Seq2Seq模型 与 Attention 策略
Seq2Seq模型
传统的机器翻译的方法往往是基于单词与短语的统计,以及复杂的语法结构来完成的。基于序列的方式,可以看成两步,分别是 Encoder 与 Decoder,Encoder 阶段就是将输入的单词序列(单词向量)变成上下文向量,然后 decoder根据这个向量来预测翻译的结果。
encoder 阶段
encoder 阶段面临的一个问题是,对于输入语句,语句的长度往往是不固定的,但是我们训练神经网络往往都是要固定长度的向量。所以如何解决这个问题是 encoder阶段的关键。我们通常使用多层的 LSTM,上一层的输出将作为下一层的输入。
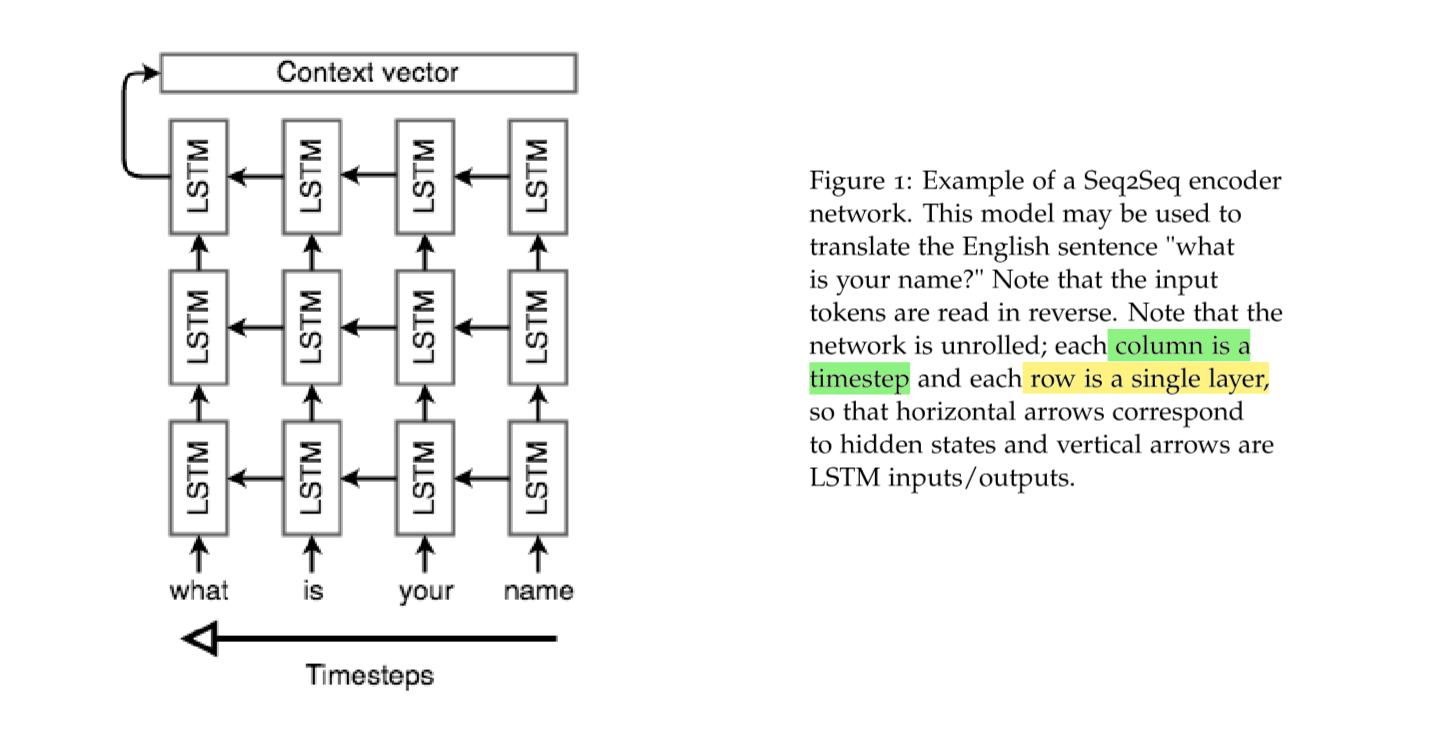
在 Google 提出 Seq2Seq 的时候,提出了将输出的语句反序输入到 encoder中,这么做是为了在 encoder阶段的最后一个输出恰好就是 docoder阶段的第一个输入。
decoder阶段
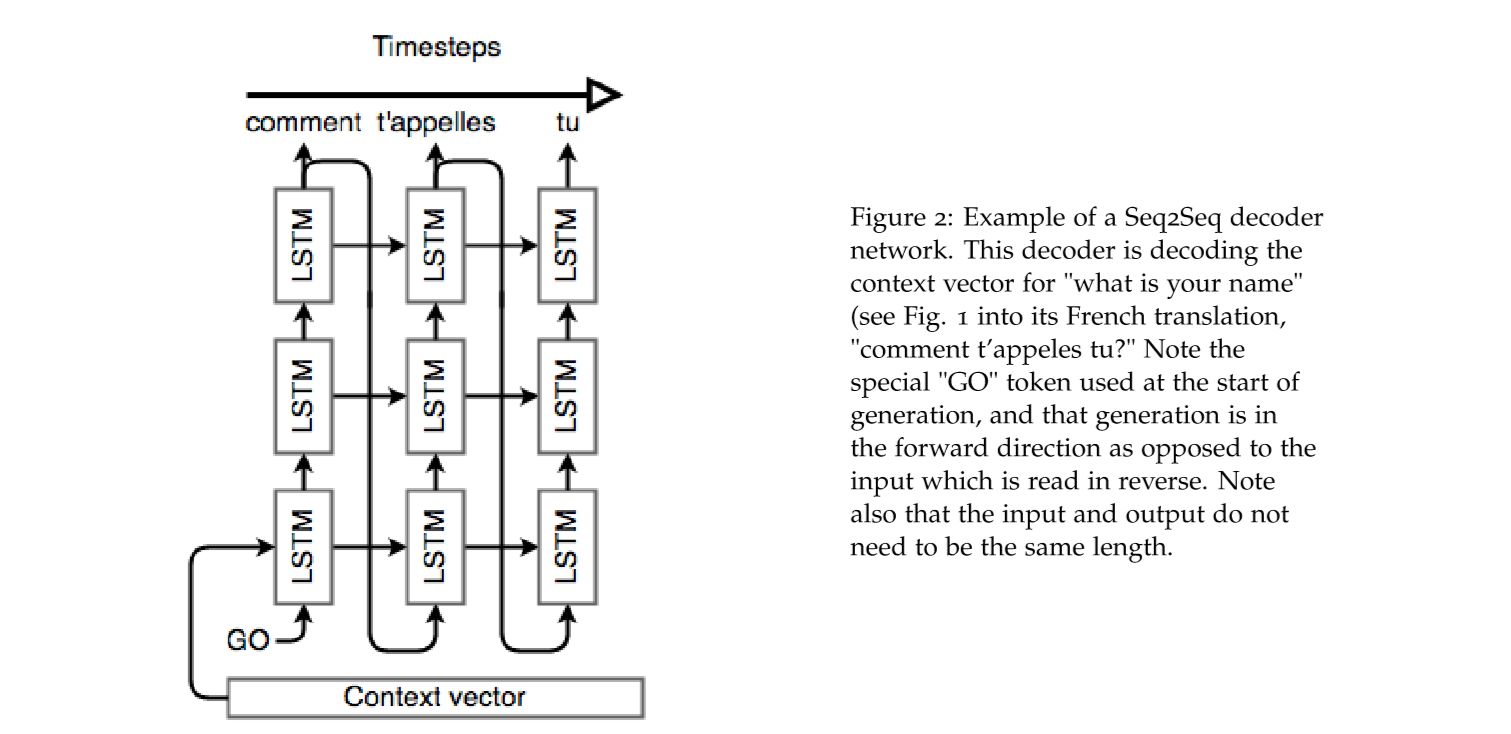
这一阶段要稍微与encoder阶段要复杂一点点。首先是一个 Token, 一般是一个 <EOS> 表示输入的结束,也就是下图中的 "Go",表示 decoder 阶段的开始,还有一点不一样就是,我们期望用以及正确预测的数据作为下一次的上下文参考,所以也就是上一节讲到的 \(C_i\) 的信息,作用到下一个时间点。横向可以看成 序列的,纵向可以看成是并行的(但是实际上不是并行的)。
