spark-shell操作hive
本文是在集群已经搭建好的基础上来说的,还没有搭建好集群的小伙伴还请自行百度!
启动spark-shell之前要先启动hive metastore 和 hiveservice2
hive --service metastore &
hiveserver2
然后再启动spark-shell
spark-shell --master yarn --deploy-medo client
启动之后可能会抛出一些异常
[root@master hadoop]# spark-shell --master yarn --deploy-mode client
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/06/04 09:46:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/06/04 09:47:00 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
18/06/04 09:47:35 WARN DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:609)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:370)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:546)
18/06/04 09:47:59 WARN HiveConf: HiveConf of name hive.metastore.hbase.aggregate.stats.false.positive.probability does not exist
18/06/04 09:47:59 WARN HiveConf: HiveConf of name hive.llap.io.orc.time.counters does not exist
18/06/04 09:47:59 WARN HiveConf: HiveConf of name hive.orc.splits.ms.footer.cache.ppd.enabled does not exist
18/06/04 09:47:59 WARN HiveConf: HiveConf of name hive.server2.metrics.enabled does not exist
18/06/04 09:47:59 WARN HiveConf: HiveConf of name hive.llap.am.liveness.connection.timeout.ms does not exist
18/06/04 09:47:59 WARN HiveConf: HiveConf of name hive.server2.thrift.client.connect.retry.limit does not exist
18/06/04 09:47:59 WARN HiveConf: HiveConf of name hive.llap.io.allocator.direct does not exist
18/06/04 09:47:59 WARN HiveConf: HiveConf of name hive.llap.auto.enforce.stats does not exist
18/06/04 09:47:59 WARN HiveConf: HiveConf of name hive.llap.client.consistent.splits does not exist
这些警告不影响咱们的运行
scala> val rdd=sc.parallelize(1 to 100,5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[] at parallelize at <console>:24 scala> rdd.count
res0: Long = 100 scala>
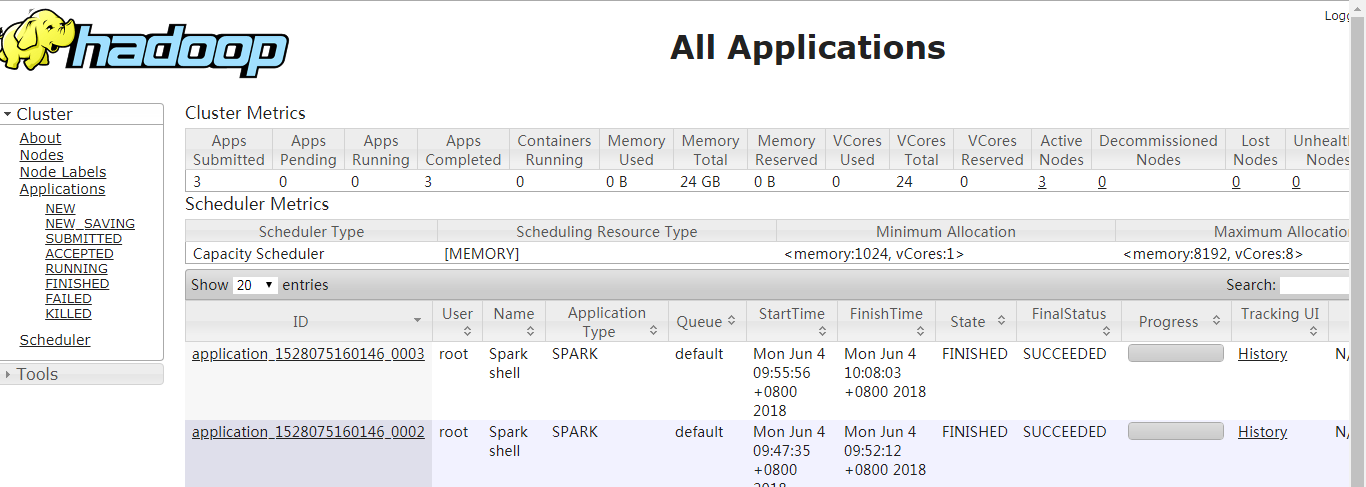
spark的UI页面
spark-shell操作hive的更多相关文章
- spark2.3.0 配置spark sql 操作hive
spark可以通过读取hive的元数据来兼容hive,读取hive的表数据,然后在spark引擎中进行sql统计分析,从而,通过spark sql与hive结合实现数据分析将成为一种最佳实践.配置步骤 ...
