Oracle 分区表中本地索引和全局索引的适用场景
背景
分区表创建好了之后,如果需要最大化分区表的性能就需要结合索引的使用,分区表有两种索引:本地索引和全局索引。既然存在着两种的索引类型,相信存在即合理。既然存在就会有存在的原因,也就是在特定的场景中就更能发挥出索引的性能的;
本文档通过测试,总结出两种索引的适合的场景;
测试环境
数据库版本:11.2.0.3
分区表的创建脚本:
CREATE TABLE SCOTT.PTB
(
GG1DM VARCHAR2(9 BYTE),
SL NUMBER(18,4) ,
DJBH VARCHAR2(20 BYTE)
)
NOCOMPRESS
PARTITION BY LIST (GG1DM)
(
PARTITION PTABLE_P1 VALUES ('07'),
PARTITION PTABLE_P2 VALUES ('08'),
PARTITION PTABLE_P3 VALUES ('09')
)然后插入大量的数据,再进行统计信息的更新;select t3.table_name,
t3.partition_name,
t3.high_value,
t3.num_rows,
t3.blocks,
t3.empty_blocks,
t3.last_analyzed
from dba_tab_partitions t3
where t3.table_name='PTABLE'
order by t3.num_rows desc;开始测试
测试一、跨分区的数据查询
1.1 创建本地索引(注意:该列不是分区的列)
SQL> CREATE INDEX SCOTT.IN_PTB ON SCOTT.PTB
(DJBH)
LOGGING
LOCAL (
PARTITION PTABLE_P1
LOGGING
NOCOMPRESS ,
PARTITION PTABLE_P2
LOGGING
NOCOMPRESS ,
PARTITION PTABLE_P3
LOGGING
NOCOMPRESS
)
SQL> select Segment_NAME,PARTITION_NAME,SEGMENT_TYPE from dba_segments a where a.segment_name='IN_PTB';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
---------------- --------------------- ------------------
IN_PTB PTABLE_P1 INDEX PARTITION
IN_PTB PTABLE_P2 INDEX PARTITION
IN_PTB PTABLE_P3 INDEX PARTITIONLOCAL索引会在每个分区上面单独创建INDEX PARTITION,类似于三个子索引;
进行执行计划的查看
SQL> select count(1) from scott.ptb where djbh='R23NAA002138250';
COUNT(1)
----------
512
1.2 创建全局索引,原先的索引先drop(注意:该列不是分区的列)
SQL> CREATE INDEX SCOTT.IN_PTB_L ON SCOTT.PTB
(DJBH)
NOLOGGING
STORAGE (
BUFFER_POOL DEFAULT
FLASH_CACHE DEFAULT
CELL_FLASH_CACHE DEFAULT
)
NOPARALLEL;
SQL> select Segment_NAME,PARTITION_NAME,SEGMENT_TYPE from dba_segments a where a.segment_name='IN_PTB_L';
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE
-------------- --------------------- --------------------
IN_PTB_L INDEX进行执行计划的查看
需要先刷新buffer:
alter system flush buffer_cache;
select count(1) from scott.ptb where djbh='R23NAA002138250';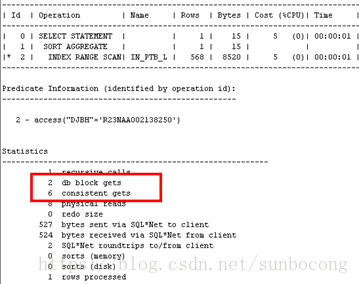
测试一总结:
以上那种情况因为djbh这一列是需要跨分区的,当查询的条件是需要跨分区查询内容的时候,LOCAL INDEX的效率比GLOBAL INDEX的效率要低,通过consistent gets和db block gets的对比可以看出来;
测试二、分区内部的查询
2.1 分区内使用本地索引
alter system flush buffer_cache;
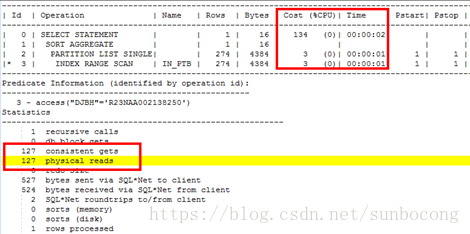
select count(1) from scott.ptb where djbh='R23NAA002138250' and GG1DM='07'; #- 1
- 2
该条件可以确定在单个分区里面
2.2 分区内使用全局索引
alter system flush buffer_cache;
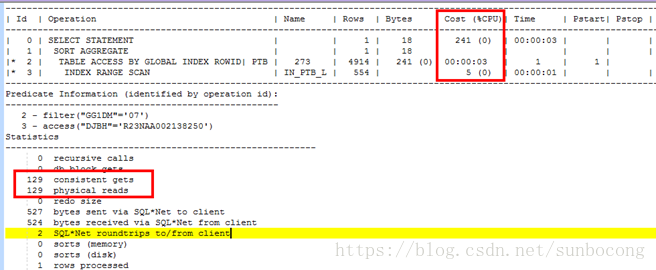
select /*+ index(PTB IN_PTB_L) */ count(1) from scott.ptb where djbh='R23NAA002138250' and GG1DM='07';- 1
- 2
测试二总结:
通过这组实验可以看出来如果查询的条件是在单个分区里面查询的时候,那么LOCAL INDEX的效率比GLOBAL INDEX的效率要高。
总结
经过以上的测试可以发现全局索引和本地索引的使用效率跟查询条件有直接的影响,创建索引的时候需要根据业务的使用场景进行创建;
而分区表的创建也是受使用场景所影响的,所以在创建分区表和分区索引的时候都需要事先了解业务的需求,尽量把业务需要统计的信息放在一个同一个分区。这样使分区表的性能实现最大化;
Oracle 分区表中本地索引和全局索引的适用场景的更多相关文章
- Atitit.分区对索引的影响 分区索引和全局索引 attilax总结
Atitit.分区对索引的影响 分区索引和全局索引 attilax总结 1. 分区的好处1 2. 分区键:2 3. 分区的建议:2 4. 分区索引和全局索引:2 5. 全局索引就是在全表上创建索引, ...
