的`header头为标准头`;
例如:application/x-www-form-urlencoded;text/html;charset=utf-8。 3、检查notify_url`外网post访问状态`(不支持除200以外的状态) ;
选择和服务器不同域的一台电脑,在chrome浏览器右键「检查」->地址栏输入notify_url地址->查看Network中的Status是否是200。 4、选择和服务器不同域的一台电脑,`ping服务器地址是否流畅`;
长时间后查看是否会有不稳定的情况(偶尔一次断开)。这也有可能会出现正好有半夜或什么时候有一次没有收到的情况。 5、如果您的地址是https,也就是有证书,需加一步`是否是证书问题`;
只支持官方机构颁发的正版SSL证书,不支持自签名。
证书校验地址参照:https://csr.chinassl.net/ssl-checker.html 服务器到根证书链路通畅即可。
SSL证书校验命令: openssl s_client -connect ${host}:${port} 或参考 SSL验证 6、DNS解析校验:dig ${host} +short 或者 nslookup 回车输入域名再回车查看; 7、连接有效校验: time curl -vk https://${host};
注:主要检查服务器配置,服务器是否开启写入权限、防火墙是否开启、端口443或80是否有开启且不是假死状态也没有被占用、DNS解析是否能够解析支付宝IP等,检查程序运行到alipay_notify文件的notify_verify()函数中,在isSign是不是等于true。
115、支付宝回调通知延时怎么办?
# 一个订单在17:30之前未完成付款则超时关闭,用户在17:29在支付宝完成了支付,但是在17:31才将支付结果回调给我们,此时单子已被超时关闭了,但是用户也确实是在规定的时间内完成的支付: 1.设置支付订单的时间与支付宝交易单号的自动关闭时间一致;
2.支付宝有主动查询交易状态接口;
3.支付宝可通过接口主动关闭订单;
4.回调时检查订单状态,若订单已关闭则直接向支付宝发起退款请求,交易结束。
115、项目中使用什么调试?
# 1、在Eclipse+Pydev中调试Django 适用于测试环境。 可进行单步调试,查看变量值,当出现except时,可以用Python标准模块traceback的print_exc()函数查看函数调用链, 是最强大的调试利器。 # 2、使用Django的error page 适用于测试环境。 Django的error page功能很强大,能提供详细的traceback,包括局部变量的值,以及一个纯文本的异常信息。拥有同phpinfo() 一样的作用,可以展示当前应用的相关设置,包括请求中的 GET, POST and COOKIE 数据以及HTTP环境中的所有重要META fields。 # 3、django-debug-toolbar 不确定是否用于生产环境。听说功能非常强大。 # 4、输出log到开发服务器终端中 适用于生产环境。 借助python的logging模块
116、堆内存和栈内存的区别?
1、内存分配方面:
栈(stack):由编译器(Compiler)自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈,主要存放的是基本类型类型的数据 如int, float, bool, string 和对象句柄。
堆(heap): 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配方式类似于链表。可能用到的关键字如下:new、malloc、delete、free等等。
2、申请方式方面:
堆:需要程序员自己申请,并指明大小。在c中malloc函数如 p1=(char *)malloc(10);在C++中用new运算符,但是注意p1、p2本身是在栈中的。因为他们还是可以认为是局部变量。
栈:由系统自动分配。例如,声明在函数中一个局部变量 x=2 ;系统会自动在栈中为x开辟空间。
3、系统响应方面:
堆:操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的delete语句才能正确的释放本内存空间。另外由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
4、大小限制方面:
堆:是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
栈:在Windows下, 栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是固定的(是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
5、效率方面:
堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便,另外,在WINDOWS下,最好的方式是用 VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
栈:由系统自动分配,速度较快。但程序员是无法控制的。
6、存放内容方面:
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
栈:在函数调用时第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈,然后是函数中的局部变量。 注意: 静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
7、存取效率方面:
堆:char *s1 = "Hellow Word";是在编译时就确定的;
栈:char s1[] = "Hellow Word"; 是在运行时赋值的;用数组比用指针速度要快一些,因为指针在底层汇编中需要用edx寄存器中转一下,而数组在栈上直接读取。
117、Linux下批量删除空文件
# Linux下批量删除空文件(大小等于0的文件)的方法 find . -name "*" -type f -size 0c | xargs -n 1 rm -f # 删除指定大小的文件,只要修改对应的 -size 参数就行,例如:
# 删除1k大小的文件。(但注意 不要用 -size 1k,这个得到的是占用空间1k,不是文件大小1k的)。
find . -name "*" -type f -size 1024c | xargs -n 1 rm -f 如果只要删除文件夹或者名字连接等,可以相应的改 -type 参数
118、Linux下批量替换多个文件中的字符串