双向 RNN
上面的方法面临这样一个问题,那就是单词向量往往是与上下文有关的,而不仅仅只于前面的文字有关,所以需要改进单向 RNN,这里我们使用双向 RNN来解决这个问题:
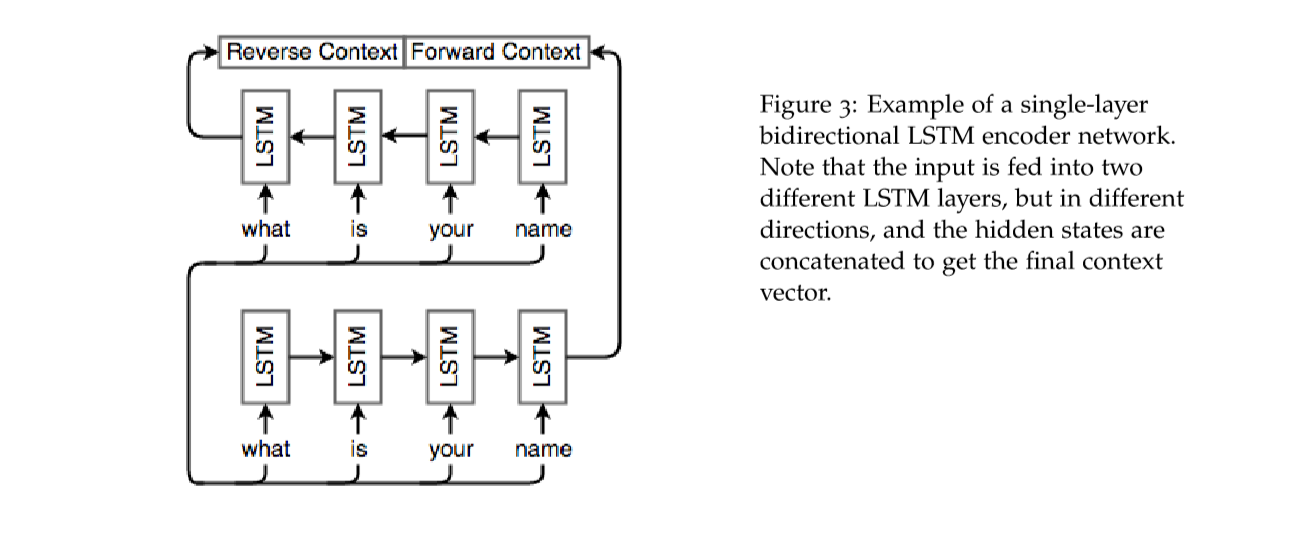
上图是一个双向 LSTM,图中是一个encoder的例子,每一个隐含层的状态都有两个向量表示,分别表示两个方向,\(h=\left[h^{(f)} \quad h^{(b)}\right]\)。输出也有两个,分别是 \(\left[ \begin{array}{ll}{o_{t}^{(f)}} & {o_{t}^{(b)}}\end{array}\right]\)。
Attention 机制
在翻译的模型中,举个简单的例子,
"the ball is on the field,"
其中关键的单词就那么几个,而且很多情况下,如果将所有的单词都考虑进来的话,会导致过拟合,反而会导致语义的不准确,所以提出了attention 的机制,主要思想作用在 decoder阶段,每次观察整个句子,在每一步可以决定那些单词是重要的。
Bahdanau et al.提出的 神经网络翻译模型
encoder阶段使用一个双向 LSTM,
decoder阶段
神经网络隐含层的使用的机制:
\[