- Oracle 分区表中索引失效
当对分区表进行 一些操作时,会造成索引失效. 当有truncate/drop/exchange 操作分区 时全局索引 会失效. exchange 的临时表没有索引,或者有索引,没有用includin ...
- Oracle分区表删除分区引发错误ORA-01502: 索引或这类索引的分区处于不可用状态
(一)问题: 最近在做Oracle数据清理,在对分区表进行数据清理时,采用的方法是drop partition,删除的过程中,没有遇到任何问题,大概过了10分钟,开发人员反馈部分分区表上的业务失败.具 ...
- Oracle数据库中如何选择合适的索引类型 .
索引就好象一本字典的目录.凭借字典的目录,我们可以非常迅速的找到我们所需要的条目.数据库也是如此.凭借Oracle数据库的索引,相关语句可以迅速的定位记录的位置,而不必去定位整个表. 虽然说,在表中是 ...
- Oracle分区表删除分区数据时导致索引失效解决
https://blog.csdn.net/e_wsq/article/details/80896258
- ORACLE 全局索引和本地索引
Oracle数据库中,有两种类型的分区索引,全局索引和本地索引,其中本地索引又可以分为本地前缀索引和本地非前缀索引.下面就分别看看每种类型的索引各自的特点. 全局索引以整个表的数据为对象建立索引,索引 ...
- Oracle非分区索引,全局分区索引和本地分区索引。
1.如果按照索引是否分区作为划分依据,Oracle 的索引类型可以分为非分区索引,全局分区索引和本地分区索引. 2.创建演示实例 --创建非分区表create table test_partition ...
- 深入学习Oracle分区表及分区索引
关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类: • Range(范围)分区 • Has ...
- 转:深入学习Oracle分区表及分区索引
转自:http://database.ctocio.com.cn/tips/286/8104286.shtml 关于分区表和分区索引(About Partitioned Tables and Inde ...
随机推荐
- Python进阶:程序界的垃圾分类回收
垃圾回收是 Python 自带的机制,用于自动释放不会再用到的内存空间: 什么是内存泄漏呢? 内存泄漏,并不是说你的内存出现了信息安全问题,被恶意程序利用了,而是指程序本身没有设计好,导致程序未能释放 ...
- memcached源码分析二-lru
在前一篇文章中介绍了memcached中的内存管理策略slab,那么需要缓存的数据是如何使用slab的呢? 1. 缓存对象item内存分布 在memcached,每一个缓存的对象都使用一个ite ...
- SpringCloud整合过程中jar依赖踩坑经验
今天在搭建SpringCloud Eureka过程中,一直在报pom依赖错误,排查问题总结如下经验. 1.SpringBoot整合SpringCloud两者版本是有严格约束的,详细见SpringBoo ...
- (一) CentOS 7 进行 Docker CE 安装
参考并感谢 官方文档: https://docs.docker.com/install/linux/docker-ce/centos/ 卸载旧版本 # 停止所有正在运行的容器 docker stop ...
- ② Python3.0 运算符
Python3.0 语言支持的运算符有: 算术运算符.比较(关系)运算符.赋值运算符.逻辑运算符.位运算符.成员运算符.身份运算符.运算符优先级 一.算术运算符 常见的算术运算符有+,-,*,/,%, ...
- ADO.NET 七(一个例子)
通过一个完整的实例实现课程信息管理功能的操作,包括查询.修改.删除课程信息等操作. 1) 创建课程信息表 create table StuCourse ( id int primary key ide ...
- 强大的VIM
个人感觉,vim用熟了,比任何编辑器都好用,VIM的许多特性节省了时间和击键次数,并可以完成一些其他编辑器无法完成的功能,这里在网上找了几个经典案例,记录一下. 与大部分其它编辑器不同,进入 Vim ...
- java报错与解决方法总结
错误 error:Syntax error, insert ")" to complete MethodDeclaration 解决办法:放到main方法里 错误原因: 错误: e ...
- atan、atanf、atanl、atan2、atan2f、atan2l
很久不发博客了,今天在园中计算各种角,于是复习下fan正切函数 计算x的反正切值 (atan.atanf和 atanl) 或y/x 的反正切值 (atan2.atan2f和 atan2l). ...
- redis键过期 (redis 2.6及以上)
EXPIRE key seconds 用来对一个键设置一个过期时间,第二个参数表示经过多少秒后键过期. 一个键过期后, 这个键将会被自动删除. 在Redis术语中,带有过期时间的键经常被称作volat ...