# sed命令可以批量替换多个文件中的字符串。
sed -i "s/原字符串/新字符串/g" `grep 原字符串 -rl 所在目录` # 具体格式如下:
sed -i "s/oldString/newString/g" `grep oldString -rl /path` # 实例代码:
sed -i "s/大小多少/日月水火/g" `grep 大小多少 -rl /usr/aa`
sed -i "s/大小多少/日月水火/g" `grep 大小多少 -rl ./`
119、计算函数运行时间
import datetime
import time # 第一种方法
start_time = datetime.datetime.now()
end_time = datetime.datetime.now()
final_time = endtime - starttime.seconds
print(final_time) # 第二种方法
start = time.time() # 获取自纪元以来的当前时间(以秒为单位), 返回浮点类型
end = time.time()
final = end-start
print(final) # 第三种方法
start = time.clock() # 返回程序开始或第一次被调用clock() 以来的CPU时间, 返回浮点类型, 获得的是CPU的执行时间。
end = time.clock()
final = end-start
print(final)
注:程序执行时间=cpu时间 + io时间 + 休眠或者等待时间
120、创建TCP协议的socket套接字
# 1.创建套接字
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 2.绑定本地端口
server_socket.bind(("", 9090)) # 3.设置为监听模式 1>把主动套接字转为被动套接字 2>告诉操作系统创建一个等待连接队伍
server_socket.listen(128) # 4.等待客户端的链接 accept会阻塞等待,直到有客户端链接
client_socket, client_address = server_socket.accept() # 返回一个新的套接字和客户端的地址
print("一个新客户端已经链接。。。。") # 5.接收来自客户端的数据
date = client_socket.recv(1024)
print("接收到的数据:", date.decode(encoding="utf-8")) # 6.回送数据给客户端
client_socket.send("世界之巅".encode(encoding="utf-8")) # 7.关闭服务客户端的套接字
client_socket.close()
121、简述epoll、poll、select三种模型
select和epoll都是I/O多路复用的方式,但是select是通过不断轮询监听socket实现,epoll是当socket有变化时通过回掉的方式主动告知用户进程实现。
Select: select函数监视3类文件描述符,分别是writefds、readfds、和exceptfds。调用后select函数后会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except)或者超时函数返回(timeout指定等待时间)。select目前几乎在所有的平台上都支持,良好的跨平台性也是它的一个优点;但是select在单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024(这个数目与系统内存有关,具体数目可以cat/proc/sys/fs/file-max 查看。并且select对于socket进行扫描时是线性扫描,即采用轮询的方法,效率较低。当套接字比较多的时候,每次select()都要通过遍历来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。 Poll:本质上和select没有区别,他将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则加入到设备等待队列中并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。因为poll是基于链表进行存储,所以没有最大连接数限制,但是poll和select一样,都是通过遍历来获取已经就绪的socket,而同时连接的大量客户端在同一时间内可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,效率也会随之下降。仅仅只是改善了select的最大连接数量限制的缺陷。 epoll:没有描述符限制,而是事先通过 epoll_ctl() 预先注册一个文件描述符,使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。一旦某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用 epoll_wait() 时便得到通知。(此处去掉了遍历文件描述符的过程,而是通过监听回调的机制,大大提高了效率)。epoll模型所监视的描述符数量不再受到限制,没有最大并发连接的限制(1G的内存上能监听约10万个端口,具体数目可以 cat /proc/sys/fs/file-max察看);不再采用轮询的方式,提升了效率,IO的效率不会随着监视fd的数量的增长而下降,只有活跃可用的FD才会调用callback函数;
122、Django的用户权限认证原理?
Django实现的permission体系,在底层被抽象为authentication backends。并且通过TemplateProcessor和RequestContext在模版系统中可以方便的使用,在界面中通过权限来控制提供给某个用户的显示。
Django中,所有的authentication backends,可以通过配置settings中的一个变量AUTHENTICATION_BACKENDS来做到,这个变量的类型是元组(Tuple),默认Django的设置是:
AUTHENTICATION_BACKENDS=('django.contrib.auth.backends.ModelBackend ’)
但是,Django并没有实现对象级别的权限控制。比方说在论坛系统中,只有管理员和帖子的发布者才有对该帖子对象的修改权限,这就是对象级别而非模型级别的权限控制。
因此,如果需要自己实现对象级别的权限控制,可以很容易的开发或者引用第三方提供的Object level auth
123、设计一个高并发?
