爬虫 1 requests 、beautifulsoup
1.requests
1.method
提交方式:post、get、put、delete、options、head、patch
2.url
访问地址
3.params
在url中传递的参数,GET
params = {'k1':'v1','k2':'v2'} params = ‘k1=v1&k2=v2’ params = [('k1','v1'),('k2,'v2')]
4.data
在请求体内传递的参数
data = {'k1':'v1','k2':'v2'} data = ‘k1=v1&k2=v2’ data = [('k1','v1'),('k2,'v2')] data = open('file','rb')
5.json
在请求体内传递的参数
JSON serializable Python object
参数经过序列化,意味着可以传递字典内嵌套字典等
6.headers
请求头
headers = { 'referer':上次浏览的页面
'user-agent':用户使用的客户端类型
...
}
7.cookies
即cookie
字典类型或CookieJar object类型,在请求头中传递
8.files
文件
files = {'file1':open('file','rb')} files = ('file1',open('file','rb')) === ('filename', fileobj, 'content_type') 或 ('filename', fileobj, 'content_type', custom_headers)
9.auth
用户名、密码加密 auth = HTTPBasicAuto(username,pwd)
10.timeout
请求和响应的超时
11.allow_redirects
是否允许重定向
.proxies
代理
13.verify
是否忽略证书
14.stream
下载方式 类型为布尔值 True,则下载能下多少下多少
15.cert
针对https,证书文件
16.session
requests.session 可以免去写cookies
2.beautifulsoup
1.markup
将一个字符串或者文件序列化(url,文件路径等)
2.features
解析器类型
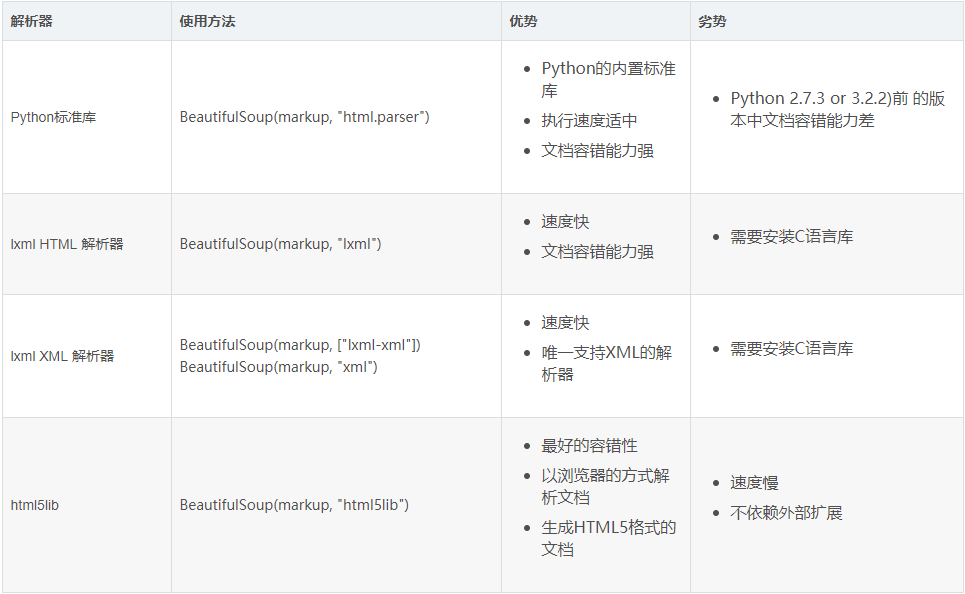
基本应用
.tag
1)name
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
print(tag.name)
通过可以通过该属性来修改标签,如果改变了tag的name,那将影响所有通过当前Beautiful Soup对象生成的HTML文档。
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag.name = 'a'
print(tag)
2)Attributes
一个tag可能有很多个属性. tag <b class="boldest"> 有一个 “class” 的属性,值为 “boldest” . tag的属性的操作方法与字典相同
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
print(tag['class'])
也可以使用attrs可以以字典形式返回标签的所有属性
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
print(tag.attrs)
tag的属性可以被添加,删除或修改.
