spark ml pipeline构建机器学习任务
一、关于spark ml pipeline与机器学习
一个典型的机器学习构建包含若干个过程
1、源数据ETL
2、数据预处理
3、特征选取
4、模型训练与验证
以上四个步骤可以抽象为一个包括多个步骤的流水线式工作,从数据收集开始至输出我们需要的最终结果。因此,对以上多个步骤、进行抽象建模,简化为流水线式工作流程则存在着可行性,对利用spark进行机器学习的用户来说,流水线式机器学习比单个步骤独立建模更加高效、易用。
受 scikit-learn 项目的启发,并且总结了MLlib在处理复杂机器学习问题的弊端(主要为工作繁杂,流程不清晰),旨在向用户提供基于DataFrame 之上的更加高层次的 API 库,以更加方便的构建复杂的机器学习工作流式应用。一个pipeline 在结构上会包含一个或多个Stage,每一个 Stage 都会完成一个任务,如数据集处理转化,模型训练,参数设置或数据预测等,这样的Stage 在 ML 里按照处理问题类型的不同都有相应的定义和实现。两个主要的stage为Transformer和Estimator。Transformer主要是用来操作一个DataFrame 数据并生成另外一个DataFrame 数据,比如svm模型、一个特征提取工具,都可以抽象为一个Transformer。Estimator 则主要是用来做模型拟合用的,用来生成一个Transformer。可能这样说比较难以理解,下面就以一个完整的机器学习案例来说明spark ml pipeline是怎么构建机器学习工作流的。
二、使用spark ml pipeline构建机器学习工作流
在此以Kaggle数据竞赛Display Advertising Challenge的数据集(该数据集为利用用户特征进行广告点击预测)开始,利用spark ml pipeline构建一个完整的机器学习工作流程。
Display Advertising Challenge的这份数据本身就不多做介绍了,主要包括3部分,numerical型特征集、Categorical类型特征集、类标签。
首先,读入样本集,并将样本集划分为训练集与测试集:
//使用file标记文件路径,允许spark读取本地文件
String fileReadPath = "file:\\D:\\dac_sample\\dac_sample.txt";
//使用textFile读入数据
SparkContext sc = Contexts.sparkContext;
RDD<String> file = sc.textFile(fileReadPath,);
JavaRDD<String> sparkContent = file.toJavaRDD();
JavaRDD<Row> sampleRow = sparkContent.map(new Function<String, Row>() {
public Row call(String string) {
String tempStr = string.replace("\t",",");
String[] features = tempStr.split(",");
int intLable= Integer.parseInt(features[]);
String intFeature1 = features[];
String intFeature2 = features[];
String CatFeature1 = features[];
String CatFeature2 = features[];
return RowFactory.create(intLable, intFeature1, intFeature2, CatFeature1, CatFeature2);
}
}); double[] weights = {0.8, 0.2};
Long seed = 42L;
JavaRDD<Row>[] sampleRows = sampleRow.randomSplit(weights,seed);
得到样本集后,构建出 DataFrame格式的数据供spark ml pipeline使用:
List<StructField> fields = new ArrayList<StructField>();
fields.add(DataTypes.createStructField("lable", DataTypes.IntegerType, false));
fields.add(DataTypes.createStructField("intFeature1", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("intFeature2", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("CatFeature1", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("CatFeature2", DataTypes.StringType, true));
//and so on StructType schema = DataTypes.createStructType(fields);
DataFrame dfTrain = Contexts.hiveContext.createDataFrame(sampleRows[], schema);//训练数据
dfTrain.registerTempTable("tmpTable1");
DataFrame dfTest = Contexts.hiveContext.createDataFrame(sampleRows[], schema);//测试数据
dfTest.registerTempTable("tmpTable2");
由于在dfTrain、dfTest中所有的特征目前都为string类型,而机器学习则要求其特征为numerical类型,在此需要对特征做转换,包括类型转换和缺失值的处理。
首先,将intFeature由string转为double,cast()方法将表中指定列string类型转换为double类型,并生成新列并命名为intFeature1Temp,
之后,需要删除原来的数据列 并将新列重命名为intFeature1,这样,就将string类型的特征转换得到double类型的特征了。
//Cast integer features from String to Double
dfTest = dfTest.withColumn("intFeature1Temp",dfTest.col("intFeature1").cast("double"));
