Spark之RDD依赖关系及DAG逻辑视图
RDD依赖关系为成两种:窄依赖(Narrow Dependency)、宽依赖(Shuffle Dependency)。窄依赖表示每个父RDD中的Partition最多被子RDD的一个Partition所使用;宽依赖表示一个父RDD的Partition都会被多个子RDD的Partition所使用。
一、窄依赖解析
RDD的窄依赖(Narrow Dependency)是RDD中最常见的依赖关系,用来表示每一个父RDD中的Partition最多被子RDD的一个Partition所使用,如下图所示,父RDD有2~3个Partition,每一个分区都只对应子RDD的一个Partition(join with inputs co-partitioned:对数据进行基于相同Key的数值相加)。
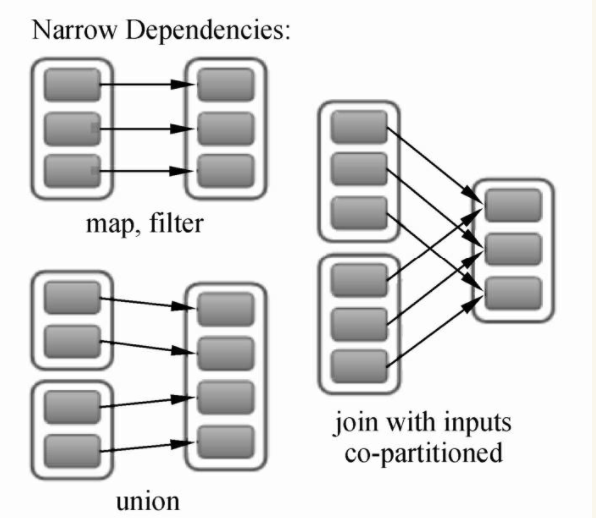
窄依赖分为两类:第一类是一对一的依赖关系,在Spark中用OneToOneDependency来表示父RDD与子RDD的依赖关系是一对一的依赖关系,如map、filter、join with inputs co-partitioned;第二类是范围依赖关系,在Spark中用RangeDependency表示,表示父RDD与子RDD的一对一的范围内依赖关系,如union。OneToOneDependency依赖关系的Dependency.scala的源码如下。
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
OneToOneDependency的getParents重写方法引入了参数partitionId,而在具体的方法中也使用了这个参数,这表明子RDD在使用getParents方法的时候,查询的是相同partitionId的内容。也就是说,子RDD仅仅依赖父RDD中相同partitionID的Partition。
Spark窄依赖中第二种依赖关系是RangeDependency。Dependency.scala的RangeDependency的源码如下。
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD
* @param outStart the start of the range in the child RDD
* @param length the length of the range
*/
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}
RangeDependency和OneToOneDependency最大的区别是实现方法中出现了outStart、length、instart,子RDD在通过getParents方法查询对应的Partition时,会根据这个partitionId减去插入时的开始ID,再加上它在父RDD中的位置ID,换而言之,就是将父RDD中的Partition,根据partitionId的顺序依次插入到子RDD中。
分析完Spark中的源码,下边通过两个例子来讲解从实例角度去看RDD窄依赖输出的结果。对于OneToOneDependency,采用map操作进行实验,实验代码和结果如下所示。
val sparkSession = SparkSession.builder().master("local").appName("wordcount").getOrCreate()
val sc = sparkSession.sparkContext
sc.setLogLevel("WARN")
// val people = sparkSession.read.parquet("...").as[Person]
val num = Array(100,80,70)
val rddnum1 = sc.parallelize(num)
val mapRdd = rddnum1.map(_*2)
mapRdd.collect().foreach(println)
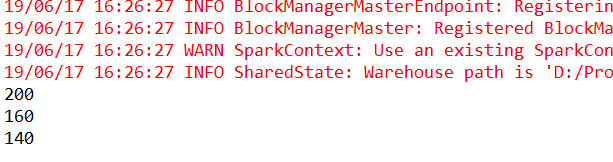
对于RangeDependency,采用union操作进行实验,实验代码和结果如下所示。
val sparkSession = SparkSession.builder().master("local").appName("wordcount").getOrCreate()
val sc = sparkSession.sparkContext
sc.setLogLevel("WARN")
// 创建数组1
val data1 = Array("spark","scala","hadoop")
// 创建数组2
val data2 = Array("SPARK","SCALA","HADOOP")
// 将数组1的数据形成RDD1
val rdd1 = sc.parallelize(data1)
// 将数组2的数据形成RDD2
val rdd2 = sc.parallelize(data2)
// 把RDD1与RDD2联合
val unionRdd = rdd1.union(rdd2)
// 将结果收集并输出
unionRdd.collect().foreach(println)

二、宽依赖解析
RDD的宽依赖(Shuffle Dependency)是一种会导致计算时产生Shuffle操作的RDD操作,用来表示一个父RDD的Partition都会被多个子RDD的Partition使用,如下图中groupByKey算子操作所示,父RDD有3个Partition,每个Partition中的数据会被子RDD中的两个Partition使用。
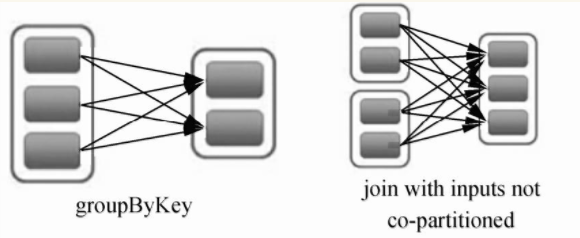