tag['class'] = 'verybold'
tag['id'] = 1 del tag['class']
del tag['id'] tag['class']
print(tag.get('class'))
3)children
所有子标签
4)clear
将标签的所有子标签全部清空(保留标签名)
tag = soup.find('body')
tag.clear()
print(soup)
5)decompose
递归的删除所有的标签
body = soup.find('body')
body.decompose()
print(soup)
6)extract
递归的删除所有的标签,并获取删除的标签
body = soup.find('body')
v = body.extract()
print(soup)
7)decode 和 encode
decode转换为字符串(含当前标签);decode_contents(不含当前标签)
encode转换为字节(含当前标签);encode_contents(不含当前标签)
body = soup.find('body')
v = body.decode()
v = body.decode_contents()
print(v)
decode
body = soup.find('body')
v = body.encode()
v = body.encode_contents()
print(v)
encode
8)find 和 find_all
查找第一个和查找所有,源码中find的实现基于find_all,取[0]
tag = soup.find('a')
print(tag)
tag = soup.find(name='a', attrs={'class': 'sister'}, recursive=True, text='Lacie')
tag = soup.find(name='a', class_='sister', recursive=True, text='Lacie')
print(tag)
find
tags = soup.find_all('a')
print(tags)
tags = soup.find_all('a',limit=1)
print(tags)
tags = soup.find_all(name='a', attrs={'class': 'sister'}, recursive=True, text='Lacie')
tags = soup.find(name='a', class_='sister', recursive=True, text='Lacie')
print(tags)
####### 列表 #######
v = soup.find_all(name=['a','div'])
print(v)
v = soup.find_all(class_=['sister0', 'sister'])
print(v)
v = soup.find_all(text=['Tillie'])
print(v, type(v[0]))
v = soup.find_all(id=['link1','link2'])
print(v)
v = soup.find_all(href=['link1','link2'])
print(v)
####### 正则 #######
import re
rep = re.compile('p')
rep = re.compile('^p')
v = soup.find_all(name=rep)
print(v)
rep = re.compile('sister.*')
v = soup.find_all(class_=rep)
print(v)
rep = re.compile('http://www.oldboy.com/static/.*')
v = soup.find_all(href=rep)
print(v)
####### 方法筛选 #######
def func(tag):
return tag.has_attr('class') and tag.has_attr('id')
v = soup.find_all(name=func)
print(v)
## get,获取标签属性
tag = soup.find('a')
v = tag.get('id')
print(v)
find_all
9)has_attr
检查标签是否具有该属性
10)get_text
获取标签内部文本内容
11)index
检查标签在某标签中的索引位置
爬虫 1 requests 、beautifulsoup的更多相关文章
- 【Python】在Pycharm中安装爬虫库requests , BeautifulSoup , lxml 的解决方法
BeautifulSoup在学习Python过程中可能需要用到一些爬虫库 例如:requests BeautifulSoup和lxml库 前面的两个库,用Pychram都可以通过 File--> ...
- 爬虫之Requests&beautifulsoup
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕 ...
- python 爬虫(一) requests+BeautifulSoup 爬取简单网页代码示例
以前搞偷偷摸摸的事,不对,是搞爬虫都是用urllib,不过真的是很麻烦,下面就使用requests + BeautifulSoup 爬爬简单的网页. 详细介绍都在代码中注释了,大家可以参阅. # -* ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- 利用requests, beautifulsoup包爬取股票信息网站
这是第一次用requests, beautifulsoup实现爬虫,此次爬取的是一个股票信息网站:http://www.gupiaozhishi.net.cn. 实现非常简单,只是为了demo使用的数 ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
- 爬虫入门二 beautifulsoup
title: 爬虫入门二 beautifulsoup date: 2020-03-12 14:43:00 categories: python tags: crawler 使用beautifulsou ...
- 【爬虫入门手记03】爬虫解析利器beautifulSoup模块的基本应用
[爬虫入门手记03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.Bea ...
- 【网络爬虫入门03】爬虫解析利器beautifulSoup模块的基本应用
[网络爬虫入门03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.B ...
- Python爬虫之requests
爬虫之requests 库的基本用法 基本请求: requests库提供了http所有的基本请求方式.例如 r = requests.post("http://httpbin.org/pos ...
随机推荐
- mlsql 基本操作
数据库的操作: 1.创建 create databases python_test_01(库名,自定义)chaeset = utf8; 2.删除 drop database python_test_0 ...
- Eclipse 护眼背景色设置
链接地址:http://blog.chinaunix.net/uid-27183448-id-3509010.html 背景颜色推荐:色调:85,饱和度:123,亮度:205 文档都不再是刺眼的白底 ...
- PythonStudy——编程基础 Python Primary
1.什么是编程语言 语言: 一个事物与另外一个事物沟通的介质 .编程语言是程序员与计算机沟通的介质. 编程: 将人类内识别的语言转化为机器能识别的指令,这种过程就叫做编程. 注:最终这些指令会被转化 ...
- Centos7 下安装VMware tools
1:先在虚拟机点击安装VMware Tools 2:然后挂载 mount /dev/cdrom /mnt 3:进入/mnt,可以看到有 4:拷贝VMwareTools到其他 ...
- [转]Servlet的学习之Filter过滤器技术
本篇将讲诉Servlet中一项非常重要的技术,Filter过滤器技术.通过过滤器,可以对来自客户端的请求进行拦截,进行预处理或者对最终响应给客户端的数据进行处理后再输出. 要想使用Filter过滤器, ...
- zabbix之 自定义内存使用率监控报警
配置zabbix当内存剩余不足15%的时候触发报警 zabbix默认的剩余内存报警:Average Lack of available memory on server {HOST.NAME}{T ...
- python3中的编码
python2字符串编码存在的问题: 使用 ASCII 码作为默认编码方式,对中文处理不友好 把字符串分为 unicode 和 str 两种类型,将unicode作为唯一内码,误导开发者 python ...
- PostgreSQL 自定义自动类型转换(CAST)
转载自:https://yq.aliyun.com/articles/228271 背景 PostgreSQL是一个强类型数据库,因此你输入的变量.常量是什么类型,是强绑定的,例如 在调用操作符时,需 ...
- ubuntu-docker入门到放弃(七)Dockerfile简介
一.dockerfile基本结构 最简单的理解就是dockerfile实际上是一些命令的堆叠,有点像最基础的shell脚本,没有if 没有for,就是串行的一堆命令. 一般而言,dockerfile分 ...
- problem: vue中获取动态元素高度
前言:始终要相信你能想到的解决方案,基本上都是可以用技术实现的... 解决方法就是在mounted中在this.$nextTick()去获取,如果没有获取到,不是写法错就是,元素没有绑定对地方,注意检 ...