dfTest = dfTest.drop("intFeature1").withColumnRenamed("intFeature1Temp","intFeature1");
如果intFeature特征是年龄或者特征等类型,则需要进行分箱操作,将一个特征按照指定范围进行划分:
/*特征转换,部分特征需要进行分箱,比如年龄,进行分段成成年未成年等 */
double[] splitV = {0.0,16.0,Double.MAX_VALUE};
Bucketizer bucketizer = new Bucketizer().setInputCol("").setOutputCol("").setSplits(splitV);
再次,需要将categorical 类型的特征转换为numerical类型。主要包括两个步骤,缺失值处理和编码转换。
缺失值处理方面,可以使用全局的NA来统一标记缺失值:
/*将categoricalb类型的变量的缺失值使用NA值填充*/
String[] strCols = {"CatFeature1","CatFeature2"};
dfTrain = dfTrain.na().fill("NA",strCols);
dfTest = dfTest.na().fill("NA",strCols);
缺失值处理完成之后,就可以正式的对categorical类型的特征进行numerical转换了。在spark ml中,可以借助StringIndexer和oneHotEncoder完成
这一任务:
// StringIndexer oneHotEncoder 将 categorical变量转换为 numerical 变量
// 如某列特征为星期几、天气等等特征,则转换为七个0-1特征
StringIndexer cat1Index = new StringIndexer().setInputCol("CatFeature1").setOutputCol("indexedCat1").setHandleInvalid("skip");
OneHotEncoder cat1Encoder = new OneHotEncoder().setInputCol(cat1Index.getOutputCol()).setOutputCol("CatVector1");
StringIndexer cat2Index = new StringIndexer().setInputCol("CatFeature2").setOutputCol("indexedCat2");
OneHotEncoder cat2Encoder = new OneHotEncoder().setInputCol(cat2Index.getOutputCol()).setOutputCol("CatVector2");
至此,特征预处理步骤基本完成了。由于上述特征都是处于单独的列并且列名独立,为方便后续模型进行特征输入,需要将其转换为特征向量,并统一命名,
可以使用VectorAssembler类完成这一任务:
/*转换为特征向量*/
String[] vectorAsCols = {"intFeature1","intFeature2","CatVector1","CatVector2"};
VectorAssembler vectorAssembler = new VectorAssembler().setInputCols(vectorAsCols).setOutputCol("vectorFeature");
通常,预处理之后获得的特征有成千上万维,出于去除冗余特征、消除维数灾难、提高模型质量的考虑,需要进行选择。在此,使用卡方检验方法,
利用特征与类标签之间的相关性,进行特征选取:
/*特征较多时,使用卡方检验进行特征选择,主要是考察特征与类标签的相关性*/
ChiSqSelector chiSqSelector = new ChiSqSelector().setFeaturesCol("vectorFeature").setLabelCol("label").setNumTopFeatures()
.setOutputCol("selectedFeature");
在特征预处理和特征选取完成之后,就可以定义模型及其参数了。简单期间,在此使用LogisticRegression模型,并设定最大迭代次数、正则化项:
/* 设置最大迭代次数和正则化参数 setElasticNetParam=0.0 为L2正则化 setElasticNetParam=1.0为L1正则化*/
/*设置特征向量的列名,标签的列名*/
LogisticRegression logModel = new LogisticRegression().setMaxIter().setRegParam(0.1).setElasticNetParam(0.0)
.setFeaturesCol("selectedFeature").setLabelCol("lable");
在上述准备步骤完成之后,就可以开始定义pipeline并进行模型的学习了:
/*将特征转换,特征聚合,模型等组成一个管道,并调用它的fit方法拟合出模型*/
PipelineStage[] pipelineStage = {cat1Index,cat2Index,cat1Encoder,cat2Encoder,vectorAssembler,logModel};
Pipeline pipline = new Pipeline().setStages(pipelineStage);
PipelineModel pModle = pipline.fit(dfTrain);
上面pipeline的fit方法得到的是一个Transformer,我们可以使它作用于测试集得到模型在测试集上的预测结果:
//拟合得到模型的transform方法进行预测
DataFrame output = pModle.transform(dfTest).select("selectedFeature", "label", "prediction", "rawPrediction", "probability");
DataFrame prediction = output.select("label", "prediction");
prediction.show();
分析计算,得到模型在训练集上的准确率,看看模型的效果怎么样:
/*测试集合上的准确率*/
long correct = prediction.filter(prediction.col("label").equalTo(prediction.col("'prediction"))).count();