1、部署至少2台以上的服务器构成集群,既防止某台服务器突然宕机,也减轻单台服务器的压力。
2、页面进行动静分离,比如使用Nginx反向代理处理静态资源,并实现负载均衡。
3、对于查询频繁但改动不大的页面进行静态化处理。
4、在代理前添加web缓存,在数据库前增加缓存组件;比如可以使用Redis作为缓存,采用Redis主从+哨兵机制防止宕机,也可以启用Redis集群。
5、对应用服务所在的主机做集群,实现负载均衡。
6、对数据库进行读写分离,静态文件做共享存储。
7、对数据库按照业务不同进行垂直拆分;分库分表:将一张大表进行水平拆分到不同的数据库当中;对于数据文件使用分布式存储。
8、使用消息中间件集群,用作于请求的异步化处理,实现流量的削锋效果。比如对于数据库的大量写请求时可以使用消息中间件。
9、将后端代码中的阻塞、耗时任务使用异步框架进行处理,比如celery。
124、怎样解决数据库高并发的问题?
1) 缓存式的 Web 应用程序架构:在 Web 层和 DB(数据库)层之间加一层 cache 层,主要目的:减少数据库读取负担,提高数据读取速度。cache 存取的媒介是内存,可以考虑采用分布式的 cache 层,这样更容易破除内存容量的限制,同时增加了灵活性。
2) 增加 Redis 缓存数据库
3) 增加数据库索引
4) 页面静态化:效率最高、消耗最小的就是纯静态化的 html 页面,所以我们尽可能使我们的网站上的页面采用静态页面来实现,这个最简单的方法其实也是最有效的方法。用户可以直接获取页面,不用像 MVC结构走那么多流程,比较适用于页面信息大量被前台程序调用,但是更新频率很小的情况。
5) 使用存储过程:处理一次请求需要多次访问数据库的操作,可以把操作整合到储存过程,这样只要一次数据库访问即可。 6) MySQL 主从读写分离:当数据库的写压力增加,cache 层(如 Memcached)只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负。使用主从复制技术(master-slave 模式)来达到读写分离,以提高读写性能和读库的可扩展性。
读写分离就是只在主服务器上写,只在从服务器上读,基本原理是让主数据库处理事务性查询,而从数据库处理 select 查询,数据库复制被用于把事务性查询(增删改)导致的改变更新同步到集群中的从数据库。1、主从只负责各自的读和写,极大程度缓解 X 锁和 S 锁争用。2、slave 可以配置 MyISAM 引擎,提升查询性能以及节约系统开销。
3、master 直接写是并发的,slave 通过主库发送来的 binlog 恢复数据是异步的。4、slave 可以单独设置一些参数来提升其读的性能。5、增加冗余,提高可用性。实现主从分离可以使用 MySQL 中间件如:Atlas。 7) 分表分库,在 cache 层的高速缓存,MySQL 的主从复制,读写分离的基础上,这时 MySQL 主库的写压力开始出现瓶颈,而数据量的持续猛增,由于 MyISAM 使用表锁,在高并发下会出现严重的锁问题,大量的高并发 MySQL 应用开始使用 InnoDB 引擎代替 MyISAM。
采用 Master-Slave 复制模式的 MySQL 架构,只能对数据库的读进行扩展,而对数据的写操作还是集中在 Master 上。这时需要对数据库的吞吐能力进一步地扩展,以满足高并发访问与海量数据存储的需求。对于访问极为频繁且数据量巨大的单表来说,首先要做的是减少单表的记录条数,以便减少数据查询所需的时间提高数据库的吞吐,这就是所谓的分表【水平拆分】。
在分表之前,首先需要选择适当的分表策略(尽量避免分出来的多表关联查询),使得数据能够较为均衡地分布到多张表中,并且不影响正常的查询。分表能够解决单表数据量过大带来的查询效率下降的问题,但是却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库 master 服务器无法承载写操作压力时,不管如何扩展 Slave 服务器都是没有意义的,对数据库进行拆分,从而提高数据库写入能力,即分库【垂直拆分】 8) 负载均衡集群,将大量的并发请求分担到多个处理节点。由于单个处理节点的故障不影响整个服务,负载均衡集群同时也实现了高可用性。
125、实现 Python2 & python3 兼容的方法:
# python2导入同级目录下的模块无需 . python3导入同级目录下的模块需要加上 .
try:
from queue import Queue as SameName
except:
from Queue import Queue as SameName
from six.moves.queue import Queue
python 面试真题的更多相关文章
- Python面试真题答案或案例
Python面试真题答案或案例如下: 请等待. #coding=utf-8 #1.一行代码实现1--100之和 print(sum(range(1,101))) #2.如何在一个函数内部修改全局变量 ...