宽依赖的源码位于Dependency.scala文件的ShuffleDependency方法中,newShuffleId()产生了新的shuffleId,表明宽依赖过程需要涉及shuffle操作,后续的代码表示宽依赖进行时的shuffle操作需要向shuffleManager注册信息。Dependency.scala的ShuffleDependency的源码如下。
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] { override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]] private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName) val shuffleId: Int = _rdd.context.newShuffleId() val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this) _rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] { override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]] private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
// 注意:如果在PairRDDFunctions方法中使用combineByKeyWithClassTag,combiner类标签可能为空
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName) val shuffleId: Int = _rdd.context.newShuffleId() val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this) _rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}
Spark中宽依赖关系非常常见,其中较经典的操作为GroupByKey(将输入的key-value类型的数据进行分组,对相同key的value值进行合并,生成一个tuple2),具体代码和操作结果如下所示。输入5个tuple2类型的数据,通过运行产生3个tuple2数据。
val sparkSession = SparkSession.builder().master("local").appName("wordcount").getOrCreate()
val sc = sparkSession.sparkContext
sc.setLogLevel("WARN")
val data = Array(Tuple2("spark",100),Tuple2("spark",95),Tuple2("hadoop",99),Tuple2("hadoop",80),Tuple2("scala",75))
val rdd = sc.parallelize(data)
val rddGroup = rdd.groupByKey()
rddGroup.collect().foreach(println)

三、DAG生成的机制
在图论中,如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。而在Spark中,由于计算过程很多时候会有先后顺序,受制于某些任务必须比另一些任务较早执行的限制,我们必须对任务进行排队,形成一个队列的任务集合,这个队列的任务集合就是DAG图,每一个定点就是一个任务,每一条边代表一种限制约束(Spark中的依赖关系)。
通过DAG,Spark可以对计算的流程进行优化,对于数据处理,可以将在单一节点上进行的计算操作进行合并,并且计算中间数据通过内存进行高效读写,对于数据处理,需要涉及Shuffle操作的步骤划分Stage,从而使计算资源的利用更加高效和合理,减少计算资源的等待过程,减少计算中间数据读写产生的时间浪费(基于内存的高效读写)。
Spark中DAG生成过程的重点是对Stage的划分,其划分的依据是RDD的依赖关系,对于不同的依赖关系,高层调度器会进行不同的处理。对于窄依赖,RDD之间的数据不需要进行Shuffle,多个数据处理可以在同一台机器的内存中完成,所以窄依赖在Spark中被划分为同一个Stage;对于宽依赖,由于Shuffle的存在,必须等到父RDD的Shuffle处理完成后,才能开始接下来的计算,所以会在此处进行Stage的切分。
在Spark中,DAG生成的流程关键在于回溯,在程序提交后,高层调度器将所有的RDD看成是一个Stage,然后对此Stage进行从后往前的回溯,遇到Shuffle就断开,遇到窄依赖,则归并到同一个Stage。等到所有的步骤回溯完成,便生成一个DAG图。
DAG生成的相关源码位于Spark的DAGScheduler.scala。getParentStages获取或创建一个给定RDD的父Stages列表,getParentStages调用了getShuffleMapStage,,getShuffleMapStage调用了getAncestorShuffleDependencies,getAncestorShuffleDependencies返回给定RDD的父节点中直接的Shuffle依赖。DAGScheduler.scala的getParentStages的源码如下。
/**
* Get or create the list of parent stages for a given RDD. The new Stages will be created with
* the provided firstJobId.