s_{i}=f\left(s_{i-1}, y_{i-1}, c_{i}\right)
\]
其中 \(s_{i-1}\) 是神经网络前一层的输出,然后 \(y_{i-1}\) 是上一个时间序列,也就是预测的上一个单词的输出,\(C_{t}\) 于LSTM中的 \(C_t\)不太一样,但是本质上都是用来记录信息的。
通过神经网络的输出,预测的机制:
\[
p\left(y_{i} | y_{1}, \ldots, y_{i-1}, \mathbf{x}\right)=g\left(y_{i-1}, s_{i}, c_{i}\right)
\]
上面式子中用到的 \(y_{i-1}\) 就很容易理解了。
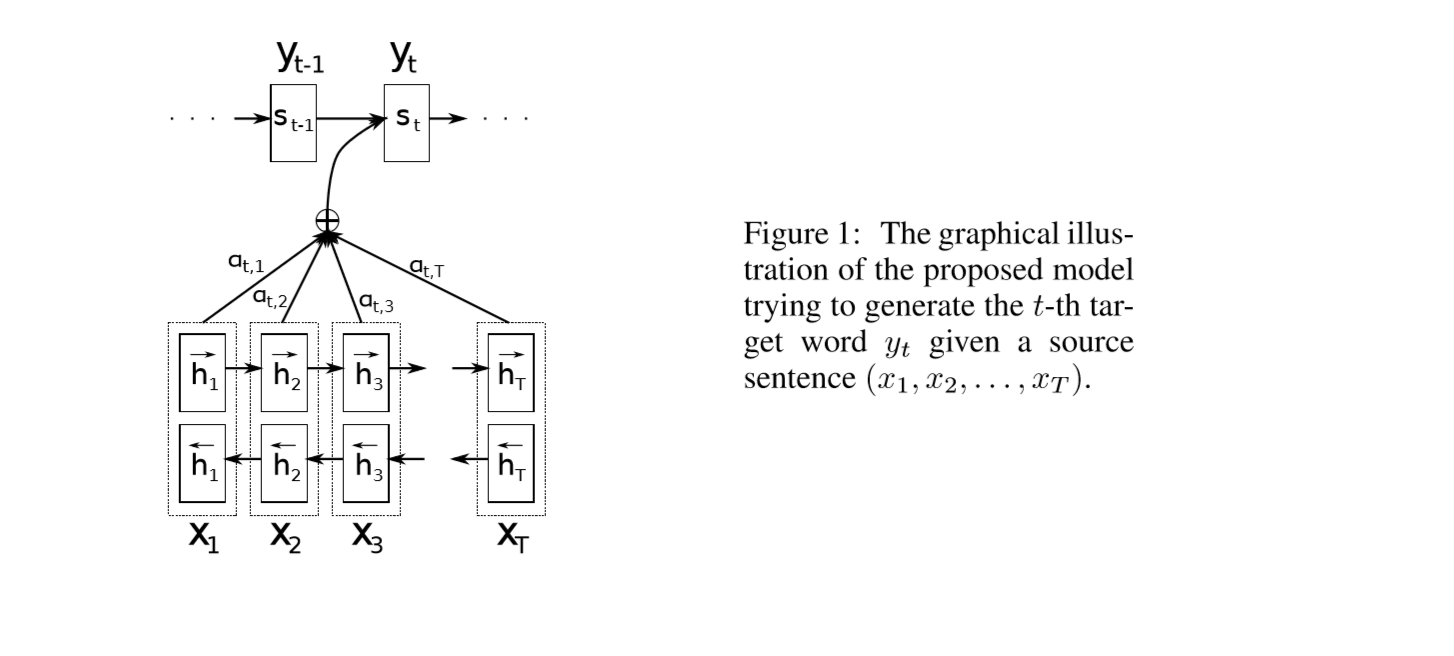
这个 \(C_i\) 本质上都是用来记录信息的,这里的计算方式是:
\[
c_{i}=\sum_{j=1}^{T_{x}} \alpha_{i j} h_{j}
\]
上式中的 \(h_j\) 也不是LSTM中的隐含层的状态,隐含层的状态是 \(s_i\) ,而是包含了重点关注第 \(i\)个单词的信息。所以我们很容易想到,这里获取 \(c_i\) 的时候必须要加权,就是对每个 \(i\),进行加权,那么衡量权重的标志是什么呢?我们用 \(e_{ij}\) 来表示,
\[
e_{i j}=a\left(s_{i-1}, h_{j}\right)
\]
这是一个对齐模型,表示输入的单词 \(j\), (我们重点关注的)在输出位置为 \(i\) 的可能性大小。然后我们将这个得分进行加权计算,就得到了
\[
\alpha_{i j}=\frac{\exp \left(e_{i j}\right)}{\sum_{k=1}^{T_{x}} \exp \left(e_{i k}\right)}
\]
再返回去求 \(c_i\)。上面的对齐模型,我们可以直接使用一个传统的神经网络。attention 机制的一个好处就是可以很好的翻译长句子,因为可以忽略不需要的信息。
Huong et al. 的神经网络翻译模型
全局attention 机制
对于encoder阶段给出的隐藏层的状态,\(h_{1}, \ldots, h_{n}\),对于 decoder阶段的隐含层状态,\(\overline{h_{1}}, \ldots, \overline{h_{n}}\)。我们可以计算一个得分,使用下面任意一种函数:
\[
\operatorname{score}\left(h_{i}, \overline{h}_{j}\right)=\left\{\begin{array}{l}{h_{i}^{T} \overline{h}_{j}} \\ {h_{i}^{T} W \overline{h}_{j}} \\ {W\left[h_{i}, \overline{h}_{j}\right]}\end{array}\right.