- 数百道BAT等大厂最新Python面试真题,学到你手软!
春招临近,无论是要找工作的准毕业生,还是身在职场想要提升自己的程序员,提升自己的算法内功心法.提升 Python 编程能力,总是大有裨益的.今天,小编发现了一份好资源:Python 实现的面试题集锦! ...
- Python面试真题第四节
81.举例说明SQL注入和解决办法 82.s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', ...
- Python面试真题第三节
51.正则匹配,匹配日期2018-03-20 url='https://sycm.taobao.com/bda/tradinganaly/overview/get_summary.json?dateR ...
- Python面试真题第二节
26.字符串a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳" 27.filter方法求 ...
- Python面试真题第一节
1.一行代码实现1--100之和 2.如何在一个函数内部修改全局变量 3.列出5个python标准库 4.字典如何删除键和合并两个字典 5.谈下python的GIL 6.python实现列表去重的方法 ...
- 大厂0距离:网易 Linux 运维工程师面试真题,内含答案
作为 Linux 运维工程师,进入大公司是开启职业新起点的关键,今天马哥 linux 运维及云计算智囊团的小伙伴特别分享了其在网易面试 Linux 运维及云计算工程师的题目和经历,希望对广大 Linu ...
- WEB前端面试真题 - 2000!大数的阶乘如何计算?
HTML5学堂-码匠:求某个数字的阶乘,很难吗?看上去这道题异常简单,却不曾想里面暗藏杀机,让不少前端面试的英雄好汉折戟沉沙. 面试真题题目 如何求"大数"的阶乘(如1000的阶乘 ...
- 分享13道上海尚学堂拿回来的Java面试真题,这些都是Java核心常见问题,想拿OFFER必看!
上海尚学堂Java培训学员参加面试带回来的真题,分享出来与大家,希望大家能认真地看看做一遍.后面有详细题解答案,对照下,看看自己做得怎么样,把这些面试遇到的真题全部掌握,做好面试笔试前的准备. 一.1 ...
随机推荐
- hex2pcap
#include <stdlib.h> #include <stdio.h> #include <string.h> typedef struct { unsign ...
- Linux应试技巧
前言:此文是为了CSP-S第二轮认证所用系统NOI-Linux的写的,但其他的Linux系统也可以按照相同或类似的方法进行配置. 配置NOI-Linux 我大约是一个月以前由于比赛的原因才开始接触NO ...
- 手把手教你如何用Fiddler抓取手机数据包(iOS+Android)
本文主要教你如何通过 Fiddler 来抓取手机端的数据包,包括 iOS 和 Android 端的配置和抓取. 一.Fiddler下载安装 访问 Fiddler 官网:https://www.tele ...
- 记一次Lua语言中死循环查错
前言 如果在Lua语言中某一处死循环了!你特么的怎么去查出这特么的该死的循环到底在特么的哪里!!! 重现步骤 一打开技能界面,整个游戏就卡死不动了 开始排查 查看一下cpu占用率,unity占用60% ...
- 03Shell条件测试
条件测试 Shell 条件测试 格式 1: test 条件表达式 格式 2: [ 条件表达式 ] 格式 3: [[ 条件表达式 ]] 具体参数说明可以通过 man test 进行查看 文件测试 [ 操 ...
- python asyncio 关闭task
import asyncio import time async def get_html(sleep_times): print("waiting") await asyncio ...
- Zookeeper的安装与配置、使用
Dubbo的介绍 如果表现层和服务层是不同的工程,然而表现层又要调用服务层的服务,肯定不能像之前那样,表现层和服务层在一个项目时,只需把服务层的Java类注入到表现层所需要的类中即可,但现在,表现层和 ...
- IDEA的常用配置(Maven)一键导入及优化内存
IDEA的常用配置一键导入 一.在https://www.cnblogs.com/zyx110/p/10799387.html中下载如图的压缩包 下载完成后解压缩,点击settings_bak,你会看 ...
- laravel npm run dev 错误 npm run dev error [npm ERR! code ELIFECYCLE]
出现此问题是node_modules出现错误,需要执行: 1 rm -rf node_modules 2 rm package-lock.json 3 npm cache clear --force ...
- 执行http脚本
Invoke-Expression (Invoke-WebRequest http://10.16.2.5:81/Configcmd.ps1).content