*/
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
// Kind of ugly: need to register RDDs with the cache here since
// we can't do it in its constructor because # of partitions is unknown
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
parents += getShuffleMapStage(shufDep, firstJobId)
case _ =>
waitingForVisit.push(dep.rdd)
}
}
}
}
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents.toList
}
DAGScheduler.scala的getShuffleMapStage的源码如下。
/**
* Get or create a shuffle map stage for the given shuffle dependency's map side.
*/
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) => stage
case None =>
// We are going to register ancestor shuffle dependencies
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
if (!shuffleToMapStage.contains(dep.shuffleId)) {
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
}
// Then register current shuffleDep
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
DAGScheduler.scala的getAncestorShuffleDependencies的源码如下。
/** Find ancestor shuffle dependencies that are not registered in shuffleToMapStage yet */
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = {
val parents = new Stack[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
if (!shuffleToMapStage.contains(shufDep.shuffleId)) {
parents.push(shufDep)
}
case _ =>
}
waitingForVisit.push(dep.rdd)
}
}
} waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents
}
四、DAG逻辑视图解析
下面通过一个简单计数案例讲解DAG具体的生成流程和关系。示例代码如下。
val conf = new SparkConf()
conf.setAppName("My first spark app").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val lines = sc.textFile("./src/test3/words.txt")
// 操作一 通过flatmap形成新的MapPartitionRDD
val words = lines.flatMap(lines=>lines.split(" "))
// 操作二 通过map形成新的MapPartitionRDD
val pairs = words.map(word=>(word,1))
// 操作三 reduceByKey(包含两步reduce)
// 此步骤生成MapPartitionRDD和ShuffleRDD
val WordCounts = pairs.reduceByKey(_+_)
WordCounts.collect().foreach(println)
println(pairs.toDebugString) // 通过toDebugString查看RDD的谱系
println("====================================================")
println(WordCounts.toDebugString)
println("====================================================")
sc.stop()

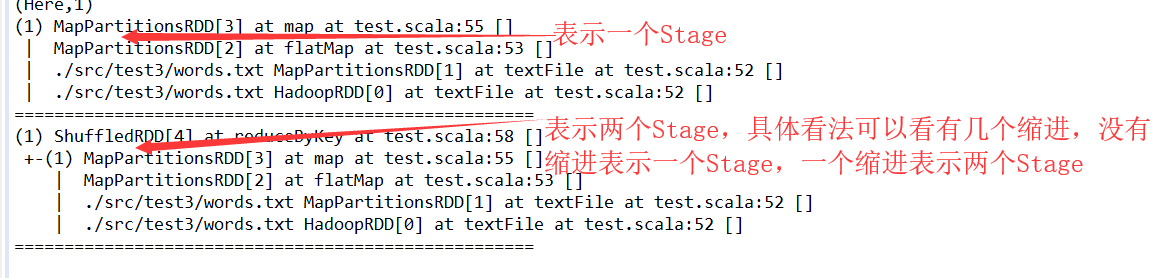
具体解释为:在程序正式运行前,Spark的DAG调度器会将整个流程设定为一个Stage,此Stage包含3个操作,5个RDD,分别为MapPartitionRDD(读取文件数据时)、MapPartitionRDD(flatMap操作)、MapPartitionRDD(map操作)、MapPartitionRDD(reduceByKey的local段的操作)、ShuffleRDD(reduceByKeyshuffle操作)。
(1)回溯整个流程,在shuffleRDD与MapPartitionRDD(reduceByKey的local段的操作)中存在shuffle操作,整个RDD先在此切开,形成两个Stage。
(2)继续向前回溯,MapPartitionRDD(reduceByKey的local段的操作)与MapPartitionRDD (map操作)中间不存在Shuffle(即两个RDD的依赖关系为窄依赖),归为同一个Stage。
(3)继续回溯,发现往前的所有的RDD之间都不存在Shuffle,应归为同一个Stage。
(4)回溯完成,形成DAG,由两个Stage构成:
第一个Stage由MapPartitionRDD(读取文件数据时)、MapPartitionRDD(flatMap操作)、MapPartitionRDD(map操作)、MapPartitionRDD(reduceByKey的local段的操作)构成。第二个Stage由ShuffleRDD(reduceByKey Shuffle操作)构成。
Spark之RDD依赖关系及DAG逻辑视图的更多相关文章
- RDD算子、RDD依赖关系
RDD:弹性分布式数据集, 是分布式内存的一个抽象概念 RDD:1.一个分区的集合, 2.是计算每个分区的函数 , 3.RDD之间有依赖关系 4.一个对于key-value的RDD的Partit ...