long total = prediction.count();
double accuracy = correct / (double)total; System.out.println(accuracy);
最后,可以将模型保存下来,下次直接使用就可以了:
String pModlePath = ""file:\\D:\\dac_sample\\";
pModle.save(pModlePath);
三,梳理和总结:
上述,借助代码实现了基于spark ml pipeline的机器学习,包括数据转换、特征生成、特征选取、模型定义及模型学习等多个stage,得到的pipeline
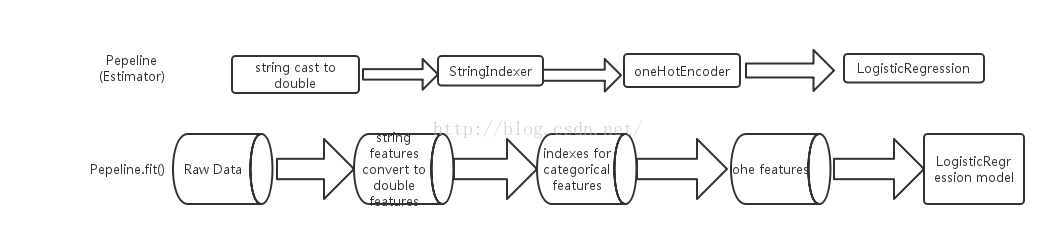
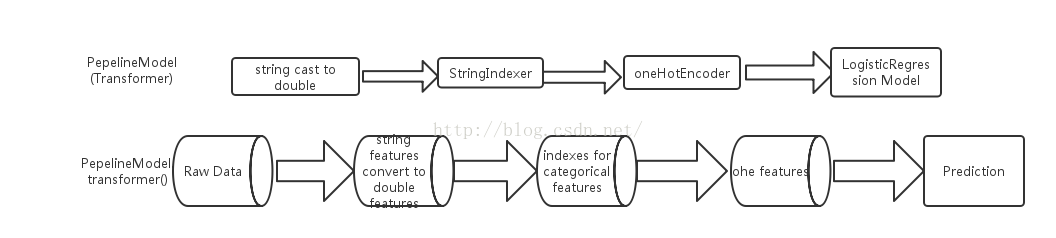
模型后,就可以在新的数据集上进行预测,总结为两部分并用流程图表示如下:
训练阶段:
预测阶段:
借助于Pepeline,在spark上进行机器学习的数据流向更加清晰,同时每一stage的任务也更加明了,因此,无论是在模型的预测使用上、还是
模型后续的改进优化上,都变得更加容易。
spark ml pipeline构建机器学习任务的更多相关文章
- 使用spark ml pipeline进行机器学习
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
- 使用 ML Pipeline 构建机器学习工作流
http://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice5/
- Spark ML Pipeline简介
Spark ML Pipeline基于DataFrame构建了一套High-level API,我们可以使用MLPipeline构建机器学习应用,它能够将一个机器学习应用的多个处理过程组织起来,通过在 ...
- spark ML pipeline 学习
一.pipeline 一个典型的机器学习过程从数据收集开始,要经历多个步骤,才能得到需要的输出.这非常类似于流水线式工作,即通常会包含源数据ETL(抽取.转化.加载),数据预处理,指标提取,模型训练与 ...
- spark ml 的例子
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
- Spark ML机器学习库评估指标示例
本文主要对 Spark ML库下模型评估指标的讲解,以下代码均以Jupyter Notebook进行讲解,Spark版本为2.4.5.模型评估指标位于包org.apache.spark.ml.eval ...
- 基于Spark ML的Titanic Challenge (Top 6%)
下面代码按照之前参加Kaggle的python代码改写,只完成了模型的训练过程,还需要对test集的数据进行转换和对test集进行预测. scala 2.11.12 spark 2.2.2 packa ...
- Spark ML源码分析之二 从单机到分布式
前一节从宏观角度给大家介绍了Spark ML的设计框架(链接:http://www.cnblogs.com/jicanghai/p/8570805.html),本节我们将介绍,Spar ...
- Spark.ML之PipeLine学习笔记
地址: http://spark.apache.org/docs/2.0.0/ml-pipeline.html Spark PipeLine 是基于DataFrames的高层的API,可以方便用户 ...
随机推荐
- pyspark读取hdfs 二进制文件
程序如下: from pyspark import SparkConf, SparkContext conf = SparkConf().setAppName("My test App&qu ...
- RSA 加密 解密 (长字符串) JAVA JS版本加解密
系统与系统的数据交互中,有些敏感数据是不能直接明文传输的,所以在发送数据之前要进行加密,在接收到数据时进行解密处理:然而由于系统与系统之间的开发语言不同. 本次需求是生成二维码是通过java生成,由p ...
- test20190802 夏令营NOIP训练18
今天的题很有难度啊.然而我10:40才看题-- 高一学堂 在美丽的中山纪念中学里面,有一座高一学堂.所谓山不在高,有仙则名:水不在深,有龙则灵.高一学堂,因为有了yxr,就成了现在这个样子 = =. ...
- go内置的反向代理
package main import ( "log" "net/http" "net/http/httputil" "net/u ...
- Codevs 1500 后缀排序(后缀数组)
1500 后缀排序 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 大师 Master 题目描述 Description 天凯是MIT的新生.Prof. HandsomeG给了他一个 ...
- CF Gym 102028G Shortest Paths on Random Forests
CF Gym 102028G Shortest Paths on Random Forests 抄题解×1 蒯板子真jir舒服. 构造生成函数,\(F(n)\)表示\(n\)个点的森林数量(本题都用E ...
- luogu P1160 队列安排
二次联通门 :luogu P1160 队列安排 /* luogu P1160 队列安排 链表 手动模拟一下就好了... */ #include <cstdio> #define Max 5 ...
- 课标2-2-1-3 :MMU配置与使用
void create_page_table(void){ unsigned long *ttb = (unsigned long *)0x20000000; unsigned long vaddr, ...
- 像素迷踪,当Unity的Frame Debugger力不从心时
http://www.manew.com/thread-92382-1-1.html 从版本5开始,Unity包含了一个全新的可视化帧调试工具,Frame Debugger.该工具能帮你解决很多图形方 ...
- XOR Clique(按位异或)
XOR Clique(按位异或): 传送门:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=4057 准备:异或:参加运算的两 ...