\]
然后就像上面的那个模型一样,通过 \(softmax\) 函数来计算概率,将这个概率作为加权即可,
\[
\alpha_{i, j}=\frac{\exp \left(\operatorname{score}\left(h_{j}, \overline{h}_{i}\right)\right)}{\sum_{k=1}^{n} \exp \left(\operatorname{score}\left(h_{k}, \overline{h}_{i}\right)\right)}
\]
然后就得出了单词的文本向量,
\[
c_{i}=\sum_{j=1}^{n} \alpha_{i, j} h_{j}
\]
接下来就可以计算新的隐含层的状态了:
\[
\tilde{h}_{i}=f\left(\left[\overline{h}_{i}, c_{i}\right]\right)
\]
然后通过最后的预测函数,预测出下一个单词。这里在时间上 \(\tilde{h}_{i}\) 也会作为下一个时间点的输入。
Local attention 的机制
Local Attention 就是使用了一个窗口表示关注的单词,可以改变窗口的大小,说明对任意的单词都可以关注。
Sequence model decoders
上面的例子也说明了,在 Attention 阶段最重要的是 Decoder的策略。
机器翻译起源于统计翻译,我们从概率的角度就是对于输入语句 \(S\) 与目标语句 \(\overline{S}\),我们的目标就是
\[
\overline{s} *=\operatorname{argmax}_{\overline{s}}(\mathbb{P}(\overline{s} | s))
\]
但是对于目标语句可能性太多,也就造成了计算量太大,我们有几种策略:
Beam search
Beam search 是使用的最多的一种策略,这种方法就是每次维持一个大小为 \(K\) 的翻译语句集合,
\[
\mathcal{H}_{t}=\left\{\left(x_{1}^{1}, \ldots, x_{t}^{1}\right), \ldots,\left(x_{1}^{K}, \ldots, x_{t}^{K}\right)\right\}
\]
当我们预测 \(t+1\) 的时刻的时候,我们依然取可能性最大的 \(K\) 个集合:
\[
\tilde{\mathcal{H}}_{t+1}=\bigcup_{k=1}^{K} \mathcal{H}_{t+1}^{\tilde{k}}
\]
其中
\[
\mathcal{H}_{t+1}^{\tilde{k}}=\left\{\left(x_{1}^{k}, \ldots, x_{t}^{k}, v_{1}\right), \ldots,\left(x_{1}^{k}, \ldots, x_{t}^{k}, v_{|V|}\right)\right\}
\]
表示每一种可能的组合。
机器翻译的评估系统
Evaluation against another task
将我们翻译的语句用于其他的系统中以查看翻译的效果。举个例子,我们将翻译的语句用于问答系统,与标准的语句用于问答系统,都能得到准确的回答,那么说明我们翻译的过程中抓住了句子的关键信息,在评估翻译结果的时候,时要考虑多方面的,这是我们既不能说我们的翻译完全正确,也不能说是失败了。
Bilingual Evaluation Understudy (BLEU)
这个方法是通过将一个参与的翻译系统的结果 B,与人工翻译的结果 A,进行对比评估,使用 n-gram 的方法进行对比。其中可能会有多个参考也就是reference。
n-gram 的方法主要是关注窗口的大小。将连在一起的单词作为一个窗口,然后计算匹配的窗口的个数。最简单的例子就是:

对于窗口,我们用 window 来表示,出现的次数,
\[
Count_{clip}=\min \left(\text { Count }, \text { Max }_{-} \text { Ref }_{-} \text { Count }\right)
\]
表示这个 window 在翻译文本与 reference文本中出现的最低的次数,那么精度可以这样计算:
\[
P_{n}=\frac{\sum_{i} \sum_{k} \min \left(h_{k}\left(c_{i}\right), \max _{j \in m} h_{k}\left(s_{i j}\right)\right)}{\sum_{i} \sum_{k} \min \left(h_{k}\left(c_{i}\right)\right)}