- Spark-Core RDD依赖关系
scala> var rdd1 = sc.textFile("./words.txt") rdd1: org.apache.spark.rdd.RDD[String] = . ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark的RDD原理以及2.0特性的介绍
转载自:http://www.tuicool.com/articles/7VNfyif 王联辉,曾在腾讯,Intel 等公司从事大数据相关的工作.2013 年 - 2016 年先后负责腾讯 Yarn ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark --【宽依赖和窄依赖】
前言 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,暴力的理解就是stage的划分是按照有没有涉及到shuffle来划分的,没涉及的shuffle的都划 ...
- RDDs基本操作、RDDs特性、KeyValue对RDDs、RDD依赖
摘要:RDD是Spark中极为重要的数据抽象,这里总结RDD的概念,基本操作Transformation(转换)与Action,RDDs的特性,KeyValue对RDDs的Transformation ...
- Spark之RDD的定义及五大特性
RDD是分布式内存的一个抽象概念,是一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,能横跨集群所有节点并行计算,是一种基于工作集的应用抽象. RDD底层存储原理:其数据分布存储于多台机器上 ...
随机推荐
- fork,vfork
转自 http://blog.csdn.net/todd911/article/details/14062103 1.fork函数 一个现有的进程可以调用fork函数创建一个新的子进程. #inclu ...
- 洛谷P3834题解
若想要深入学习主席树,传送门. Description: 给定数列 \(\{a_n\}\) ,求闭区间 \([l,r]\) 的第 \(k\) 小的数. Method: 先对数据进行离散化,然后按照权值 ...
- unity:坐标变换 - 两个函数
在cocos中,我们知道有如下的坐标变换函数: CCPoint convertToNodeSpace(const CCPoint& worldPoint);CCPoint convertToW ...
- js正则表达式之解决html解析<>标签问题
应用场景:以博客写文章为例,有的时候我们不经意间写的字符串带标签,然后浏览器将其解析了,实际上我们并不希望其被解析,于是可通过核心代码解决该问题. 核心代码如下: data.codeSource.re ...
- 【Gamma】Scrum Meeting 5
目录 写在前面 进度情况 任务进度表 照片 写在前面 例会时间:6.1 22:45-23:00 例会地点:微信群语音通话 代码进度记录github在这里 临近期末,团队成员课程压力均较大,需要较多时间 ...
- Django实现自动发布(2视图-任务接收)
上一篇服务版本的新增,是通过触发 gitlab 任务来实现的,那么如何得到任务的最终状态呢? 好在 gitlab 为我们提供了webhook,也就是消息钩子,可以发送pipeline消息到我们指定的地 ...
- 深度学习最全优化方法总结比较及在tensorflow实现
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/u010899985/article/d ...
- Windows Server 2008 + IIS 7+ ASP.NET 并发优化
Windows Server 2008 + IIS 7+ ASP.NET 并发优化 站点出现这样的错误信息: Error Summary: HTTP Error 503.2 - Service Una ...
- CentOS7下安装ELK(nginx 、elasticsearch-5.1.1、logstash-5.1.1、kibana-5.1.1)
nginx: #直接yum安装: [root@elk-node1 ~]# yum install nginx -y 官方文档:http://nginx.org/en/docs/http/ngx_htt ...
- java上传图片并压缩图片大小
Thumbnailator 是一个优秀的图片处理的Google开源Java类库.处理效果远比Java API的好.从API提供现有的图像文件和图像对象的类中简化了处理过程,两三行代码就能够从现有图片生 ...