- 通过 Spark R 操作 Hive
作为数据工程师,我日常用的主力语言是R,HiveQL,Java与Scala.R是非常适合做数据清洗的脚本语言,并且有非常好用的服务端IDE——RStudio Server:而用户日志主要储存在hive ...
- spark+hcatalog操作hive表及其数据
package iie.hadoop.hcatalog.spark; import iie.udps.common.hcatalog.SerHCatInputFormat; import iie.ud ...
- Spark SQL 操作Hive 数据
Spark 2.0以前版本:val sparkConf = new SparkConf().setAppName("soyo") val spark = new SparkC ...
- spark shell操作
RDD有两种类型的操作 ,分别是Transformation(返回一个新的RDD)和Action(返回values). 1.Transformation:根据已有RDD创建新的RDD数据集build ...
- Spark SQL with Hive
前一篇文章是Spark SQL的入门篇Spark SQL初探,介绍了一些基础知识和API,可是离我们的日常使用还似乎差了一步之遥. 终结Shark的利用有2个: 1.和Spark程序的集成有诸多限制 ...
- Hive on Spark和Spark sql on Hive,你能分的清楚么
摘要:结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序. 本文分享自华为云社区<Hive on Spark和Spark sql o ...
- Spark 操作Hive 流程
1.ubuntu 装mysql 2.进入mysql: 3.mysql>create database hive (这个将来是存 你在Hive中建的数据库以及表的信息的(也就是元数据))mysql ...
- Spark之 使用SparkSql操作Hive的Scala程序实现
依赖 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2 ...
- HBASE与hive对比使用以及HBASE常用shell操作。与sqoop的集成
2.6.与 Hive 的集成2.6.1.HBase 与 Hive 的对比1) Hive(1) 数据仓库Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个双射关系,以方 ...
随机推荐
- Linux内核引用计数器kref结构
1.前言 struct kref结构体是一个引用计数器,它被嵌套进其它的结构体中,记录所嵌套结构的引用计数.引用计数用于检测内核中有多少地方使用了某个对象,每当内核的一个部分需要某个对象所包含的信息时 ...
- CMD使用的几个小技巧
一.自定义窗口初始化大小 以前在Windows 7的时候感觉打开cmd时窗口初始化的大小还是比较合适的,但到Windows 10之后打开cmd窗口就很大一点都不适应----当然也可能是新电脑分辨率比较 ...
- JDBC链接数据库MySQL 8.0 Public Key Retrieval is not allowed 错误的解决方法
现象 Mybatis和Spring框架整合过程中报 com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Publ ...
- SpringBoot扩展点之二:ApplicationRunner和CommandLineRunner的扩展
CommandLineRunner并不是Spring框架原有的概念,它属于SpringBoot应用特定的回调扩展接口: public interface CommandLineRunner { /** ...
- Linux低延迟服务器系统调优
最近做了一些系统和网络调优相关的测试,达到了期望的效果,有些感悟.同时,我也发现知乎上对Linux服务器低延迟技术的讨论比较欠缺(满嘴高并发现象):或者对现今cpu + 网卡的低延迟潜力认识不足(动辄 ...
- Promise实现子组件的多表单校验并反馈结果给父组件
全手打原创,转载请标明出处:https://www.cnblogs.com/dreamsqin/p/11529207.html,多谢,=.=~ 本文中多表单验证主要用到Promise.all()实现多 ...
- servlet是一组规范--Servlet是JavaEE规范的一种
Java Servlet API是Servlet容器和Servlet之间的接U,它定义了Servlet的各种方法, 还定义了Servlet容器传送给Servlet的对象类,其中最重要的是请求对象Ser ...
- 部署CentOS虚拟机集群
1.在虚拟机中安装CentOS (1)使用CentOS-6.5-i386-minimal.iso.(2)创建虚拟机:打开Virtual Box,点击“新建”按钮,点击“下一步”,输入虚拟机名称为esh ...
- How to signout from an Azure Application?(转载)
问: I have created a Azure AD application and a Web App. The Azure AD Application uses AAD Authentica ...
- 一次golang应用的docker部署经历
开发平台win10,服务器centos7.5 编写dockerfile # scratch 为空镜像,因为golang的build的可执行文件不需要什么环境 FROM scratch # 作者署名 M ...