\]
\(H_k(c_i)\) 表示机器翻译的结果中 \(c_i\) 出现的次数,\(H_k(s_{ij})\) 表示标准答案下 \(S_{ij}\) 出现的次数,这里为什么 \(S\) 下面有双下标,是因为,这里我们可以有很多个 reference。
惩罚因子
考虑机器翻译的结果为第二句,第一句为参考的情况,这个时候,计算的结果表明,翻译的很好,因为第二个语句比较短,所以 \(H_k(s_{ij})\) 的正确率表现得比较高,但是实际上整个句子的翻译效果没有那么高:
there are many ways to evaluate the quality of a translation, like comparing the number of n-grams between a candidate translation and reference
the quality of a translation is evaluate of n-grams in a reference and with translation
因此我们引入一个惩罚因子:
\[
\beta=e^{\min \left(0,1-\frac{\operatorname{le}_{\mathrm{ref}}}{\operatorname{len}_{\mathrm{MT}}}\right)}
\]
其中分子表示 reference的长度,分母是机器翻译结果的长度,那么最终的评分我们就可以表示成:
\[
B L E U=\beta \times \exp \left(\sum_{n=1}^{N} w_{n} \log P_{n}\right)
\]
Dealing with the large output vocabulary
还有一个问题就是处理 vocabulary 过大的情况下,由于输出的时候需要经过一个 \(softmax\) 函数,所以在输出的时候,如果输出的 vocabulary 过大的话,那么 softmax 这一过程计算量就会特别大。
在第一节课里面我们就介绍过两种方法,分别是分层 SoftMax 与 Negative Sampling(负采样)。传送门:传送门
还有一些方法可以用:
降低词典的大小
为了限制词典的大小,对于语句中出现的未知的单词,我们就用 <UNK> 来表示,但是这样可能会导致源语句失去一些关键信息。还有一种方法就是,
还有一种做法就是将数据集进行划分,这样的好处是,相似关系的数据集一般在一起。每个训练数据的子集取大小为 $ \tau=\left|V^{\prime}\right|$ 的字典。然后对整个数据集进行迭代。主要思想就是,我们在训练的时候,将训练数据分成很多个 Min-Batches,对每个 Min-Batches 的选取就是选取到 $ \tau$ 个单词的时候,用来表示这个字典,然后在训练的时候用这种数据会大大降低在 SoftMax 阶段的计算量。我们假设每次训练集的目标单词,也就是 Min-Batches 部分的单词,构成集合 \(V_{i}^{\prime}\),那么这个集合中每个单词的概率就是:
\[
Q_{i}\left(y_{k}\right)=\left\{\begin{array}{ll}{\frac{1}{\left|V_{i}^{\prime}\right|}} & {\text { if } y_{t} \in V_{i}^{\prime}} \\ {0} & {\text { otherwise }}\end{array}\right.
\]
基于单词的模型与基于字母的模型
基于单词的模型,可以选取出现概率最高的 n-gram 框,然后将这个框不断地加到数据集中去。
简单说下这两种方式的混合策略,
混合策略中,首先是对于单词的预测,使用常规的 LSTM,但是遇到输出的单词是 <UNK> 的时候,我们就需要使用字母级上的神经网络了。
Seq2Seq模型 与 Attention 策略的更多相关文章
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- 深度学习的seq2seq模型——本质是LSTM,训练过程是使得所有样本的p(y1,...,yT‘|x1,...,xT)概率之和最大
from:https://baijiahao.baidu.com/s?id=1584177164196579663&wfr=spider&for=pc seq2seq模型是以编码(En ...
- seq2seq模型详解及对比(CNN,RNN,Transformer)
一,概述 在自然语言生成的任务中,大部分是基于seq2seq模型实现的(除此之外,还有语言模型,GAN等也能做文本生成),例如生成式对话,机器翻译,文本摘要等等,seq2seq模型是由encoder, ...
- [转] 图解Seq2Seq模型、RNN结构、Encoder-Decoder模型 到 Attention
from : https://caicai.science/2018/10/06/attention%E6%80%BB%E8%A7%88/ 一.Seq2Seq 模型 1. 简介 Sequence-to ...
- 学习笔记CB014:TensorFlow seq2seq模型步步进阶
神经网络.<Make Your Own Neural Network>,用非常通俗易懂描述讲解人工神经网络原理用代码实现,试验效果非常好. 循环神经网络和LSTM.Christopher ...
- 从Encoder到Decoder实现Seq2Seq模型
https://zhuanlan.zhihu.com/p/27608348 更新:感谢@Gang He指出的代码错误.get_batches函数中第15行与第19行,代码已经重新修改,GitHub已更 ...
- seq2seq模型以及其tensorflow的简化代码实现
本文内容: 什么是seq2seq模型 Encoder-Decoder结构 常用的四种结构 带attention的seq2seq 模型的输出 seq2seq简单序列生成实现代码 一.什么是seq2seq ...
- 时间序列深度学习:seq2seq 模型预测太阳黑子
目录 时间序列深度学习:seq2seq 模型预测太阳黑子 学习路线 商业中的时间序列深度学习 商业中应用时间序列深度学习 深度学习时间序列预测:使用 keras 预测太阳黑子 递归神经网络 设置.预处 ...
- Seq2Seq模型与注意力机制
Seq2Seq模型 基本原理 核心思想:将一个作为输入的序列映射为一个作为输出的序列 编码输入 解码输出 解码第一步,解码器进入编码器的最终状态,生成第一个输出 以后解码器读入上一步的输出,生成当前步 ...
随机推荐
- MyCat教程一:MyCat的简单介绍
MyCat教程二:mysql主从复制实现 MyCat教程三:安装及配置介绍 MyCat教程四:实现读写分离 MyCat教程五:实现分库分表 MyCat教程六:全局序列号-全局主键的自增长 一.MyCa ...
- java项目路径总结,java.io.File支持的路放方式
1.直接输入路径 已maven项目为例,直接输入路径的4种方式,即是File类支持的方式: /** * FileOutpurStream以字节数组方式写入文件 * @throws IOExceptio ...
- nginx 页面加载不全的问题
在nginx的server中添加: proxy_buffer_size 2m; proxy_buffers 8 1m; proxy_busy_buffers_size 2m; 这是由于页面内容过长,默 ...
- python的包管理软件Conda的用法
创建自己的虚拟环境 conda create -n learn python= 切换环境: activate learn 查看所有环境: conda env list 安装第三方包: conda in ...
- vue 项目中安装npm--save-dev 和 --save 命令
在vue项目中我们常用npm install 安装模块或插件 有两种命令把他们写入到 package.json 文件里面去 例如安装axios 安装到开发环境npm axios --save-dev ...
- opencv想到的
opencv是用C++写的库,包了多种语言接口,包括C,C++,python,java等. OpenCV 是一个开放源代码的计算机视觉库,目前在科研和开发中被广泛使用.OpenCV 由一系列 C 函数 ...
- egg 阻止 sql 注入,相关文章
egg 阻止 sql 注入,相关文章 网址 注意!!我们极其不建议开发者拼接 sql 语句,这样很容易引起 sql 注入!!如果必须要自己拼接 sql 语句,请使用 mysql.escape 方法. ...
- 【Javascript】call
var ShowDlg = function ShowDlg() { } ShowDlg.prototype.animate = function(msg) { alert(msg); } var l ...
- docker 启动失败 Job for docker.service failed because the control process exited with error code. See "systemctl status docker.service" and "journalctl -xe" for details.
CentOS7安装docker,安装成功后,启动失败 提示: 我们可以看到此处它提示是Failed to start Docker Application Container Engine. 于是在网 ...
- Trie Service
Description Build tries from a list of <word, freq> pairs. Save top 10 for each node. Example ...